给2026的自己的一篇博客
原创
给2026的自己的一篇博客
原创
九年义务漏网鲨鱼
发布于 2025-12-31 00:45:03
发布于 2025-12-31 00:45:03
序言
我是一个很喜欢记录的人,同时又是一个不善于表达自己的人,从小就开始喜欢写日记,但从来不会超过一个星期。在2025这一年,我尝试过用很多方式来记录自己的生活:
1️⃣ 通过表格的形式记录
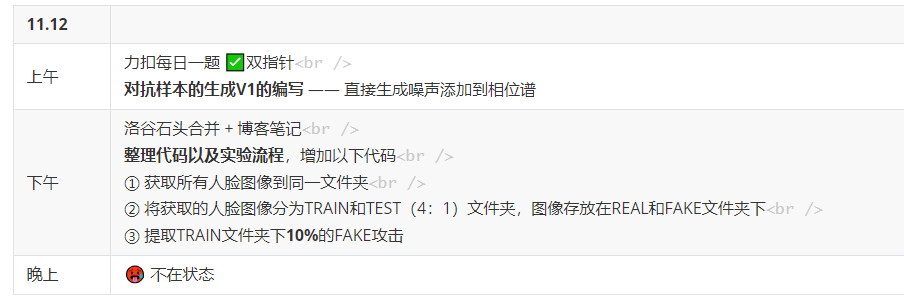
2️⃣ 通过小红书的形式
在这一年中,无时无刻的在记录着自己。我的生活就像动画片、电视剧一样,有着主线任务、支线任务以及番外篇。在主线剧情中反复穿插番外篇以及支线任务。作为一名研究生,主线任务就比较明显啦。一年四季在科研。这一年来也让我从一个科研小白变成了一个知道怎么去讲好一个故事,写出一篇完整论文的大白。与此同时,也分别在6月份和10月份开启了两个支线任务:写博客和实习。
而在此刻(2025.12.30),我也会开始回忆这一整年,以博客的形式呈现这一整年,希望26年的自己回首这一年,不会遗憾,如果有遗憾,也希望更加努力,朝着更好的自己前进。
第一篇章:过去
主线任务
科研起步就是阅读大量文献,来找到一个合适的idea。本人是一个比较有强迫症的人,喜欢把所有的东西都整理的整整齐齐,这当然也包括了我的文献。我将我所准备看的文献、看完的文献,通过Zotero管理。
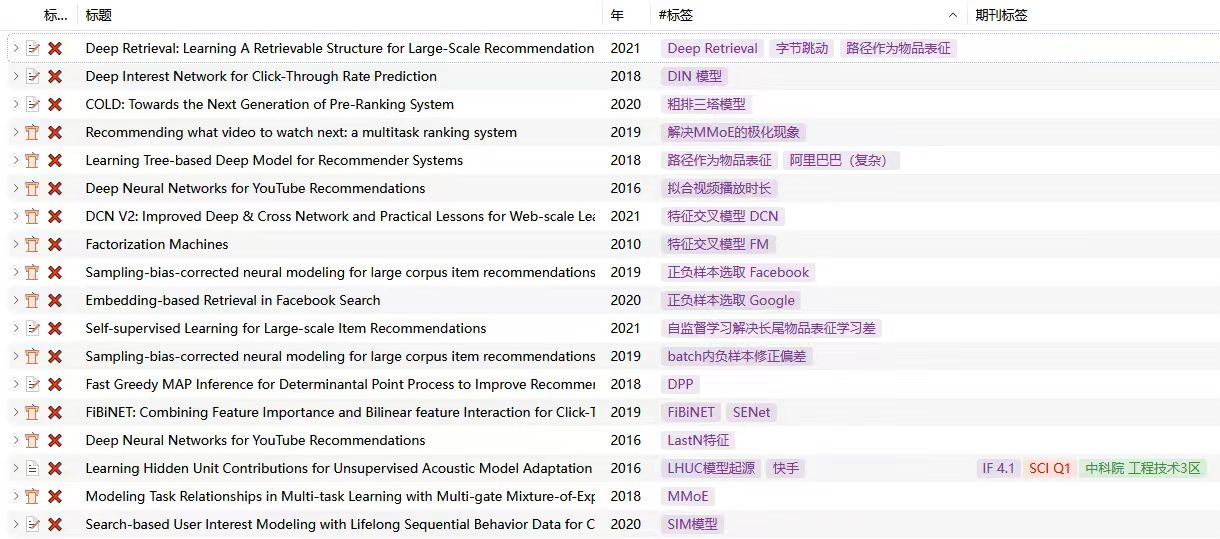
一般来说,发表的论文都是经过了一定的时间周期,在我们看到的这篇论文时,可能这个创新点或者说这个领域又出现了很多新的工作。因此除了在顶会顶刊上了解如何写好一篇工作的同时,还需要去arxiv上了解最新的工作。为此,我也是用python写了一个脚本,去通过关键词获取最新的论文。
例如我的研究领域是人脸伪造(Face Forgery)我会把forgery作为关键词去检索文献

- 获取文献的代码(如果有代码需求欢迎索取!)
