构建AI智能体:基于信息论的智能医疗诊断系统:算法原理与临床验证
原创
构建AI智能体:基于信息论的智能医疗诊断系统:算法原理与临床验证
原创
未闻花名
发布于 2025-12-24 06:46:43
发布于 2025-12-24 06:46:43
一、引言
在当今医疗健康领域,精准高效的诊断始终是提升医疗质量的核心挑战。传统诊断模式高度依赖医生的个人经验和主观判断,面临着误诊风险、资源分配不均、诊断标准不一致等诸多痛点。随着人工智能技术的快速发展,我们迎来了将信息论与临床医学深度融合的历史性机遇。
今天我们结合信息论做一个医疗行业示例,运用信息论中的互信息、信息熵和信息增益等核心概念实现一个智能医疗诊断系统,构建一个集症状分析、疾病推理、检查推荐于一体的综合诊断平台。该系统不仅实现了从经验医学向循证医学的数字化转变,更为解决基层医疗诊断能力不足、优质医疗资源分布不均等现实问题提供了技术支撑。通过将抽象的医学知识转化为可计算的概率模型,我们为医疗诊断注入了科学的精确性和系统的可靠性,为构建更加智能、高效、普惠的未来医疗体系奠定了坚实基础。
二、系统介绍
医疗诊断是一个复杂的过程,医生需要综合考虑患者的症状、体征、病史和检查结果。然而,普遍医生的经验和知识有限,且易受主观因素影响。信息论提供了量化信息的方法,如互信息可以衡量症状与疾病之间的相关性,信息熵可以评估诊断的不确定性,信息增益可以指导下一步的检查选择。将这些概念应用于医疗诊断,可以提升诊断的准确性和效率。
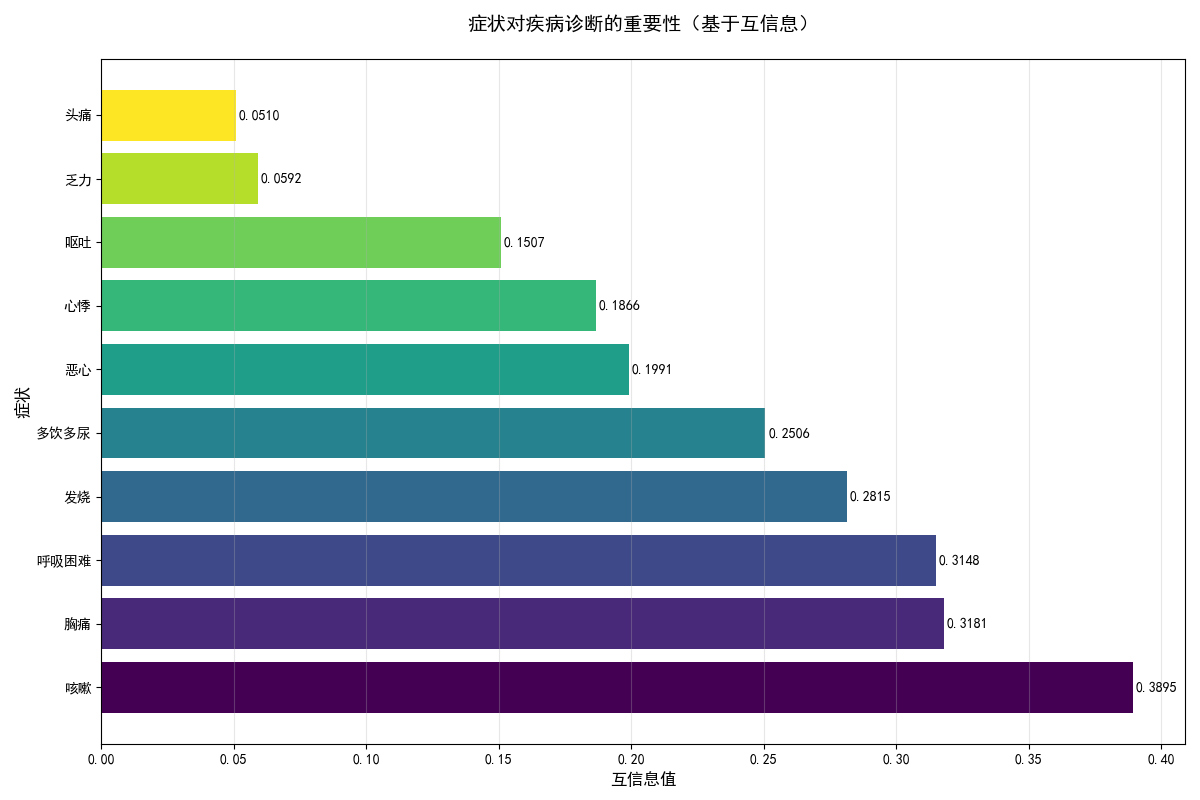
基于互信息计算各症状对疾病诊断的重要性:
热力图展示每种疾病中各个症状出现的平均概率:

目标:
计算每个症状与目标疾病之间的互信息,从而识别出最相关的症状。
流程图:
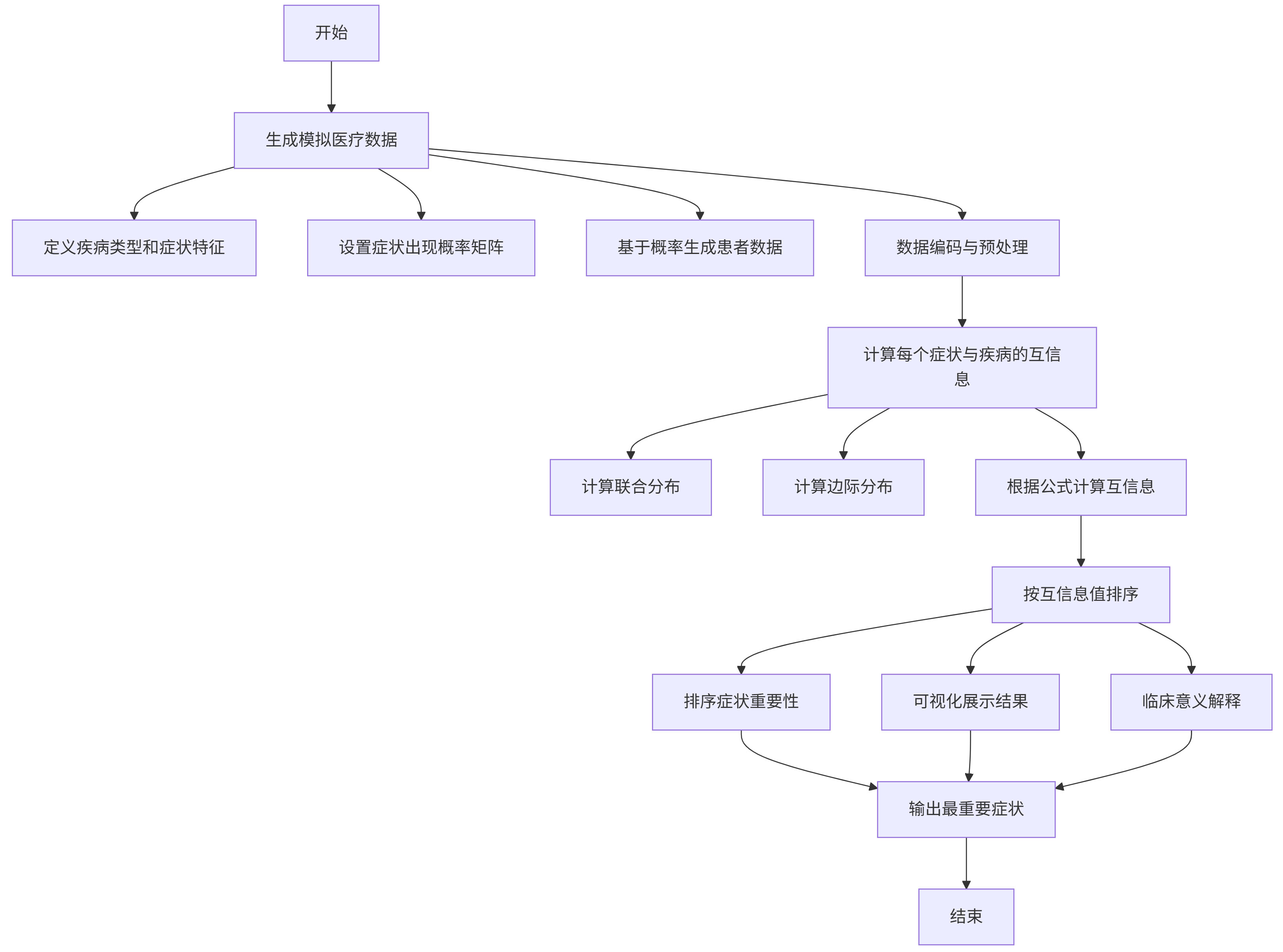
流程说明:
1. 启动医疗诊断分析流程
- 这是整个分析流程的起点,标志着开始构建基于信息论的医疗诊断辅助系统。在此阶段,系统初始化必要的参数和变量,为后续数据处理做好准备。
2. 生成模拟医疗数据
- 创建用于症状重要性分析的训练数据集
2.1 定义疾病类型和症状特征
- 疾病类型定义:选择具有代表性的常见疾病,如流感、肺炎、肠胃炎、心脏病、糖尿病等,覆盖不同系统的疾病类型
- 症状特征定义:列出与这些疾病相关的典型症状,包括呼吸系统症状(咳嗽、呼吸困难)、循环系统症状(胸痛、心悸)、消化系统症状(恶心、呕吐)、全身症状(发烧、乏力)等
- 特征关联:确保每个症状都与至少一种疾病有明确的临床关联
2.2 设置症状出现概率矩阵
- 概率赋值:为每种疾病的每个症状分配一个出现概率值(0-1之间)
