openGauss 应用开发测评(PostgreSQL 接入方式)


前言
本文基于本地环境进行一次面向应用开发者的轻量测评,关注“易用性、兼容性、事务语义、开发体验”。示例通过 PostgreSQL 驱动(psycopg2)连接 openGauss,并在数据库中进行若干简单的表操作与事务演示。
**一、开源数据库的时代背景与****openGauss的定位 **
在全球数字化浪潮席卷各行各业的今天,数据库作为信息系统核心基石的地位愈发凸显。长期以来,我国数据库市场处于被国外商业巨头垄断的局面,多数数据库厂商只能基于MySQL或PostgreSQL进行封装开发,在技术上缺乏面向未来的创新机遇。这一局面随着openGauss的出现发生了根本性转变。

openGauss是华为开源的企业级开源关系型数据库,自2020年6月开源以来,迅速成长为数据库领域的领军力量。根据最新市场报告显示,2024年openGauss在线下集中式关系型数据库新增市场份额已达到30.2%,基于openGauss的关系型数据库产品占比达28.5%,超过MySQL和PostgreSQL,成为三大主流开源技术路线之首。这一数据充分证明了openGauss在市场上的广泛认可度和技术竞争力。截至目前,openGauss社区已汇聚850余家社区企业成员,7600多名贡献者,覆盖全球1623个城市,累计下载量超过360万次。这种开放式创新生态为openGauss的持续进化提供了不竭动力。在技术特性上,openGauss具备高性能、高安全、高可用、高智能的显著优势。它通过多核架构性能优化、主备部署高可用性、全密态计算安全机制等创新技术,为企业级应用提供了坚实的数据库解决方案。特别是在与PostgreSQL协议的兼容性方面,openGauss的表现令人瞩目——它兼容PostgreSQL无线协议,这意味着大量的PostgreSQL生态工具和驱动程序可以直接或稍作调整后应用于openGauss环境,极大地降低了开发者的学习和迁移成本。本次测评将聚焦于openGauss的这一重要特性——对PostgreSQL协议的兼容性,通过实际的开发示例展示如何使用标准的PostgreSQL驱动(psycopg2)连接和操作openGauss数据库,评估其在真实开发场景中的易用性、兼容性和可靠性。
**二、**技术测评的价值与目标设定
对openGauss进行基于PostgreSQL接入方式的开发测评具有重要的实践意义。随着openGauss在金融、电信、政府、能源等关键行业的广泛应用,越来越多的应用开发者需要评估将其现有PostgreSQL应用迁移到openGauss的可行性,或者为新项目选择技术路线。因此,本次测评旨在为开发者提供一手参考,帮助其了解openGauss的实际开发体验。

从行业应用角度看,openGauss已在多个关键业务场景中验证了其价值。在金融领域,邮政储蓄银行通过鲲鹏、自主创新操作系统、openGauss打造的IT基础设施,支持全国6.5亿用户,日均20亿的交易,全天联机平均耗时降低30%,系统负载峰值TPS提升319%。兴业银行基于openGauss开源数据库对现有业务进行优化,已在报表系统、支付系统等系统投产使用,共计应用超过30套系统。
这些成功案例充分证明了openGauss在企业级应用中的成熟度和可靠性。本次测评将避开复杂的架构讨论和性能基准测试,转而从应用开发者的实际视角出发,关注以下核心维度:易用性:使用标准的PostgreSQL驱动连接openGauss的便捷程度,包括连接字符串配置、基础CRUD操作等方面;
- 兼容性:openGauss对PostgreSQL协议和SQL语法的兼容范围,是否存在显著差异或限制;
- 事务语义:在事务处理方面的一致性,包括事务隔离级别、原子性、一致性等特性的表现;
- 开发体验:错误信息清晰度、开发工具支持、文档质量等影响开发效率的因素。
通过这几个维度的评估,我们希望为Python开发者(特别是已有PostgreSQL经验的团队)提供关于openGauss的实用参考,降低技术选型和迁移决策的不确定性。
三、openGauss测试
环境与连接信息
- 数据库:openGauss
- 连接方式:PostgreSQL 驱动(psycopg2)
- 地址:127.0.0.1
- 端口:8888
- 用户:joe
- 密码:123456Zy!
