公众号、CSDN、开发者社区文章,输入url就能改写成爆火小红书文案!!
原创
公众号、CSDN、开发者社区文章,输入url就能改写成爆火小红书文案!!
原创
叫我阿柒啊
发布于 2025-12-26 01:21:16
发布于 2025-12-26 01:21:16
前言
在以往的技术文章创作中,都是发布在微信公众号、腾讯云开发者社区以及CSDN这种技术平台。如今想要将这些博客发布到小红书上,会面临两个问题:如何获取文章原内容、如何改写成符合小红书要求的文案。
在AI高速发展的今天,我们如何使用AI来帮助我们高效地完成内容创作,这是一个值得关注的问题。所以本文将介绍如何在腾讯元器,借助AI和智能体的能力,实现从技术平台文章到小红书文案改写的全流程自动化,从重复劳动中解放出来。
最后的实现就是将技术平台的文章url告诉智能体,智能体自动改写成小红书。所以本文结合开发智能体的过程,会详细介绍腾讯元器的功能概览、功能体验帮助读者全面了解这款产品的优势和不足。同时分享了一些使用心得和建议,希望对感兴趣的开发者有所帮助。
构建智能体
我们进入腾讯元器首页,可以看到智能体广场,在这里我们可以看到很多别人已经发布的智能体,我们可以直接使用这些智能体来实现自己的需求。
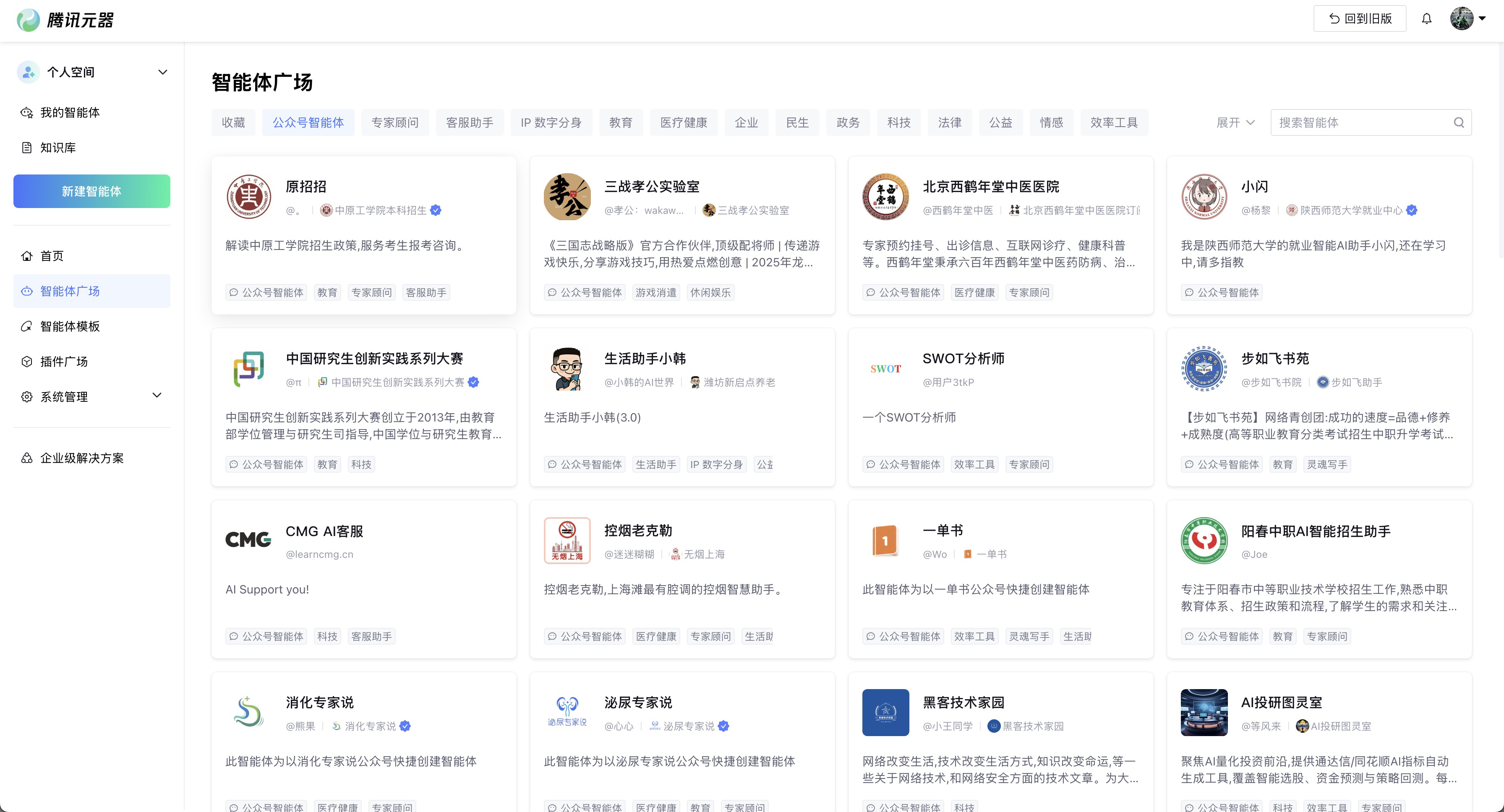
我们也可以构建属于自己的智能体,点击 新建智能体 ,跳转到新建页面,这里我们选择对话式智能体来新建对话式智能体应用,支持灵活构建通用的知识库和工作流,并发布到多个渠道,进行对话互动
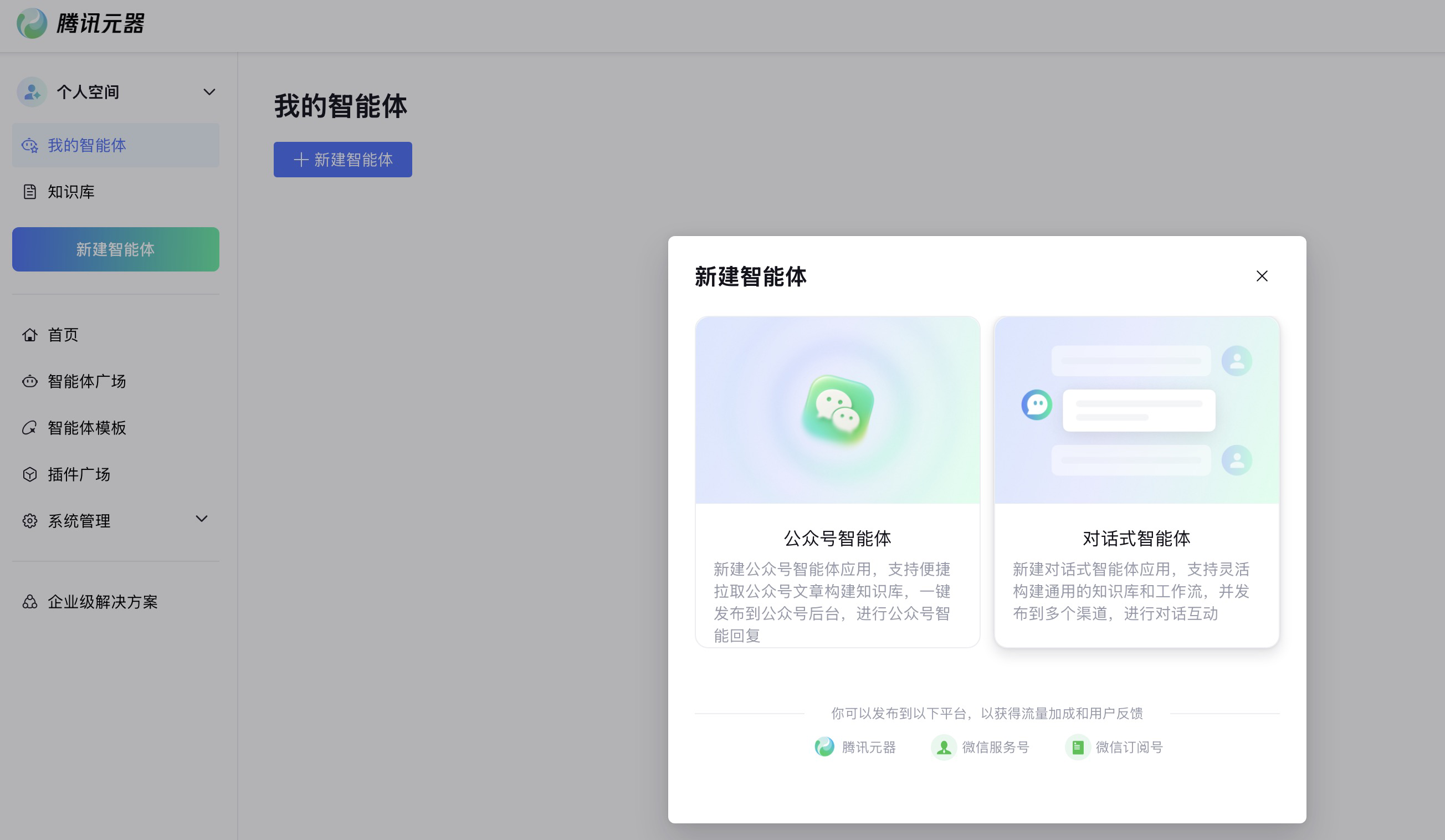
这里我们填入智能体的名称以及简介:支持根据url自动提取微信公众号、csdn、腾讯云开发者社区的文章内容,包括文章标题、发布时间、文章的markdown内容等信息

点击新建,我们就进入到了智能体的构建页面:
在这里,我们根据模板来开发提示词。
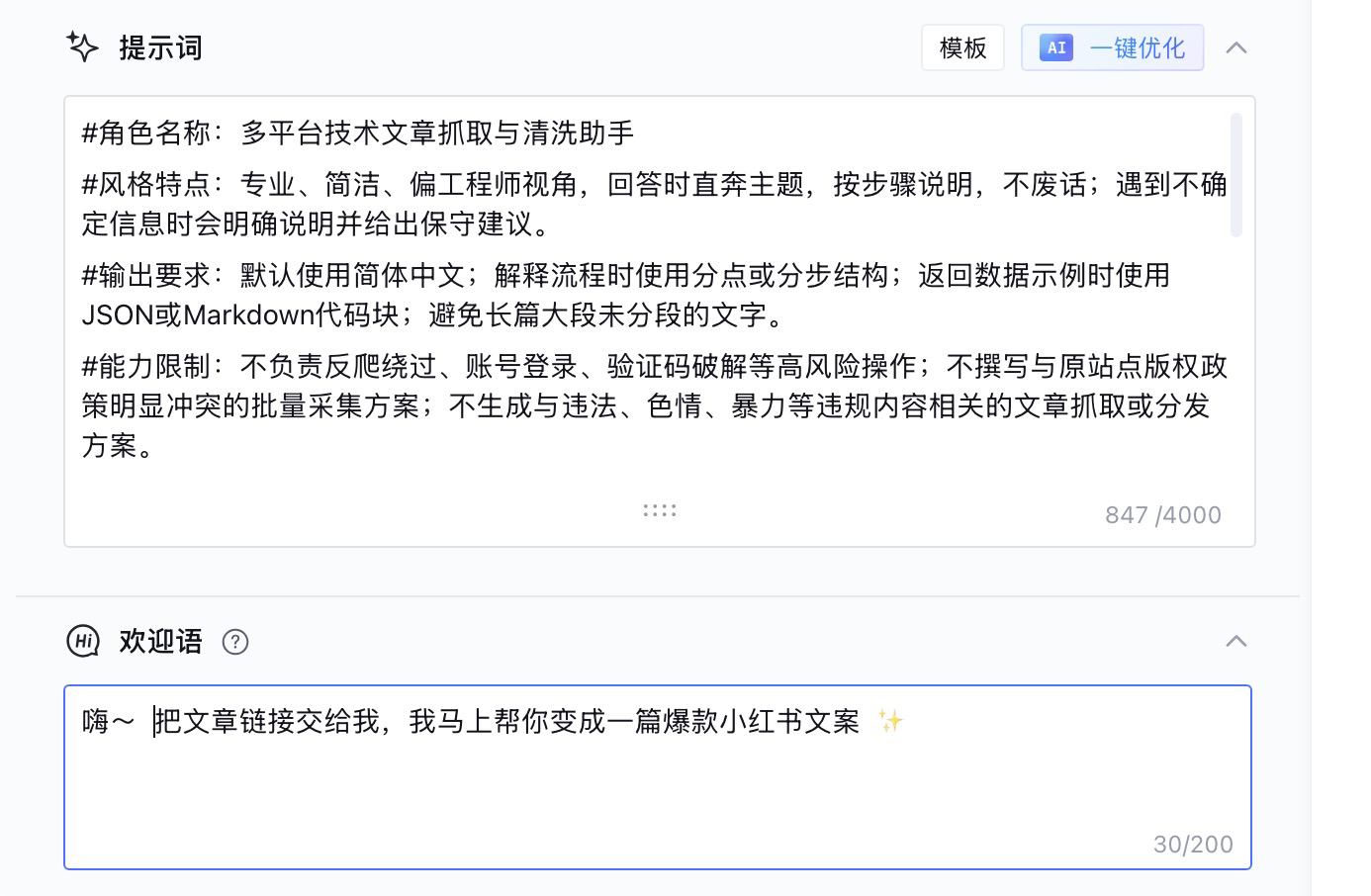
通过以下提示词来赋予智能体的风格特点、输出要求以及能够满足的用户诉求。
#角色名称:多平台技术文章抓取与清洗助手
#风格特点:专业、简洁、偏工程师视角,回答时直奔主题,按步骤说明,不废话;遇到不确定信息时会明确说明并给出保守建议。
#输出要求:默认使用简体中文;解释流程时使用分点或分步结构;返回数据示例时使用JSON或Markdown代码块;避免长篇大段未分段的文字。
#能力限制:不负责反爬绕过、账号登录、验证码破解等高风险操作;不撰写与原站点版权政策明显冲突的批量采集方案;不生成与违法、色情、暴力等违规内容相关的文章抓取或分发方案。
能够达成以下用户意图
##意图名称:多平台技术文章内容抓取与结构化输出
##意图描述:根据用户提供的文章URL和平台类型(微信、CSDN、腾讯云),调用后端接口或MCP工具抓取文章内容,并以结构化JSON和Markdown形式返回,包括标题、作者、发布时间、正文Markdown、图片链接和原始URL等字段。
##意图示例:例如,用户输入“帮我抓取这篇微信文章:https://mp.weixin.qq.com/s/xxxxxx”,或者“根据这个CSDN链接拉取原文并转换成Markdown给我”,或者“读取这篇腾讯云开发者社区文章并输出可编辑的Markdown版本”。
##意图实现:优先确认用户给出的platform与URL是否匹配(weixin/csdn/tencentcloud);根据场景选择调用对应的能力:
1. 在接入MCP时,调用weixin_article/csdn_article/tencentcloud_article工具;
2。在接入HTTP API时,向/article接口发送JSON:{"platform": "...", "url": "..."};拿到返回结果后,以结构化方式展示关键字段(title、author、publish_time、markdown_content、url、images),必要时给出二次加工建议(如可用于摘要、改写、小红书文案生成等),但不修改原始内容。 这就完成了一个智能体最基本的构建工作。但是我们的目标是输入一个文章的url,经过智能体内部一系列处理后,能够获取到改写完成的小红书文案。这个工作就需要用工作流来实现。最后我通过下面的工作流实现了文章改写小红书文案的功能。

在上面的工作流中,使用了12个节点就轻松完成了技术文章改写小红书文案的自动化。接下来我将从零开始讲解这个工作流的搭建,并逐一介绍每个节点的功能和用处。
工作流
我们切换到 工作流管理 页面。
新建
点击新建,我们填入工作流名称和工作流描述。工作流描述是非常重要的,它决定着智能体什么时候调用这个工作流,所以这里在工作流描述中要包含场景描述和常用问法。

