【详解】Mycat程序指定分区分片
原创
【详解】Mycat程序指定分区分片
原创
大盘鸡拌面
发布于 2025-12-31 10:14:12
发布于 2025-12-31 10:14:12
Mycat程序指定分区分片
前言
在大数据时代,数据库的性能和扩展性成为了许多应用的关键问题。为了应对这些问题,数据库分库分表(Sharding)技术应运而生。Mycat是一个开源的分布式数据库系统,它支持SQL解析、数据分片等功能,能够有效地帮助用户解决数据库扩展性和高可用性的问题。本文将详细介绍如何在Mycat中配置分区分片。
什么是Mycat?
Mycat,原名Atlas,是阿里云开发的一个开源项目,后成为独立项目。它是一个基于Java实现的MySQL代理层,可以看作是MySQL的一个增强版本。Mycat主要功能包括但不限于:
- 读写分离:通过配置主从复制,实现读写分离。
- 分库分表:支持水平拆分,即分库分表,以提高系统的处理能力和存储能力。
- SQL解析与优化:支持SQL语句的解析和部分优化。
- 高可用性:支持多节点部署,提高系统的可用性和稳定性。
分区分片的基本概念
分区(Partitioning)
分区是指在一个数据库内部,根据一定的规则将一个大表的数据分割成多个较小的部分,这些部分可以存储在同一个数据库的不同物理位置上。分区的主要目的是提高查询效率和管理大型数据库的能力。
分片(Sharding)
分片是指将一个数据库的数据分布在多个数据库实例上,每个实例称为一个分片。分片不仅可以提高系统的可扩展性,还可以通过增加更多的硬件资源来提升系统的处理能力。
Mycat中的分区分片配置
配置文件简介
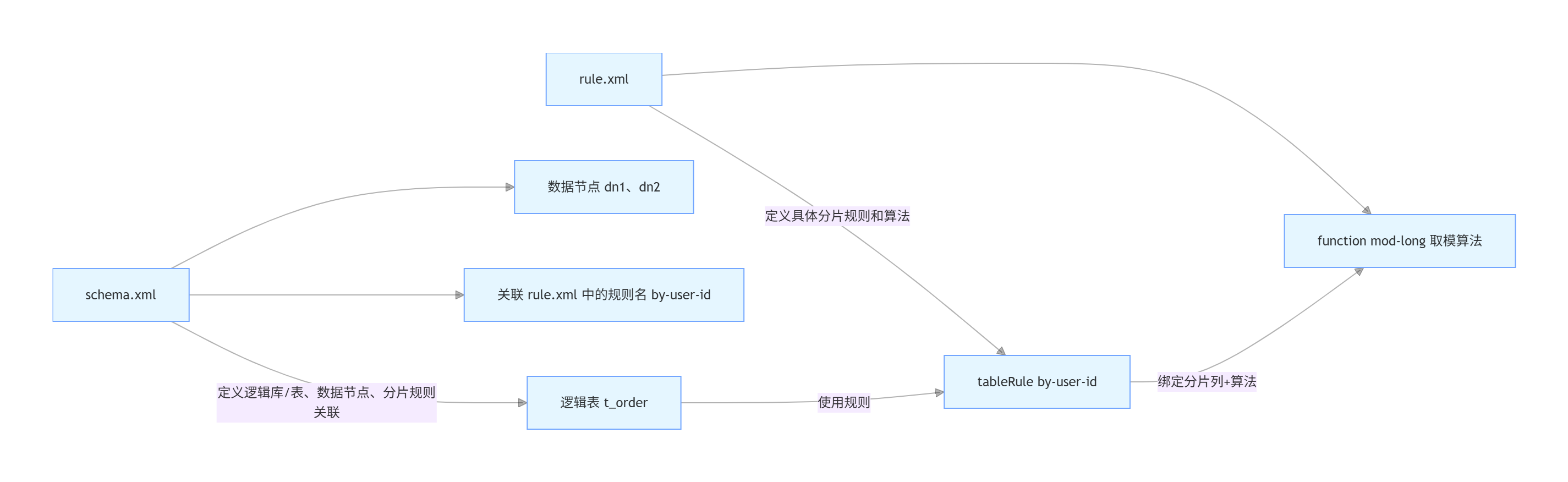
Mycat的配置主要通过几个XML文件完成,其中最重要的两个文件是schema.xml和rule.xml。
- schema.xml:定义了逻辑数据库、表、分片规则等信息。
- rule.xml:定义了具体的分片策略,如哈希算法、范围算法等。
示例配置
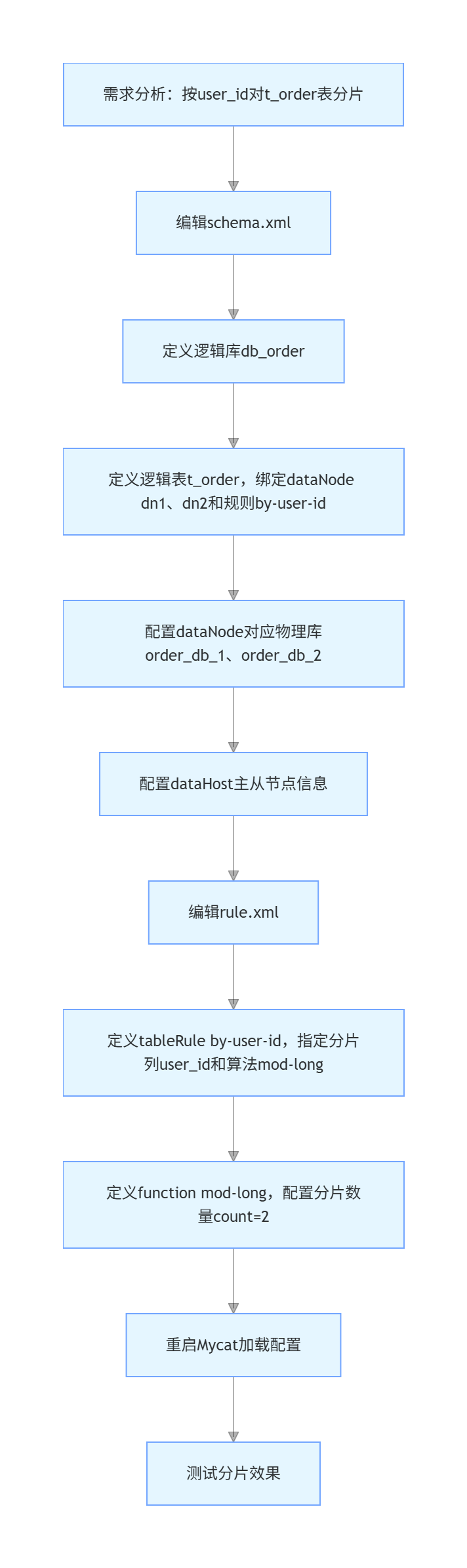
假设我们有一个订单系统,需要对订单表进行分片。我们将订单表按照用户ID进行分片,每100个用户ID为一个分片单位。
1. 编辑 schema.xml
首先,在schema.xml中定义逻辑数据库和表,并指定分片规则。
<schema name="db_order" checkSQLSchema="false" sqlMaxLimit="100">
<table name="t_order" dataNode="dn1,dn2" rule="by-user-id"/>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="order_db_1"/>