- 数据库:db_tpcc
依赖与准备
- Python 3.8+
- 依赖安装(示例):pip install psycopg2-binary
- openGauss 已就绪并允许通过以上账号访问数据库 db_tpcc。
- macOS 开发说明:在 mac 上开发使用的是 PostgreSQL 的驱动(psycopg2)来链接 openGauss 数据库。openGauss 兼容 PostgreSQL wire protocol,因此通过 psycopg2-binary 安装并使用标准 PG 接口即可完成连接与常规 CRUD/事务操作。
示例脚本
主要演示:
- 连接openGauss(PostgreSQL 方式)
- 创建/删除示例表(blog_demo_users、blog_demo_orders)
- 插入/查询/更新/删除数据(参数化 SQL)
- 事务演示:失败回滚与成功提交
关键代码片段(源自opengauss_pg_demo.py):
- 连接获取(mac 上使用 PostgreSQL 驱动 psycopg2)
def get_connection() -> _connection:
"""获取数据库连接(禁用自动提交)
- 从环境变量读取连接信息(OG_HOST/OG_PORT/OG_USER/OG_PASSWORD/OG_DATABASE),若不存在使用默认值。
- 返回 psycopg2 连接对象,并将 autocommit 设为 False,以便进行显式事务控制。
"""
host = os.getenv("OG_HOST", "127.0.0.1")
port = int(os.getenv("OG_PORT", "8888"))
user = os.getenv("OG_USER", "joe")
password = os.getenv("OG_PASSWORD", "123456Zy!")
dbname = os.getenv("OG_DATABASE", "db_tpcc")
conn = psycopg2.connect(host=host, port=port, user=user, password=password, dbname=dbname)
conn.autocommit = False
return conn- 表结构初始化(DDL)
def init_schema(conn: _connection) -> None:
"""初始化示例表结构
- 创建 `blog_demo_users` 表:包含 id(自增主键)、username(唯一)、created_at(默认当前时间)。
- 创建 `blog_demo_orders` 表:包含 id(自增主键)、user_id(外键引用 users.id)、amount、created_at。
- 使用 IF NOT EXISTS 保证重复运行脚本不会报错。
"""
ddl_users = (
"CREATE TABLE IF NOT EXISTS blog_demo_users ("
" id SERIAL PRIMARY KEY,"
" username TEXT NOT NULL UNIQUE,"
" created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP"
")"
)
ddl_orders = (
"CREATE TABLE IF NOT EXISTS blog_demo_orders ("
" id SERIAL PRIMARY KEY,"
" user_id INTEGER NOT NULL REFERENCES blog_demo_users(id),"
" amount NUMERIC(12,2) NOT NULL,"
" created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP"
")"
)
with conn.cursor() as cur:
cur.execute(ddl_users)
cur.execute(ddl_orders)
conn.commit()
print("schema initialized.")- 事务演示(唯一约束冲突回滚+ 正常提交)
def transaction_demo(conn: _connection) -> None:
"""事务演示:失败回滚与成功提交
- 场景一:故意触发唯一约束冲突,验证异常捕获与回滚。
- 场景二:正常插入并提交。
"""
try:
with conn.cursor() as cur:
cur.execute("INSERT INTO blog_demo_users(username) VALUES (%s)", ("alice",))
conn.commit()
print("unexpected: unique insert succeeded (should fail).")