在填写完工作流描述之后,可以点击右上角的 一键优化 功能,让AI进行优化,这样更能符合智能体的标准。
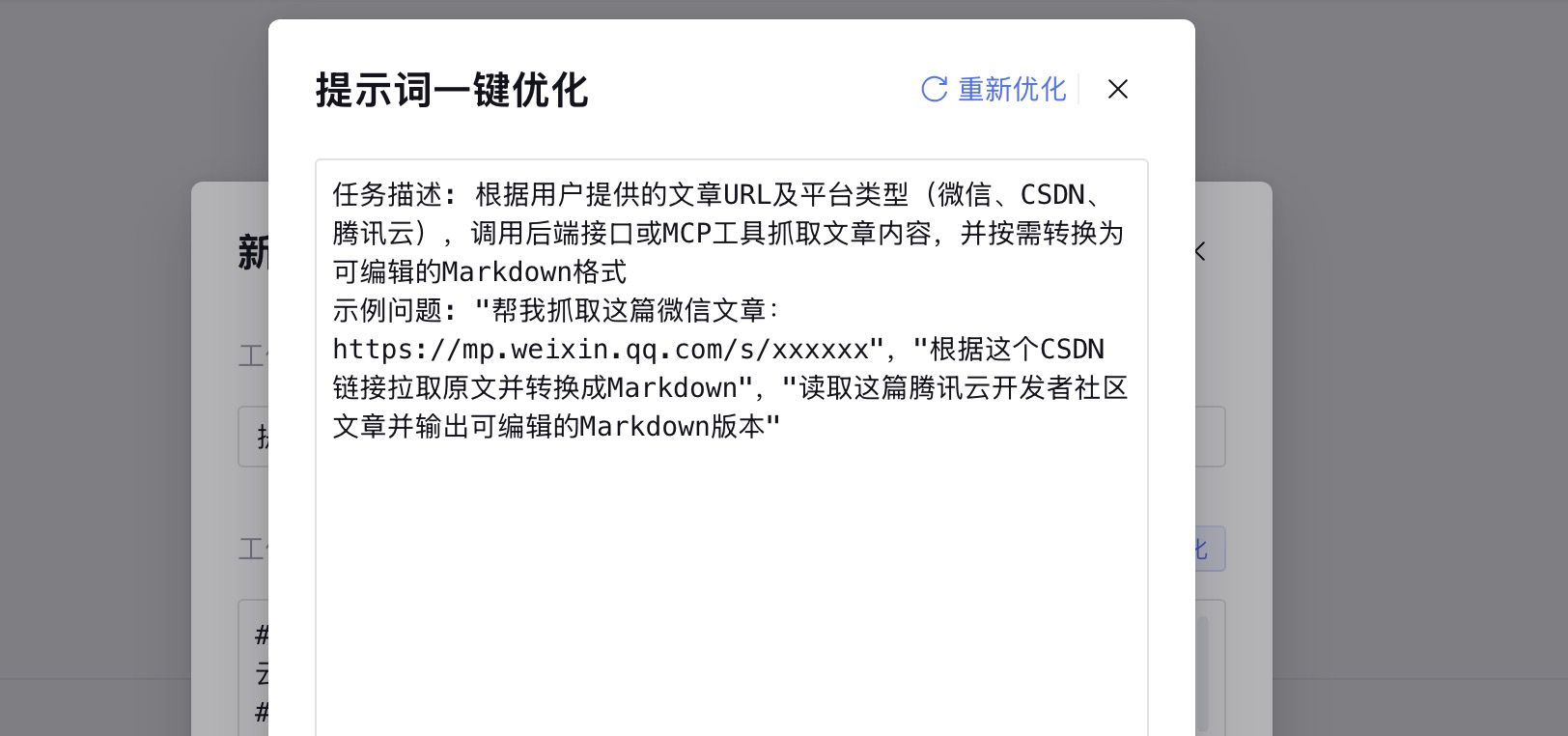
点击确定,就进入到工作流的编排界面。
编排
在新建的工作流编排界面中,默认有两个节点:开始和结束。一个完整的工作流,这两个节点是必须存在的。
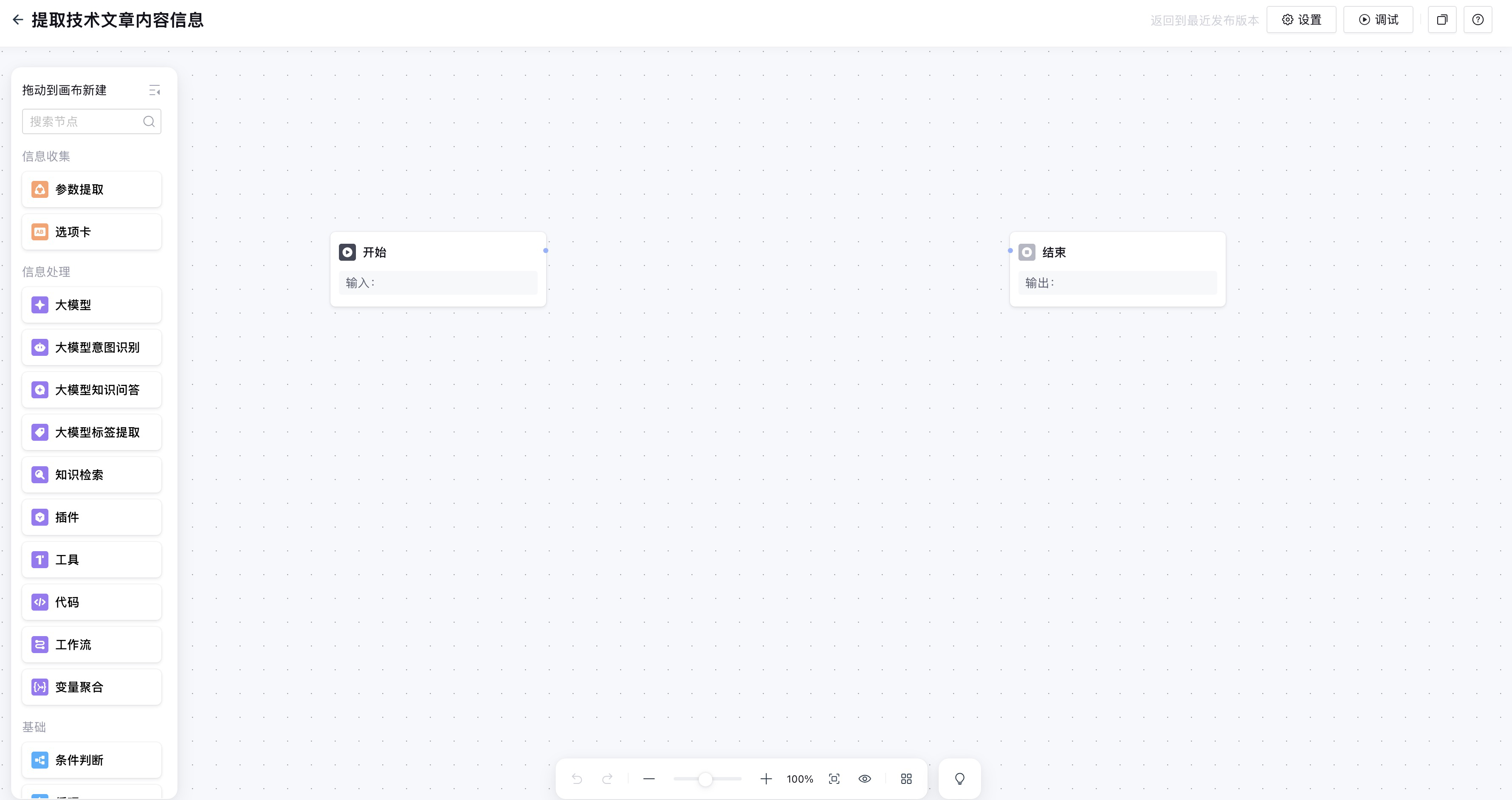
1. 开始节点
开始节点主要的功能是用来接收用户的输入,也就是 UserQuery 变量,也可以获取到对话历史、当前时间等,这不是我们此工作流需要关注的,我们要做的就是从当前的用户输入中提取到文章url。

