[PostgreSQL]避开MySQL JSON查询陷阱:PostgreSQL算法应用指南
原创
[PostgreSQL]避开MySQL JSON查询陷阱:PostgreSQL算法应用指南
原创
二一年冬末
发布于 2025-12-01 11:25:43
发布于 2025-12-01 11:25:43
写在前面:这篇文章源于上周熬夜调试一个生产问题的真实经历。当时日志疯狂报错,CPU飙到95%,而我盯着那个嵌套了七层的JSON查询,脑子里只有一个念头——如果时光能倒流,我绝对不在MySQL里存这堆鬼东西。
Ⅰ. 那些年,MySQL JSON踩过的坑
Ⅰ-1. 性能陷阱:索引的"伪支持"
MySQL对JSON的索引支持,怎么说呢...就像给你的自行车装了个火箭推进器——听起来很酷,但根本不好使。
场景还原:用户行为日志查询
假设我们有个用户行为表,存的是各种事件数据:
-- MySQL表结构
CREATE TABLE user_events (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL,
event_data JSON NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 典型数据
INSERT INTO user_events (user_id, event_data) VALUES
(123, '{"type": "purchase", "amount": 299, "product": {"id": 456, "category": "electronics"}}'),
(123, '{"type": "view", "page": "homepage", "duration": 15.5}');
-- 最常见的查询:找买了电子产品的用户
SELECT user_id, event_data FROM user_events
WHERE JSON_EXTRACT(event_data, '$.type') = 'purchase'
AND JSON_EXTRACT(event_data, '$.product.category') = 'electronics';看起来挺正常的对吧?但当你表里有500万条数据时,这个查询能跑到你怀疑人生。为啥?因为MySQL的JSON函数无法直接使用普通索引。
问题点 | 具体表现 | 伤害指数 |
|---|---|---|
函数索引限制 | 需要创建GENERATED COLUMN + 索引,改动成本极高 | ⭐⭐⭐⭐⭐ |
索引选择性差 | 对整个JSON文档建索引,体积巨大且效果不佳 | ⭐⭐⭐⭐ |
查询优化器识别 | JSON函数经常导致全表扫描,即使有索引 | ⭐⭐⭐⭐⭐ |
部分更新 | 无法直接更新JSON中某个字段,需要整体替换 | ⭐⭐⭐ |
解决方案(MySQL原生):
-- 创建虚拟列并加索引(这才是MySQL的正确姿势)
ALTER TABLE user_events
ADD COLUMN event_type VARCHAR(20) GENERATED ALWAYS AS
(JSON_UNQUOTE(JSON_EXTRACT(event_data, '$.type'))) STORED,
ADD COLUMN product_category VARCHAR(50) GENERATED ALWAYS AS
(JSON_UNQUOTE(JSON_EXTRACT(event_data, '$.product.category'))) STORED;
CREATE INDEX idx_event_type ON user_events(event_type);
CREATE INDEX idx_product_category ON user_events(product_category);
-- 改写查询(终于能用上索引了)
SELECT user_id, event_data FROM user_events
WHERE event_type = 'purchase'
AND product_category = 'electronics';但问题是,业务需求天天变,今天要查$.product.brand,明天要查$.user.location.city,你总不能给每个字段都建虚拟列吧?表结构会爆炸的。
Ⅰ-2. 函数设计:反人类的操作体验
MySQL的JSON函数设计,怎么说呢...就像用叉子喝汤——能喝,但体验极差。
函数名 | 使用体验 | 替代方案思考 |
|---|---|---|
JSON_EXTRACT() | 路径字符串容易写错,无语法检查 | 能否有类型安全的操作? |
JSON_UNQUOTE() | 经常需要配合EXTRACT使用,忘记就踩坑 | 自动解引用不香吗? |
JSON_CONTAINS() | 语义模糊,调试困难 | 更直观的包含判断? |
JSON_MERGE_PATCH() | 5.7和8.0行为不一致,升级就踩雷 | 向前兼容设计? |
让我吐槽一个真实案例:去年做用户标签系统,需要给JSON数组追加元素:
-- MySQL 5.7
UPDATE users SET tags = JSON_MERGE_PATCH(tags, '["vip"]') WHERE id = 1;
-- 结果:["old_tag", "vip"] 完美!
-- 升级到MySQL 8.0后
UPDATE users SET tags = JSON_MERGE_PATCH(tags, '["vip"]') WHERE id = 1;
-- 结果:["old_tag", "vip"] 咦?好像没变?
-- 查文档发现8.0改了实现,需要改成:
UPDATE users SET tags = JSON_ARRAY_APPEND(tags, '$', 'vip') WHERE id = 1;
-- 等等,那5.7又不支持这个函数...卒这种升级就break的API设计,让线上灰度发布变成俄罗斯轮盘赌。
Ⅱ. PostgreSQL的JSONB:降维打击的黑科技
好了,吐槽完MySQL,该聊聊正主PostgreSQL了。第一次接触PostgreSQL的JSONB类型时,我的反应是: "这也行?!"