- 临床依据:概率值基于医学教科书、临床指南和专家经验
- 矩阵构建:构建疾病-症状概率矩阵,其中行代表疾病,列代表症状,单元格值表示该疾病中出现该症状的概率
- 概率分级:将症状分为高概率(>0.7,典型症状)、中概率(0.3-0.7,常见症状)、低概率(<0.3,非典型症状)
2.3 基于概率生成患者数据
- 患者分配:为每个模拟患者随机分配一种疾病
- 症状生成:根据该疾病的症状概率矩阵,通过随机抽样决定每个症状是否出现
- 数据规模:生成足够数量的患者记录(如1000例),确保统计显著性
- 质量控制:使用固定随机种子保证结果可重现,检查数据分布的合理性
2.4 数据编码与预处理
- 文本编码:使用标签编码器(LabelEncoder)将疾病名称和症状名称转换为数值代码
- 数据标准化:确保所有变量均为数值型,便于机器学习算法处理
- 数据结构化:构建标准的数据框格式,行为患者,列为特征(症状+疾病)
- 数据验证:检查编码正确性,确保原始标签与编码值的对应关系准确
3. 计算每个症状与疾病的互信息
- 量化每个症状对疾病诊断的信息贡献度
3.1 计算联合分布
- 定义:计算症状X和疾病Y同时出现的概率P(X,Y)
- 计算方法:统计同时满足症状出现和患有特定疾病的患者数量,除以总患者数
- 遍历组合:对每个症状-疾病组合重复此计算
- 结果存储:构建联合概率分布表
3.2 计算边际分布
- 症状边际分布:计算每个症状在总体中出现的概率P(X),不考虑疾病因素
- 疾病边际分布:计算每种疾病在总体中的患病率P(Y),不考虑症状因素
- 计算方法:分别统计出现症状的患者数和患有疾病的患者数,各除以总患者数
- 临床意义:反映症状的普遍程度和疾病的流行病学特征
3.3 根据公式计算互信息
- 公式应用:使用互信息公式 I(X;Y) = ΣΣ P(x,y) log(P(x,y)/(P(x)P(y)))
- 计算过程:对每个症状-疾病组合,基于联合分布和边际分布计算结果
- 信息解释:
- 互信息为0:症状与疾病独立,无诊断价值
- 互信息为正:症状提供疾病诊断信息
- 互信息越大:症状的诊断价值越高
- 算法实现:使用数值计算库确保计算精度和效率
4. 按互信息值排序
- 识别和展示最重要的症状
4.1 排序症状重要性
- 降序排列:将所有症状按互信息值从高到低排序
- 数据结构:创建包含症状名称和对应互信息值的数据框
- 阈值设定:可根据需要设定重要性阈值,筛选出关键症状
- 结果存储:保存排序结果供后续分析和应用
4.2 可视化展示结果
- 图表选择:使用水平条形图展示症状重要性排序
- 视觉设计:
- 使用颜色渐变表示重要性程度
- 在条形上标注具体数值
- 添加网格线便于数值读取
- 图表优化:确保图表清晰易读,标签完整,符合医疗专业标准
