MYSQL实战:深入理解内存临时表优化
原创


在日常的数据库运维中,你是否遇到过这种情况:一个看起来并不复杂的查询,在数据量稍微增大时就突然变得异常缓慢?你检查了索引,看起来都挺合理,但查询性能就是上不去。这很可能是因为你的SQL查询内存临时表造成的问题,今天给大家聊聊内存临时表相关的实战技巧,希望对大家能有所帮助!
什么是内存临时表?
简单来说,当MySQL执行某些类型的查询时(比如包含GROUP BY、DISTINCT、排序或者UNION),它可能需要创建一个内部临时表来存储中间计算结果。
这个临时表有个特点:优先在内存中创建,但如果大小超过了某个阈值,就会被转换成磁盘临时表。而一旦发生这种转换,性能就会急剧下降,因为磁盘I/O的速度比内存操作慢几个数量级。
实战案例
首先我们先来创建测试数据,然后模拟一下实际效果
创建测试表结构
-- 用户表
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
INDEX idx_username (username),
INDEX idx_created (created_at)
);
-- 订单表
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL,
amount DECIMAL(10,2) NOT NULL,
status ENUM('pending', 'completed', 'cancelled') NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
INDEX idx_user_id (user_id),
INDEX idx_created_status (created_at, status)
);用户表
订单表
插入测试数据
-- 插入10万用户
DELIMITER $$
CREATE PROCEDURE InsertUsers()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 100000 DO
INSERT INTO users (username, email, created_at)
VALUES (CONCAT('user', i), CONCAT('user', i, '@example.com'),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 365) DAY));
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL InsertUsers();
DROP PROCEDURE InsertUsers;
-- 插入100万订单数据
DELIMITER $$
CREATE PROCEDURE InsertOrders()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE user_count INT;
SELECT COUNT(*) INTO user_count FROM users;
WHILE i <= 1000000 DO
INSERT INTO orders (user_id, amount, status, created_at)
VALUES (FLOOR(1 + RAND() * user_count),
ROUND(RAND() * 1000, 2),
ELT(FLOOR(1 + RAND() * 3), 'pending', 'completed', 'cancelled'),
DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 365) DAY));
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL InsertOrders();
DROP PROCEDURE InsertOrders;
问题查询场景
首先执行一个看起来合理的业务查询:统计最近一个月每个用户的订单总金额,并按金额降序排列。
SELECT
u.username,
SUM(o.amount) as total_amount,
COUNT(o.id) as order_count
FROM users u
INNER JOIN orders o ON u.id = o.user_id
WHERE o.created_at >= DATE_SUB(NOW(), INTERVAL 30 DAY)
AND o.status = 'completed'
GROUP BY u.id, u.username
ORDER BY total_amount DESC
LIMIT 1000;这个查询在测试环境中运行了8.7秒,对于交互式应用来说完全不可接受。
诊断问题:临时表在哪里?
使用EXPLAIN分析执行计划:
EXPLAIN
SELECT
u.username,
SUM(o.amount) as total_amount,
COUNT(o.id) as order_count
FROM users u
INNER JOIN orders o ON u.id = o.user_id