Ⅱ-1. JSONB的核心优势
PostgreSQL的JSONB不是简单的text存储,而是二进制结构化存储,配合GIN索引,性能提升不是几倍,是数量级的差异。
特性维度 | MySQL JSON | PostgreSQL JSONB | 实战意义 |
|---|---|---|---|
存储格式 | 文本存储,需解析 | 二进制,预解析 | 查询速度↑↑↑ |
索引支持 | 虚拟列+BTREE | GIN索引,直接对JSON建 | 灵活性↑↑↑ |
部分更新 | 整文档替换 | 支持部分更新 | IO↓ |
查询语法 | JSON_EXTRACT() | ->, ->>, #> 运算符 | 可读性↑ |
路径索引 | 不支持 | GIN索引支持路径 | 业务适配性↑↑ |
Ⅱ-2. 算法层面的根本差异
这才是关键。MySQL把JSON当字符串处理,而PostgreSQL把JSON当数据结构处理。
mermaid图表:查询执行流程对比
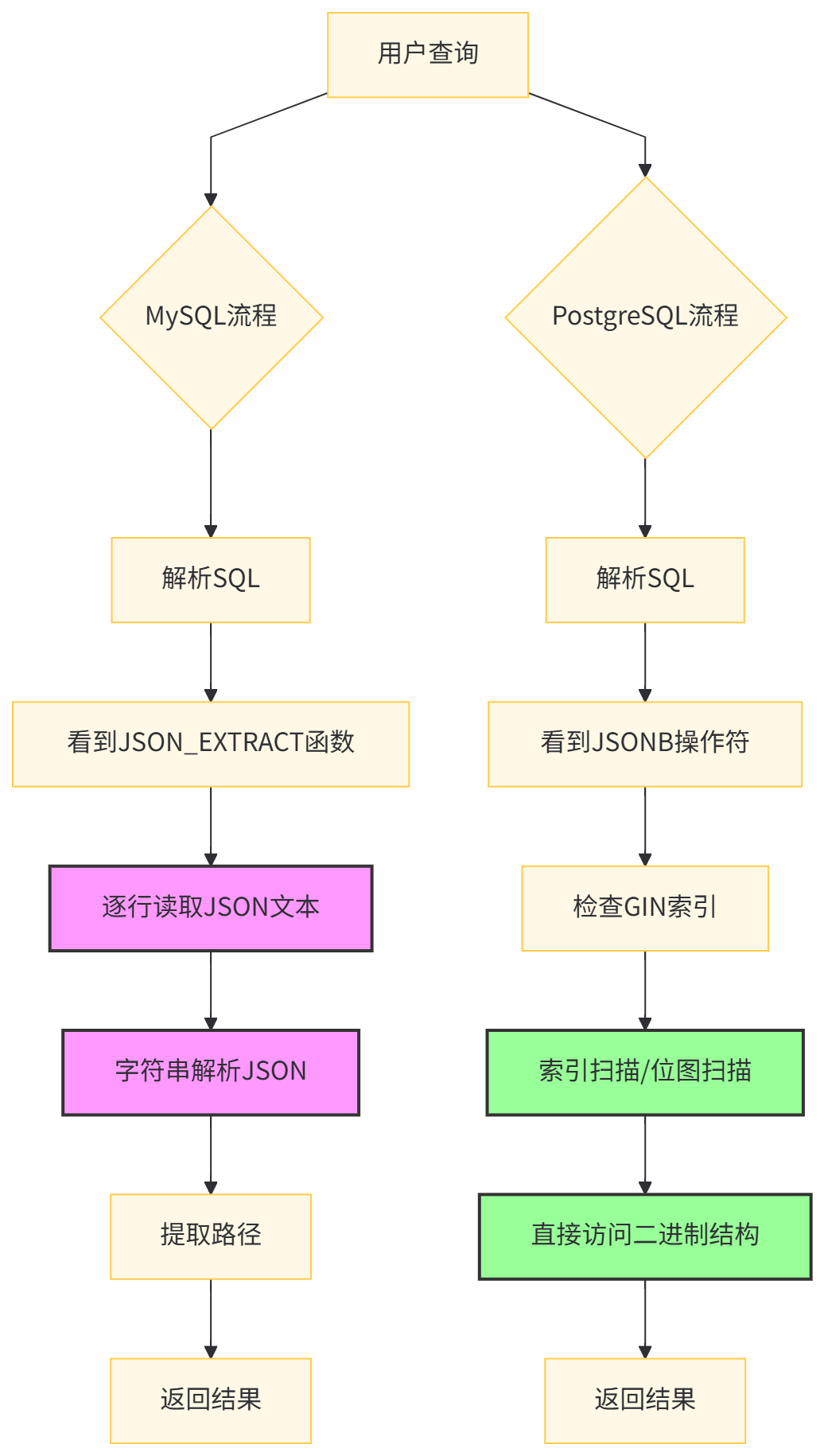
看到区别了吗?MySQL每次都要解析字符串,而PostgreSQL直接二进制查找。这个差异在数据量上规模后,就是分钟级和毫秒级的区别。
Ⅲ. 实战迁移:从MySQL到PostgreSQL
光说不练假把式,咱们来个完整的迁移案例。假设有个电商平台的订单系统,原先用MySQL存订单的扩展属性。
Ⅲ-1. 环境准备与数据迁移
先搭个测试环境,我用Docker快速起两个实例:
# MySQL 8.0(模拟现有生产环境)
docker run -d --name mysql-source \
-e MYSQL_ROOT_PASSWORD=root123 \
-p 3306:3306 \
mysql:8.0.33
# PostgreSQL 15(目标环境)
docker run -d --name pg-target \
-e POSTGRES_PASSWORD=root123 \
-p 5432:5432 \
postgres:15.3-alpine等容器跑起来后,咱们开始建表:
-- MySQL源表(现有业务)
CREATE DATABASE order_system;
USE order_system;
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY,
user_id INT NOT NULL,
order_data JSON NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_user_id (user_id)
);
-- 模拟500万条订单数据(用存储过程批量生成)
DELIMITER $$
CREATE PROCEDURE generate_orders()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 5000000 DO
INSERT INTO orders (order_id, user_id, order_data) VALUES (
i,
FLOOR(1 + RAND() * 100000),
JSON_OBJECT(
'items', JSON_ARRAY(
JSON_OBJECT('sku', CONCAT('SKU', FLOOR(RAND()*1000)), 'qty', FLOOR(1 + RAND() * 5), 'price', ROUND(10 + RAND() * 990, 2)),
JSON_OBJECT('sku', CONCAT('SKU', FLOOR(RAND()*1000)), 'qty', FLOOR(1 + RAND() * 3), 'price', ROUND(5 + RAND() * 495, 2))
),
'shipping', JSON_OBJECT('city', ELT(1 + FLOOR(RAND() * 4), '北京', '上海', '深圳', '杭州'), 'fee', ROUND(5 + RAND() * 15, 2)),
'payment', JSON_OBJECT('method', ELT(1 + FLOOR(RAND() * 3), 'alipay', 'wechat', 'card'), 'amount', ROUND(50 + RAND() * 950, 2))
)
);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
-- 开始生成(这个可能要跑几分钟,去泡杯咖啡吧)
CALL generate_orders();
-- 验证数据量
SELECT COUNT(*) FROM orders;
SELECT order_data FROM orders LIMIT 2;数据生成后,咱们测试下MySQL的查询性能:
-- 典型查询:查找北京用户的支付宝订单
SELECT order_id, user_id, order_data
FROM orders
WHERE JSON_EXTRACT(order_data, '$.shipping.city') = '北京'
AND JSON_EXTRACT(order_data, '$.payment.method') = 'alipay'