<dataNode name="dn2" dataHost="localhost1" database="order_db_2"/>
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456">
<readHost host="hostS1" url="localhost:3307" user="root" password="123456"/>
</writeHost>
</dataHost>2. 编辑 rule.xml
接下来,在rule.xml中定义具体的分片策略。
<tableRule name="by-user-id">
<rule>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">2</property>
</function>在这个例子中,我们使用了mod-long函数,它根据user_id对2取模的结果来决定数据应该存储在哪一个分片中。
测试分片效果
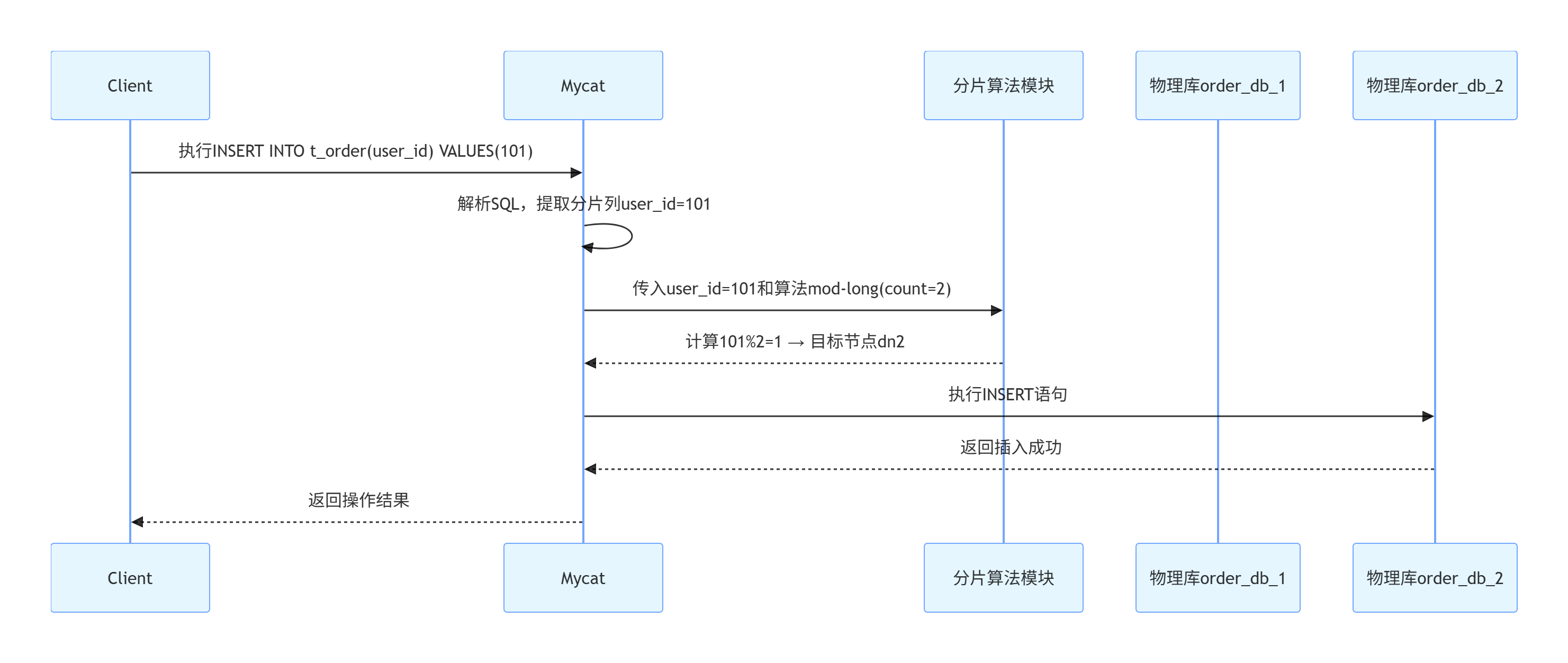
配置完成后,可以通过执行一些SQL语句来测试分片的效果。例如:
INSERT INTO t_order (order_id, user_id, amount) VALUES (1, 101, 100.0);
INSERT INTO t_order (order_id, user_id, amount) VALUES (2, 201, 200.0);执行上述SQL后,可以检查order_db_1和order_db_2中的数据分布情况,验证分片是否按预期工作。
下面是一个简单的示例,展示如何在 Mycat 中配置分区分片规则。假设我们有一个电商系统,需要对订单表 order 进行分区分片,以提高查询效率和处理能力。
1. 配置 Mycat 的 schema.xml
首先,我们需要在 schema.xml 文件中定义数据库、表以及分片规则。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 定义数据库节点 -->
<dataHost name="dh1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://192.168.1.1:3306/db1" user="root" password="password">
<readHost host="hostS1" url="jdbc:mysql://192.168.1.2:3306/db1" user="root" password="password"/>
</writeHost>
</dataHost>
<!-- 定义数据库分片 -->
<schema name="db" checkSQLschema="false" sqlMaxLimit="100">
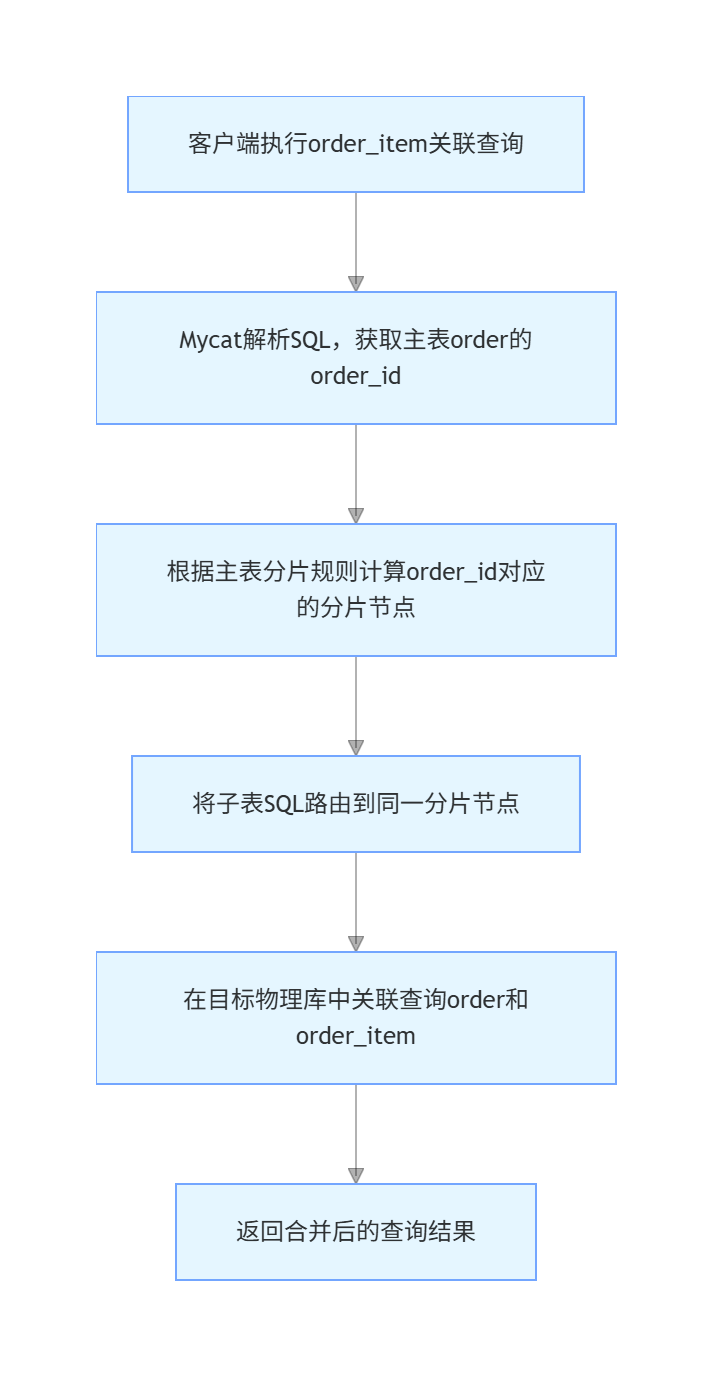