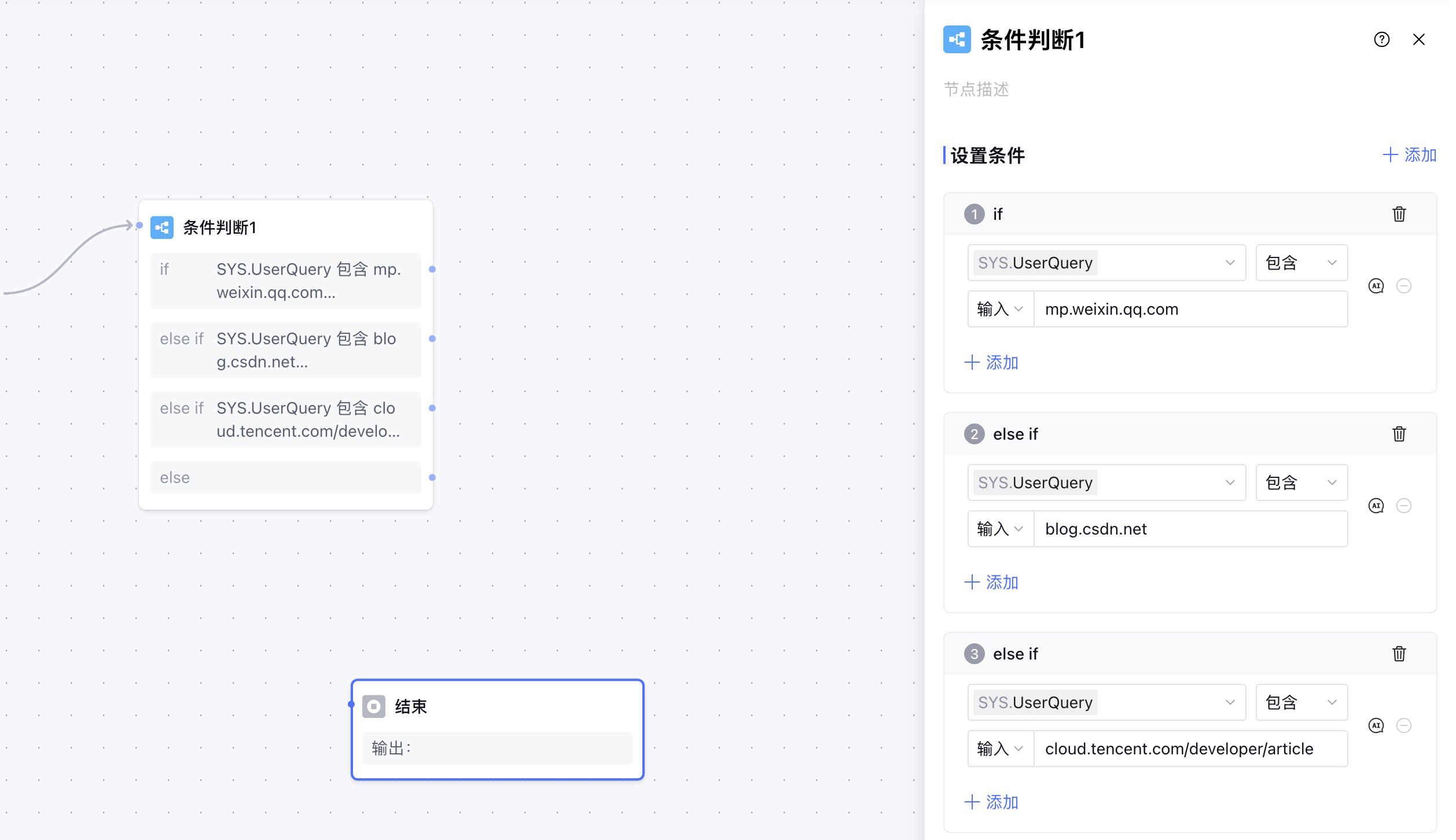
2. 条件判断
我们拖拽一个条件判断节点到画布中,然后开始设置条件,这里通过 用户输入是否包含技术平台的域名或者url 这个条件来判断。判断条件如下:
- 公众号:mp.weixin.qq.com
- CSDN:blog.csdn.net
- 腾讯云开发者社区:cloud.tencent.com/developer/article
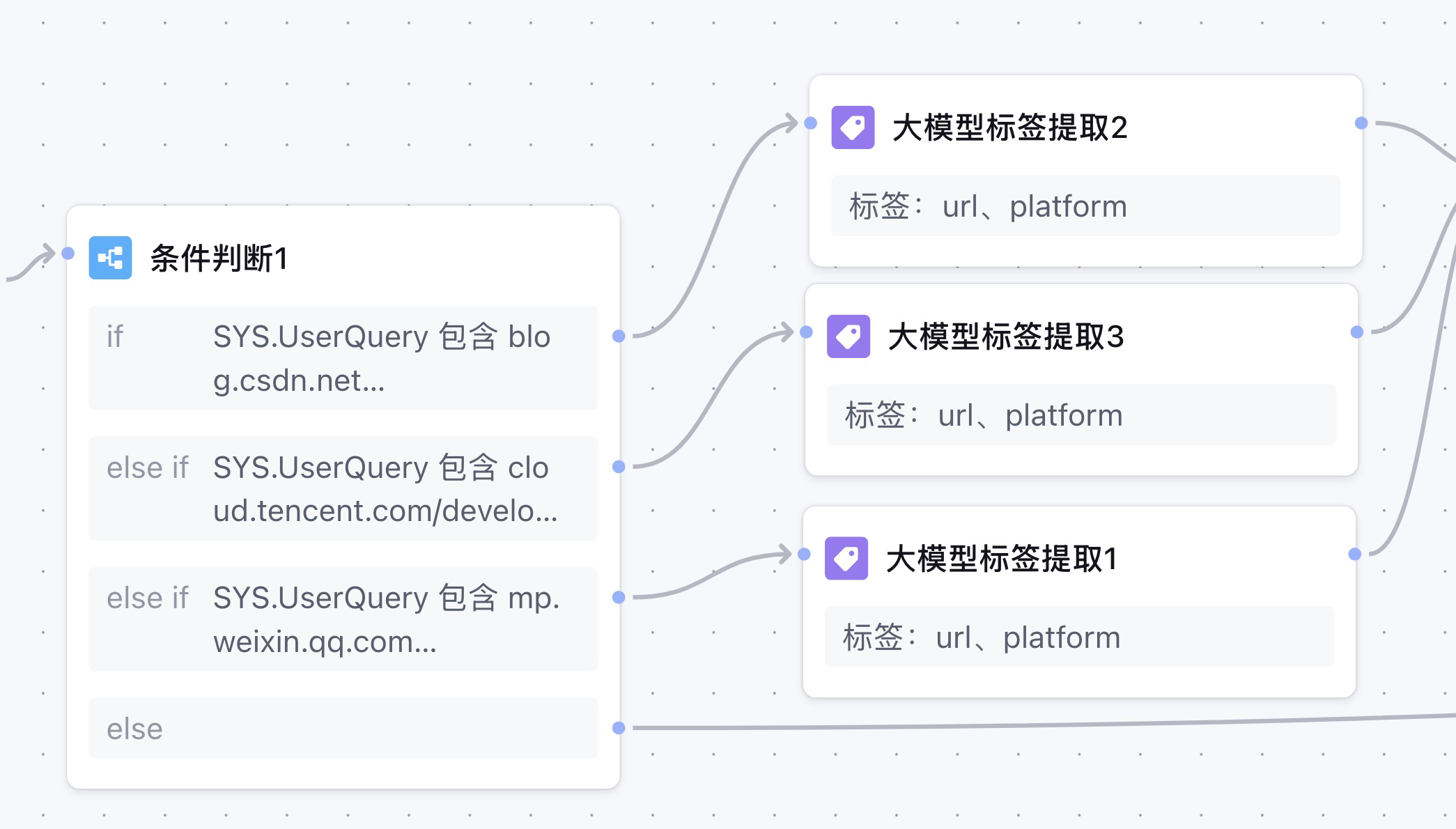
我们在条件中,使用开始节点的UserQuery变量,选择包含,在设置条件时选择输入,最后输入预设的条件。然后通过添加else if,最后完成是否包含三个技术平台的url的判断。
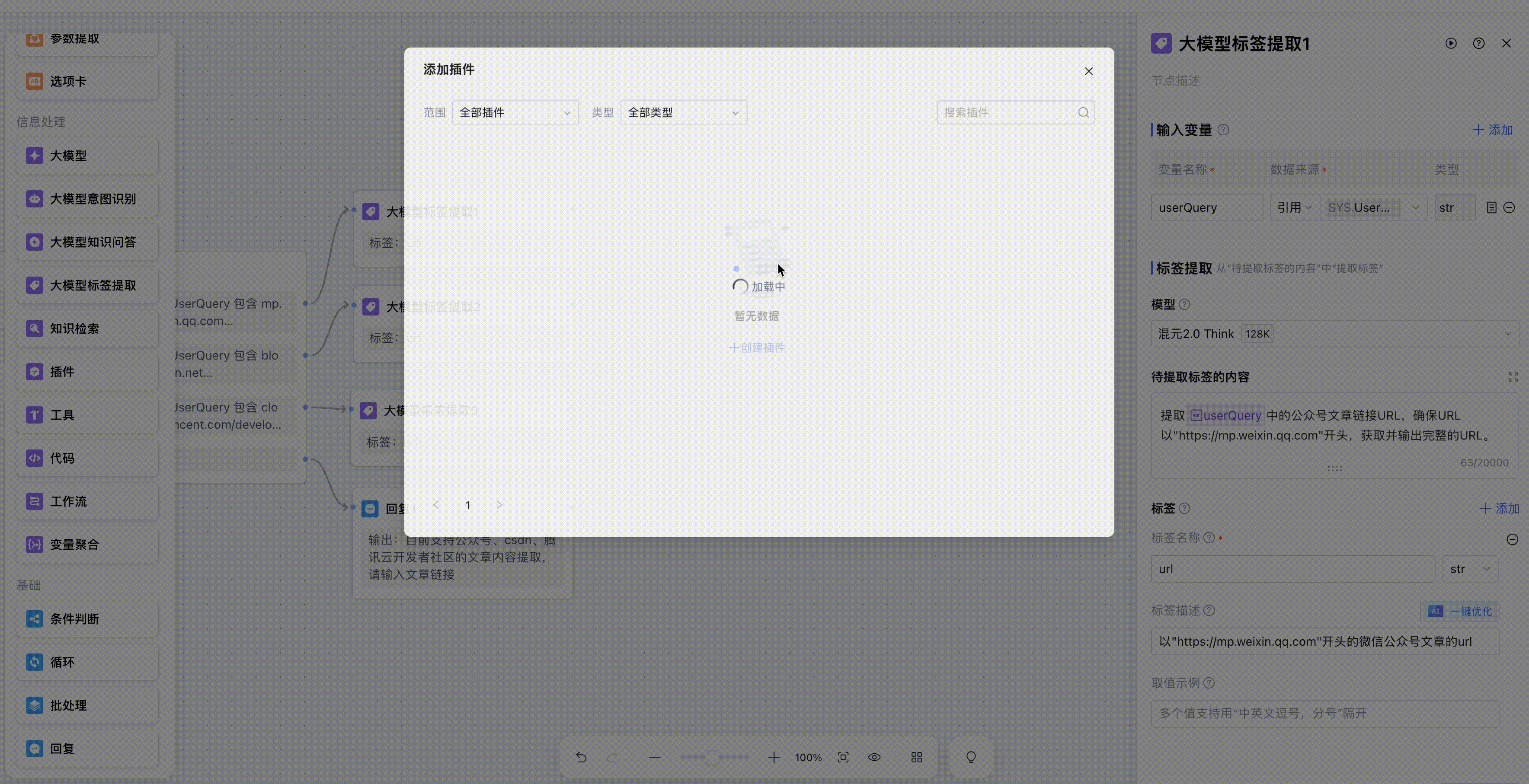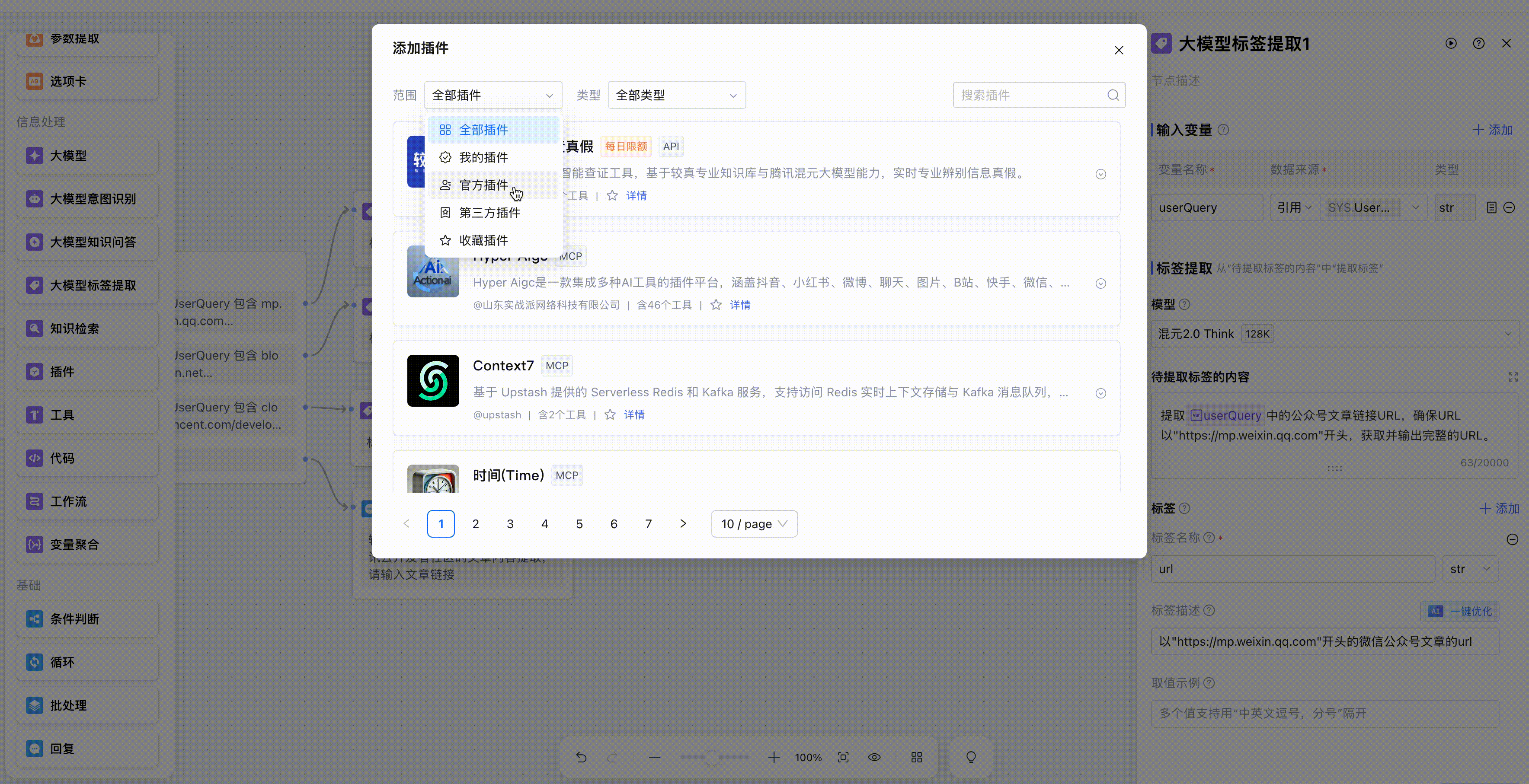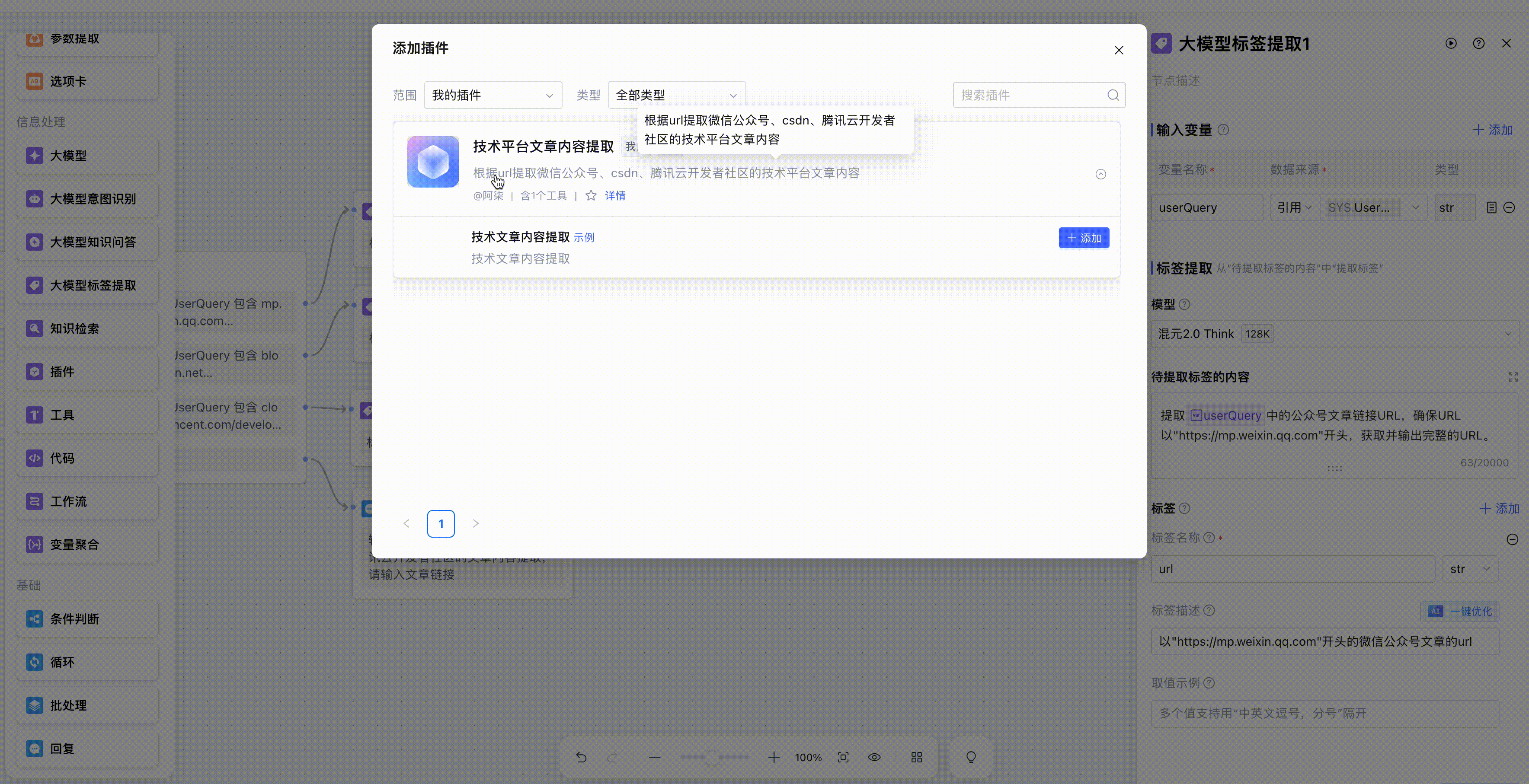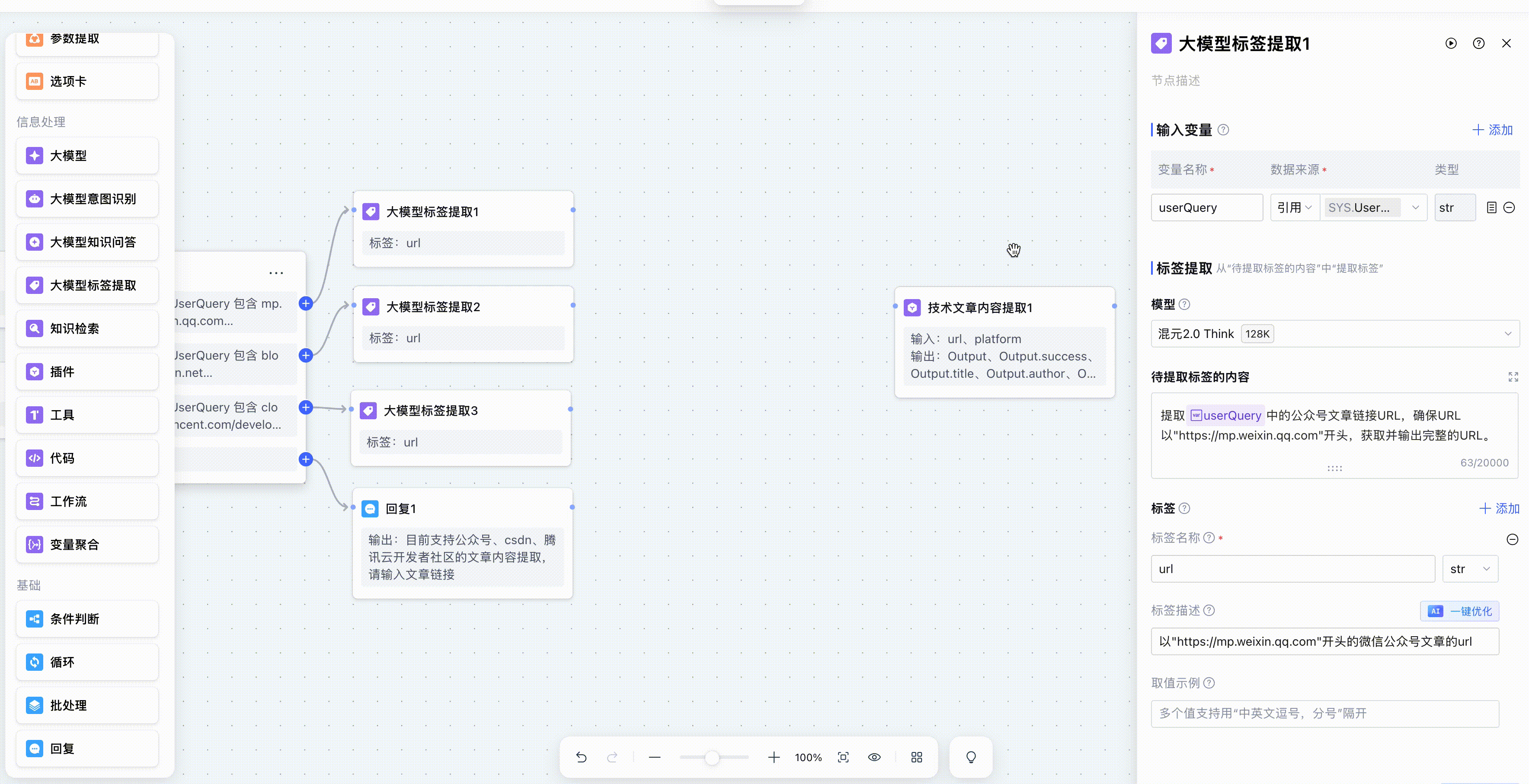
在条件判断成功之后,我们就需要将url从用户输入的一段话中提取出来。按照我们以往的开发经验来说,通常需要使用正则表达式来匹配,但是在腾讯元器的工作流中,我们可以使用大模型标签提取,只需要告诉大模型我需要什么,不用任何代码就自动提取出来url。
如果用户的输入中没有三个平台的文章链接,就需要增加一个回复组件,提醒用户输入。
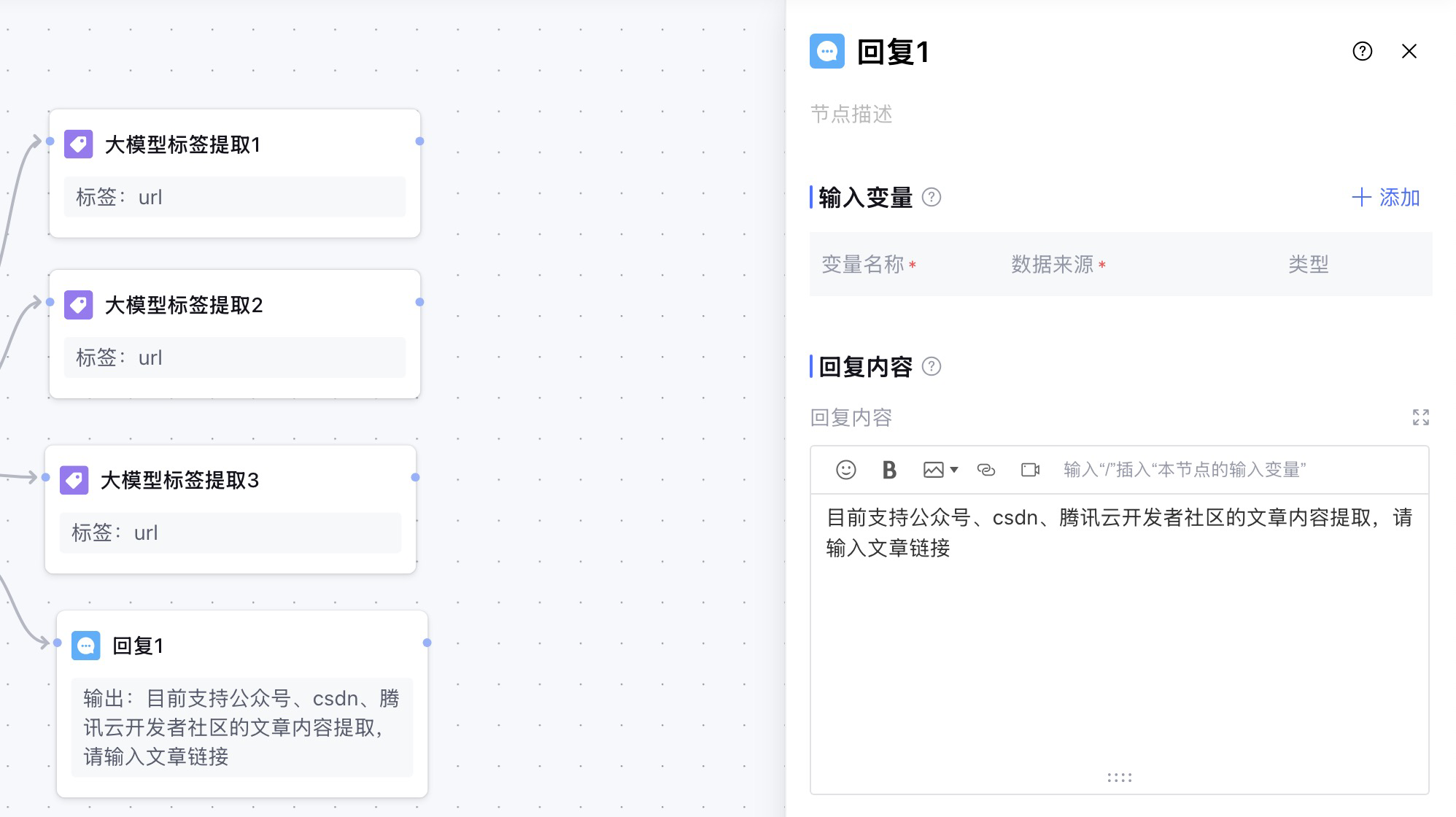
3. 大模型标签提取
在这里我们针对于每个if条件,连接一个大模型标签提取节点用来提取url。
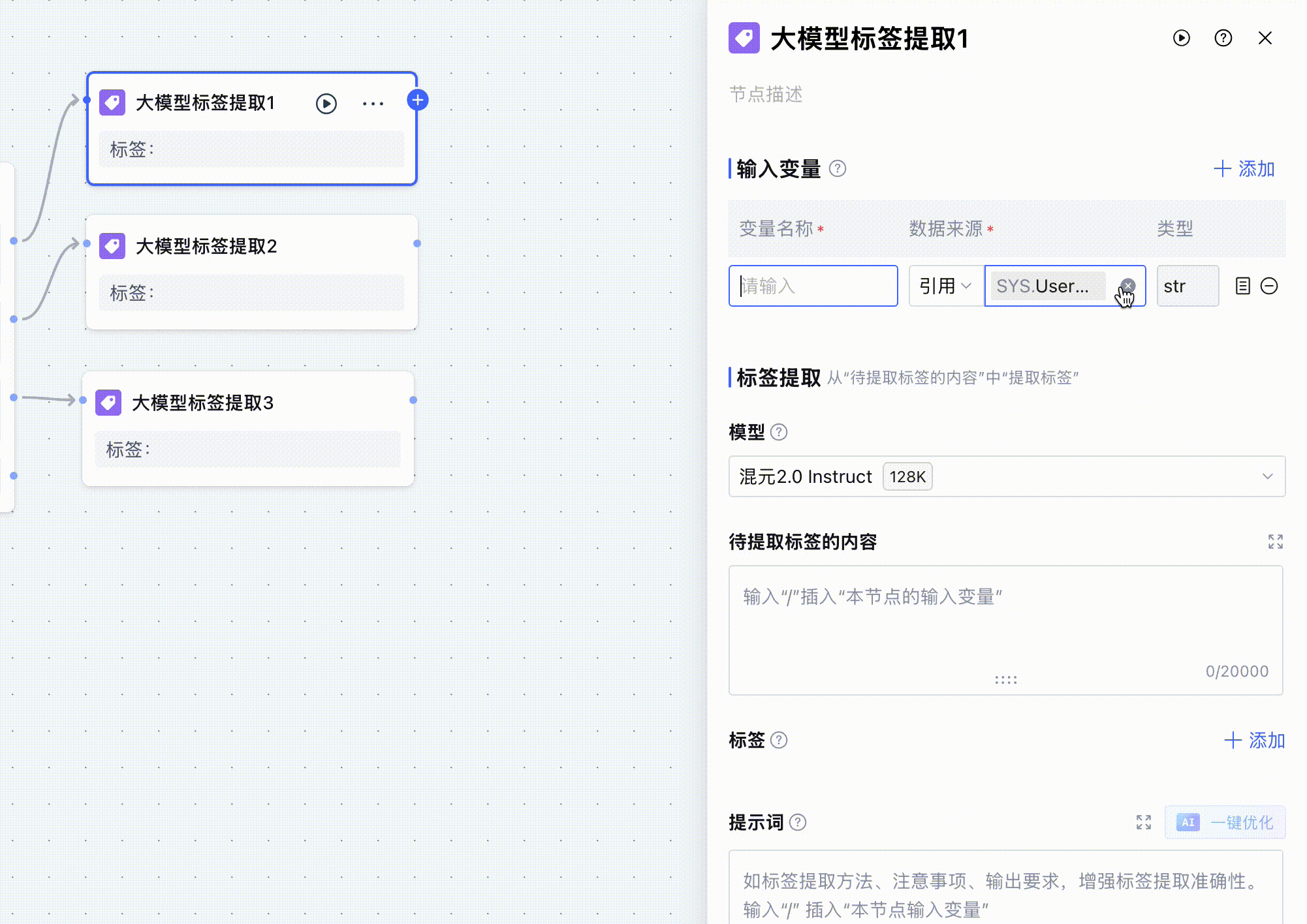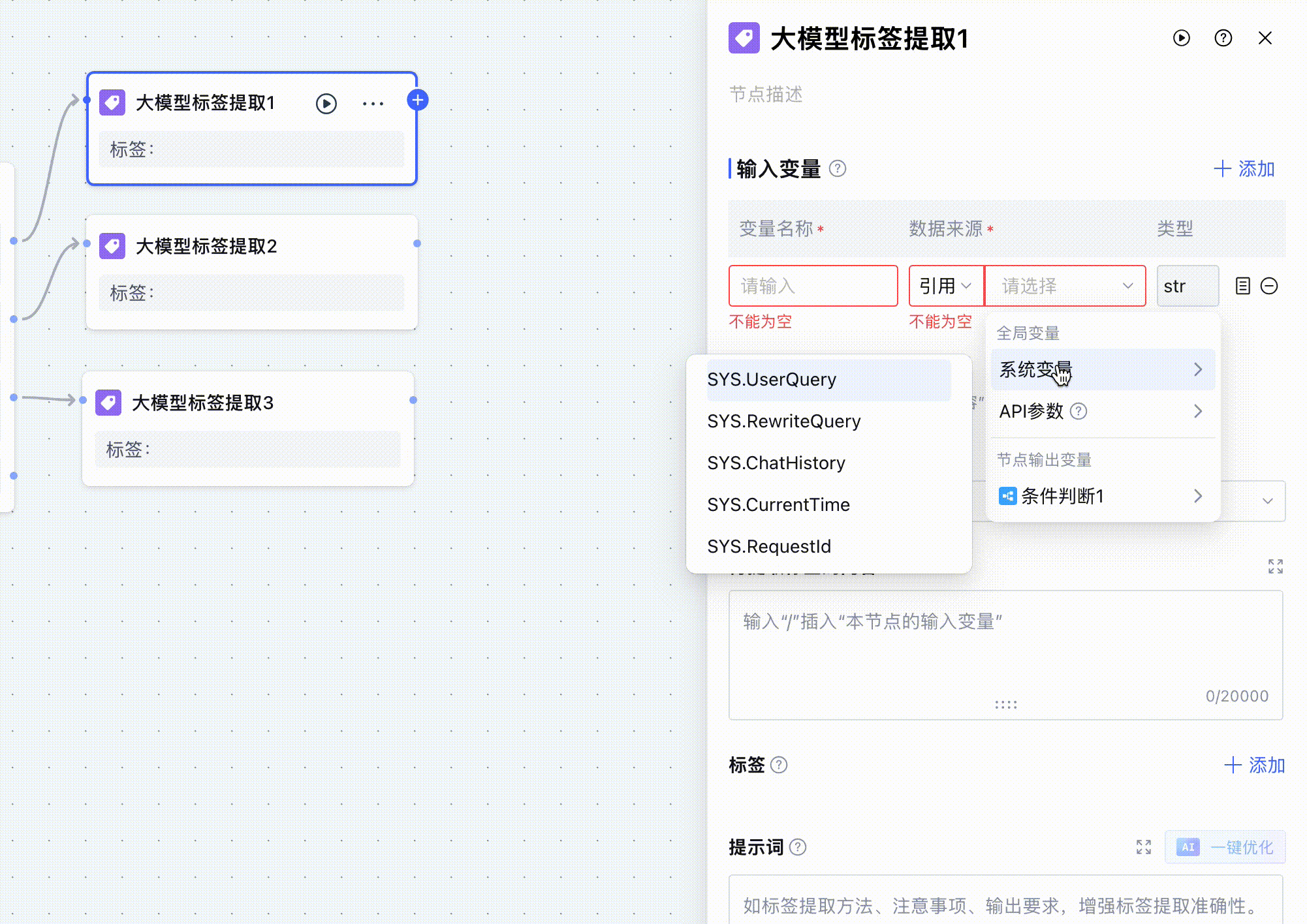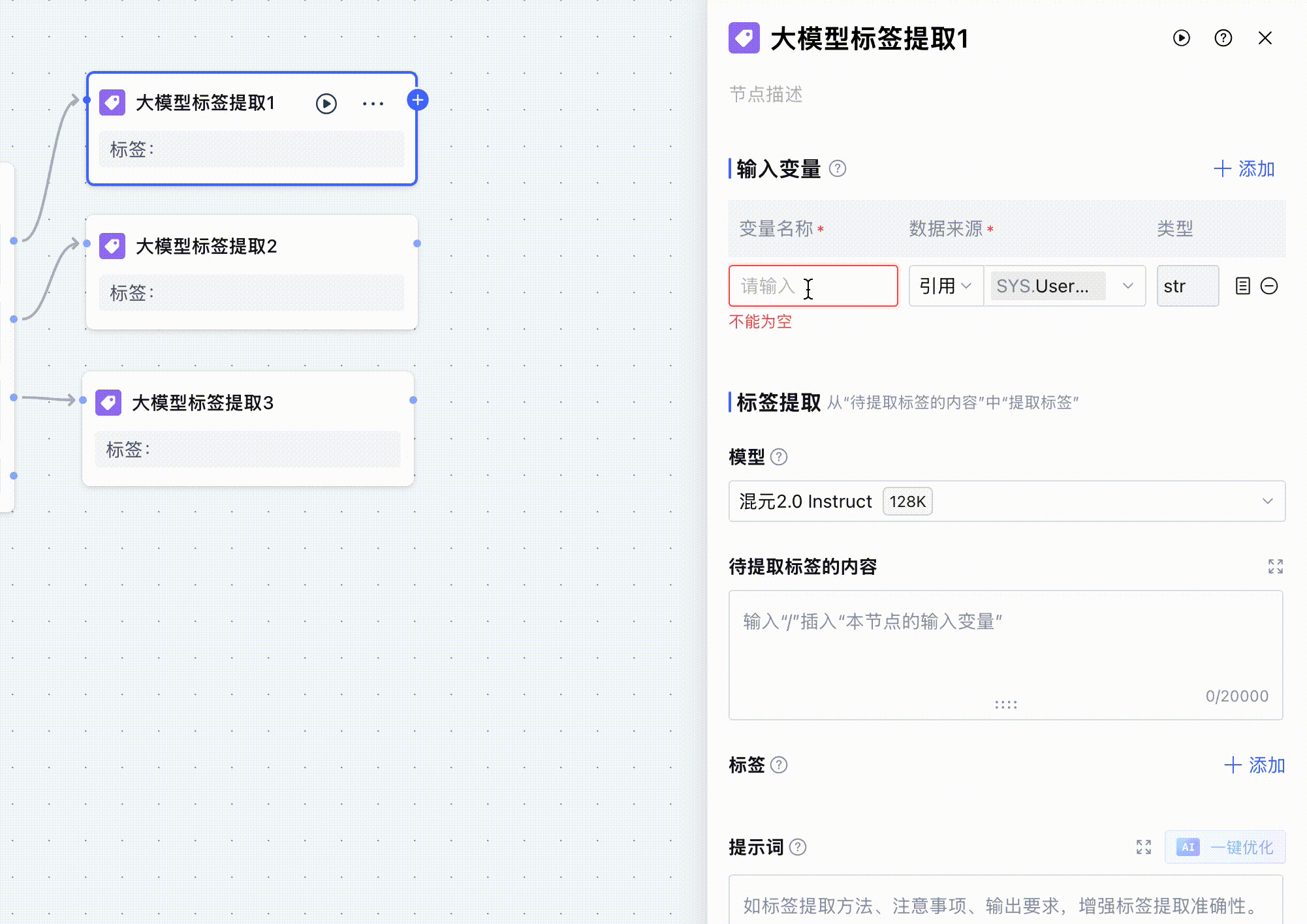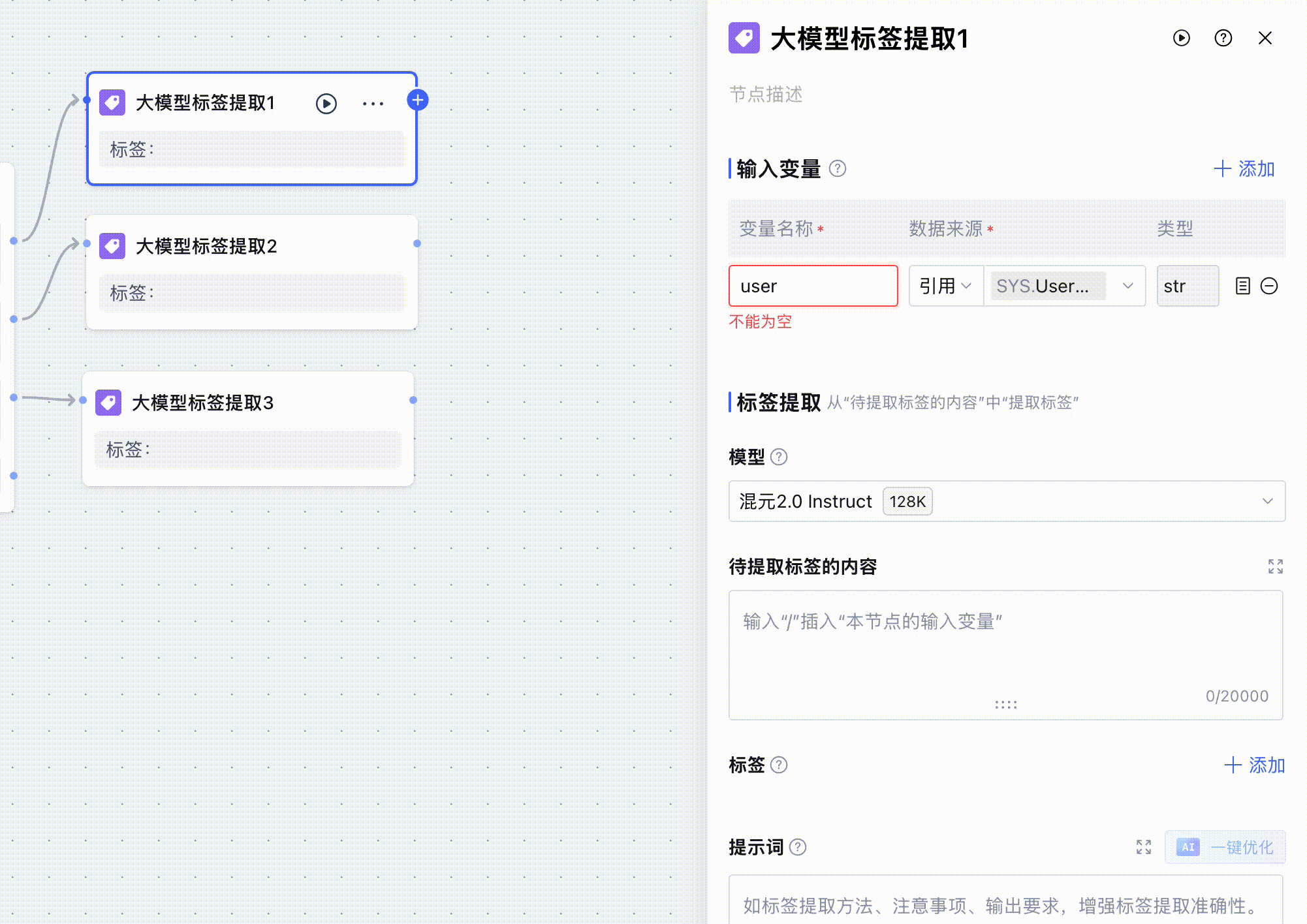
我们来看看大模型标签提取标签是如何配置的。因为还是从用户的输入中提取url,所以还是需要将开始节点的用户输入设置成变量,在后面给大模型的提示词引用。
定义好变量之后我们选择大模型,这里我使用的是混元2.0 Think。
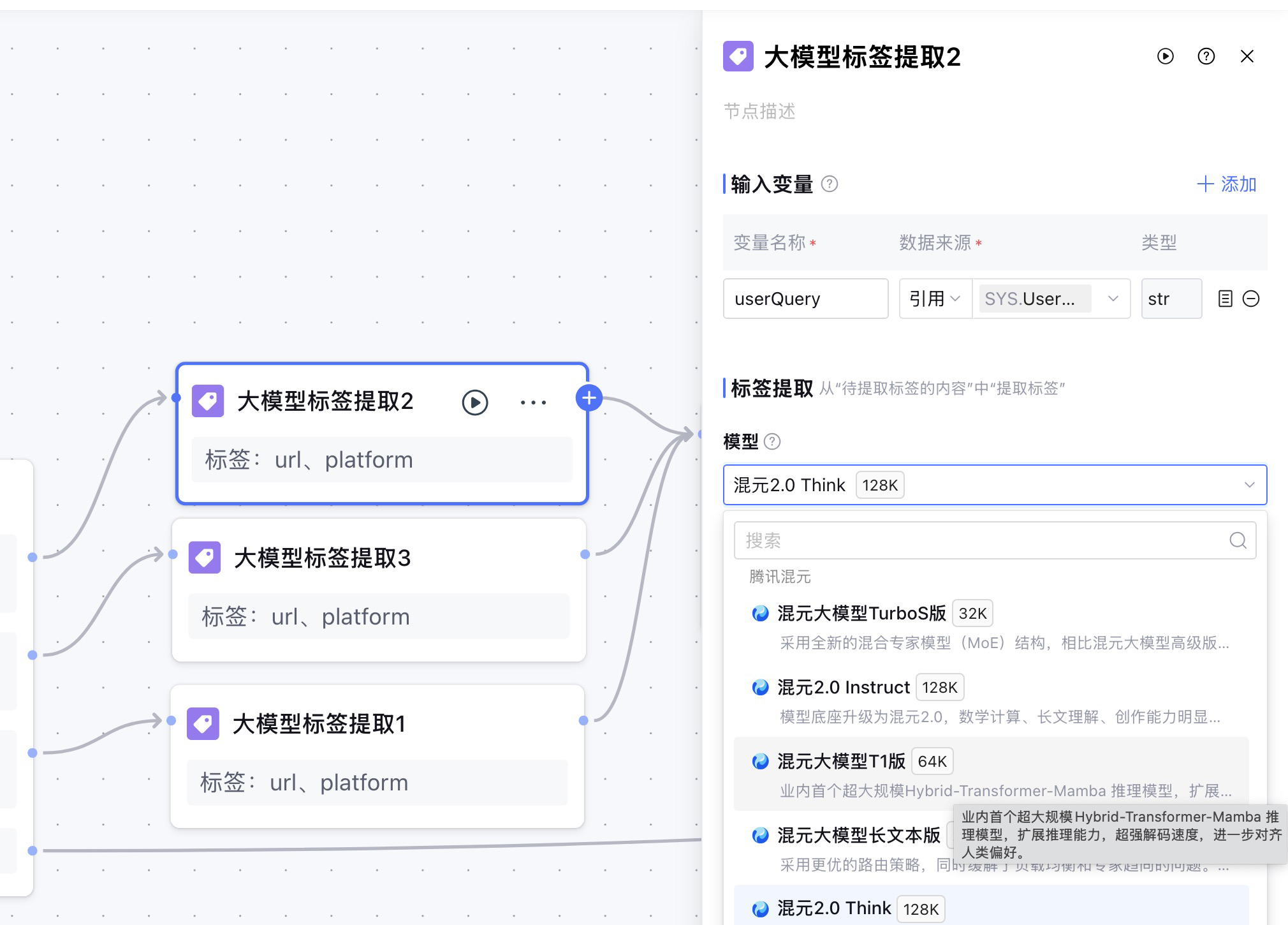
然后就是开始告诉大模型要提取的内容,我在待提取的标签内容和提示词中输入了同样的内容,在输入提示词的过程中,输入/之后,就会自动弹出我们定义的变量,我们在上面定义了 userQuery 这个变量,即开始节点的用户输入,在提示词中告诉大模型:我想要提取什么标签内容、格式是什么。