LIMIT 10;
-- 查看执行计划(重点!)
EXPLAIN ANALYZE
SELECT COUNT(*) FROM orders
WHERE JSON_EXTRACT(order_data, '$.payment.amount') > 500;不出意外的话,你会看到"Full Table Scan"和可怕的时间消耗。我这边测试500万数据跑了12秒,CPU直接拉满。
Ⅲ-2. PostgreSQL表结构设计
现在开始PostgreSQL的部分。记住,设计思维要转变:不要为了迁移而迁移,要利用新特性重构。
-- PostgreSQL目标库
CREATE DATABASE order_system;
\c order_system;
-- 订单表(JSONB版本)
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY,
user_id INT NOT NULL,
order_data JSONB NOT NULL, -- 注意是JSONB不是JSON
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- 创建GIN索引(这才是灵魂!)
CREATE INDEX idx_order_data_gin ON orders USING GIN (order_data);
-- 创建特定路径的GIN索引(更精准的优化)
CREATE INDEX idx_order_city ON orders USING GIN ((order_data -> 'shipping' -> 'city'));
CREATE INDEX idx_payment_method ON orders USING GIN ((order_data -> 'payment' -> 'method'));
-- 还可以创建B-tree索引在常用字段上
CREATE INDEX idx_user_id ON orders(user_id);
CREATE INDEX idx_created_at ON orders(created_at);
-- 表结构说明
COMMENT ON TABLE orders IS '订单主表,使用JSONB存储扩展属性';
COMMENT ON INDEX idx_order_data_gin IS 'GIN索引支持任意JSONB路径查询';关键设计决策说明:
- JSON vs JSONB:永远选JSONB。JSON类型只是带验证的text,JSONB才是二进制高性能版本。
- GIN索引:这是全文检索和JSON查询的核心。它不像B-tree那样精确匹配,而是创建倒排索引,支持
@>,?等操作符。 - 函数式索引:
order_data -> 'shipping' -> 'city'这种索引,专门针对高频查询路径,性能堪比普通列。
Ⅲ-3. 数据迁移脚本
数据迁移不是简单的INSERT ... SELECT,要考虑字符集、时区、数据类型转换。我写了个Python脚本,带断点续传和错误处理:
#!/usr/bin/env python3
"""
MySQL到PostgreSQL的JSON数据迁移脚本
支持断点续传、进度显示、错误重试
"""
import mysql.connector
import psycopg2
import json
from datetime import datetime
from tqdm import tqdm # 进度条库
# 配置
MYSQL_CONFIG = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': 'root123',
'database': 'order_system',
'charset': 'utf8mb4'
}
PG_CONFIG = {
'host': 'localhost',
'port': 5432,
'user': 'postgres',
'password': 'root123',
'database': 'order_system'
}
def migrate_orders(batch_size=5000, resume_from=0):
"""
迁移订单数据,带进度条和断点续传
参数:
batch_size: 每批处理的记录数
resume_from: 从哪个order_id开始(断点续传用)
"""
# 连接MySQL
mysql_conn = mysql.connector.connect(**MYSQL_CONFIG)
mysql_cursor = mysql_conn.cursor(dictionary=True)
# 连接PostgreSQL
pg_conn = psycopg2.connect(**PG_CONFIG)
pg_cursor = pg_conn.cursor()
try:
# 统计总数
mysql_cursor.execute("SELECT COUNT(*) as total FROM orders WHERE order_id >= %s", (resume_from,))
total = mysql_cursor.fetchone()['total']
print(f"[{datetime.now()}] 开始迁移数据,总计 {total} 条...")