def load_papers(self):
url = "http://export.arxiv.org/api/query?search_query=all:cs.AI&start=0&max_results=2000&sortBy=lastUpdatedDate"
response = requests.get(url)
if response.status_code != 200:
QMessageBox.warning(self, "错误", "无法获取论文数据")
return
import xml.etree.ElementTree as ET
root = ET.fromstring(response.text)
new_papers = []
existing_ids = {p['id'] for p in self.paper_data}
for entry in root.findall("{http://www.w3.org/2005/Atom}entry"):
paper_id = entry.find("{http://www.w3.org/2005/Atom}id").text
if paper_id in existing_ids:
continue
title = entry.find("{http://www.w3.org/2005/Atom}title").text.strip().replace("\n", " ")
summary = entry.find("{http://www.w3.org/2005/Atom}summary").text.strip()
updated = entry.find("{http://www.w3.org/2005/Atom}updated").text
authors = [author.find("{http://www.w3.org/2005/Atom}name").text for author in
entry.findall("{http://www.w3.org/2005/Atom}author")]
categories = [cat.attrib['term'] for cat in entry.findall("{http://arxiv.org/schemas/atom}category")]
new_papers.append({
"id": paper_id,
"title": title,
"summary": summary,
"updated": updated,
"authors": authors,
"categories": categories,
"new": True
})
self.paper_data = new_papers + self.paper_data
self.save_local_data()
self.display_papers()慢慢的,我找到了自己的第一个研究方向:人脸攻击。我开始去通过各种方法尝试加攻击扰动。通过频域,通过flow算法,通过相位噪声。如图所示,失败的工作不止这一个,在此期间尝试了许多的工作,但都失败告终。
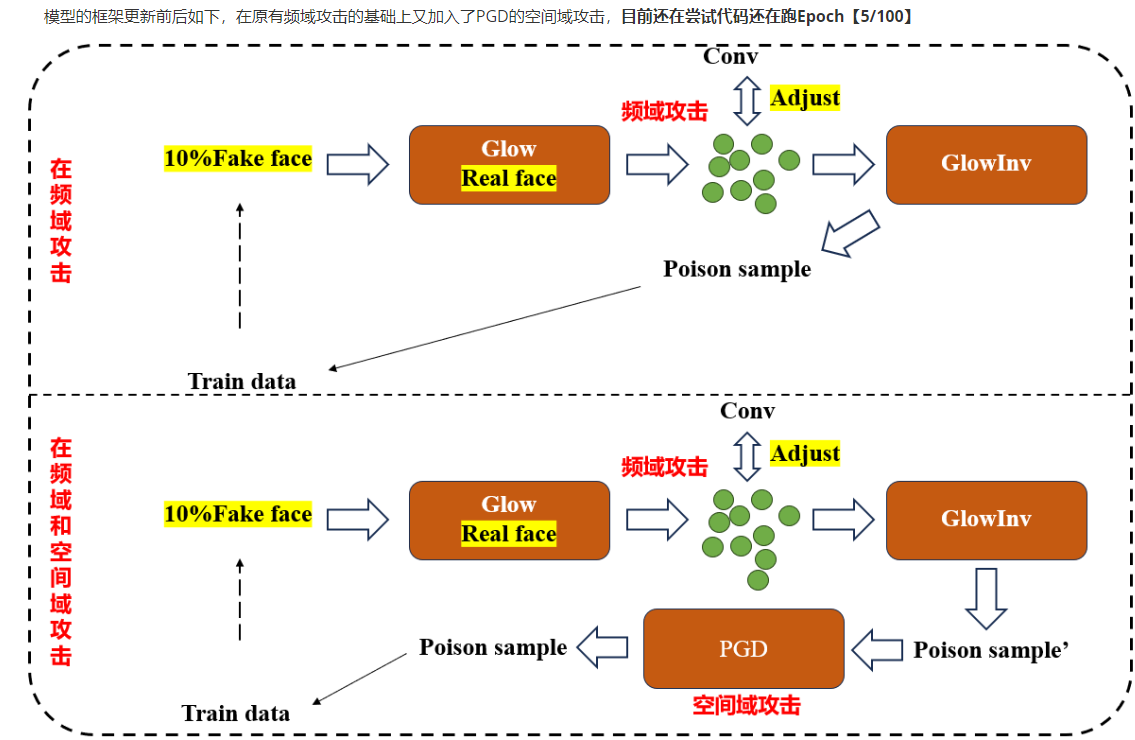
终于到了今年三月份,我的工作有了一定的进展,我的攻击方法在保证了攻击率的同时大幅度提升了图像质量。从此刻开始,主线任务也开始从找idea做实验转到了论文的撰写。实话说,有了ai的加持,英文论文的撰写也没有了以前那么困难了,只需要把我们想要表达的意思告诉他,然后自己阅读一遍再修改就可以了。
正当我自信满满的把我的初稿交给老师时,结果却是不尽人意。他直接掏出了他的口头禅:三秒就给我拒了,我也愣了一下。他指出了我论文的各种毛病,但他就是不会看技术和实验,更重要的是逻辑和写作,说写好一篇论文就是要写好一个故事,SOTA只是门槛(至少我现在已经认可了这一点)。