WHERE o.created_at >= DATE_SUB(NOW(), INTERVAL 30 DAY)
AND o.status = 'completed'
GROUP BY u.id, u.username
ORDER BY total_amount DESC
LIMIT 100;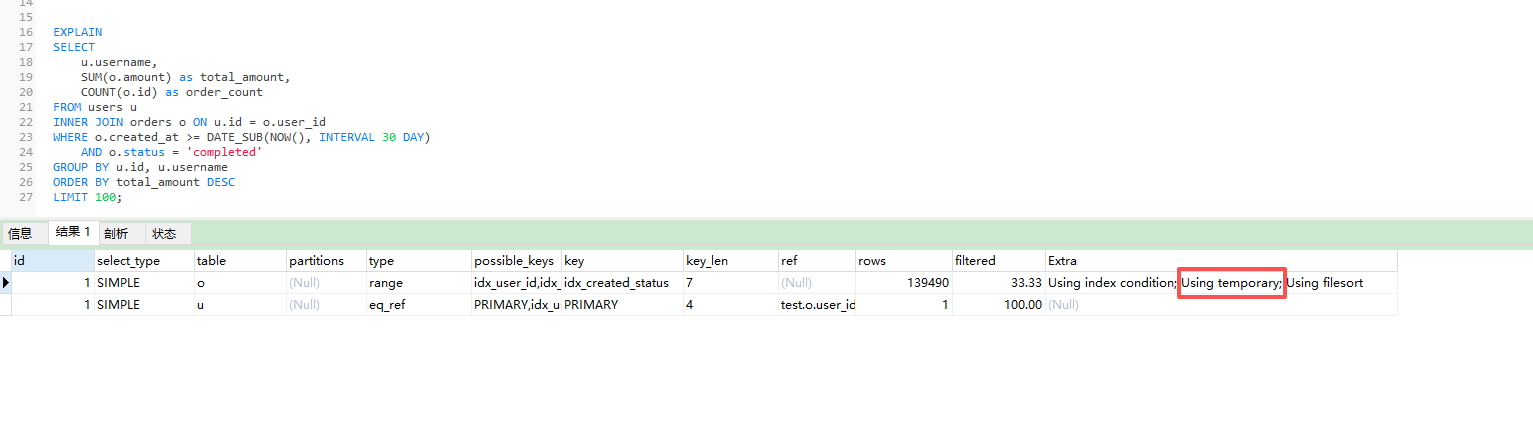
在输出中,我们要特别关注Extra列,如果看到Using temporary和Using filesort,就说明MySQL创建了临时表来进行分组和排序。
更详细地,我们可以查看临时表的使用情况:
-- 查看临时表配置
SHOW VARIABLES LIKE 'tmp_table_size';
SHOW VARIABLES LIKE 'max_heap_table_size';
-- 在另一个会话中监控临时表创建
SHOW STATUS LIKE 'Created_tmp%';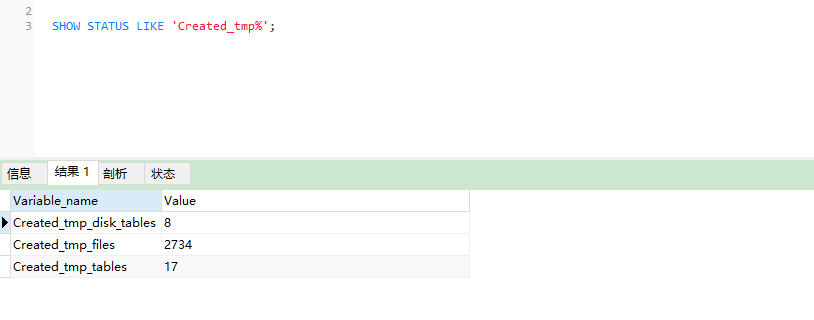
可以直接看到,当执行复杂查询时,Created_tmp_disk_tables和Created_tmp_tables计数器在增加,这证实了临时表的存在。
优化策略:避免临时表产生
方法一:优化索引设计
临时表产生的主要原因是在无法有效利用现有索引的情况下。上面的实例中,问题在于orders表缺少一个覆盖查询条件的复合索引。
-- 建议删除可能存在的低效索引
DROP INDEX idx_created_status ON orders;
-- 创建更适合的复合索引
CREATE INDEX idx_orders_covering ON orders (status, created_at, user_id, amount);该索引包含了查询所需的所有字段,MySQL可以直接从索引中获取数据,避免回表操作,也减少了临时表的大小。
方法二:调整SQL写法
SQL本身的写法也会造成性能差距很大。
-- 原查询(性能差)
SELECT
u.username,
SUM(o.amount) as total_amount,
COUNT(o.id) as order_count
FROM users u
INNER JOIN orders o ON u.id = o.user_id
WHERE o.created_at >= DATE_SUB(NOW(), INTERVAL 30 DAY)
AND o.status = 'completed'
GROUP BY u.id, u.username
ORDER BY total_amount DESC
LIMIT 100;
-- 优化后的查询:先聚合再连接
SELECT
u.username,
ot.total_amount,
ot.order_count
FROM users u
INNER JOIN (
SELECT
user_id,
SUM(amount) as total_amount,
COUNT(id) as order_count
FROM orders
WHERE created_at >= DATE_SUB(NOW(), INTERVAL 30 DAY)
AND status = 'completed'
GROUP BY user_id
) ot ON u.id = ot.user_id
ORDER BY ot.total_amount DESC
LIMIT 100;说明:先在子查询中完成对orders表的分组聚合,这个中间结果集通常比原始连接结果小得多,然后再与users表连接,可以大大减少了临时表的大小。
方法三:调整系统参数(新手谨慎使用)
针对某些特定场景如果确定某些查询确实需要较大的临时表,可以临时调整参数:
-- 增大内存临时表的大小限制(当前会话有效)
SET SESSION tmp_table_size = 256 * 1024 * 1024; -- 256MB
SET SESSION max_heap_table_size = 256 * 1024 * 1024;注意:这种方法要谨慎使用,过大的设置可能导致内存耗尽。
什么时候需要警惕临时表?

以下场景容易产生临时表问题:
- 复杂的GROUP BY和DISTINCT:特别是涉及多表连接的分组操作
- UNION查询:UNION默认会去重,需要临时表
- 没有索引的排序:ORDER BY字段没有合适的索引
- 子查询:某些类型的子查询会被优化器转换为临时表
- 派生表:FROM子句中的子查询
总结
内存临时表是MySQL查询优化中经常被忽视但对于查询性能的影响也是非常重要的,希望本篇文章能够给大家实际使用过程中提供一些帮助!
通过本文的实战案例,我们希望你能掌握:
五个备选文章标题:
- 《MySQL性能暗礁:深入理解内存临时表优化》
- 《从8秒到0.3秒:一次临时表优化的完整实战》
- 《GROUP BY为什么慢?揭开内存临时表的秘密》
- 《MySQL查询突然变慢的元凶:磁盘临时表诊断与优化》
- 《中级DBA必备技能:MySQL临时表性能调优实战》
希望这篇文章能为你提供有价值的参考。在实际工作中遇到类似问题时,不妨从临时表的角度去分析和优化,可能会有意想不到的收获。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