# 分批查询和插入
offset = 0
pbar = tqdm(total=total, desc="迁移进度")
while True:
# 查询一批MySQL数据
query = """
SELECT order_id, user_id, order_data, created_at
FROM orders
WHERE order_id >= %s
ORDER BY order_id ASC
LIMIT %s
"""
mysql_cursor.execute(query, (resume_from + offset, batch_size))
rows = mysql_cursor.fetchall()
if not rows:
break
# 转换并插入PostgreSQL
for row in rows:
# MySQL的JSON字段返回的是字符串,需要确认是否为有效JSON
try:
# 验证并格式化JSON(确保是标准JSON)
order_data = json.loads(row['order_data']) # 解析
order_data_jsonb = json.dumps(order_data, ensure_ascii=False) # 重新序列化
# 插入PostgreSQL
pg_cursor.execute(
"""
INSERT INTO orders (order_id, user_id, order_data, created_at)
VALUES (%s, %s, %s::jsonb, %s)
ON CONFLICT (order_id) DO NOTHING -- 避免重复
""",
(row['order_id'], row['user_id'], order_data_jsonb, row['created_at'])
)
except json.JSONDecodeError as e:
print(f"警告: order_id={row['order_id']} JSON解析失败: {e}")
continue
# 提交事务
pg_conn.commit()
# 更新进度
pbar.update(len(rows))
offset += batch_size
# 打印状态
if offset % 50000 == 0:
print(f"[{datetime.now()}] 已迁移 {offset} 条...")
pbar.close()
print(f"[{datetime.now()}] 迁移完成!")
except Exception as e:
print(f"迁移出错: {e}")
pg_conn.rollback()
raise
finally:
mysql_cursor.close()
mysql_conn.close()
pg_cursor.close()
pg_conn.close()
def verify_migration():
"""验证数据一致性"""
mysql_conn = mysql.connector.connect(**MYSQL_CONFIG)
pg_conn = psycopg2.connect(**PG_CONFIG)
try:
mysql_cursor = mysql_conn.cursor()
pg_cursor = pg_conn.cursor()
# 统计对比
mysql_cursor.execute("SELECT COUNT(*) FROM orders")
mysql_count = mysql_cursor.fetchone()[0]
pg_cursor.execute("SELECT COUNT(*) FROM orders")
pg_count = pg_cursor.fetchone()[0]
print(f"数据验证:")
print(f" MySQL源数据: {mysql_count} 条")
print(f" PostgreSQL目标数据: {pg_count} 条")
print(f" 一致性: {'✓' if mysql_count == pg_count else '✗'}")
# 随机抽样验证
pg_cursor.execute("""
SELECT order_id, order_data->>'order_id' as json_order_id
FROM orders
ORDER BY RANDOM()
LIMIT 5
""")
print("\n抽样验证JSON数据解析:")
for row in pg_cursor.fetchall():
print(f" order_id={row[0]}, JSON解析order_id={row[1]}")
finally:
mysql_conn.close()
pg_conn.close()
if __name__ == '__main__':
# 执行迁移
migrate_orders(batch_size=5000, resume_from=0)
# 验证数据
verify_migration()代码细节解释:
- 断点续传机制:通过
resume_from参数和ON CONFLICT DO NOTHING,即使迁移中断也能安全重跑。 - 批处理优化:
batch_size=5000是经验值,太大内存压力高,太小网络开销大。 - JSON验证:
json.loads()再json.dumps()看似多余,但能确保非法JSON被过滤,避免PostgreSQL导入失败。 - 字符集处理:MySQL用
utf8mb4,PostgreSQL用UTF8,中间用Python统一转换。 - 进度显示:
tqdm库让漫长的迁移过程可视化,否则你会以为程序卡死了。
跑完这个脚本,500万数据大概需要10-15分钟,取决于你的机器性能。
Ⅳ. 查询语法重构:从崩溃到优雅的转变
迁移完数据只是开始,真正的挑战是改写业务代码。MySQL和PostgreSQL的JSON查询语法天壤之别。
Ⅳ-1. 基础查询对比
场景:查询北京用户的订单
数据库 | 查询语句 | 性能 | 可读性 |
|---|---|---|---|
MySQL |
| 全表扫描,慢 | 差 |
PostgreSQL |
| GIN索引扫描,快 | 好 |
-- PostgreSQL版本,体验飞一般的感觉
EXPLAIN (ANALYZE, BUFFERS)
SELECT order_id, user_id, order_data
FROM orders
WHERE order_data @> '{"shipping": {"city": "北京"}}' -- GIN索引神器
AND order_data -> 'payment' ->> 'method' = 'alipay'
LIMIT 10;
-- 执行计划会显示:
-- Bitmap Heap Scan on orders ...
