【C语言】C语言指针题目实战:经典例题 + 解题思路,新手也能轻松看懂

【C语言】C语言指针题目实战:经典例题 + 解题思路,新手也能轻松看懂

小年糕是糕手
发布于 2026-01-14 14:33:29
发布于 2026-01-14 14:33:29
一、数组指针笔试题解析
在学习这部分内容之前我们先来回顾一下数组名的意义:
数组名的意义: 1. sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。 2. &数组名,这里的数组名表示整个数组,取出的是整个数组的地址。 3. 除此之外所有的数组名都表示首元素的地址。
1、一维数组
下面给出的代码希望大家先去自行写出运行结果并解释,我也会为大家贴出解析供大家参考
代码一:
#include<stdio.h>
int main()
{
int a[] = { 1,2,3,4 };
printf("%zu\n", sizeof(a));
printf("%zu\n", sizeof(a + 0));
printf("%zu\n", sizeof(*a));
printf("%zu\n", sizeof(a + 1));
printf("%zu\n", sizeof(a[1]));
printf("%zu\n", sizeof(&a));
printf("%zu\n", sizeof(*&a));
printf("%zu\n", sizeof(&a + 1));
printf("%zu\n", sizeof(&a[0]));
printf("%zu\n", sizeof(&a[0] + 1));
return 0;
}解析
int a[] = { 1,2,3,4 };
printf("%zu\n", sizeof(a));// 4 * 4 = 16
//a是数组名,数组名单独放在sizeof中,数组名表示整个数组,计算的是整个数组的大小,单位是字节
printf("%zu\n", sizeof(a + 0));// 4/8(X64与X86环境不同)
//a是数组名,但是并没有单独放在sizeof内部,也没有&,不符合俩种特殊情况,所以a就是首元素的地址
//a + 0,还是首元素的地址,sizeof(a + 0)计算的是一个地址的大小,即为4/8(X64与X86环境不同)
printf("%zu\n", sizeof(*a));// 4
//不是特殊情况,a就相当于&a[0],*a就相当于*&a[0],就是首元素(整数1),所以sizeof(*a)就是四个字节
printf("%zu\n", sizeof(a + 1));// 4/8(X64与X86环境不同)
//不是特殊情况,a就是首元素的地址,a + 1就是第二个元素的地址,sizeof(a + 1)计算的是地址的大小
printf("%zu\n", sizeof(a[1]));// 4
//a[1]就是数组的第二个元素,大小是四个字节,只有地址才是4/8个字节
printf("%zu\n", sizeof(&a));// 4/8(X64与X86环境不同)
//特殊情况取出的是整个数组的地址,数组的地址也是地址,只要是地址大小就是四个或者八个字节
//&的特殊性,体现在+ -整数这一块,int(*p)[4] = &a
printf("%zu\n", sizeof(*&a));// 16
//*&a == a 就变成了与第一个相同的了
//&a取出的是数组的地址,它的类型是int(*)[4],对于数组指针解引用,访问的是这个数组,大小就是整个数组
printf("%zu\n", sizeof(&a + 1));// 4/8(X64与X86环境不同)
//&a是数组的地址,&a + 1就是跳过整个数组后的地址,是地址大小就是四个或者八个字节
printf("%zu\n", sizeof(&a[0]));// 4/8(X64与X86环境不同)
//&a[0]就是第一个元素的地址,是地址大小就是四个或者八个字节
printf("%zu\n", sizeof(&a[0] + 1));// 4/8(X64与X86环境不同)
//&a[0] + 1就是数组第二个元素的地址,是地址大小就是四个或者八个字节
return 0;2、字符数组
代码一:
#include <stdio.h>
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%zu\n", sizeof(arr));
printf("%zu\n", sizeof(arr + 0));
printf("%zu\n", sizeof(*arr));
printf("%zu\n", sizeof(arr[1]));
printf("%zu\n", sizeof(&arr));
printf("%zu\n", sizeof(&arr + 1));
printf("%zu\n", sizeof(&arr[0] + 1));
return 0;
}解析
char arr[] = { 'a','b','c','d','e','f' };
printf("%zu\n", sizeof(arr));// 1 * 6 = 6
//特殊情况,arr表示整个数组,sizeof(arr)计算的就是整个数组的大小
printf("%zu\n", sizeof(arr + 0));// 4/8(X64与X86环境不同)
//非特殊情况,arr表示数组首元素的地址,只要是地址,大小就是四个或者八个字节
printf("%zu\n", sizeof(*arr));// 1 * 1 = 1
//非特殊情况,arr表示数组首元素的地址,所以*arr就表示首元素,sizeof(*arr)计算的是首元素的大小
printf("%zu\n", sizeof(arr[1]));// 1 * 1 = 1
//arr[1]就是第二个元素,大小就是一个字节
printf("%zu\n", sizeof(&arr));// 4/8(X64与X86环境不同)
//特殊情况,&arr取出的是数组的地址,只要是地址,大小就是四个或者八个字节
printf("%zu\n", sizeof(&arr + 1));// 4/8(X64与X86环境不同)
//&arr + 1是跳过整个数组后的地址,跳过之后依旧是地址,是地址大小就是四个或者八个字节
printf("%zu\n", sizeof(&arr[0] + 1));// 4/8(X64与X86环境不同)
//&arr[0] + 1就是第二个元素的地址,只要是地址,大小就是四个或者八个字节
return 0;代码二:
#include <stdio.h>
#include <string.h>
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%zu\n", strlen(arr));
printf("%zu\n", strlen(arr + 0));
printf("%zu\n", strlen(*arr));
printf("%zu\n", strlen(arr[1]));
printf("%zu\n", strlen(&arr));
printf("%zu\n", strlen(&arr + 1));
printf("%zu\n", strlen(&arr[0] + 1));
return 0;
}解析
char arr[] = { 'a','b','c','d','e','f' };
//要注意strlen只能求字符型
printf("%zu\n", strlen(arr));// 随机值
//非特殊情况arr表示数组首元素的地址,字符串中没有\0
printf("%zu\n", strlen(arr + 0));// 随机值(和第一个随机值相同)
//arr依旧是数组首元素的地址,再+0还是首元素的地址无\0
printf("%zu\n", strlen(*arr));// 程序崩溃
//*arr表示数组的首元素(a),a的ASCLL码值是97,非法访问内存
//我们应该传入的是地址,这里传入的是一个元素,不符合!!!