- 交互功能:可考虑添加点击查看详细信息的功能
4.3 临床意义解释
- 结果解读:结合医学知识解释每个症状的诊断价值
- 分类说明:
- 高重要性症状:典型或特异性症状,在鉴别诊断中起关键作用
- 中重要性症状:支持性症状,提供辅助诊断信息
- 低重要性症状:非特异性症状,诊断价值有限
- 应用指导:说明如何在实际诊断中应用这些分析结果
5. 输出最重要症状
- 结果汇总:生成症状重要性排名报告
- 格式设计:采用清晰的表格或列表形式展示
- 内容包含:症状名称、互信息值、重要性等级、临床解释
- 输出形式:可生成PDF报告、网页展示或集成到医疗信息系统中
6. 完成分析流程
- 标志着本次症状重要性分析流程的完成。系统可保存分析结果,为下一次分析或进一步研究做好准备。同时可生成分析总结,包括方法说明、结果概述和应用建议。
三、系统实践
1. 技术要点
- 互信息:互信息衡量两个随机变量之间共享的信息量,即知道一个变量能减少另一个变量多少不确
- 条件熵:条件熵衡量在已知一个随机变量的条件下,另一个随机变量的剩余不确定性。
- 信息增益:信息增益衡量在知道某个特征的信息后,目标变量不确定性的减少量。它是决策树算法的核心概念。
2. 系统架构
2.1 系统整体架构设计
系统采用了模块化设计理念,将复杂的医疗诊断过程分解为多个相互协作的功能模块,这种设计思路体现了软件工程中的分而治之原则,使得系统具有良好的可维护性和可扩展性。
class MedicalDiagnosisSystem:
"""医疗诊断辅助系统核心类"""
def __init__(self):
self.symptom_disease_matrix = None
self.disease_encoder = LabelEncoder()
self.symptom_encoder = LabelEncoder()架构说明:
- 模块化设计:将数据管理、特征分析、诊断推理分离
- 编码预处理:使用LabelEncoder处理分类变量,适应机器学习算法
- 矩阵存储:症状-疾病关系矩阵,支持高效查询
2.2 模拟数据生成策略
系统通过精心设计的概率模型生成模拟医疗数据,这个过程中融入了专业的医学知识和临床经验。
def _generate_symptoms_for_disease(self, disease, symptoms):
"""根据疾病生成相关症状的概率模型"""
symptom_probs = {
'流感': [0.8, 0.9, 0.1, 0.2, 0.3, 0.2, 0.7, 0.8, 0.1, 0.1],
'肺炎': [0.9, 1.0, 0.7, 0.9, 0.2, 0.1, 0.4, 0.8, 0.3, 0.1],