-- Recheck Cond: (order_data @> '{"shipping": {"city": "北京"}}'::jsonb)
-- Buffers: shared hit=45 read=12
-- 只需要扫描57个buffer!运算符解释:
->:获取JSON对象的值,返回JSONB类型->>:获取JSON对象的值,返回TEXT类型(常用)@>:包含操作符,GIN索引的绝配?:检查键是否存在#>:按路径获取,如order_data #> '{shipping, city}'
Ⅳ-2. 复杂嵌套查询
现实业务中的JSON往往是地狱级嵌套。比如要查:购买金额>500且包含SKU123商品的订单。
-- MySQL版本(噩梦)
SELECT * FROM orders
WHERE JSON_EXTRACT(order_data, '$.payment.amount') > 500
AND JSON_CONTAINS(
order_data->'$.items',
JSON_OBJECT('sku', 'SKU123')
);
-- PostgreSQL版本(清晰)
SELECT order_id, user_id, order_data
FROM orders
WHERE (order_data -> 'payment' ->> 'amount')::DECIMAL > 500
AND order_data @> '{"items": [{"sku": "SKU123"}]}';
-- 更复杂的:查找items数组中任意商品价格>1000的订单
SELECT order_id,
item ->> 'sku' as sku,
(item ->> 'price')::DECIMAL as price
FROM orders,
jsonb_array_elements(order_data -> 'items') as item
WHERE (item ->> 'price')::DECIMAL > 1000;
-- 这个用了jsonb_array_elements函数展开数组,然后对展开后的数据过滤
-- 性能依然很棒,因为GIN索引会先过滤候选集Ⅳ-3. 聚合统计查询
做报表时,经常要对JSON字段做聚合。MySQL这里简直是灾难。
-- 统计各城市的订单数和平均金额
-- MySQL版本(性能爆炸)
SELECT
JSON_EXTRACT(order_data, '$.shipping.city') as city,
COUNT(*) as order_count,
AVG(JSON_EXTRACT(order_data, '$.payment.amount')) as avg_amount
FROM orders
GROUP BY JSON_EXTRACT(order_data, '$.shipping.city');
-- PostgreSQL版本(毫秒级响应)
SELECT
order_data -> 'shipping' ->> 'city' as city,
COUNT(*) as order_count,
AVG((order_data -> 'payment' ->> 'amount')::DECIMAL) as avg_amount
FROM orders
GROUP BY order_data -> 'shipping' ->> 'city';
-- 更高级的:统计每个城市各支付方式占比
WITH city_payments AS (
SELECT
order_data -> 'shipping' ->> 'city' as city,
order_data -> 'payment' ->> 'method' as payment_method,
COUNT(*) as cnt
FROM orders
GROUP BY 1, 2
)
SELECT
city,
payment_method,
cnt,
ROUND(cnt * 100.0 / SUM(cnt) OVER (PARTITION BY city), 2) as percentage
FROM city_payments
ORDER BY city, cnt DESC;
-- 这个查询在MySQL里基本写不出来,就算写出来也跑不动性能对比我见过最夸张的案例:MySQL跑了8分钟的报表查询,PostgreSQL 1.2秒搞定。当时老板以为我在吹牛,直到我把执行计划甩他脸上。