<table name="order" dataNode="dn1,dn2" rule="mod-long">
<childTable name="order_item" primaryKey="id" joinKey="order_id" parentKey="id" />
</table>
</schema>
<!-- 定义数据节点 -->
<dataNode name="dn1" dataHost="dh1" database="db1" />
<dataNode name="dn2" dataHost="dh1" database="db2" />
<!-- 定义分片规则 -->
<tableRule name="mod-long">
<rule>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<!-- 定义分片算法 -->
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">2</property>
</function>
</mycat:schema>2. 解释配置文件
- dataHost: 定义了数据库主机,包括主从复制的配置。
- schema: 定义了逻辑数据库,这里命名为
db。 - table: 定义了表
order,并指定了数据节点 dn1 和 dn2,以及分片规则 mod-long。 - dataNode: 定义了数据节点,分别对应不同的物理数据库实例。
- tableRule: 定义了分片规则,使用
mod-long 算法。 - function: 定义了分片算法,这里使用
PartitionByMod,表示按 user_id 取模分片。
3. 应用场景
假设我们有以下订单表结构:
CREATE TABLE `order` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`user_id` BIGINT(20) NOT NULL,
`order_amount` DECIMAL(10, 2) NOT NULL,
`create_time` DATETIME NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;根据上述配置,当插入或查询 order 表时,Mycat 会根据 user_id 的值进行取模运算,将数据分配到不同的物理数据库实例中。
例如:
- 如果
user_id 是 1,则数据会被路由到 db1。 - 如果
user_id 是 2,则数据会被路由到 db2。
4. 插入数据示例
INSERT INTO order (user_id, order_amount, create_time) VALUES (1, 100.00, NOW());