printf("%zu\n", strlen(arr[1]));// 程序崩溃
//我们应该传入的是地址,这里传入的是一个元素,非法访问内存
printf("%zu\n", strlen(&arr));// 随机值(和第一个随机值是一样的)
//&arr是数组的地址,从数组的起始位置开始向后数字符串的长度,要找\0,但是没有
printf("%zu\n", strlen(&arr + 1));// 随机值
//这个随机值应该与前面的随机值是有差异的(比第一个随机值小6)
printf("%zu\n", strlen(&arr[0] + 1));// 随机值
//&arr[0] + 1就是第二个元素的地址,依旧是随机值但是应该比第一个的随机值小1
return 0;代码三:
#include <stdio.h>
int main()
{
char arr[] = "abcdef";
printf("%zu\n", sizeof(arr));
printf("%zu\n", sizeof(arr + 0));
printf("%zu\n", sizeof(*arr));
printf("%zu\n", sizeof(arr[1]));
printf("%zu\n", sizeof(&arr));
printf("%zu\n", sizeof(&arr + 1));
printf("%zu\n", sizeof(&arr[0] + 1));
return 0;
}解析
char arr[] = "abcdef";
printf("%zu\n", sizeof(arr));// 1 * 7 = 7
//特殊情况,arr表示整个数组的大小,注意别漏掉\0共七个元素
printf("%zu\n", sizeof(arr + 0));// 4/8(X64与X86环境不同)
//非特殊情况,arr表示数组首元素的地址,arr + 0依旧是数组首元素的地址
printf("%zu\n", sizeof(*arr));// 1 * 1 = 1
//表示第一个元素即a,所以就是计算a的大小
printf("%zu\n", sizeof(arr[1]));// 1 * 1 = 1
//表示第二个元素即b,所以就是计算b的大小
printf("%zu\n", sizeof(&arr));// 4/8(X64与X86环境不同)
//特殊情况,表示整个数组的大小
printf("%zu\n", sizeof(&arr + 1));// 4/8(X64与X86环境不同)
//&arr + 1表示跳过整个数组地址之后的地址
printf("%zu\n", sizeof(&arr[0] + 1));// 4/8(X64与X86环境不同)
//表示第二个元素的地址
return 0;代码四:
#include <stdio.h>
#include <string.h>
int main()
{
char arr[] = "abcdef";
printf("%zu\n", strlen(arr));
printf("%zu\n", strlen(arr + 0));
printf("%zu\n", strlen(*arr));
printf("%zu\n", strlen(arr[1]));
printf("%zu\n", strlen(&arr));
printf("%zu\n", strlen(&arr + 1));
printf("%zu\n", strlen(&arr[0] + 1));
return 0;
}解析
char arr[] = "abcdef";
printf("%zu\n", strlen(arr));// 1 * 6 = 6
//strlen表示首元素的地址,strlen找的是\0之前的字符个数
printf("%zu\n", strlen(arr + 0));// 1 * 6 = 6
//数组名表示首元素的地址
printf("%zu\n", strlen(*arr));// 程序崩溃
//传入的是一个元素不是地址,会造成非法访问
printf("%zu\n", strlen(arr[1]));// 程序崩溃
//传入的是一个元素不是地址,会造成非法访问
printf("%zu\n", strlen(&arr));// 1 * 6 = 6
//传入的是整个数组的地址,但是地址我们是从第一个元素开始数的
printf("%zu\n", strlen(&arr + 1));// 随机值
//跳过了整个数组的地址,我们不知道下一行\0会在哪出现
printf("%zu\n", strlen(&arr[0] + 1));// 5
//&arr[0] + 1表示第二个元素,所以strlen统计的是\0之前到第二个元素之间的元素个数
return 0;代码五:
#include <stdio.h>
int main()
{
char* p = "abcdef";
printf("%zu\n", sizeof(p));
printf("%zu\n", sizeof(p + 1));
printf("%zu\n", sizeof(*p));
printf("%zu\n", sizeof(p[0]));
printf("%zu\n", sizeof(&p));
printf("%zu\n", sizeof(&p + 1));
printf("%zu\n", sizeof(&p[0] + 1));
return 0;
}解析
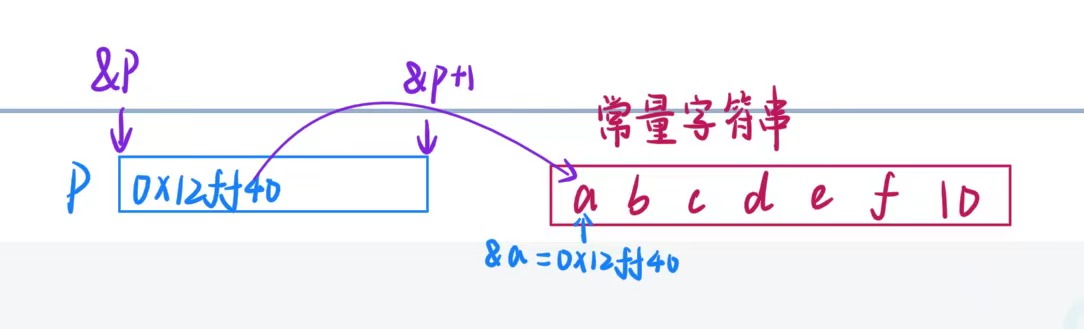
char* p = "abcdef";
printf("%zu\n", sizeof(p));// 4/8(X64与X86环境不同)
//p是一个指针变量,里面存放的是a的地址
printf("%zu\n", sizeof(p + 1));// 4/8(X64与X86环境不同)
//p + 1就是b的地址
printf("%zu\n", sizeof(*p));// 1
//p里面存放的是a的地址,*p即为a这个元素,即为计算a的大小
printf("%zu\n", sizeof(p[0]));// 1
//p[0] = *(p + 0) = *p
printf("%zu\n", sizeof(&p));// 4/8(X64与X86环境不同)
//&p是指针变量p的地址,是个二级指针,但本质上还是地址
printf("%zu\n", sizeof(&p + 1));// 4/8(X64与X86环境不同)
//如图所示
printf("%zu\n", sizeof(&p[0] + 1));// 4/8(X64与X86环境不同)
//&p[0] + 1是b的地址