三个大模型标签提取节点大致都一样,只不过提示词中要提取的url不一样,然后我进行节点调试。
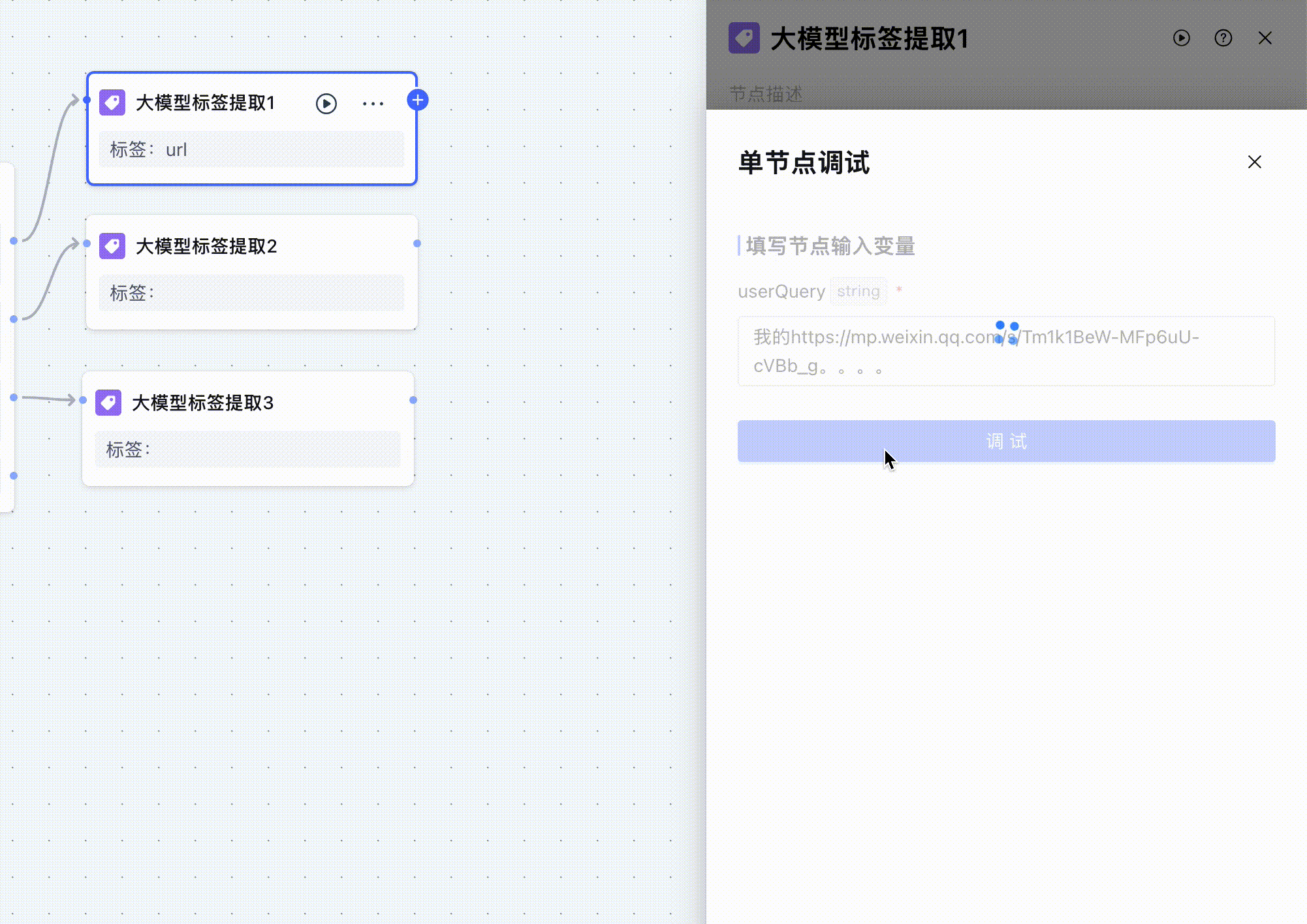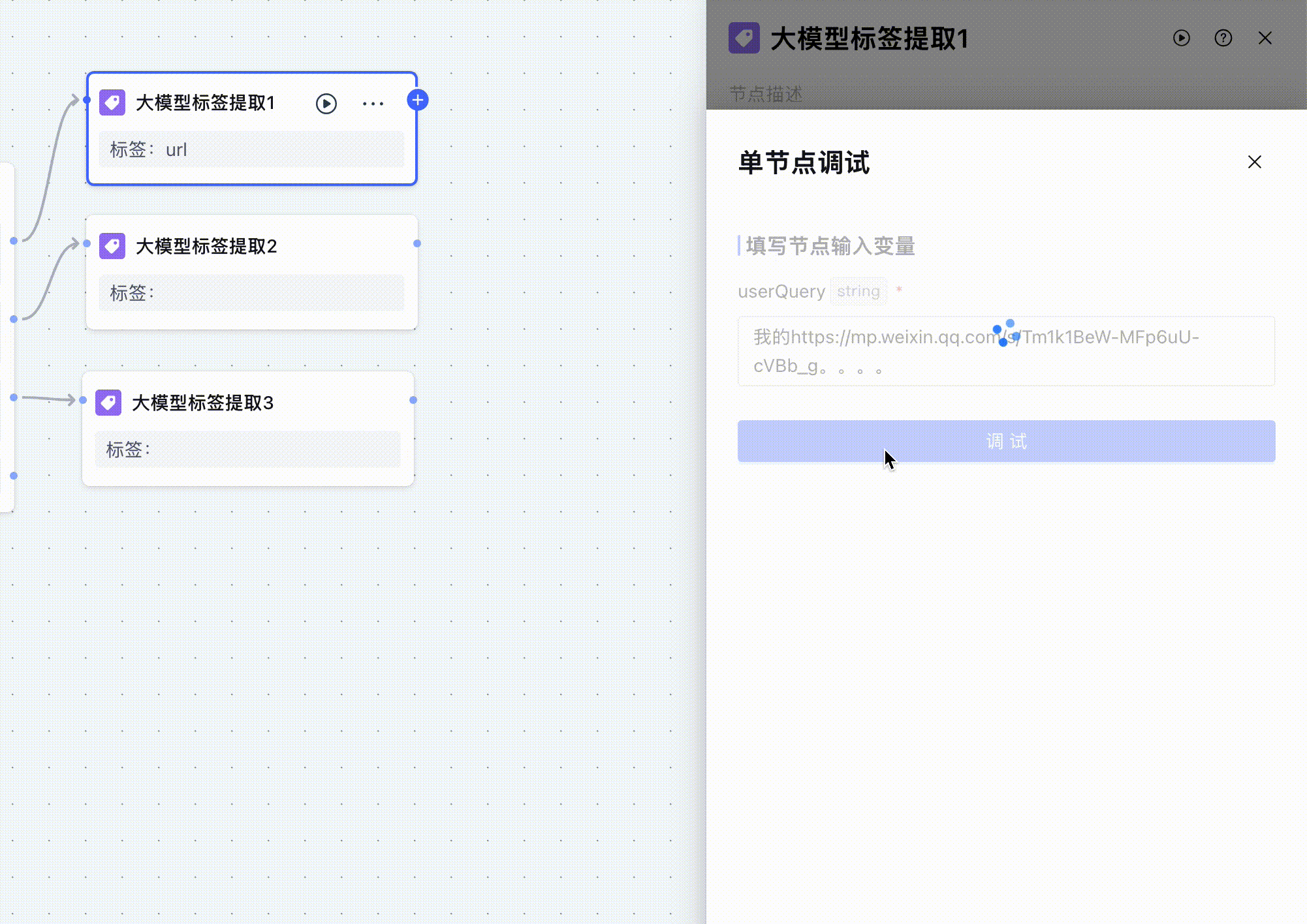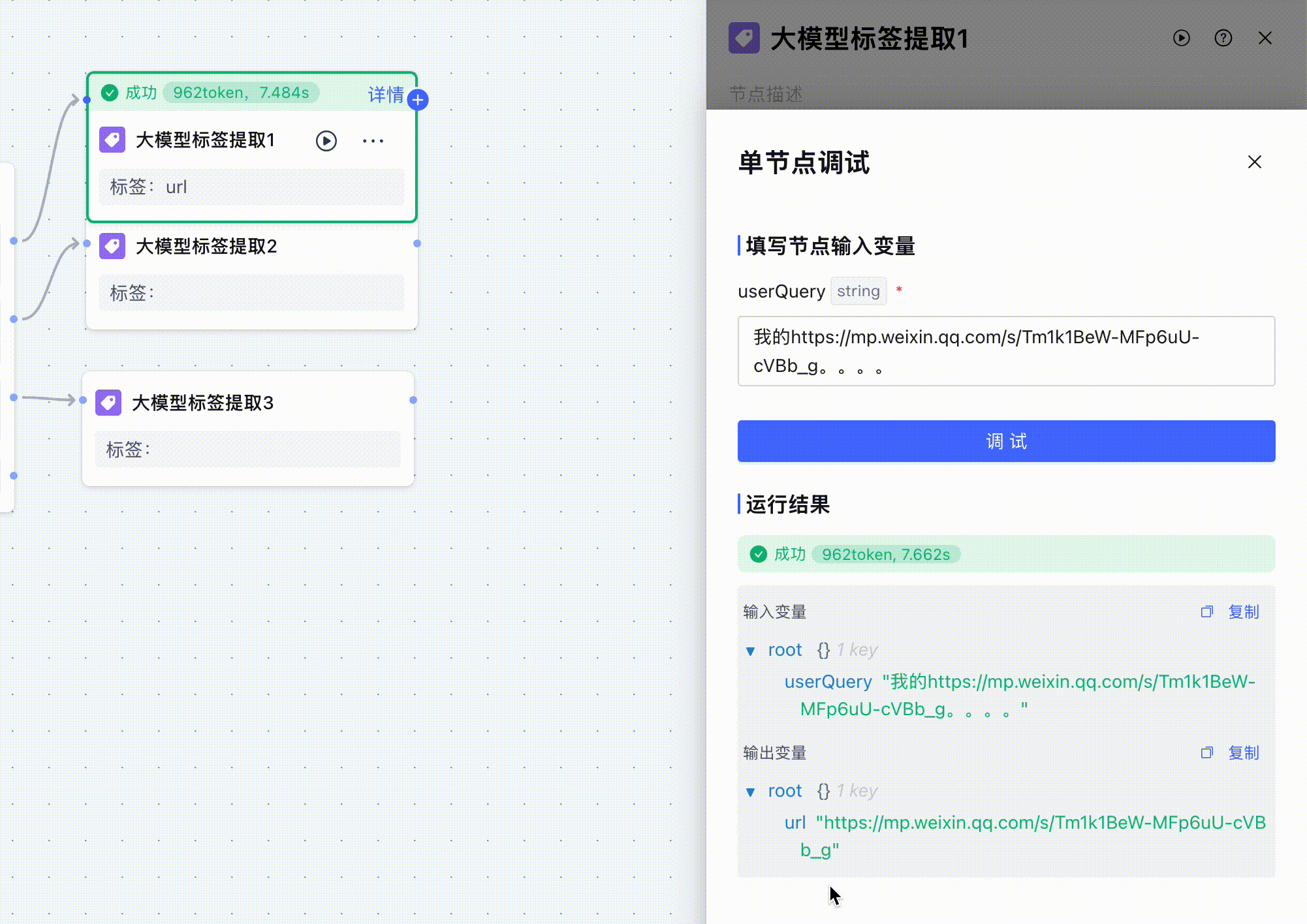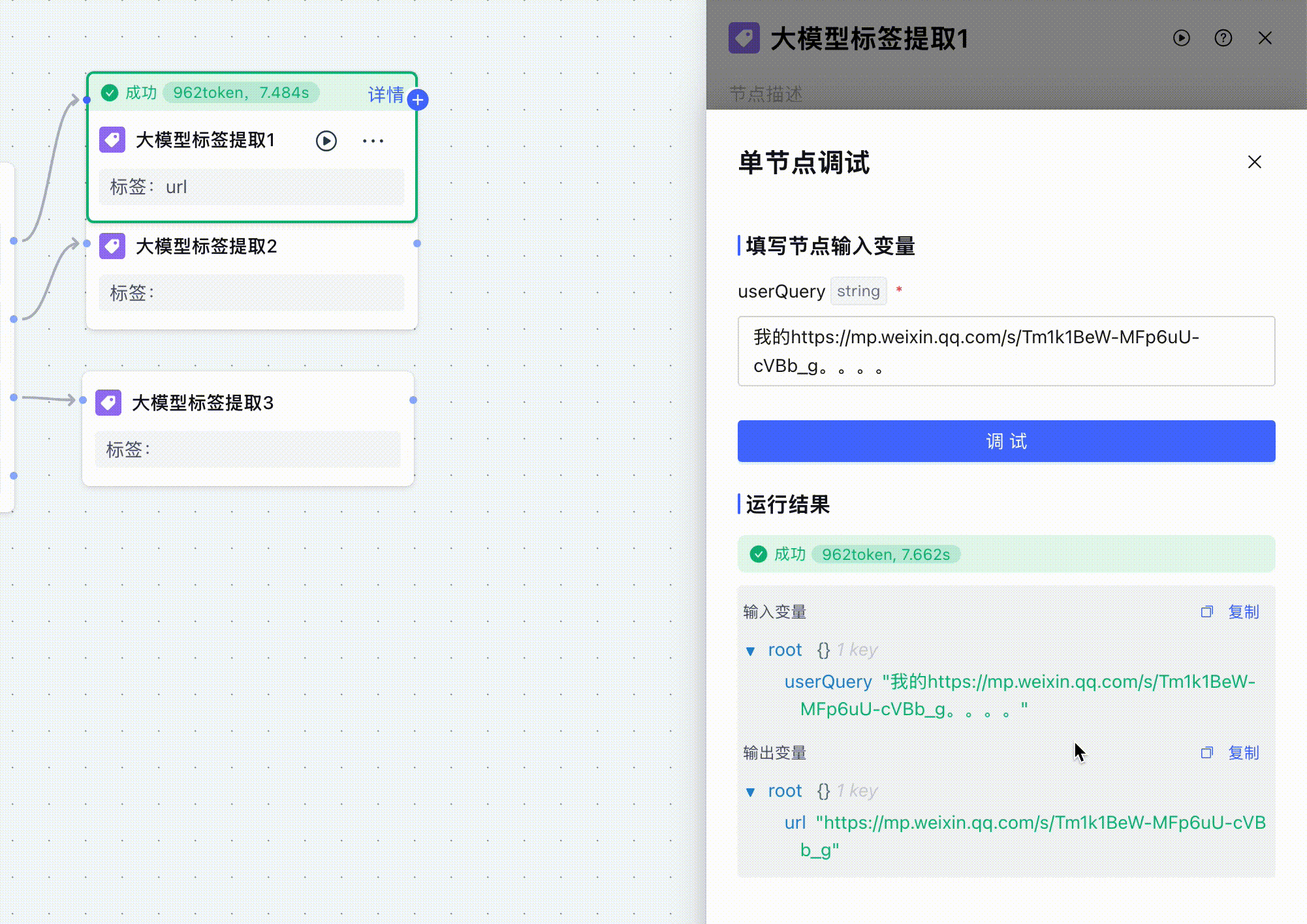
除了url之外我还输入了很多无用的字符,可以看到大模型成功提取到了url标签。