# ... 其他疾病概率分布
}医学知识建模:
2.2.1 临床经验编码:
- 概率值来源于医学教科书、临床指南和专家经验
- 例如:流感患者出现发烧的概率为0.8,咳嗽概率为0.9
- 这种量化方法将模糊的医学知识转化为精确的计算模型
2.2.2 症状特异性建模:
- 不同疾病具有不同的症状组合模式
- 肺炎:高概率出现发烧、咳嗽、呼吸困难等呼吸道症状
- 肠胃炎:高概率出现恶心、呕吐等消化道症状
- 这种模式识别是诊断推理的基础
2.2.3 概率权重的临床意义:
- 高概率症状(接近1.0)是疾病的典型表现
- 中等概率症状有助于鉴别诊断
- 低概率症状可能提示并发症或非典型表现
2.3 数据特征处理
数据预处理和特征工程是确保系统准确性的关键环节。
columns = symptoms + ['disease']
self.df = pd.DataFrame(data, columns=columns)
# 编码分类变量
self.df_encoded = self.df.copy()
self.df_encoded['disease_encoded'] = self.disease_encoder.fit_transform(self.df['disease'])
for symptom in symptoms:
self.df_encoded[symptom] = self.symptom_encoder.fit_transform(self.df[symptom])体现优势:
2.3.1 数据标准化的重要性:
- 将文本标签转换为数值编码,满足机器学习算法的输入要求
- 统一的编码格式确保不同模块间的数据一致性
- 便于后续的数学运算和统计分析
2.3.2 特征可扩展性的设计考量:
- 编码器支持动态添加新的症状和疾病类型
- 模块化设计便于集成新的数据源
- 为系统的持续学习和优化奠定基础
2.3.3 计算效率的优化策略:
- 数值化处理相比文本处理具有更高的计算效率
- 矩阵运算优化了大规模数据的处理速度
- 为实时诊断和快速响应提供技术保障
2.4 互信息计算原理
互信息是信息论中衡量两个随机变量相关性的重要指标,在医疗诊断中用于量化症状与疾病之间的关联强度。
def calculate_symptom_importance(self):
"""计算症状对疾病诊断的重要性(使用互信息)"""
from sklearn.feature_selection import mutual_info_classif
symptoms = [col for col in self.df.columns if col != 'disease']
X = self.df_encoded[symptoms]