return 0;代码六:
#include <stdio.h>
#include <string.h>
int main()
{
char* p = "abcdef";
printf("%zu\n", strlen(p));
printf("%zu\n", strlen(p + 1));
printf("%zu\n", strlen(*p));
printf("%zu\n", strlen(p[0]));
printf("%zu\n", strlen(&p));
printf("%zu\n", strlen(&p + 1));
printf("%zu\n", strlen(&p[0] + 1));
return 0;
}解析
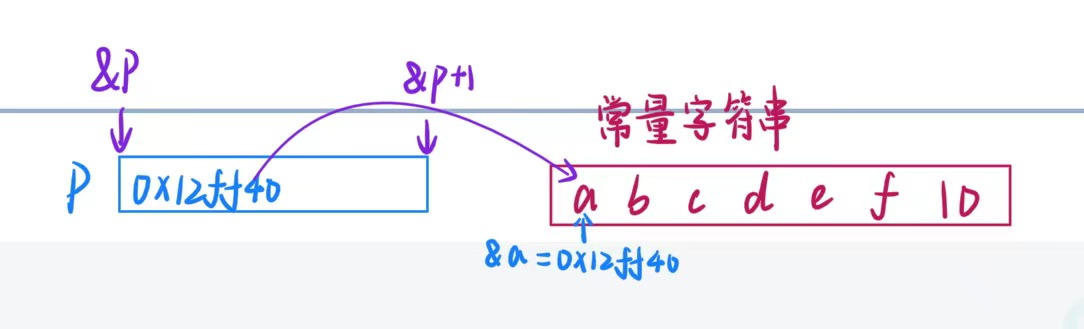
char* p = "abcdef";
printf("%zu\n", strlen(p));// 6
//传入的是a的地址,相当于从a开始往后数
printf("%zu\n", strlen(p + 1));// 5
//传入的是b的地址
printf("%zu\n", strlen(*p));// 程序崩溃
//传入的不是地址
printf("%zu\n", strlen(p[0]));// 程序崩溃
//传入的不是地址
printf("%zu\n", strlen(&p));// 随机值
//这是地址的地址,p的内容不确定,p变量在内存中后续的空间布局不确定
printf("%zu\n", strlen(&p + 1));// 随机值
//与上面的俩者间毫无联系
printf("%zu\n", strlen(&p[0] + 1));// 5
//传入的是b的地址
return 0;3、二维数组
代码一
#include <stdio.h>
int main()
{
int a[3][4] = { 0 };
printf("%zu\n", sizeof(a));
printf("%zu\n", sizeof(a[0][0]));
printf("%zu\n", sizeof(a[0]));
printf("%zu\n", sizeof(a[0] + 1));
printf("%zu\n", sizeof(*(a[0] + 1)));
printf("%zu\n", sizeof(a + 1));
printf("%zu\n", sizeof(*(a + 1)));
printf("%zu\n", sizeof(&a[0] + 1));
printf("%zu\n", sizeof(*(&a[0] + 1)));
printf("%zu\n", sizeof(*a));
printf("%zu\n", sizeof(a[3]));
return 0;
}解析
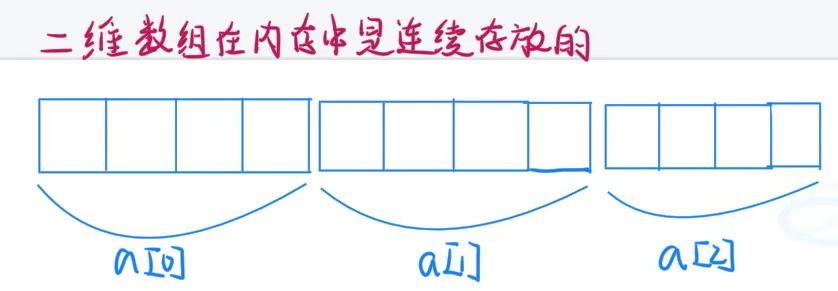
int a[3][4] = { 0 };
printf("%zu\n", sizeof(a));// 48
//a单独放在sizeof中表示整个数组的大小:4 * 3 * 4 == 48
printf("%zu\n", sizeof(a[0][0]));// 4
//表示第一行第一个元素的大小
printf("%zu\n", sizeof(a[0]));// 16
//a[0]是第一行这个一维数组的数组名,单独放在sizeof内部了,所以计算的是a[0]整个的大小
printf("%zu\n", sizeof(a[0] + 1));// 4/8(X64与X86环境不同)
//非特殊情况,所以a[0]表示首元素的地址即&a[0][0],a[0] + 1就表示第一行第二个元素的地址
printf("%zu\n", sizeof(*(a[0] + 1)));// 4
//a[0] + 1就表示第一行第二个元素的地址,再解引用就表示一个元素,所及计算的就是一个元素的大小
printf("%zu\n", sizeof(a + 1));// 4/8(X64与X86环境不同)
//非特殊情况,表示第一行的地址+1,就是第二行的地址
//a --> int(*)[4]
printf("%zu\n", sizeof(*(a + 1)));// 16
//*(a + 1) == a[1],就是第二行的数组名,符合了数组名单独放在sizeof内部中所以计算的就是整个数组的大小
printf("%zu\n", sizeof(&a[0] + 1));// 4/8(X64与X86环境不同)
//&a[0]是第一行的地址,取出的是第一行的地址,&a[0] + 1就是第二行的地址
printf("%zu\n", sizeof(*(&a[0] + 1)));// 16
//在上一个的基础上表示计算第二行数组的大小
printf("%zu\n", sizeof(*a));// 16
//数组名表示数组首元素的地址,*a就是第一行的大小
printf("%zu\n", sizeof(a[3]));// 16
// sizeof在计算变量,数组大小的时候,是通过类型来推导的,不会真实计算
//我们就假设如果这里存放的是第四行并且计算(因为实际上不会真实计算)
return 0;二、指针运算笔试题解析
题目一:
#include <stdio.h>
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1);
printf("%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
//程序的结果是什么?解析
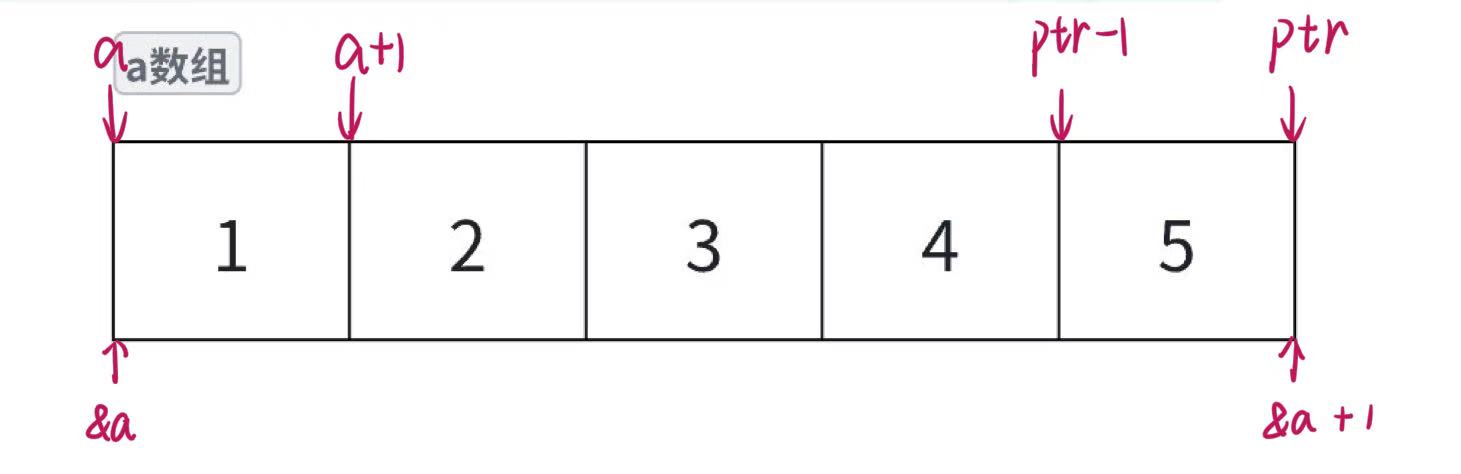
我们画出这个数组的内存布局再对其进一步分析,(int*)(&a + 1)表示的是将(&a + 1)强制类型转换为int*类型,其中&a表示的是取出整个数组的地址,可以用首元素的地址来表示,在此基础上再加1就表示跳过整个数组,如图所示,ptr就对应如此,ptr - 1就表示后退一个元素的地址,如图所示
题目二:
//在X86环境下 //假设结构体的⼤⼩是20个字节
//程序输出的结果是啥?
#include<stdio.h>
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p = (struct Test*)0x100000;
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}解析
这里考察的就是指针+-整数的应用
//程序的结果是什么?
//在X86环境下 //假设结构体的⼤⼩是20个字节
//程序输出的结果是啥?