INSERT INTO order (user_id, order_amount, create_time) VALUES (2, 200.00, NOW());5. 查询数据示例
SELECT * FROM order WHERE user_id = 1;
SELECT * FROM order WHERE user_id = 2;通过这种方式,Mycat 能够有效地将数据分散到不同的数据库实例中,提高系统的整体性能和可扩展性。Mycat 是一个开源的分布式数据库系统,它主要作用于解决数据库的读写分离、分库分表等问题。在 Mycat 中,数据的分片(Sharding)是通过配置文件来实现的,特别是 schema.xml 文件。这个文件定义了逻辑数据库、逻辑表、物理数据库以及分片规则等信息。
分区与分片的概念
- 分区:指的是将一个大的数据库分成多个较小的数据库实例,每个实例称为一个分区。
- 分片:指的是将一张大的表分割成多张小表,这些小表存储在不同的数据库实例中,每个小表称为一个分片。
配置文件 schema.xml
schema.xml 文件是 Mycat 中非常重要的配置文件之一,用于定义数据库的逻辑结构和分片策略。以下是一个简单的 schema.xml 示例:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 定义逻辑数据库 -->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="order" dataNode="dn1,dn2" rule="auto-sharding-long"/>
</schema>
<!-- 定义数据节点 -->
<dataNode name="dn1" dataHost="localhost1" database="testdb1"/>
<dataNode name="dn2" dataHost="localhost2" database="testdb2"/>
<!-- 定义数据源 -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="root" password="password">
<readHost host="hostS1" url="localhost:3307" user="root" password="password"/>
</writeHost>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="localhost:3308" user="root" password="password">
<readHost host="hostS2" url="localhost:3309" user="root" password="password"/>
</writeHost>
</dataHost>
<!-- 定义分片规则 -->