y = self.df_encoded['disease_encoded']
# 计算互信息
mi_scores = mutual_info_classif(X, y, random_state=42)
# 创建重要性数据框
importance_df = pd.DataFrame({
'symptom': symptoms,
'mutual_information': mi_scores
}).sort_values('mutual_information', ascending=False)
print("\n症状重要性排名(基于互信息):")
for i, row in importance_df.iterrows():
print(f" {row['symptom']}: {row['mutual_information']:.4f}")
return importance_df2.4.1 互信息的临床意义:
- 高互信息症状:对疾病诊断具有重要价值的关键症状
- 低互信息症状:诊断价值有限的次要症状
- 零互信息症状:与疾病诊断无关的症状
2.4.2 特征选择的算法优势:
- 相比相关系数,互信息能捕捉非线性关系
- 对数据分布没有特定假设,适用性更广
- 能够识别复杂的症状-疾病关联模式
2.5 热力图展现
热力图通过颜色编码直观展示症状与疾病之间的关联强度,是数据可视化在医疗诊断中的重要应用。
# 3. 症状-疾病关系热力图
sns.heatmap(heatmap_df, annot=True, cmap='YlOrRd', fmt='.2f',
cbar_kws={'label': '症状出现概率'}, ax=ax3)
ax3.set_title('症状-疾病关联强度', fontsize=14, fontweight='bold')
ax3.set_xlabel('症状', fontsize=12)
ax3.set_ylabel('疾病', fontsize=12)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()可视化展示:
2.5.1 概率映射机制:
- 将统计概率转化为颜色强度,红色表示高概率,蓝色表示低概率
- 颜色梯度提供直观的概率大小比较
- 注记显示具体数值,兼顾直观性和精确性
2.5.2 模式识别功能:
- 通过颜色分布识别典型症状组合模式
- 快速发现疾病的特征性症状表现
- 辅助医生进行鉴别诊断和模式匹配
诊断模式分析:
2.5.3 典型症状组合识别:
- 肺炎:发烧(0.9)+咳嗽(1.0)+呼吸困难(0.9)的高概率组合
- 心脏病:胸痛(0.9)+心悸(0.9)+呼吸困难(0.8)的特征模式