#include<stdio.h>
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}*p = (struct Test*)0x100000;//将p强制类型转换成了一个结构体指针类型
int main()
//在X86环境下整型指针是四个字节
{
//指针+-整数
//结构体指针 + 1就表示跳过一个结构体,题中告诉我们假设结构体的大小是20个字节
//0x100000 + 20 == 0x100014(转换为16进制)
printf("%p\n", p + 0x1);
//p从结构体指针类型强制类型转换为无符号整型就是在他的基础上+1
//0x100000 + 1 == 0x100001
printf("%p\n", (unsigned long)p + 0x1);
//p从结构体指针类型强制类型转换为无符号整型指针,他+1就是跳过4个字节
//0x100000 + 4 == 0x100004
printf("%p\n", (unsigned int*)p + 0x1);
//注意%p打印的时候会省略0x
return 0;
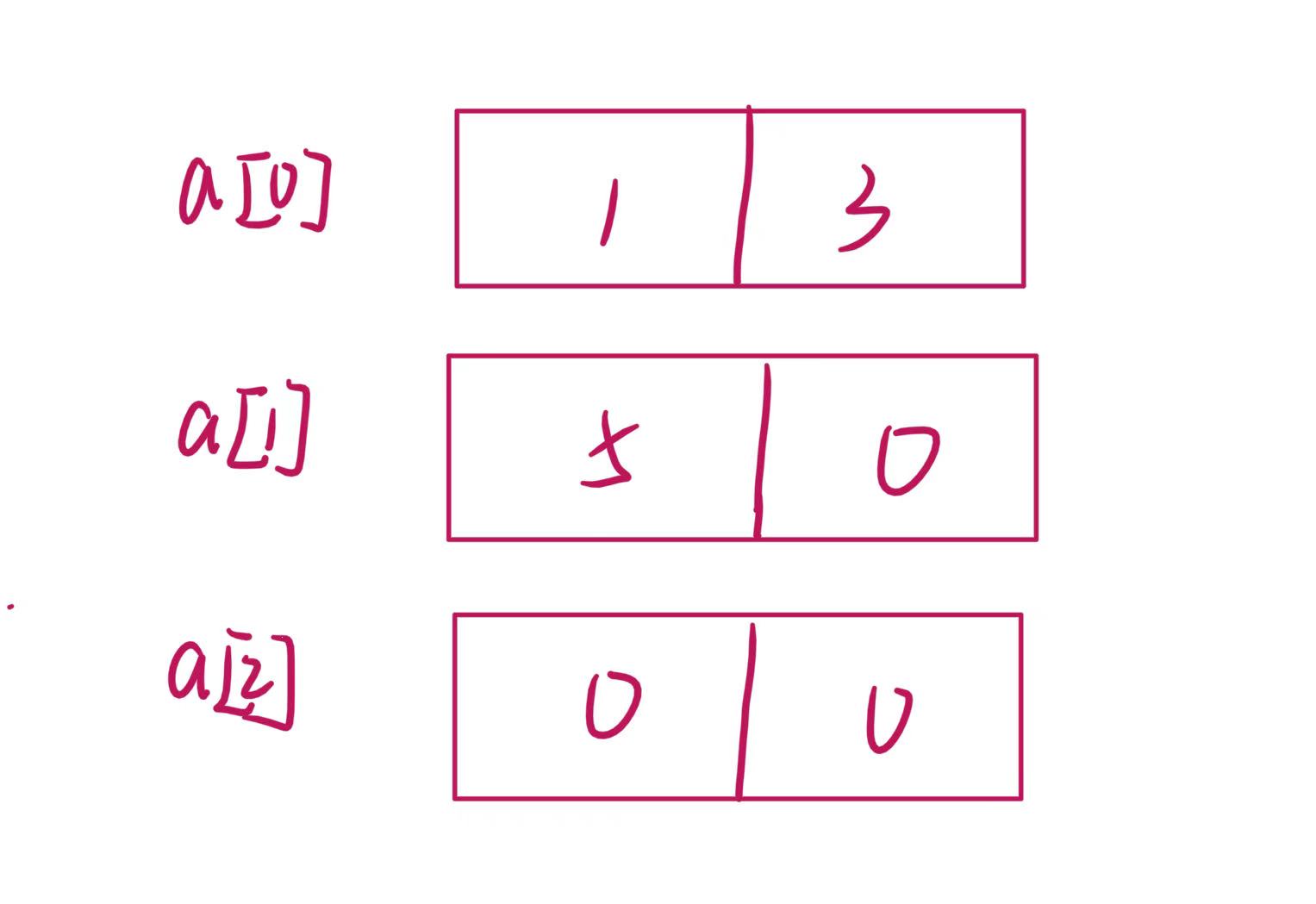
}题目三(易错):
#include <stdio.h>
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]);
return 0;
}解析
我们首先画出他的内存布局如下图所示
#include <stdio.h>
int main()
{
//这里是逗号表达式,即我们取后面的一个元素
//(0,1) == 1 (2,3) == 3 (4,5) == 5
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int* p;
//非特殊情况,即为首元素地址
p = a[0];//p=&a[0][0]
printf("%d", p[0]);//p[0] = *(p + 0)
return 0;
}题目四:
//假设环境是x86环境,程序输出的结果是啥?
#include <stdio.h>
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}解析
画出其内存布局如图所示
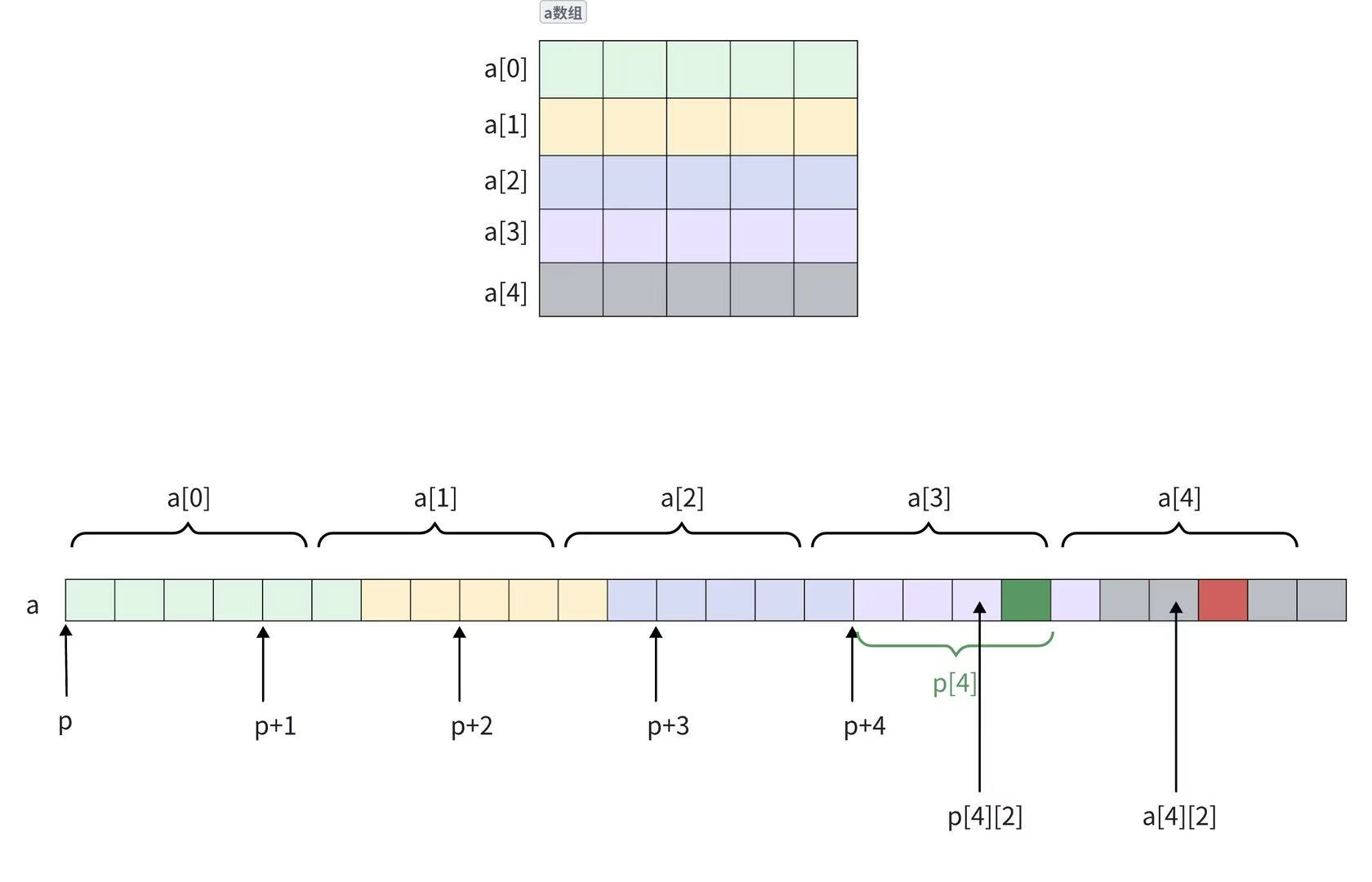
然后我们来看这题的代码我们应该可以发现这题是指针 - 指针,即打印俩个指针间的元素的个数
#include <stdio.h>
int main()
{
//p与a均为指针,一个指向4个元素,一个指向5个元素
int a[5][5];
int(*p)[4];
p = a;//p = &a[0] //a也是一个指针可以写成int(*a)[5]
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
//%d:按照十进制的形式,打印有符号的整数,%d认为内存中存放的是有符号整数的补码
//%p:打印地址(16进制),%p认为内存中存放的补码就是地址,打印时是原码
//原码:10000000 00000000 00000000 00000100
//取反,+1
//补码:11111111 11111111 11111111 11111100
//转换成十六进制
// FF FF FF FC
return 0;
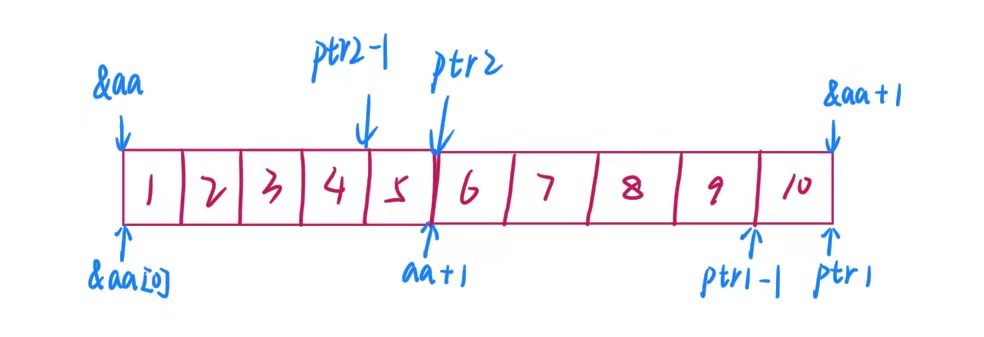
}题目五:
#include <stdio.h>
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}解析