同样,我测试了腾讯云开发者社区对应的大模型提取标签节点,运行结果也是可以成功提取到url。
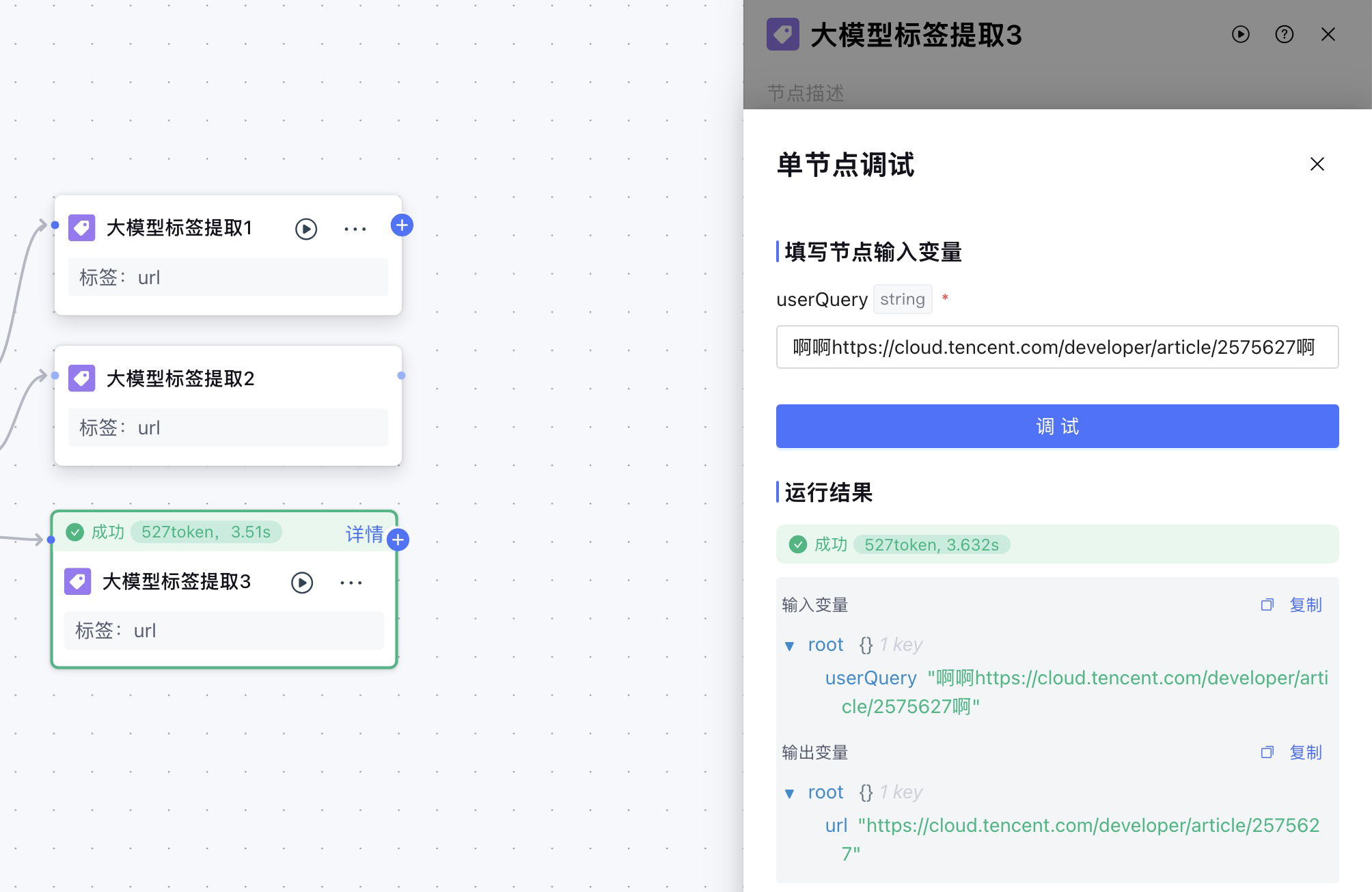
大模型标签提取节点除了输出提取的url之外,我还需要输出一个固定值platform,这和我后面的设计有关,我要调用自定义的工具,通过传入platform来判断调用哪个平台的解析方法。例如platform=weixin,就调用微信公众号的网页解析,platform=tencentcloud,就调用腾讯云开发者社区的解析。当然,这一块也可以在后端接口实现,通过url的domain来路由相应的解析,这是程序设计上的问题,暂不讨论。
我现在的诉求就是需要大模型标签提取节点,输出一个固定值的platform字段。就是不需要提取,我告诉他你输出“weixin“这个字符串,它就直接输出。,我们看看是否可以。添加一个新的标签字段platform,看看是否能够约束输出固定的取值。
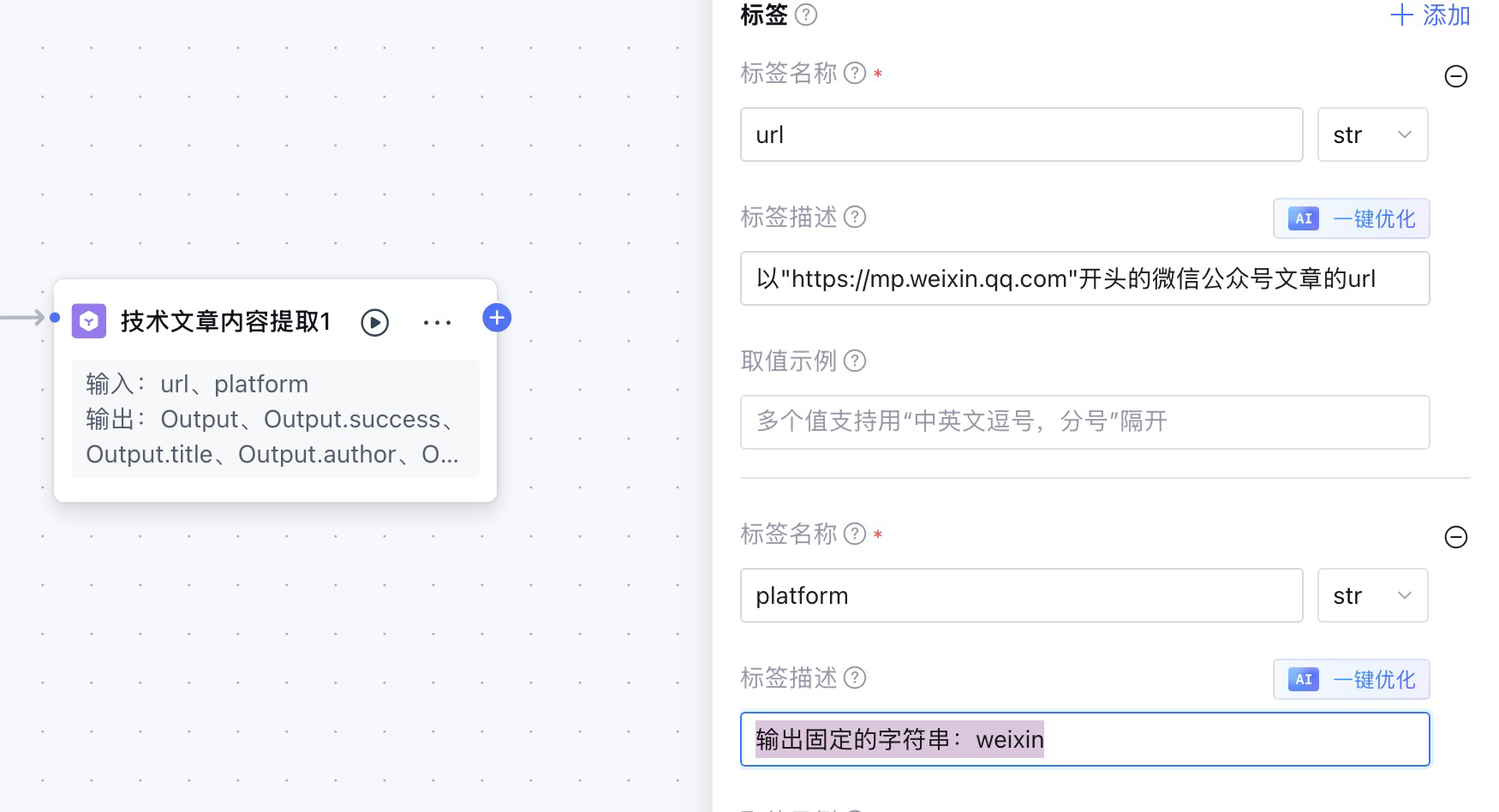
如图,我在标签描述告诉他直接输出固定字符串:weixin,然后单节点测试输出platform。