后来,在冲刺阶段,老师也请到了师兄给我修改,实话说,这是我最醍醐灌顶的一次。我知道了逻辑的重要性,知道了怎么去让一个审稿人更好的了解我们做了什么,怎么做的。我的论文就这样子反反复复修改了两三个月,在八月也是在AAAI投出了我的处女作。
支线任务——面试
在投完论文后,我也没闲着,一边开始寻找下一个工作以及实习面试。投递岗位的过程还算比较顺利,一共得到百度和B站两个多模态算法岗的面试机会。B站的面试官都很专业,也很遗憾自己并没有准备好再去面试,也是在二面的时候挂掉了。

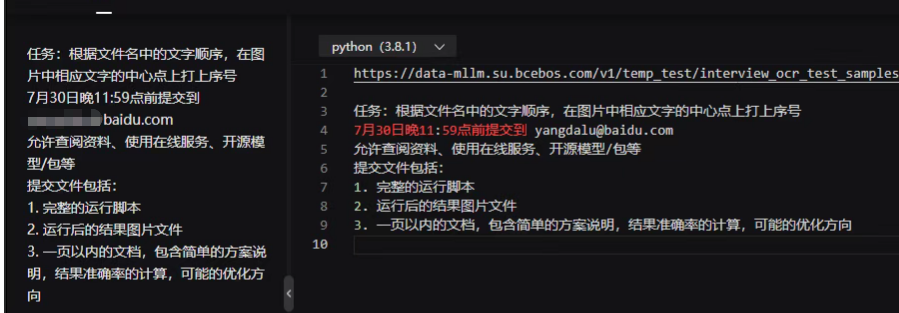
百度的面试就比较奇怪了,它在面试后还通过一种实操的方式,留作业的方式来决定是否进入下一面。一共面了三轮,留了两次作业。但是到了最后,他那个hr直接跟我说了岗位pedding了,感觉自己好像被骗了(自己就好像免费劳动力),但是那些面试官的邮箱确实是百度邮箱。我也留了一些作业的记录:
HR的相关回复:
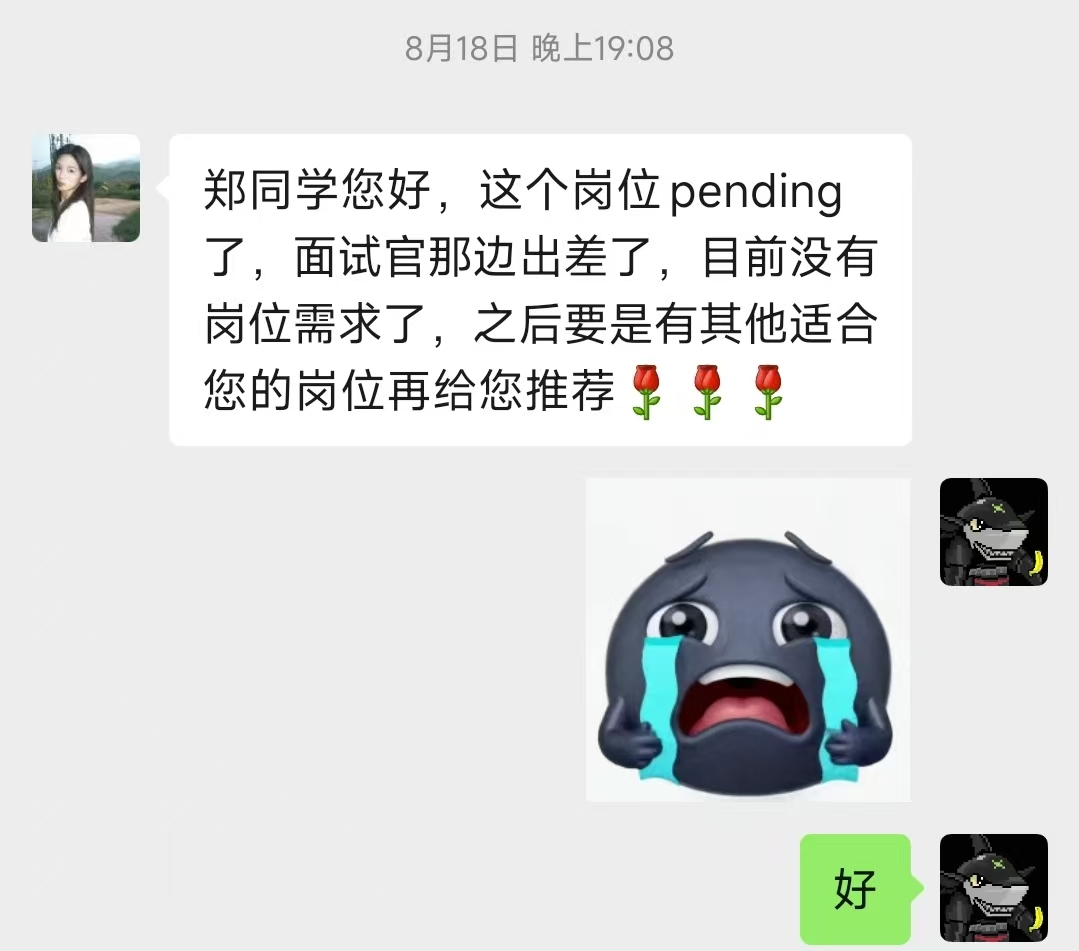
因为百度这个过程还是比较奇怪的,也希望有了解套路的人为我解答一下。
番外篇——数学建模
九月份,一年一度的研究生数学建模竞赛,华为杯开始了。对于大学生,研究生来说数学建模比赛基本都是鏖战了。我从本科到现在也算是一个数学建模的老手了,一下子就确定了选题。最后的结果还算是比较满意的,拿到了二等奖,有点可惜的是差10名就可以拿到了一等奖。

- 数学建模经验分享
数学建模考验的是:方法完整性、排版。创新度远远比这两个重要程度低。
九月同时也是AAAI一轮审稿结果下来的日子。我开始对结果不是那么的看重了,因为我知道,好像自己的实验也不完整。事实就是如此,第一轮的结果评分是665,直接被拒了。我也不找借口,也开始看审稿人的意见,给的都比较中肯,也正如我所说的,实验还差一点。也有一些比我低分的人进了二轮,这时我也才知道,不仅仅要说服审稿人,文章的内容还要符合AC的口味。
第二篇章:现在
主线任务