他的内存布局如下图所示
#include <stdio.h>
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
//&aa是取出整个数组的地址,但是可以用首元素进行表示,&aa + 1就表示跳过整个数组
int* ptr1 = (int*)(&aa + 1);
//aa实际上就是&aa[0],是首元素的地址表示一个一维数组,第一行的地址+1就表示第二行的地址
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}题目六(阿里巴巴):
#include <stdio.h>
int main()
{
char *a[] = {"work","at","alibaba"};
char**pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}解析
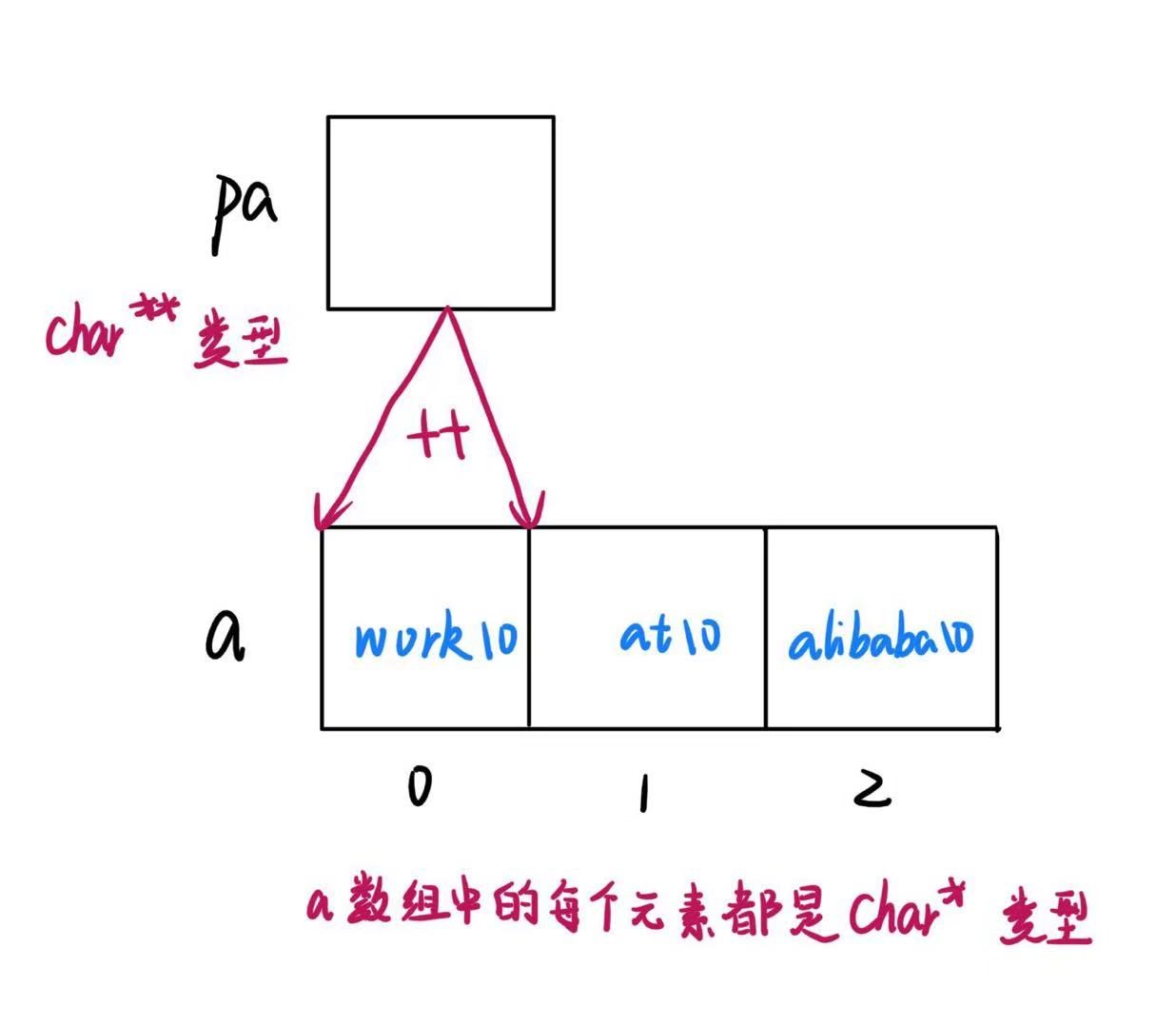
代码执行流程
- 定义字符串数组
a,包含三个字符串:"work"、"at"和"alibaba"。 - 定义二级指针
pa,并将其指向数组a的首地址。 - 将
pa向后移动一个位置,使其指向数组a的第二个元素。 - 使用
printf输出pa指向的字符串"at"。 - 程序正常结束,返回 0。
题目七(难点):
#include <stdio.h>
int main()
{
char *c[] = {"ENTER","NEW","POINT","FIRST"};
char**cp[] = {c+3,c+2,c+1,c};
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp+3);
printf("%s\n", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}解析
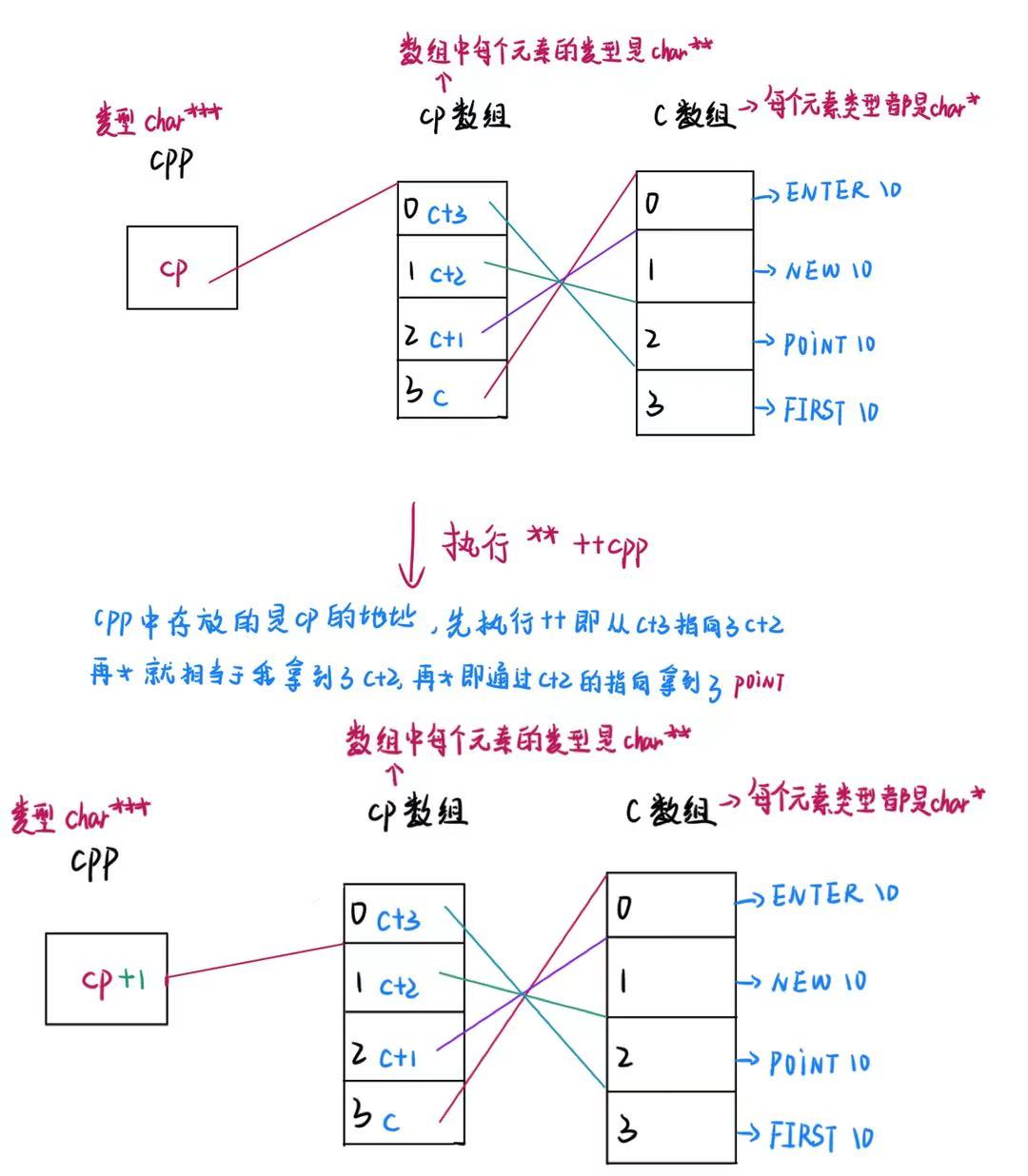
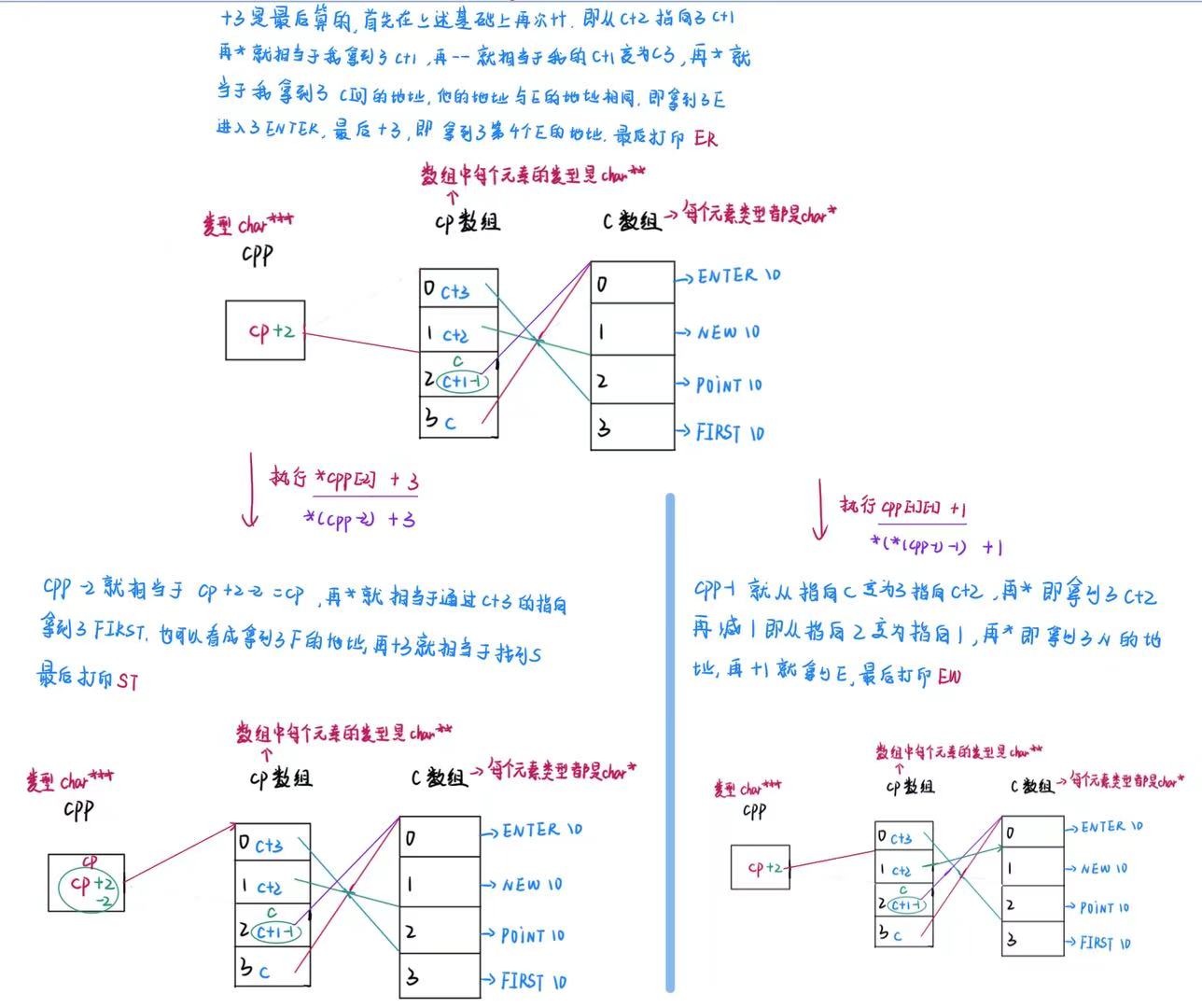
三、指针博客<上>例题解析
1、strlen函数的模拟实现
思路一:strlen函数是用来求一个字符串\0之前的字符长度的,我们要去求字符串的长度应该要去想到指针的一个特点就是:|指针-指针|(指针减去指针的绝对值) == 俩个指针之间的元素个数,当然了这也是有一个前提就是:俩个指针指向了同一空间,因此我们便可在此基础上完成用 指针 - 指针来实现strlen函数的模拟。
实践一
#include<stdio.h>
size_t my_strlen(char* p)//我们传过来的是一个指针,便要使用指针变量来接收
{
//*p是arr[0],p是&arr[0]
char* start = p;//相当于给p的地址存放在了start这个指针变量中
while (*p != '\0')
{
p++;
}
//这里p就是arr数组末尾的元素地址,start是首元素的地址
//俩者相减便是指针-指针,即为二者之间的元素个数
return p - start;
}
int main()
{
char arr[] = "hello world";
size_t ret = my_strlen(arr);
//数组名就是数组首元素的地址,所以这里我们实践传给函数的是&arr[0]
printf("%zu\n", ret);
return 0;
}思路二:除了上述的指针减去指针的方法之外我们也可以采用一步一步找到方法,即我去找字符串末尾的\0,向前进一个元素我就++直至找到\0停下,我也可以很轻松的模拟实现strlen函数(此方法更加便于理解,可以先掌握这个)