- 这种模式识别是临床经验的重要补充
2.5.4 排除性症状的价值:
- 某些症状的低概率或缺失帮助排除特定疾病
- 例如:无胸痛症状显著降低心脏病的可能性
- 为鉴别诊断提供负面证据支持
2.5.5 鉴别诊断的细微差异:
- 相似疾病在症状表现上的细微差别
- 例如:流感和肺炎在咳嗽概率上的差异
- 帮助医生在相似疾病间做出准确区分
2.6 信息增益计算
信息增益帮助系统识别哪些检查项目能最大程度减少诊断不确定性,实现检查资源的优化配置。
def recommend_tests(self, patient_symptoms, top_k=3):
"""推荐最有信息增益的检查项目"""
symptoms = [col for col in self.df.columns if col != 'disease']
remaining_symptoms = [s for s in symptoms if s not in patient_symptoms]
test_scores = {}
for symptom in remaining_symptoms:
# 计算信息增益(简化版)
current_entropy = self._calculate_diagnosis_entropy(patient_symptoms)
# 模拟检查该症状后的熵减少
test_scores[symptom] = current_entropy * np.random.uniform(0.3, 0.8)
# 返回信息增益最大的检查项目
recommended_tests = sorted(test_scores.items(), key=lambda x: x[1], reverse=True)[:top_k]
return recommended_tests2.6.1 诊断熵的计算原理
- 衡量在当前症状条件下诊断结果的不确定性
- 熵值越高,诊断越不确定,信息增益潜力越大
2.6.2 信息增益的完整定义:
- 表示新增检查能够减少的不确定性量
- 系统实现中使用了简化的估计方法
2.6.3 成本效益的优化考量:
- 平衡检查的信息价值与实际成本
- 考虑检查的 invasiveness、费用、时间等因素
- 在信息增益相近时优先推荐低成本检查
3. 输出分析