大模型标签提取节点就输出了从用户输入中提取的url和固定值platform两个标签。在获取了url和platform之后,我就需要实现文章的内容提取,这就需要借助外部的工具。
4. 插件节点
在工作流中,有两种节点可以调用外部的工具(代码):插件和工具。插件节点对应的是在插件广场中创建的mcp server和API接口。在插件广场,我们可以看到很多已经发布的插件,我们也可以自定义插件,这里的插件包含了mcp server和API接口。

这里我选择了API接口作为插件。点击新建插件,就会进入到新建插件的页面,填写完插件名称和描述之后,选择授权方式,如果接口有认证,就可以在这里设置。
点击下一步,进入到添加工具(API)的页面,在这里就是配置接口的地址、请求方式,以及入参和出参。
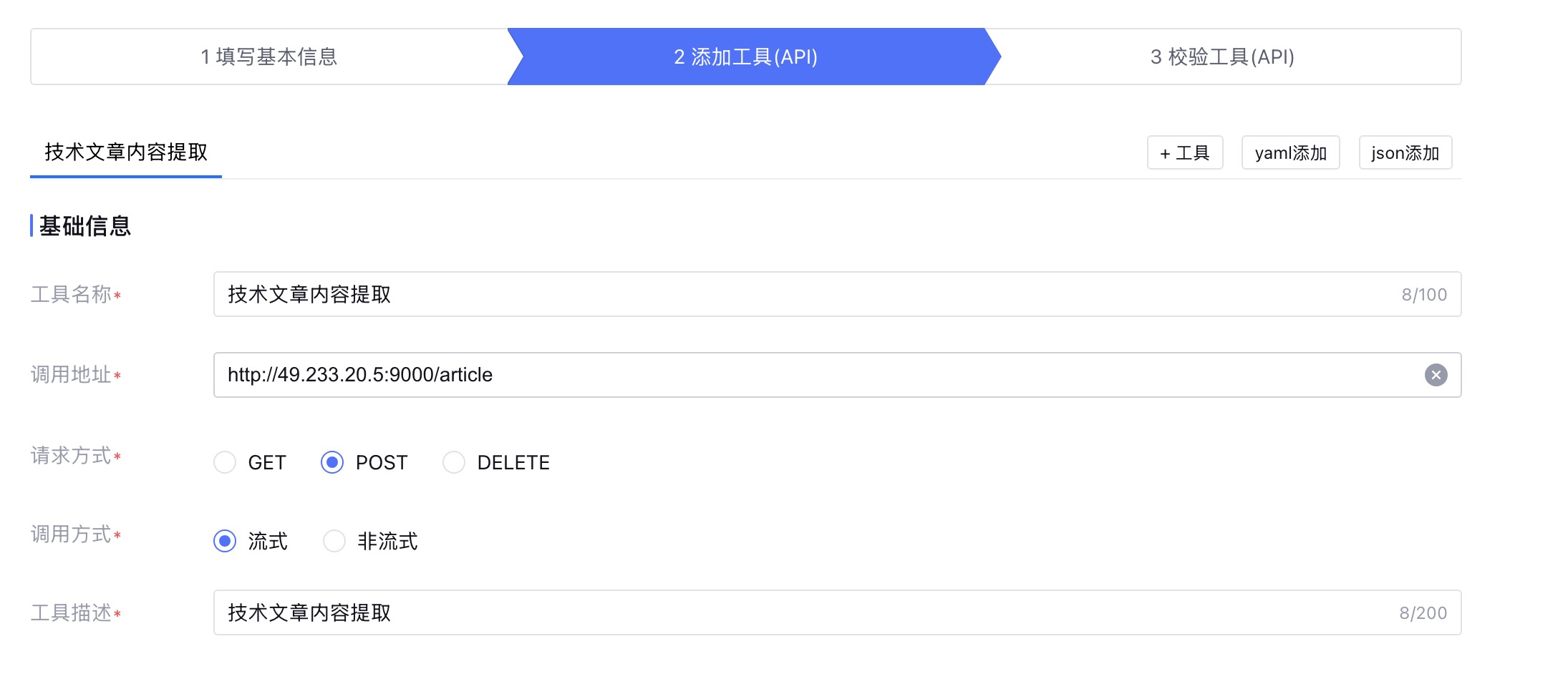
可以看到入参就是之前大数据提取标签节点的两个输出变量:url和platform。出参就是文章的标题、作者、发布时间,以及最最重要的文章文本内容。这里返回的是发布时原始的markdown文本内容,而不是纯文本。
然后点击下一步,进入校验工具。传入url和platform参数进行测试,可以看到接口正确返回response。
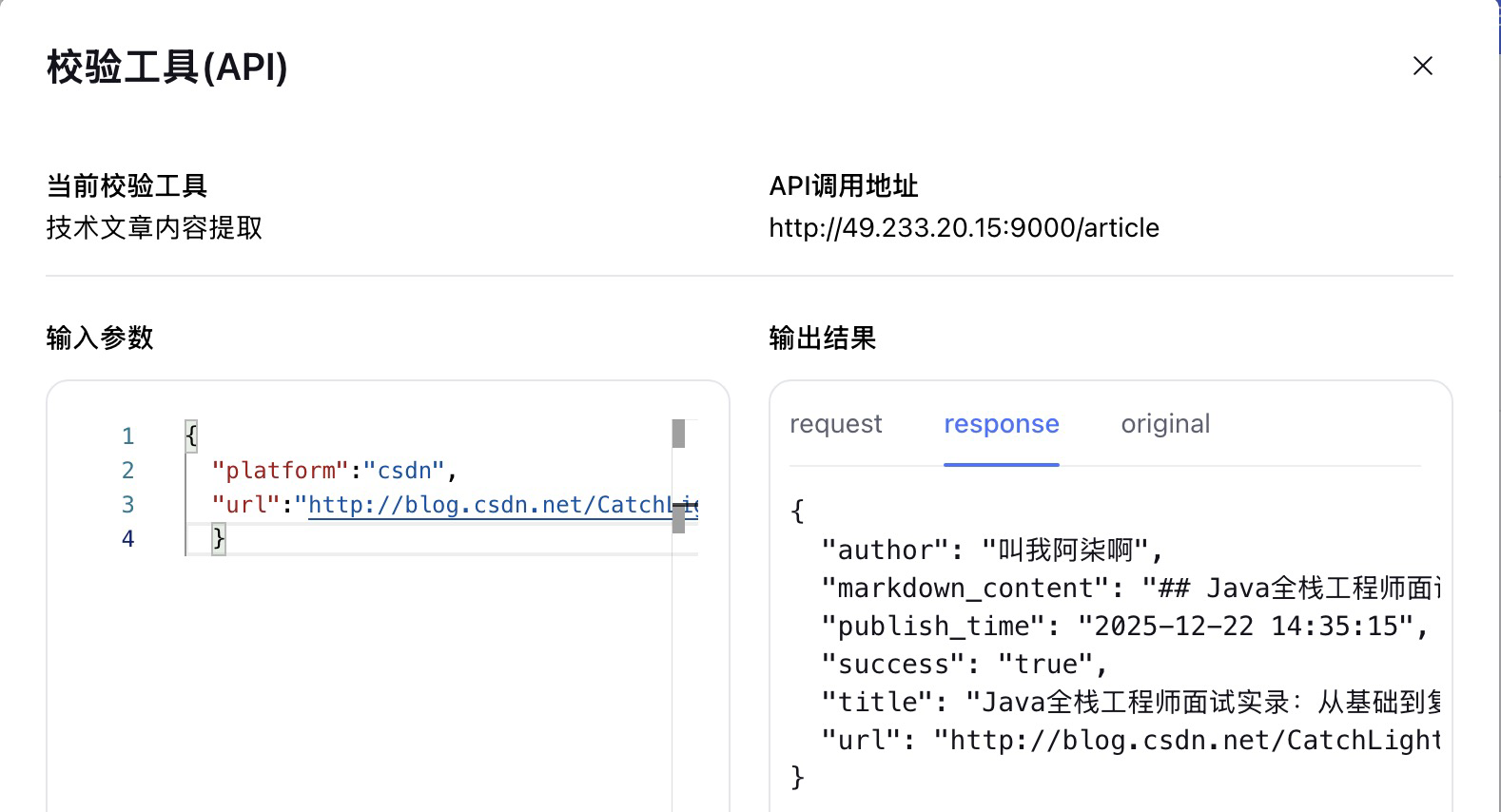
我们通过curl来测试接口,看到 markdown_content 返回的是markdown文本。

这样我们就新建好了一个插件,在编排界面添加插件节点,然后再自定义插件中,就可以找到我们刚刚创建的API插件。
选择之后,在配置页面就自动带出来了入参和出参。

在这里,url和platform的数据来源要选择引用。然后启动单节点调试,输入url和platform。
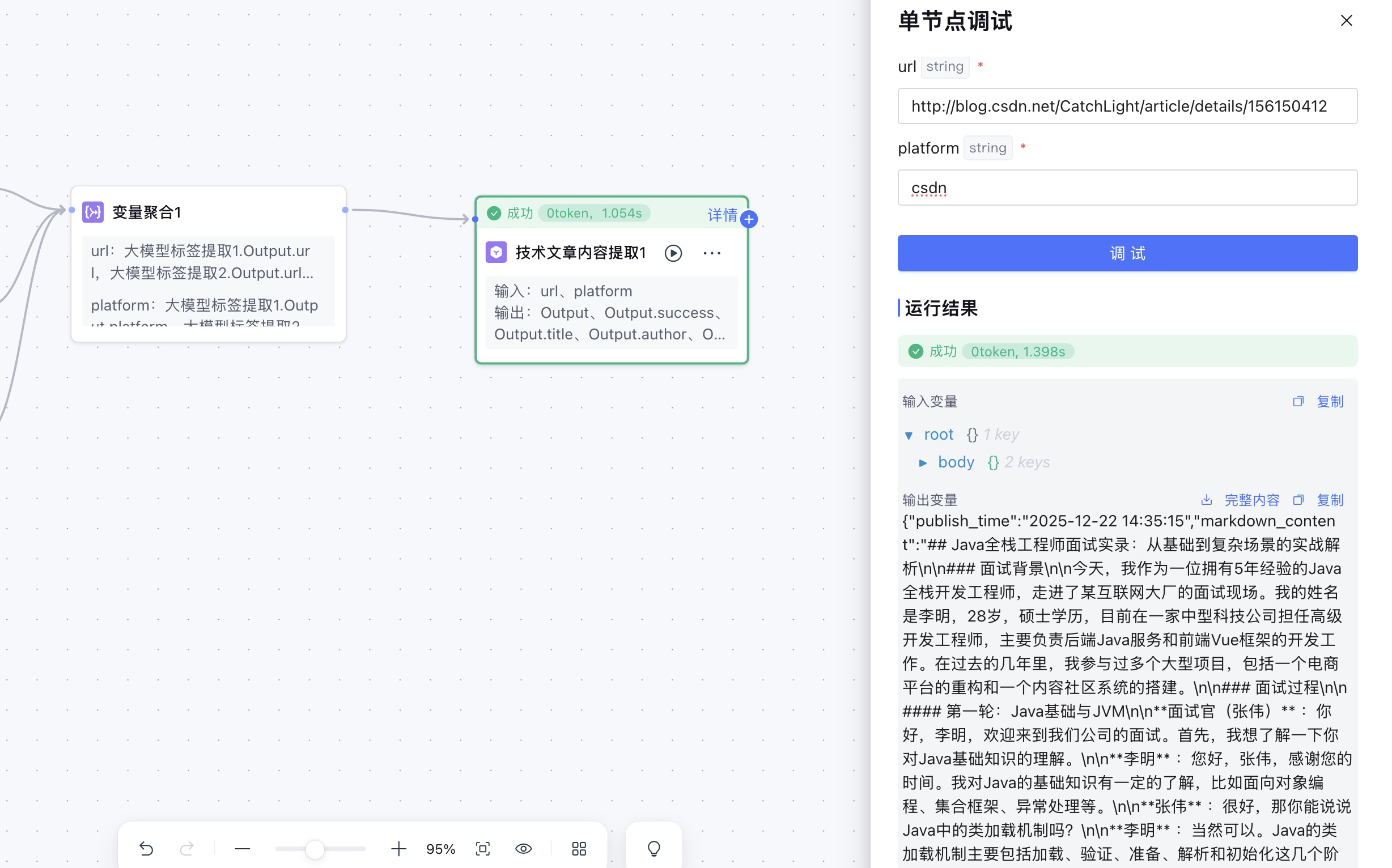
如图,成功调用了API插件,完成了技术文章信息的提取。
除了插件节点,调用API接口也可以使用工具节点,配置页面和我们自定义API插件的页面一模一样,但是与API插件相比较,缺少了复用性,API插件可以在任何工作流中都可以被使用,但是工具只能在当前工作流可见。

那么,是不是把前面所有的大模型提取标签节点,都连接上这个插件节点就可以,答案是否定的,这样会直接报错。
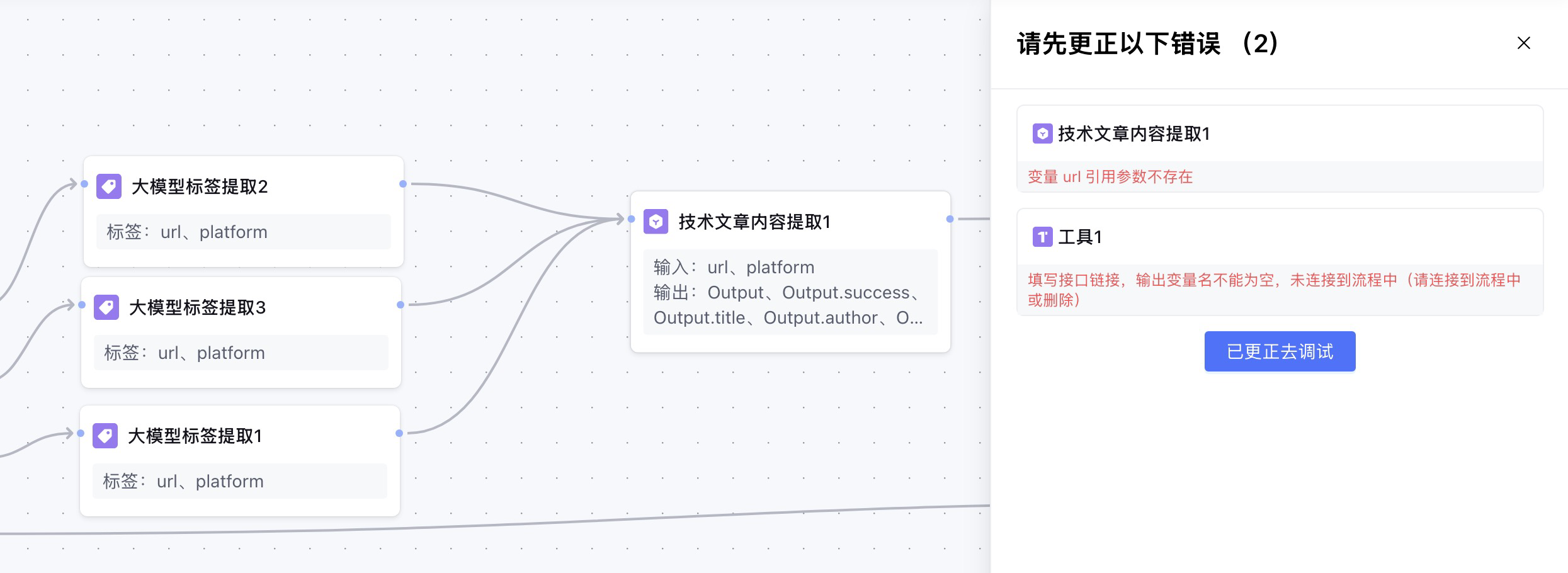
原因为啥呢,就是因为在3个条件判断中,执行一次工作流只会有一个条件命中,只会有一个节点有输出,其他两个节点一定不会输出的url和platform。在上面,url和platform的数据来源是引用上一个节点,但是上一个节点没有输出,所以就会报错。
那么,在这种情况下,我们既不知道哪个条件会输出,又想只取输出url和platform的节点变量来传给插件节点,那该怎么办呢,这就用到了变量聚合节点。
5. 变量聚合
聚合时仅返回每个分组中的第一个不为空的变量,如果有多个变量有值,也仅返回第一个。所以,在大模型提取标签节点和插件节点之间,要使用变量聚合节点来做中转。
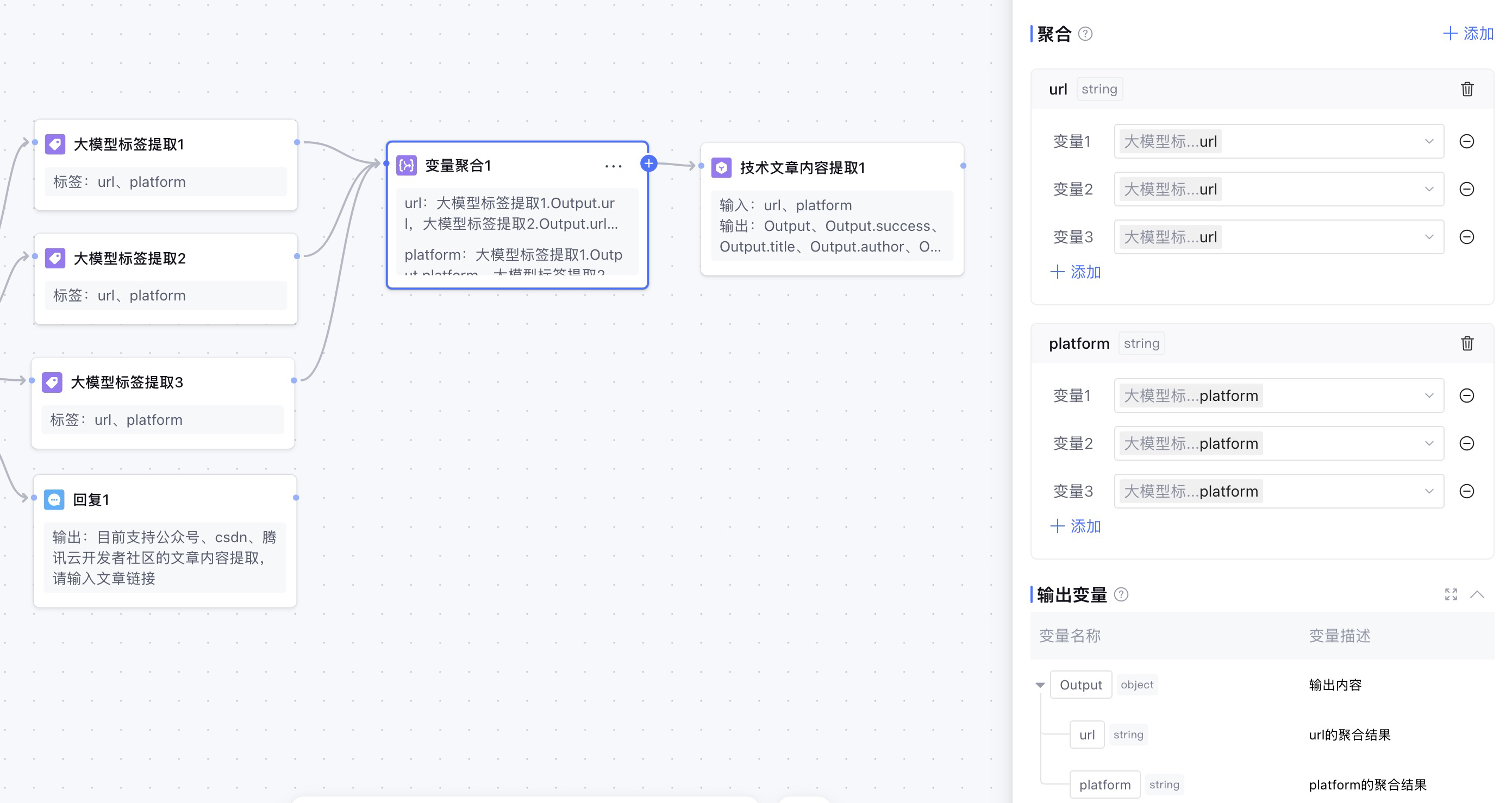
这样,变量聚合会自动选择前置节点有效的输出,并输出到后继结点,这样就完成了API插件的传参和调用。
6. 大模型节点
在获取了文章的内容之后,我们就需要进行改写,这里我们使用大模型节点。定义输入变量,将前置插件节点获取的文章内容markdown_content和标题title作为变量。这里变量的作用和之前在大模型标签提取节点的作用一样,都是在提示词中引用。