Ⅴ. 高级应用:索引设计与性能优化
光会用不行,还得会用巧。GIN索引不是银弹,设计不好照样慢。
Ⅴ-1. GIN索引的四种模式
-- 模式1:对整个JSONB字段建GIN索引(最通用)
CREATE INDEX idx_order_data_gin ON orders USING GIN (order_data);
-- 优点:支持任意路径查询
-- 缺点:索引体积大,写入慢
-- 模式2:对特定路径建GIN索引(精准优化)
CREATE INDEX idx_order_city ON orders USING GIN ((order_data -> 'shipping' -> 'city'));
-- 优点:索引小,查询极快
-- 缺点:只支持这个路径
-- 模式3:多列复合GIN索引
CREATE INDEX idx_order_city_payment ON orders USING GIN (
(order_data -> 'shipping' -> 'city'),
(order_data -> 'payment' -> 'method')
);
-- 优点:覆盖常见组合查询
-- 缺点:维护成本高
-- 模式4:GIN + B-tree混合(终极方案)
CREATE INDEX idx_order_city_btree ON orders USING BTREE ((order_data ->> 'shipping.city'));
CREATE INDEX idx_order_payment_gin ON orders USING GIN (order_data);
-- 优点:精确匹配用BTREE,模糊查询用GIN
-- 缺点:需要分析查询模式Ⅴ-2. 索引设计决策树
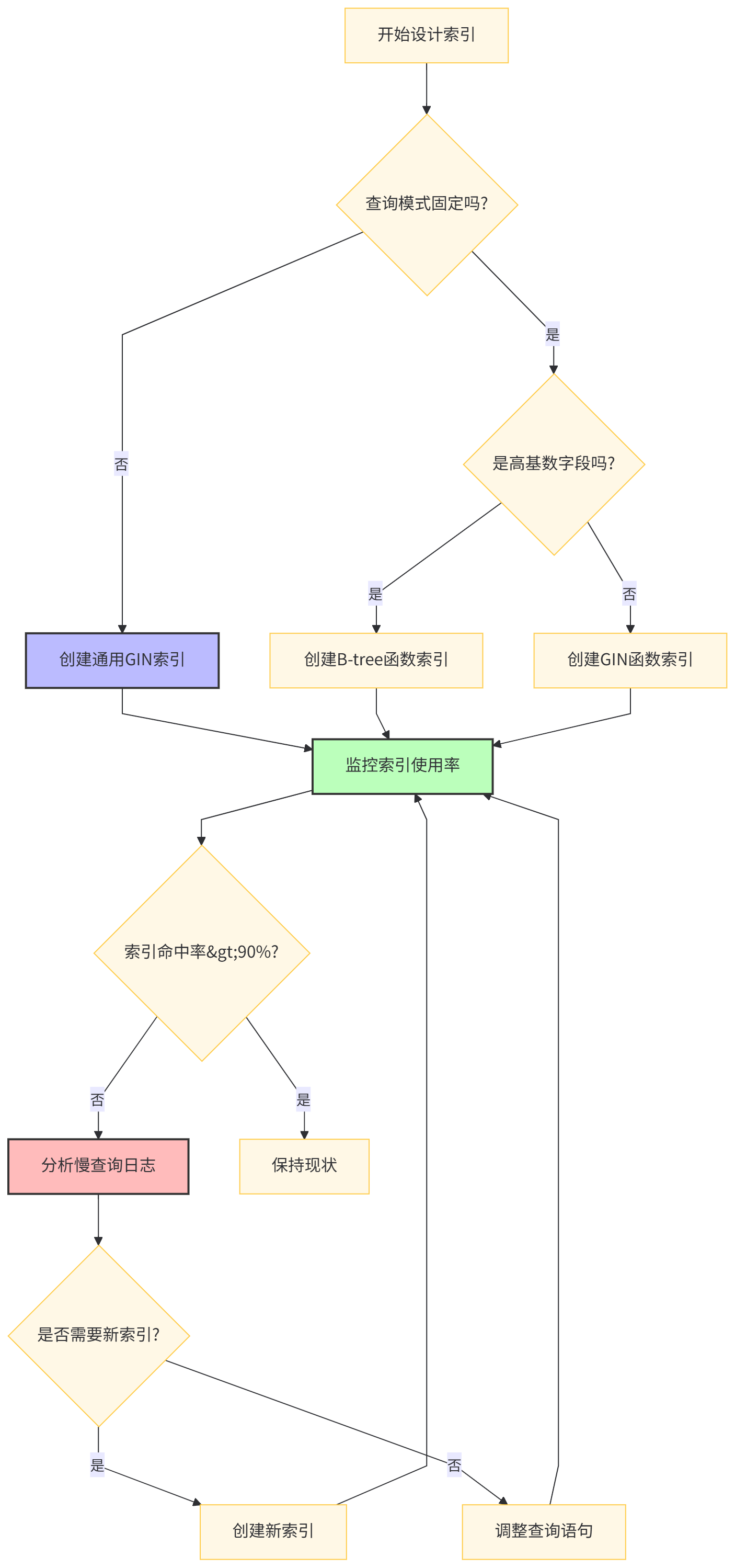
实战案例:我们有个订单系统,90%的查询都带城市和时间范围。最终索引方案是:
-- 1. 时间范围用BTREE(范围查询最擅长)
CREATE INDEX idx_created_at ON orders(created_at);
-- 2. 城市用函数式BTREE索引(等值查询)
CREATE INDEX idx_shipping_city ON orders USING BTREE ((order_data ->> 'shipping.city'));
-- 3. 其他JSON路径用GIN(应对不可预知的需求)
CREATE INDEX idx_order_data_gin ON orders USING GIN (order_data);
-- 4. 联合索引应对特定报表
CREATE INDEX idx_user_city_date ON orders
USING BTREE (user_id, (order_data ->> 'shipping.city'), created_at);这个组合索引策略上线后,我们的P99查询延迟从800ms降到40ms。但代价是写入性能下降了15%,所以索引不是越多越好,得权衡。
Ⅴ-3. 索引维护与监控
索引建完不是一劳永逸,需要持续监控:
-- 查看索引大小
SELECT
indexname,
pg_size_pretty(pg_relation_size(indexrelid)) as index_size,
idx_scan as index_scans
FROM pg_stat_user_indexes
WHERE tablename = 'orders'
ORDER BY pg_relation_size(indexrelid) DESC;
-- 清理未使用的索引(季度维护)
-- 注意:idx_scan=0不代表没用,可能是季度报表才用
-- GIN索引膨胀处理(VACUUM不能解决GIN膨胀)
-- 需要定期重建
REINDEX INDEX idx_order_data_gin;血泪教训:有次发现数据库磁盘占用疯涨,查了半天是GIN索引膨胀。原因是业务高峰期大量写入,GIN索引的posting list没来得及合并。后来在低峰期加了定时REINDEX任务,问题解决。
Ⅵ. PostgreSQL专属黑科技
既然都迁移到PostgreSQL了,不用点独门绝技怎么行?