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<!-- 定义算法 -->
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">2</property>
</function>
</mycat:schema>关键配置解析
- 逻辑数据库 (
schema):
-
name: 逻辑数据库的名称。 -
checkSQLschema: 是否检查 SQL 语句中的数据库名。 -
sqlMaxLimit: 单个 SQL 语句的最大返回行数。
- 逻辑表 (
table):
-
name: 逻辑表的名称。 -
dataNode: 数据节点的名称,可以指定多个数据节点,用逗号分隔。 -
rule: 分片规则的名称。
- 数据节点 (
dataNode):
-
name: 数据节点的名称。 -
dataHost: 数据主机的名称。 -
database: 物理数据库的名称。
- 数据主机 (
dataHost):
-
name: 数据主机的名称。 -
maxCon: 最大连接数。 -
minCon: 最小连接数。 -
balance: 负载均衡策略。 -
writeType: 写操作类型。 -
dbType: 数据库类型(如 MySQL)。 -
dbDriver: 数据库驱动类型。 -
switchType: 切换类型。 -
slaveThreshold: 从库延迟阈值。
- 心跳检测 (
heartbeat):
- 用于检测数据库连接是否正常。
- 写主节点 (
writeHost) 和 读从节点 (readHost):
-
host: 主机名或 IP 地址。 -
url: 数据库连接 URL。 -
user: 数据库用户名。 -
password: 数据库密码。
- 分片规则 (
tableRule):
-
name: 分片规则的名称。 -
columns: 参与分片的列名。 -
algorithm: 分片算法的名称。
- 分片算法 (
function):
-
name: 分片算法的名称。 -
class: 实现分片算法的类。 -
property: 分片算法的参数。
示例解释
在这个示例中,TESTDB 是一个逻辑数据库,包含一个名为 order 的逻辑表。这个表的数据被分片到两个数据节点 dn1 和 dn2 上,分片规则是根据 id 列的值进行取模运算,模数为 2。这意味着 id 为偶数的记录会被分到 dn1,而 id 为奇数的记录会被分到 dn2。
总结
通过 schema.xml 文件,Mycat 可以灵活地配置数据库的分片策略,从而实现数据的水平扩展和负载均衡。理解并正确配置 schema.xml 是使用 Mycat 进行数据库分片的关键。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号