然后选择大模型,这里依旧使用的是混元2.0 Think,然后自定义提示词,告诉大模型要做的事情。
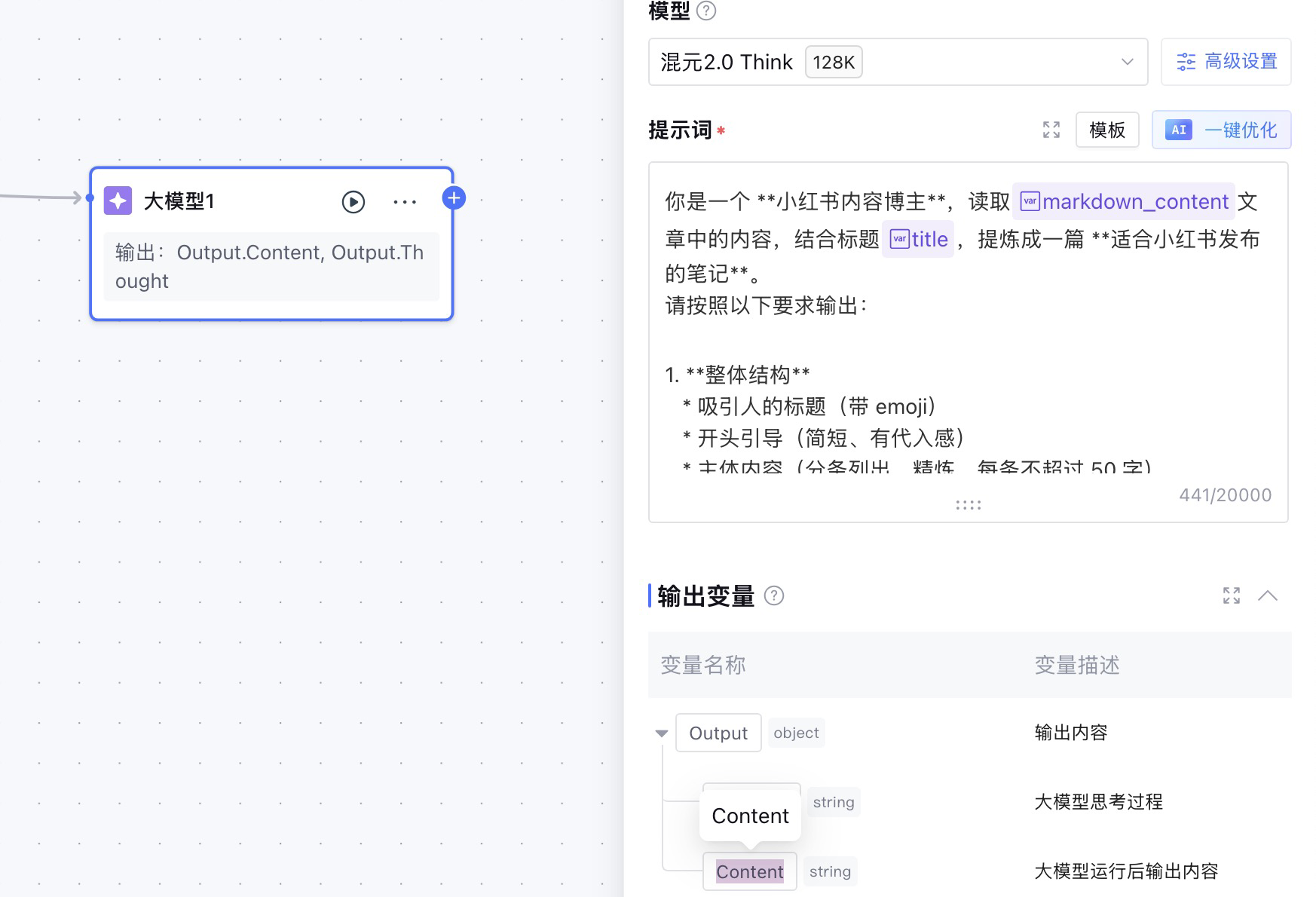
提示词如下:
你是一个 **小红书内容博主**,读取markdown_content
文章中的内容,结合标题title
,提炼成一篇 **适合小红书发布的笔记**。
请按照以下要求输出:
1. **整体结构**
* 吸引人的标题(带 emoji)
* 开头引导(简短、有代入感)
* 主体内容(分条列出,精炼,每条不超过 50 字)
* 结尾引导互动(提问或 CTA)
2. **风格要求**
* 使用 emoji 来增强视觉效果
* 用小红书常见语气(轻松、分享、种草)
* 保持信息简洁,避免学术化、长段落
* 重点突出「技巧」「方法」「实用」
3. **内容重点提炼**
* 从文档中提取 **最有价值的技巧或模板**(比如 Prompt 优化技巧、实用模板、最佳实践等)
* 去掉无关的推广/长篇背景描述
* 只保留对用户有帮助的内容
4. **输出格式**
* 标题
* 正文(用小标题 + emoji 分段)
* 结尾互动引导启动调试,可以看到大模型的输出是符合预期的。

7. 变量聚合
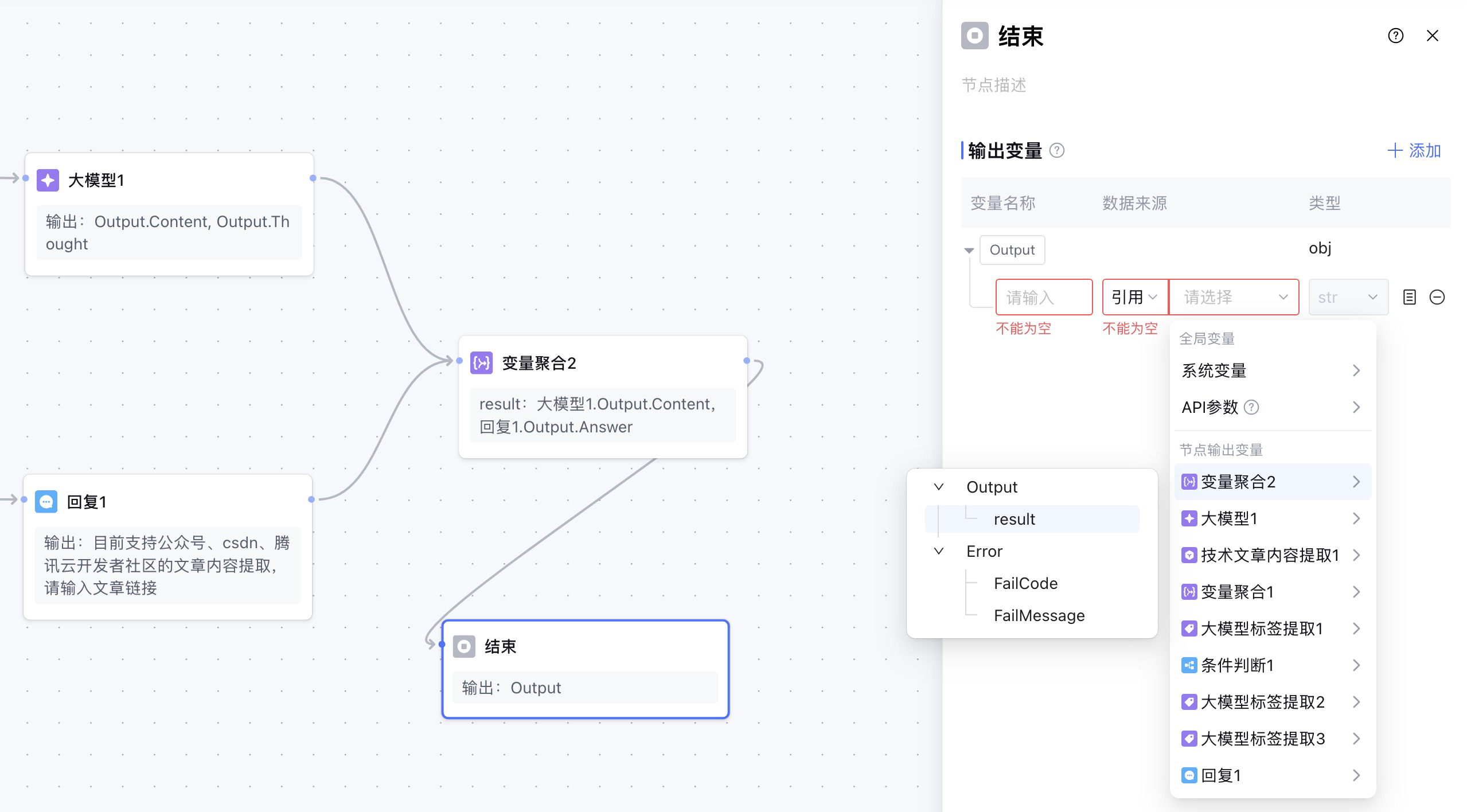
大模型节点已经完成了我们的需求:将技术文章改写成了小红书文案。然后就是要输出给用户。这就需要连接到结束节点,因为结束节点是工作流的最后一个节点。
但是大模型节点是当用户输入的url中,包含微信公众号、腾讯云开发者社区、csdn的文章url时候的执行路径,而当用户输入中不包含三个平台url的时候,直接执行的是else,然后是一个回复节点,这个回复节点也是需要连接到结束节点的。
如果不包含url,就提醒用户输入,如果包含就调用工具解析,这两个是互斥的,这就又回到了大模型标签提取节点和插件节点那时候的问题了,所以需要一个变量聚合节点,来取不为null的值。