实践二
#include<stdio.h>
size_t my_strlen(char* p)
{
size_t count = 0;
while (*p != '\0')
{
count++;
p++;
}
return count;
}
int main()
{
char arr[] = "hello world";
size_t ret = my_strlen(arr);
printf("%zu\n", ret);
return 0;
}优化:我们采用assert断言以及规避野指针来实现这段函数的优化
#include<stdio.h>
#include<assert.h>
#define NDEBUG
size_t my_strlen(const char* p)
{
size_t count = 0;
assert(p != NULL);
while (*p != '\0')
{
count++;
p++;
}
return count;
}
int main()
{
char arr[] = "hello world";
int sz = sizeof(arr) / sizeof(arr[0]);
size_t ret = my_strlen(arr);
printf("%zu", ret);
return 0;
}2、字符串逆序
内容:写一个函数,可以逆序一个字符串的内容。字符逆序__牛客网
实践
#include<stdio.h>
#include<string.h>
void Reverse(char* str)//接受的是&arr[0]
{
int len = strlen(str);
char* left = str;//&str[0]
char* right = str + len - 1;
while (left < right)
{
char tap = *left;
*left = *right;
*right = tap;
left++;
right--;
}
}
int main()
{
char arr[10000] = { 0 };
//这里不能用scanf输入因为scanf遇到空格结束
//所以字符串的输入我们用 gets
while (gets(arr))
{
Reverse(arr);//其实传过去的就是&arr[0]
printf("%s\n", arr);
}
return 0;
}3、 字符串左旋
内容:实现一个函数,可以左旋字符串中的k个字符。
例如:
ABCD左旋一个字符得到BCDA
ABCD左旋两个字符得到CDAB
实践
void leftfound(char* str, int k)
{
int len = strlen(str);
int time = k % len;//实际左旋次数
int i = 0;//次数
int j = 0;//下标
for (i = 0; i < time; i++)
{
char tap = str[0];
for (j = 0; j < len - 1; j++)
{
str[j] = str[j + 1];
}
str[j] = tap;//最后一次给前面的值赋到最后
}
}
int main()
{
char arr[] = "hello world";
int a = 0;
scanf_s("%d", &a);
leftfound(arr, a);//这里的a表示我们想左旋几个字符串
printf("%s\n", arr);
return 0;
}优化:strcpy与strncat函数的使用
我们先来简单学习一下strcpy与strncat函数
#include<stdio.h>