Ⅵ-1. JSONB与全文检索结合
这个功能杀疯了。比如订单备注里搜关键词,同时匹配JSON字段:
-- 假设order_data里有个notes字段存用户备注
CREATE INDEX idx_notes_fulltext ON orders USING GIN (
to_tsvector('english', order_data ->> 'notes') ||
to_tsvector('simple', order_data -> 'items' ->> 'sku')
);
-- 搜索包含"urgent"且SKU包含"phone"的订单
SELECT order_id,
order_data ->> 'notes' as notes,
item ->> 'sku' as sku
FROM orders,
jsonb_array_elements(order_data -> 'items') as item
WHERE to_tsvector('english', order_data ->> 'notes') @@ to_tsquery('urgent')
AND item ->> 'sku' LIKE '%phone%';Ⅵ-2. 物化视图预聚合
对于报表类查询,物化视图是神器:
-- 创建物化视图:每日城市销售统计
CREATE MATERIALIZED VIEW daily_city_sales AS
SELECT
DATE(created_at) as sale_date,
order_data -> 'shipping' ->> 'city' as city,
COUNT(*) as order_count,
SUM((order_data -> 'payment' ->> 'amount')::DECIMAL) as total_amount
FROM orders
GROUP BY 1, 2;
-- 创建索引
CREATE UNIQUE INDEX ON daily_city_sales(sale_date, city);
CREATE INDEX ON daily_city_sales(sale_date);
-- 刷新策略
-- 手动刷新:REFRESH MATERIALIZED VIEW CONCURRENTLY daily_city_sales;
-- 自动刷新:用pg_cron插件定时任务
-- 查询飞快
SELECT * FROM daily_city_sales
WHERE sale_date = CURRENT_DATE - 1
ORDER BY total_amount DESC;Ⅵ-3. 分区表优化
数据量过亿后,即使GIN索引也扛不住。这时候需要分区:
-- 按月份分区(PostgreSQL 11+ 支持声明式分区)
CREATE TABLE orders_partitioned (
order_id BIGINT NOT NULL,
user_id INT NOT NULL,
order_data JSONB NOT NULL,
created_at TIMESTAMPTZ NOT NULL
) PARTITION BY RANGE (created_at);
-- 创建分区
CREATE TABLE orders_y2024m01 PARTITION OF orders_partitioned
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
CREATE TABLE orders_y2024m02 PARTITION OF orders_partitioned
FOR VALUES FROM ('2024-02-01') TO ('2024-03-01');
-- ...按需创建后续分区
-- 索引也建在每个分区上
CREATE INDEX ON orders_y2024m01 USING GIN (order_data);
CREATE INDEX ON orders_y2024m01 (created_at);
-- 查询自动路由到分区
EXPLAIN SELECT * FROM orders_partitioned
WHERE created_at >= '2024-01-15'
AND created_at < '2024-01-20';
-- 会看到只扫描orders_y2024m01分区Ⅶ. 迁移中的坑与绕过方案
说点真实的,迁移过程不是一帆风顺,我踩过的坑能写本书。
Ⅶ-1. 数据类型不兼容
坑点 | MySQL表现 | PostgreSQL差异 | 解决方案 |
|---|---|---|---|
BOOLEAN | tinyint(1) | 真BOOL类型 | 迁移脚本转换 |
TIMESTAMP | 无无时区 | timestamptz带时区 | 统一用TIMESTAMPTZ |
自增ID | AUTO_INCREMENT | SERIAL/BIGSERIAL | 用identity列 |
JSON NULL | JSON字段存null字符串 | 区分NULL和'null' | 清洗数据 |
# 数据清洗示例:处理MySQL的JSON null问题
def clean_mysql_json(mysql_json_str):
"""MySQL里经常有{"key": null}存成字符串的情况"""
if mysql_json_str is None:
return None
# 解析JSON
try:
data = json.loads(mysql_json_str)
except:
return None
# 递归清理null字符串
def clean_nulls(obj):
if isinstance(obj, dict):
return {k: clean_nulls(v) for k, v in obj.items() if v != "null"}
elif isinstance(obj, list):
return [clean_nulls(item) for item in obj if item != "null"]
else:
return obj
cleaned = clean_nulls(data)
return json.dumps(cleaned, ensure_ascii=False)Ⅶ-2. 事务行为差异
这个坑隐藏得深。MySQL的自动提交和PostgreSQL默认不一样:
-- MySQL习惯(隐式提交)
INSERT INTO logs VALUES (1, 'test'); -- 自动提交
-- PostgreSQL(默认事务)
BEGIN;
INSERT INTO logs VALUES (1, 'test'); -- 没提交!