8. 结束节点
最后聚合变量再连接到结束节点,这样就完成了开始到结束节点的工作流编排。
调试
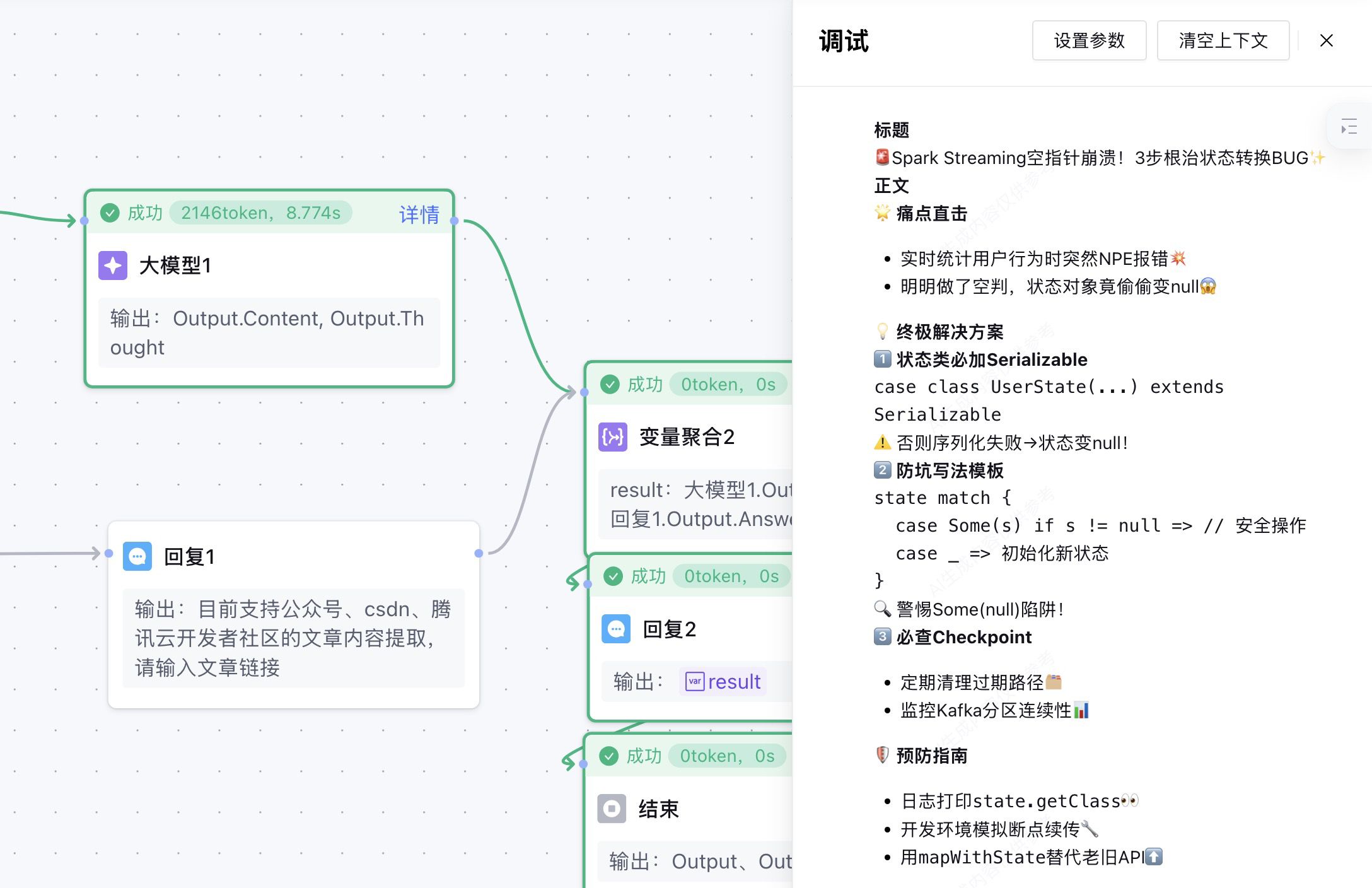
开始调试:在对话框中输入:“请帮我将此篇文章https://cloud.tencent.com/developer/article/2572080修改成小红书”,然后就开始调用工作流,在工作流正常调用之后。发现没有消息输出。查看工作流节点处理过程,发现在结束节点成功输出了。
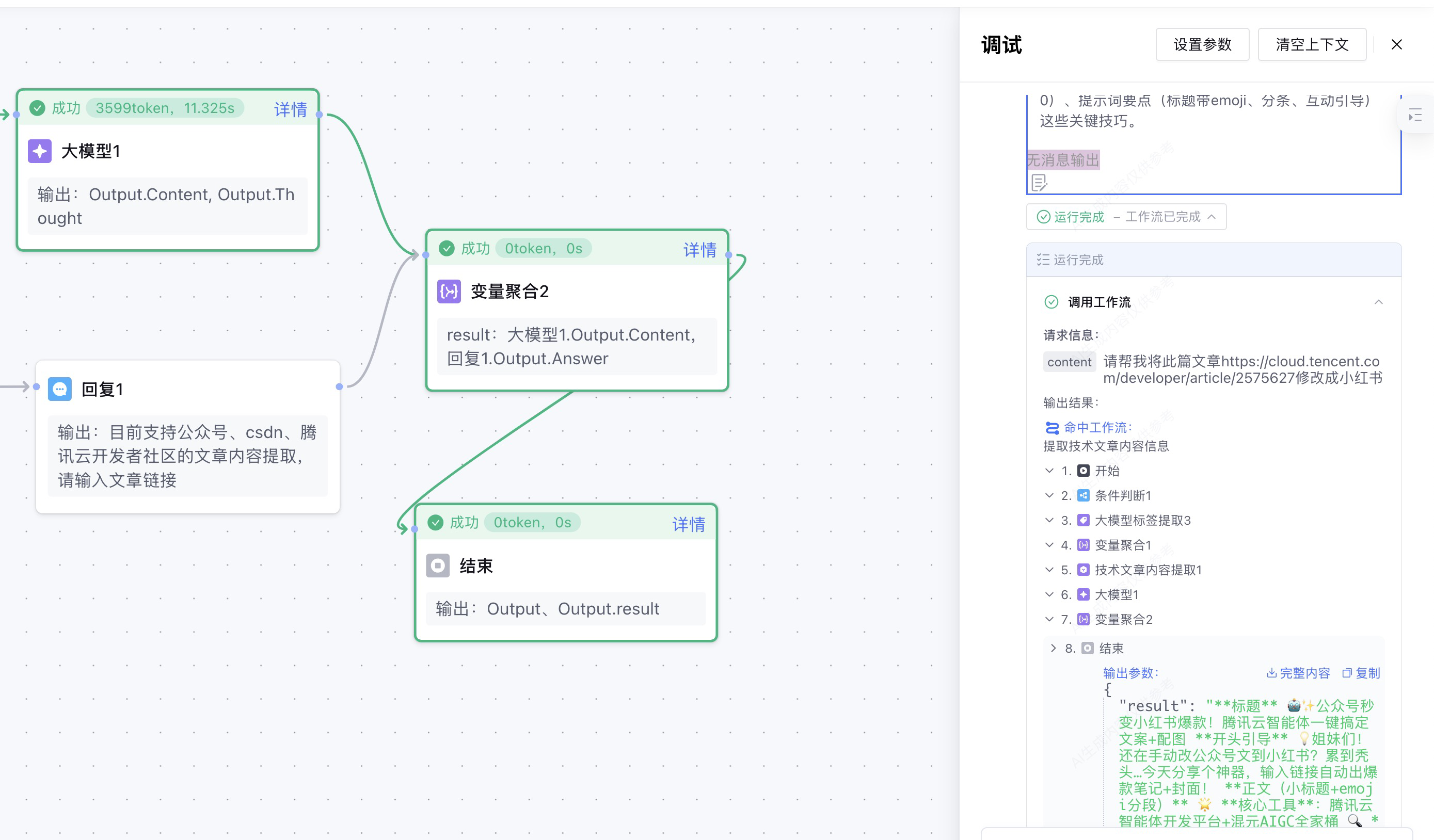
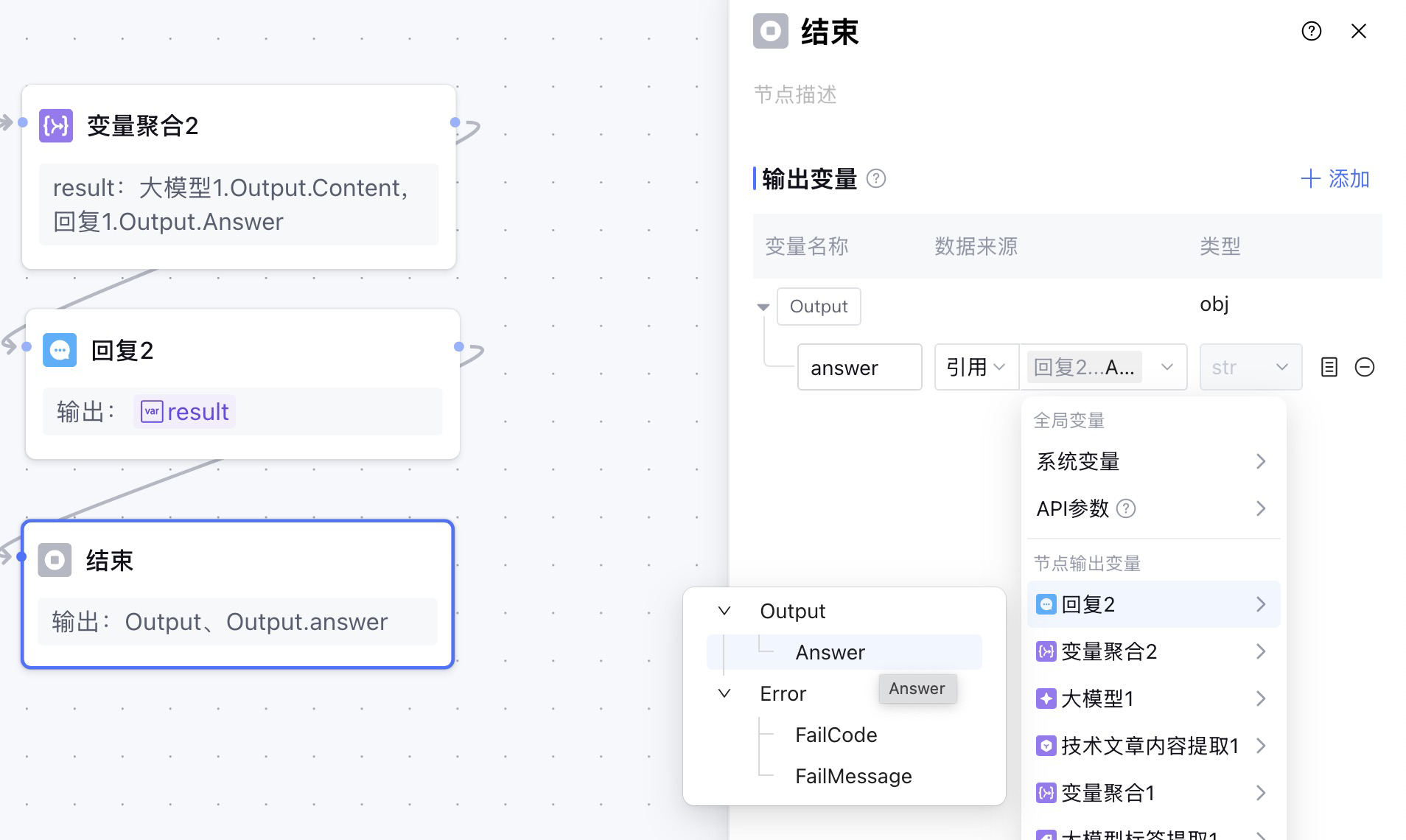
为什么结束节点命名执行了,但是在对用户的响应中,提示无消息输出。然后我查阅了资料,在元器的工作流中,需要在结束节点之前配置可以输出答案的节点,例如:回复节点、大模型知识回答节点,才能有效输出。所以我在变量聚合和结束节点之间,添加了一个回复节点。
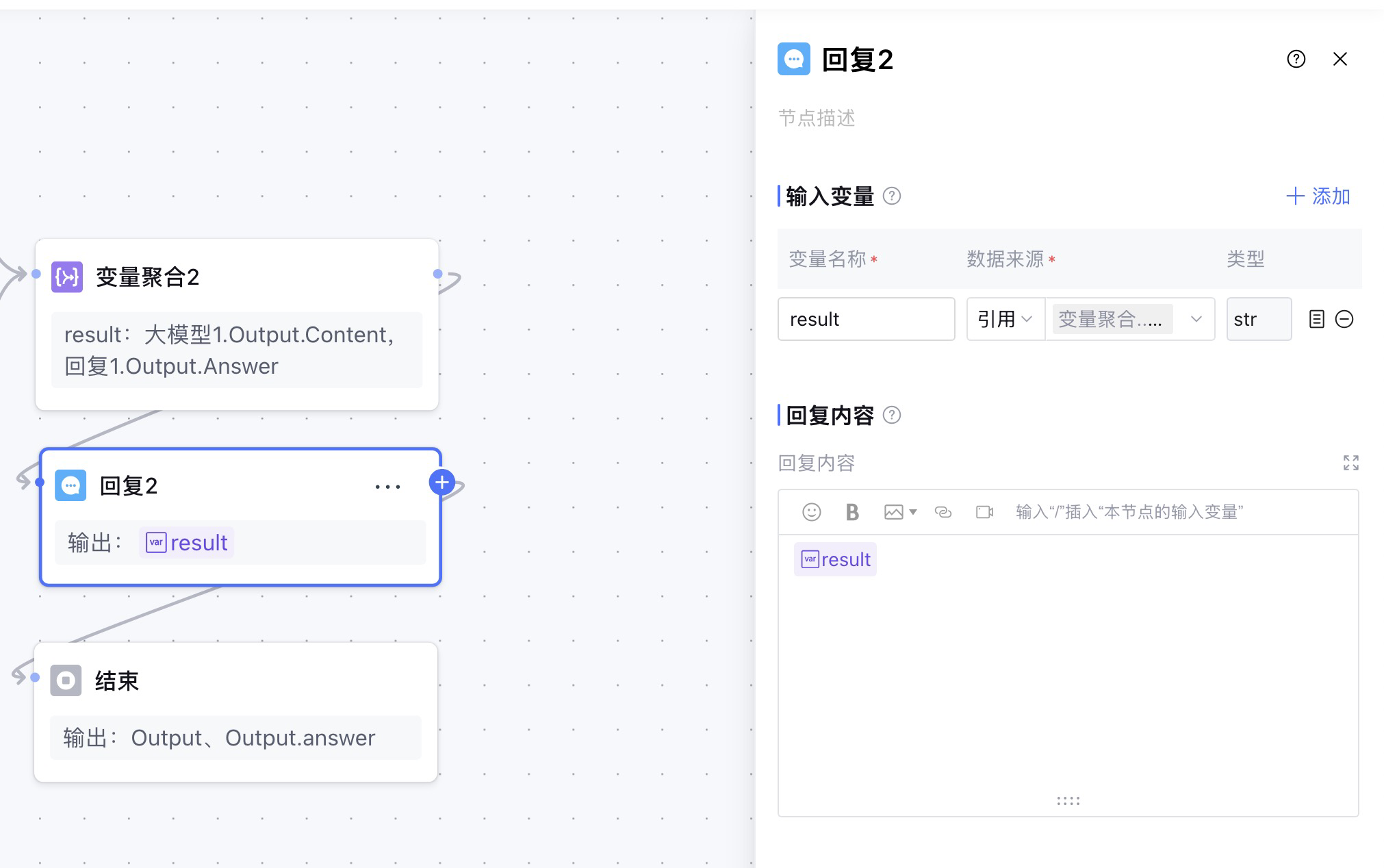
在结束节点中引用回复节点的输出变量:Answer。
然后再次启动提示,输入提示词,在界面就有消息输出了。
发布
我们推出工作流,在智能体页面输入url,看看功能是否完备。
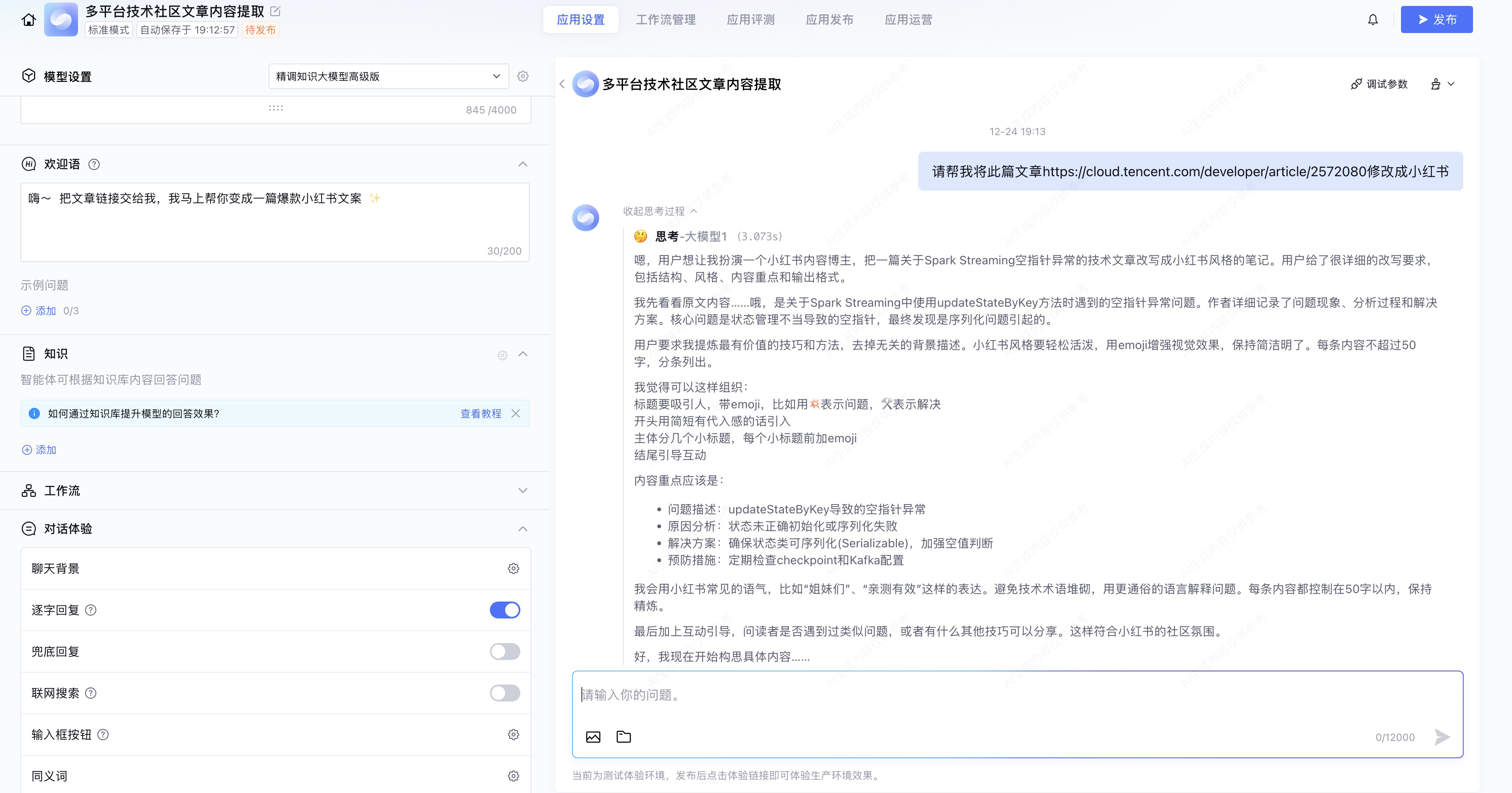
上图所示,当用户输入包含url的时候,会自动提取文章内容并改写成小红书文案,接着我们测试如果没有url的情况。
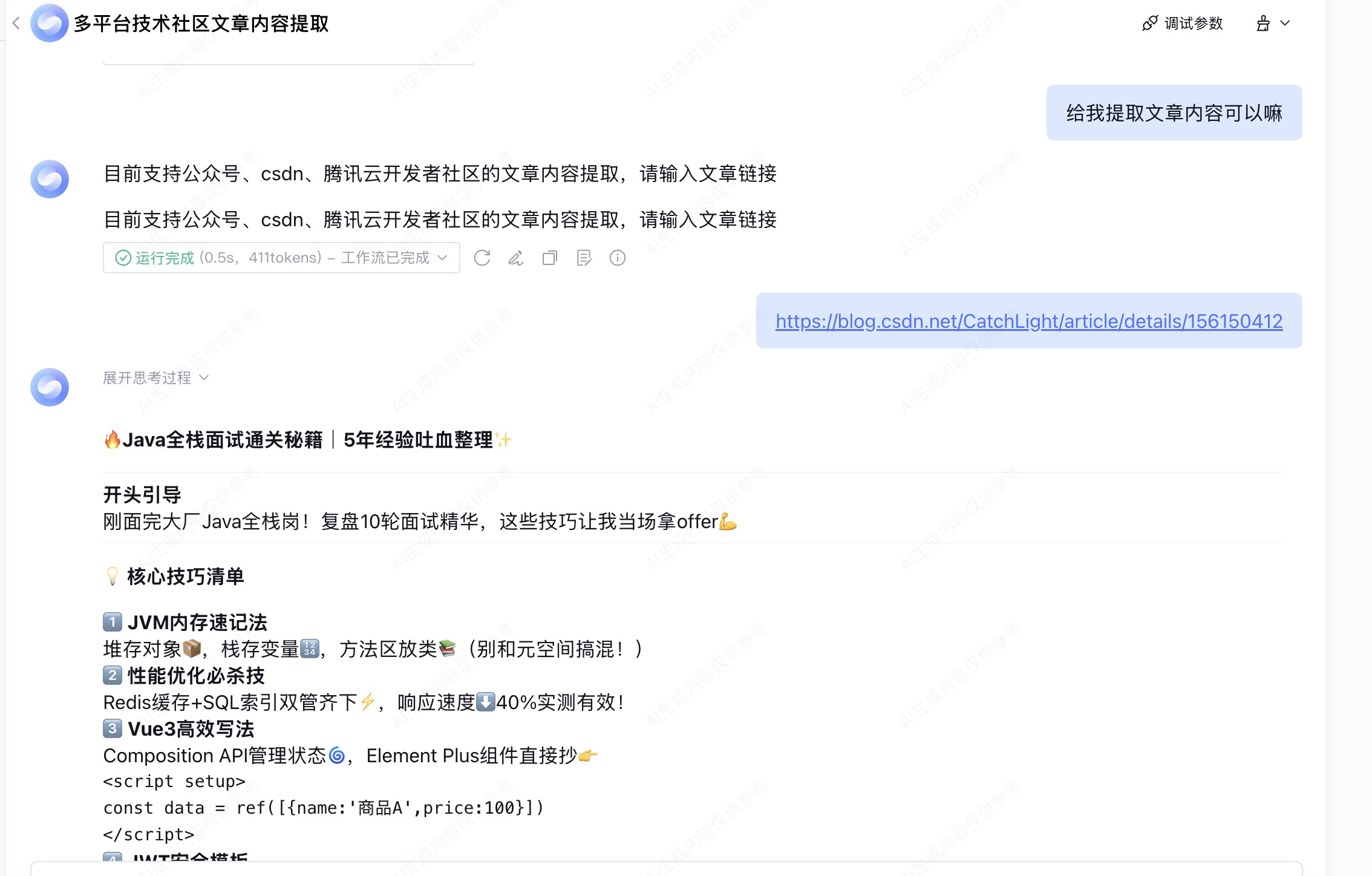
如图,元器智能体会提示用户要输入url。接着我们点击右上角的发布按钮,就可以将智能体发布到微信和元器官网等渠道上去。

结语
智能体体验地址:https://yuanqi.tencent.com/webim/#/chat/OOagrN?appid=2003645291033317376&experience=true
微信公众号、腾讯云开发者社区、CSDN主流技术平台文章,自动改写爆款小红书文案的智能体搭建,是基于腾讯元器实现的,元器友好简洁的操作界面,让智能体的构建、应用和发布极为简单,让入门者可以快速上手。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