#include<string.h>
int main()
{
char str = "abcdef";
char copy[256] = { 0 };
strcpy(copy, str);//字符串拷贝,将str中的字符串拷贝到copy中
printf("%s\n", copy);
//字符串拼接
char str2[] = "abc";
char cat[256] = "pok";
strcat(cat, str2);//字符串拼接,将str2拼接到cat的后面
strncat(cat, str2, 2);//从str2指向的位置开始 拼接2个字符到cat的最后
printf("%s\n", cat);
return 0;
}于是我们便可以写出如下的代码:
#include<stdio.h>
#include<string.h>
void leftfound(char* str, int k)
{
char tap[256] = { 0 };
int len = strlen(str);
int time = k % len;//实际左旋次数
strcpy(tap, str + time);
strncat(tap, str, time);
strcpy(str, tap);
}
int main()
{
char arr[] = "hello world";
int a = 0;
scanf_s("%d", &a);
leftfound(arr, a);//这里的a表示我们想左旋几个字符串
printf("%s\n", arr);
return 0;
}4、调整奇数偶数顺序
内容:调整数组使奇数全部都位于偶数前面。
输入一个整数数组,实现一个函数,
来调整该数组中数字的顺序使得数组中所有的奇数位于数组的前半部分,
所有偶数位于数组的后半部分。
实践
#include <stdio.h>
// 函数用于调整数组,使奇数位于偶数前面
void func(int arr[], int n)
{
// 左指针,从数组起始位置开始
int left = 0;
// 右指针,从数组末尾位置开始
int right = n - 1;
while (left < right) {
// 找到左边的偶数
while (left < right && arr[left] % 2 != 0) {
left++;
}
// 找到右边的奇数
while (left < right && arr[right] % 2 == 0) {
right--;
}
// 交换左右指针指向的元素
if (left < right) {
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
}
}
int main() {
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
int n = sizeof(arr) / sizeof(arr[0]);
printf("原数组:");
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
// 调用函数调整数组
func(arr, n);
printf("调整后的数组:");
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}5、字符串旋转结果
内容:写一个函数,判断一个字符串是否为另外一个字符串旋转之后的字符串。
写一个函数,判断一个字符串是否为另外一个字符串旋转之后的字符串。
例如:给定s1 =AABCD和s2 = BCDAA,返回1
给定s1=abcd和s2=ACBD,返回0.