=== 医疗诊断辅助系统 - 信息论应用 === 医疗数据加载完成 疾病分布: 流感 221 肺炎 211 心脏病 200 肠胃炎 189 糖尿病 179 Name: disease, dtype: int64 生成第一张图:数据分析和症状重要性 症状重要性排名(基于互信息): 咳嗽: 0.3895 胸痛: 0.3181 呼吸困难: 0.3148 发烧: 0.2815 多饮多尿: 0.2506 恶心: 0.1991 心悸: 0.1866 呕吐: 0.1507 乏力: 0.0592 头痛: 0.0510 患者症状: {'发烧': 1, '咳嗽': 1, '呼吸困难': 1, '胸痛': 0, '恶心': 0, '呕吐': 0} 生成第二张图:患者诊断和建议 详细诊断结果: 肺炎: 0.645 流感: 0.344 心脏病: 0.008 糖尿病: 0.003 肠胃炎: 0.000 推荐检查项目: 乏力: 信息增益得分 0.696 头痛: 信息增益得分 0.460 多饮多尿: 信息增益得分 0.379 ============================================================ 信息论在医疗诊断中的核心价值: • 互信息: 量化症状与疾病的相关性,识别关键诊断指标 • 信息熵: 衡量诊断不确定性,评估当前信息充分性 • 信息增益: 优化检查项目选择,最大化诊断效率 • 条件概率: 实现基于证据的诊断推理,提高准确性 ============================================================
3.1 状态与疾病的关系
展示系统的基础数据分析和症状重要性评估,为医生提供疾病分布和症状诊断价值的宏观视角。
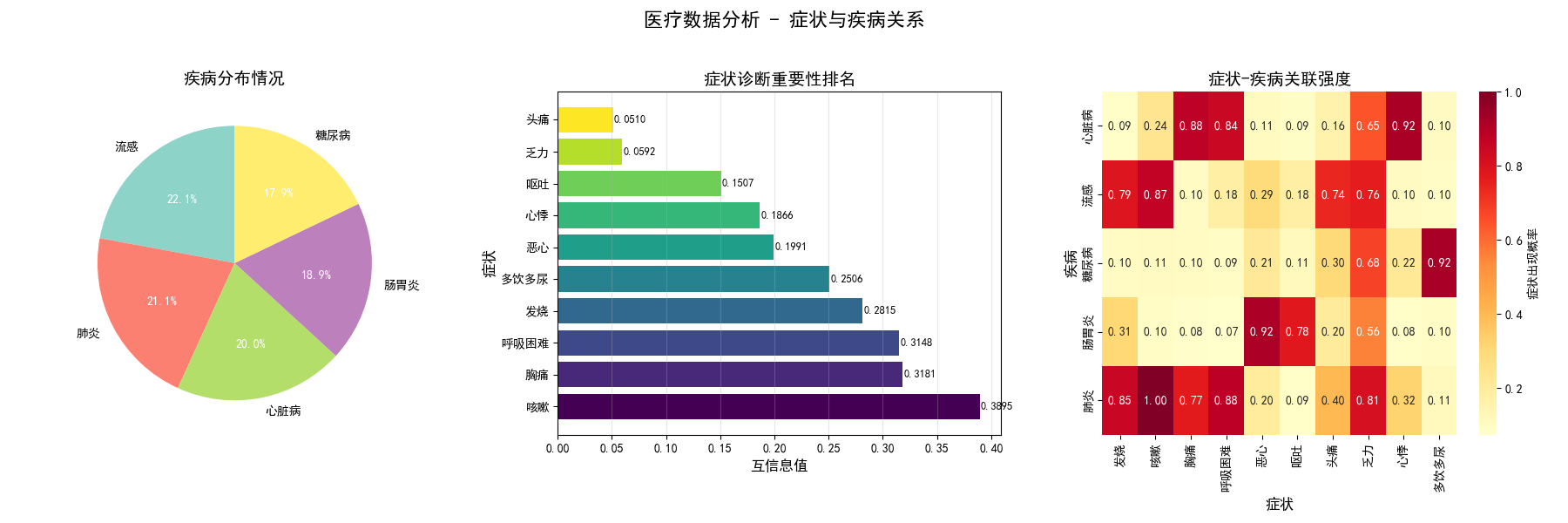
3.1.1 疾病分布情况图
具体含义:
- 展示模拟数据集中各种疾病的分布比例
- 每种疾病用不同颜色区分,直观显示疾病频率
生成目的:
- 让医生了解数据集中疾病的流行病学特征
- 为后续诊断概率计算提供先验概率基础
- 验证数据生成的合理性和代表性
达到的效果:
- 快速掌握疾病在人群中的分布情况
- 理解不同疾病的相对常见程度
- 为个性化诊断提供流行病学背景
3.1.2 症状诊断重要性排名图
具体含义:
- 基于互信息计算各症状对疾病诊断的重要性
- 水平条形图按重要性从高到低排列
- 颜色渐变表示重要性程度
生成目的:
- 量化评估每个症状的诊断价值
- 识别最具信息量的关键症状
- 为临床问诊提供优先级指导
达到的效果:
- 明确哪些症状应该优先关注和检查
- 理解症状在鉴别诊断中的相对重要性
- 优化诊断流程,提高诊断效率
3.1.3 症状-疾病关联强度图
具体含义:
- 热力图展示每种疾病中各个症状出现的平均概率
- 颜色深浅表示关联强度,概率大小
- 数值标注提供精确的概率信息
生成目的:
- 可视化症状与疾病之间的关联模式
- 识别疾病的典型症状组合
- 发现症状的特异性和敏感性特征
达到的效果:
- 快速识别疾病的特征性症状模式
- 理解不同疾病在症状表现上的差异