在第一个科研工作结束后,我也一直在寻找着第二个工作idea。尝试了很多,一开始还踏入了一个深坑——人脸伪造视频检测。当时我复现了很多工作,几乎没有工作可以复现的,包括SOTA工作也是不开源的。在2021年、2023年的经典工作基本都是复现不到论文的精度。当时我真的很气愤,自己花了很大的精力复现,0个工作可以给我作为baseline。我通过各种方式联系作者,同行,均以失败告终,这样不得不让我换一个方向。
幸运的是,新的方向还比较顺利,最近也在开始攥写论文了,这次我也将以更完整的工作、实验攥写我的工作,同时也完善了被拒的AAAI的论文。希望这次均能有一个好的结果。

支线任务——实习
在十月份,我又开始了自己的求职之旅,这次比较幸运,拿到了唯品会多模态的offer。组内的资源也比较丰厚。只可惜,与老师商量无果。
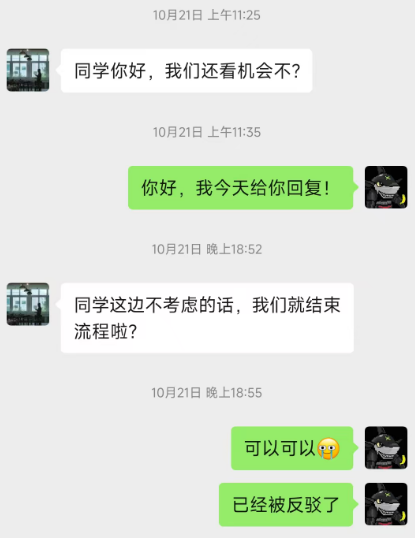
但我也深知,现在计算机岗位没有实习很难找到一个好的工作,更何况是我这种双非硕。
于是乎,本人开始偷跑,偷偷找了一家本地的企业,每天都在苟活着。一边观察着导师的微信步数,一边在跑到公司实习。幸运的是,我们小组是一个新项目组,对于考勤要求不高,每天可以睡的比较晚在过去。
公司的环境也还过得去:

项目组主要做的是网络安全智能体开发(快手事件)。由于目前还是起步阶段,组内还得靠着三个实习生摸索,通过调API来实现这个智能体。
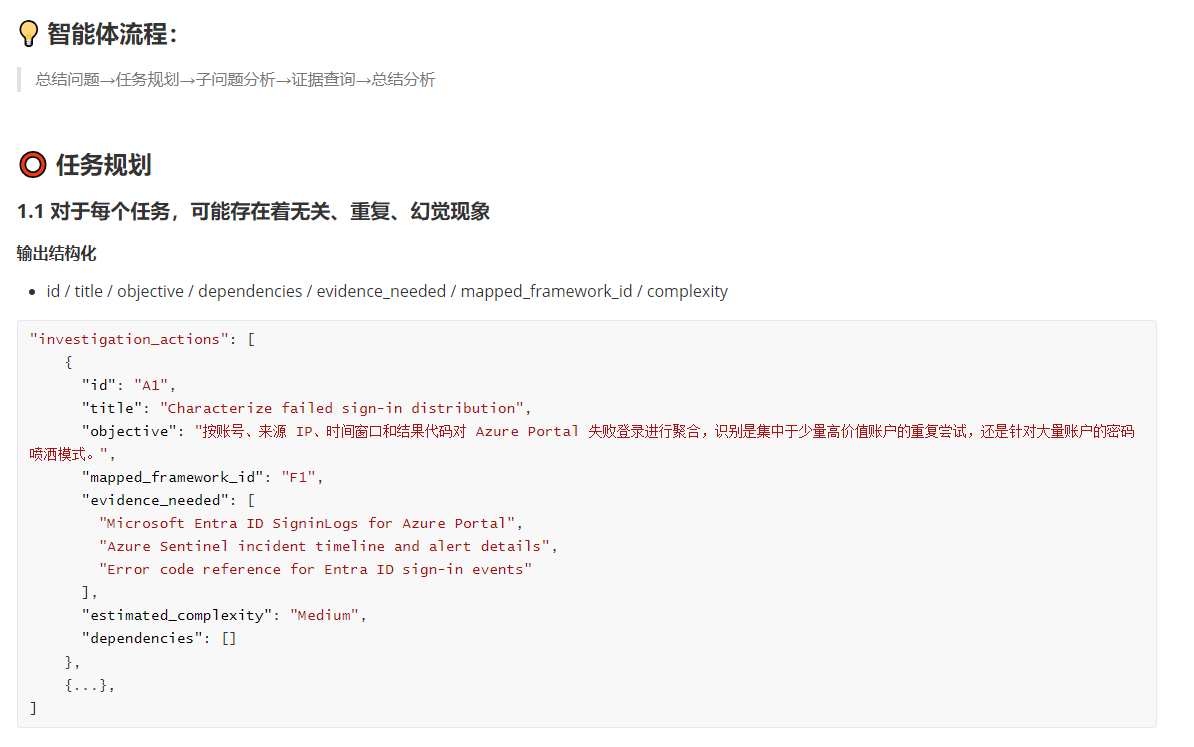
第三篇章:未来
我一直在和我朋友说,我看不见自己的未来。我到现在还不知道自己未来会干嘛,我没有一个明确的目标,我从来都是走一步看一步的人。我习惯去做好当下,再去根据实际情况展望未来。这个时候,也已经是2025年0时35分,距离这一年的过去还只剩下不到24小时。我一直相信,上天不会辜负努力的人,自己的努力也终会被看见。最近我有一种很强烈的预感:26年会是我命运的转折点。我也希望,这一年的努力,会26年成为转折点的关键。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