except Exception as e:
conn.rollback()
print(f"rollback on unique violation as expected: {e}")
try:
with conn.cursor() as cur:
cur.execute("INSERT INTO blog_demo_users(username) VALUES (%s) RETURNING id", ("bob",))
bob_id = cur.fetchone()[0]
cur.execute(
"INSERT INTO blog_demo_orders(user_id, amount) VALUES (%s, %s)",
(bob_id, 10.00),
)
conn.commit()
print(f"transaction committed with bob_id={bob_id}")
except Exception as e:
conn.rollback()
print(f"unexpected error, rolled back: {e}")- 入口与执行路径
def main() -> None:
"""脚本入口:连接、初始化、CRUD 与事务演示、可选清理
- 连接数据库并打印版本。
- 初始化表结构并插入示例数据。
- 查询、更新、删除,并演示事务处理。
- 根据命令行参数决定是否清理表结构。
"""
conn = get_connection()
try:
show_server_version(conn)
init_schema(conn)
user_id, order_id = insert_sample_data(conn)
query_data(conn)
update_order_amount(conn, order_id, 5.5)
query_data(conn)
transaction_demo(conn)
query_data(conn)
if len(sys.argv) > 1 and sys.argv[1] == "cleanup":
delete_user(conn, user_id)
cleanup_schema(conn)
finally:
conn.close()
print("connection closed.")运行步骤
- 安装依赖:pip install psycopg2-binary
- 确认数据库连通性(127.0.0.1:8888 用户 joe 密码 123456Zy!,数据库 db_tpcc)。
- 运行脚本:python scripts/opengauss_pg_demo.py
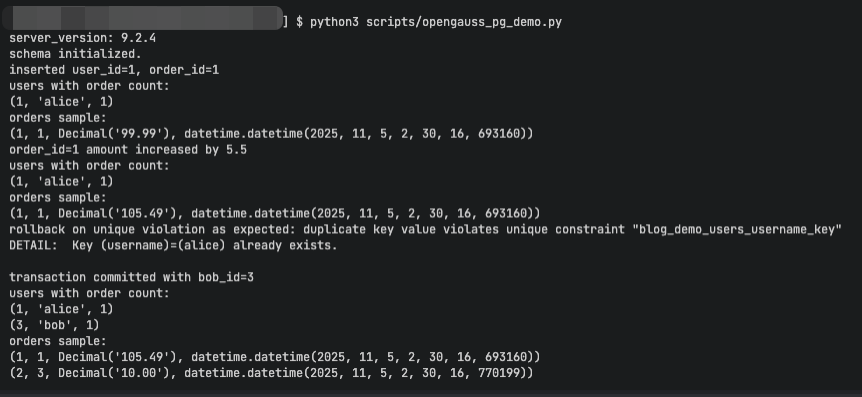
四、****测评维度
易用性与兼容性
- psycopg2 以 PostgreSQL 协议连接 openGauss,无须额外适配即可进行常见 DDL/DML/事务操作。
- 标准SQL 基本兼容;自增字段使用 SERIAL 或 identity 语法均可(本示例使用 SERIAL)。
- 元信息查询(如SHOW server_version)能正常返回版本信息,便于运维与兼容性判断。
事务语义
- 脚本演示了显式事务(禁用自动提交),对异常进行rollback,对成功流程进行 commit,行为符合预期。
- 建议在多语句写入场景中保持显式事务边界,并对异常进行细粒度分类(唯一约束、外键约束、超时等)。
性能与并发(轻量初探)
- 在本地环境下,针对少量行的简单CRUD 响应迅速,延迟低。(受机器与实例配置影响)
**五、****实践展望:****openGauss在应用开发中的未来方向 **
基于本次测评的经验和openGauss社区的发展趋势,我们可以展望openGauss在应用开发领域的几个重要发展方向。

1. AI与数据库的深度融合