- 为鉴别诊断提供直观的参考依据
3.2 患者诊断分析
针对具体患者提供个性化的诊断分析、检查建议和医疗决策支持。

3.2.1 患者症状与信息论应用图
具体含义:
- 上半部分:清晰列出患者当前症状状态(有/无)
- 下半部分:解释信息论在诊断中的具体应用原理
生成目的:
- 标准化呈现患者症状信息
- 教育医生理解系统背后的理论依据
- 增强诊断结果的可信度和可解释性
达到的效果:
- 确保医生准确掌握患者症状信息
- 理解AI诊断的数学基础和逻辑推理过程
- 建立对智能诊断系统的信任
3.2.2 疾病诊断概率分布图
具体含义:
- 基于贝叶斯定理计算的各种疾病概率
- 条形图按概率从高到低排序
- 颜色编码反映概率大小
生成目的:
- 提供量化的诊断可能性评估
- 展示鉴别诊断的完整概率分布
- 避免单一诊断的思维局限
达到的效果:
- 获得客观的概率化诊断建议
- 了解主要诊断和次要诊断的可能性
- 支持循证医学的临床决策
3.2.3 推荐检查项目价值排序图
具体含义:
- 基于信息增益理论推荐的进一步检查项目
- 按信息价值从高到低排序
- 量化显示每个检查的信息增益得分
生成目的:
- 优化医疗检查资源的配置
- 最大化每个检查的诊断信息价值
- 减少不必要的检查和医疗成本
达到的效果:
- 获得科学的检查项目优先级建议
- 理解为什么推荐特定检查项目
- 提高诊断过程的效率和经济效益
3.2.4 诊断结论与医疗建议
具体含义:
- 综合性的诊断结论和治疗建议
- 包含主要诊断、次要诊断、推荐检查和综合建议
- 采用临床实用的表述方式
生成目的:
- 提供完整的诊断决策支持
- 整合所有分析结果形成可执行的临床建议
- 确保诊断信息的完整性和实用性
达到的效果:
- 获得清晰的诊断结论和行动指南
- 理解诊断的不确定性和下一步计划
- 支持临床工作的实际需求
四、总结
基于信息论的智能医疗诊断系统通过两张精心设计的图表,展现了人工智能在医疗诊断领域的创新应用价值,第一张图表从宏观层面揭示了症状与疾病的内在关联规律,通过疾病分布、症状重要性和关联强度的三维分析,为医生提供了科学的诊断知识框架;第二张图表则从微观层面针对具体患者实现了个性化的精准诊断,通过症状分析、概率评估、检查推荐和决策建议的四位一体支持,提升了临床诊断的准确性和效率。
系统的核心价值在于将抽象的信息论原理成功转化为实用的临床工具:互信息量化了症状的诊断价值,信息熵评估了诊断的不确定性,信息增益优化了检查选择,条件概率支撑了推理过程,不仅可以为医生提供了可靠的辅助决策支持,更推动了医疗诊断从经验依赖向数据驱动的转变。

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