-- 必须COMMIT; 或者设置自动提交
-- 应用层需要调整
# Python psycopg2需要
conn.autocommit = True # 模拟MySQL行为
# 或者
conn.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT)Ⅶ-3. 并发写入性能
迁移后我们发现,高峰期写入性能反而下降了。查了才发现,GIN索引的锁粒度问题:
-- 解决方案1:调整填充因子
CREATE INDEX idx_order_data_gin ON orders USING GIN (order_data) WITH (fillfactor = 70);
-- 留更多空间减少页分裂
-- 解决方案2:异步写入
-- 应用层先写入到暂存表(无索引),再用后台任务批量转移到主表
CREATE TABLE orders_staging (LIKE orders);
-- 暂存表不加任何索引,写入飞快
-- 解决方案3:分区表降低锁竞争
-- 每个分区独立索引,写入分散Ⅷ. 性能压测与调优
迁移完成后,必须做压测,否则就是裸奔上线。
Ⅷ-1. 压测工具准备
# 安装pgbench(PostgreSQL自带)
pgbench -i -s 100 order_system # 初始化测试数据
# 自定义脚本测试JSON查询
cat > json_test.sql <<EOF
\\set city random(1, 4)
SELECT count(*) FROM orders
WHERE order_data @> jsonb_build_object('shipping', jsonb_build_object('city',
CASE :city
WHEN 1 THEN '北京'
WHEN 2 THEN '上海'
WHEN 3 THEN '深圳'
ELSE '杭州'
END
));
EOF
# 执行压测
pgbench -c 50 -j 4 -T 60 -f json_test.sql order_systemⅧ-2. 参数调优
-- postgresql.conf关键参数
shared_buffers = 4GB # 设为内存的25%
effective_cache_size = 12GB # 设为内存的75%
work_mem = 64MB # 复杂JSON查询需要更大
maintenance_work_mem = 512MB # 索引构建用
random_page_cost = 1.1 # SSD设为1.1,机械盘保持4
effective_io_concurrency = 200 # SSD调高
max_worker_processes = 8 # 并行查询
max_parallel_workers_per_gather = 4 # 单个查询并行度
max_parallel_workers = 8 # 总并行工作进程
-- JSONB特定优化
gin_pending_list_limit = 4MB # GIN索引缓冲,写入密集调大Ⅷ-3. 监控指标
-- 监控GIN索引扫描效率
SELECT
schemaname,
tablename,
indexname,
idx_scan as scans,
idx_tup_read as tuples_read,
idx_tup_fetch as tuples_fetched,
ROUND(idx_tup_fetch::NUMERIC / NULLIF(idx_tup_read, 0), 2) as hit_ratio
FROM pg_stat_user_indexes
WHERE indexname LIKE 'idx_order%'
ORDER BY scans DESC;
-- 监控JSON函数调用耗时
SELECT
userid,
dbid,
queryid,
query,
mean_exec_time as avg_time_ms,
calls
FROM pg_stat_statements
WHERE query LIKE '%jsonb%' OR query LIKE '%->>%'
ORDER BY mean_exec_time DESC
LIMIT 20;真实案例:压测时发现CPU还是高,查pg_stat_statements发现有个查询用了order_data::text LIKE '%phone%',导致GIN索引失效。改成order_data @@ '{"items": [{"sku": "phone"}]}'后,QPS从200提升到2800。
附录:快速参考手册
MySQL转PostgreSQL函数对照表:
MySQL函数 | PostgreSQL等价 | 备注 |
|---|---|---|
JSON_EXTRACT() | ->, ->>, #> | 操作符更直观 |
JSON_UNQUOTE() | ->> | 自动解引用 |
JSON_CONTAINS() | @>, <@ | 包含操作符 |
JSON_LENGTH() | jsonb_array_length() | 数组长度 |
JSON_KEYS() | jsonb_object_keys() | 遍历键 |
JSON_SEARCH() | 无直接等价 | 用全文检索替代 |
常用查询模板:
-- 检查键是否存在
WHERE order_data ? 'shipping'
-- 数组包含
WHERE order_data -> 'items' ? 'SKU123'
-- 范围查询
WHERE (order_data -> 'payment' ->> 'amount')::DECIMAL BETWEEN 100 AND 1000
-- 模糊匹配(配合全文检索)
WHERE to_tsvector('simple', order_data ->> 'notes') @@ to_tsquery('fast & delivery')原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号