openGauss社区正在积极推动AI与数据库技术的深度融合。这主要体现在两个方向:AI4DB(利用AI技术优化数据库管理)和DB4AI(在数据库内原生支持AI计算)。在AI4DB方面,openGauss正在开发智能参数调优、索引推荐和故障预测等能力,有望大幅降低数据库管理难度。在DB4AI方面,openGauss计划支持向量引擎和机器学习算法,使开发者能够直接在数据库内运行AI模型。这些能力对应用开发者意味着更简化的数据架构和更高的开发效率。例如,清华大学李琦副教授团队基于openGauss全密态数据处理框架研发的强安全可验证加密数据搜索算法,解决了数据在密文下的关键字检索等难题。这种创新使得开发者能够在保证数据安全的同时实现复杂的查询功能,无需引入额外的中间件或复杂架构。
2. 云原生与多模数据支持
随着云计算的普及,openGauss也在积极拥抱云原生架构。天翼云发布的TeleDB for openGauss是运营商首个云原生关系型数据库,支持容器化部署,能够提高资源利用率,有效隔离不同应用程序之间的相互影响。这种云原生特性使得openGaus能够更好地适应现代应用开发和部署模式。在未来,我们可以期待openGauss在多模数据支持方面的进一步强化。北京金融科技产业联盟的报告指出,openGauss将支持多种存储和部署形态,具备分布式查询、组件高可用和HTAP(混合事务/分析处理)等关键能力。这对于需要同时处理事务型和分析型工作负载的应用程序来说,将大大简化架构复杂度。

3. 安全机制的持续增强
数据安全日益成为应用开发的核心关切。openGauss在安全方面已经提供了全密态计算、国密算法认证、动态数据脱敏等先进特性。未来,随着隐私保护法规的日益严格,openGauss的安全能力将进一步增强。华中科技大学团队基于openGauss开发的差分隐私医疗诊断辅助查询系统展示了openGaus在隐私保护方面的潜力。该系统采用了国内外首创的差分隐私深度学习方法DPDLDA,在机器学习效果、隐私保护、算法优化等方面实现了优化。这种创新使得医疗机构能够在保护患者隐私的前提下进行数据分析和研究,解决了医疗行业的数据利用难题。
4. 生态工具的丰富与完善
一个健康的数据库生态系统不仅需要强大的内核,还需要丰富的周边工具和支持。openGauss社区正在积极发展生态工具,特别是在异构数据库迁移工具方面。这些工具将帮助开发者更顺畅地从其他数据库(如MySQL、Oracle)迁移到openGauss。此外,openGauss还与众多高校合作,培养数据库人才。华为ICT学院为openGauss社区量身定制了全面的人才培养课程体系,涵盖数据库基础理论、openGauss核心技术、实际项目实践等多个环节。这将为采用openGauss的企业提供更丰富的人才资源,降低招聘和培训成本。
**六、**结语

通过本次基于PostgreSQL驱动的开发测评,我们可以得出结论:openGauss对应用开发者友好,特别是对已有PostgreSQL经验的团队。其良好的协议兼容性使得大多数标准的PostgreSQL驱动和工具可以无缝使用,显著降低了学习成本和技术门槛。随着openGauss在技术创新、生态建设和社区发展上的持续投入,它有望成为企业级应用开发的首选数据库之一。对于正在评估数据库选型的开发团队而言,openGauss提供了性能、安全、可靠性和开发体验的均衡组合,特别是在对自主创新和有供应链安全要求的场景中,更具独特价值。未来,我们期待openGauss在AI集成、云原生架构、开发者工具等方面继续进化,为应用开发者提供更强大、更便捷的数据管理能力。同时,随着社区的发展,我们也希望看到更多的文档、案例和最佳实践,帮助开发者更充分地利用openGauss的先进特性,构建下一代数据驱动的应用程序。作为数据库的创新代表,openGauss正沿着“高性能、高可用、高安全、高智能”的方向稳步前进,有望在数字经济时代发挥越来越重要的作用,为千行万业的数字化转型提供坚实的数据基石。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-12-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