AABCD左旋一个字符得到ABCDA
AABCD左旋两个字符得到BCDAA
AABCD右旋一个字符得到DAABC
实践:
在实践之前我为大家介绍一个新的函数srcsrc
//介绍一个新的库方法 strstr
#include<stdio.h>
#include<string.h>
int main()
{
char* str1 = "AABCD";
char* str2 = "AB";
char* ret = strstr(str1, str2);
//会找到AB(即相同部分)之后的地址
printf("%s\n", ret);//这里输出的是ABCD
//如果没有相同部分就会返回NULL
return 0;
}根据上述函数我们便可以很轻松实现我们想要的内容(srcsrc函数后续也会展开讲解,现在先了解)
#include<stdio.h>
#include<string.h>
//src:AABCD find:BCDAA
char* func(char* src, char* find)
{
//我们创建一块新的区域叫tap,然后将src拷贝到这块区域内
//接着再将src拼接到上一个拷贝的src后面
//我们就可以在tap里面去找find,是一定可以找到的
char tap[256] = { 0 };
strcpy(tap, sizeof(tap), src);
strcat(tap, sizeof(tap), src);
return strstr(tap, find);
}
int main()
{
char* str1 = "AABCD";
char* str2 = "BCDAA";
char* ret = func(str1, str2);
if (ret != NULL)
{
printf("1\n");
printf("%s\n", ret);
}
else
{
printf("0\n");
}
return 0;
}6、猜凶手
内容:
日本某地发生了一件谋杀案,警察通过排查确定杀人凶手必为4个嫌疑犯的一个。
以下为4个嫌疑犯的供词:
A说:不是我。
B说:是C。
C说:是D。
D说:C在胡说
已知3个人说了真话,1个人说的是假话。
现在请根据这些信息,写一个程序来确定到底谁是凶手。
实践
#include<stdio.h>
void find()
{
char killer = 'a';
for (; killer <= 'd'; killer++)
{
if ((killer != 'a') + (killer == 'c') + (killer == 'd') + (killer != 'd') == 3)
{
printf("凶手是%c\n", killer);
return;
}
}
}
int main()
{
find();
return 0;
}7、杨辉三角
内容:在屏幕上打印杨辉三角。
1
1 1
1 2 1
1 3 3 1
…….......
实践
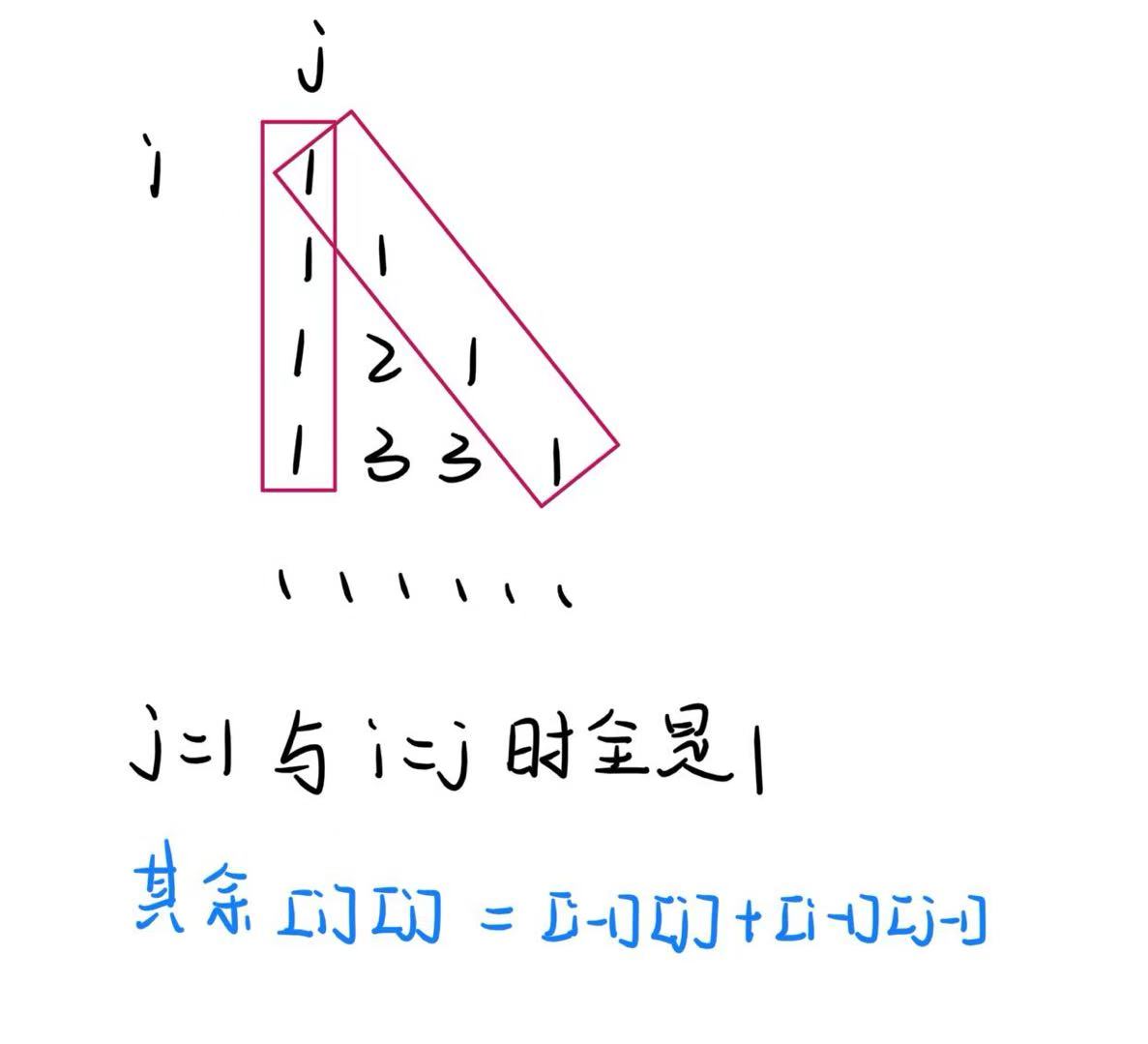
#include<stdio.h>
void func(int arr[4][4],int n)
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j <= i; j++)
{
if (j == 0 || i == j)
arr[i][j] = 1;
else
arr[i][j] = arr[i - 1][j] + arr[i - 1][j - 1];
}
printf("\n");
}
}
int main()
{
int arr[4][4] = { 0 };
func(arr, 4);
for (int i = 0; i < 4; i++)
{
for (int j = 0; j <= i; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
}8、杨氏矩阵
内容:有一个数字矩阵,矩阵的每行从左到右是递增的,矩阵从上到下是递增的,请编写程序在这样的矩阵中查找某个数字是否存在。
要求:时间复杂度小于O(N);
实践
首先给出图解帮助到大家理解:
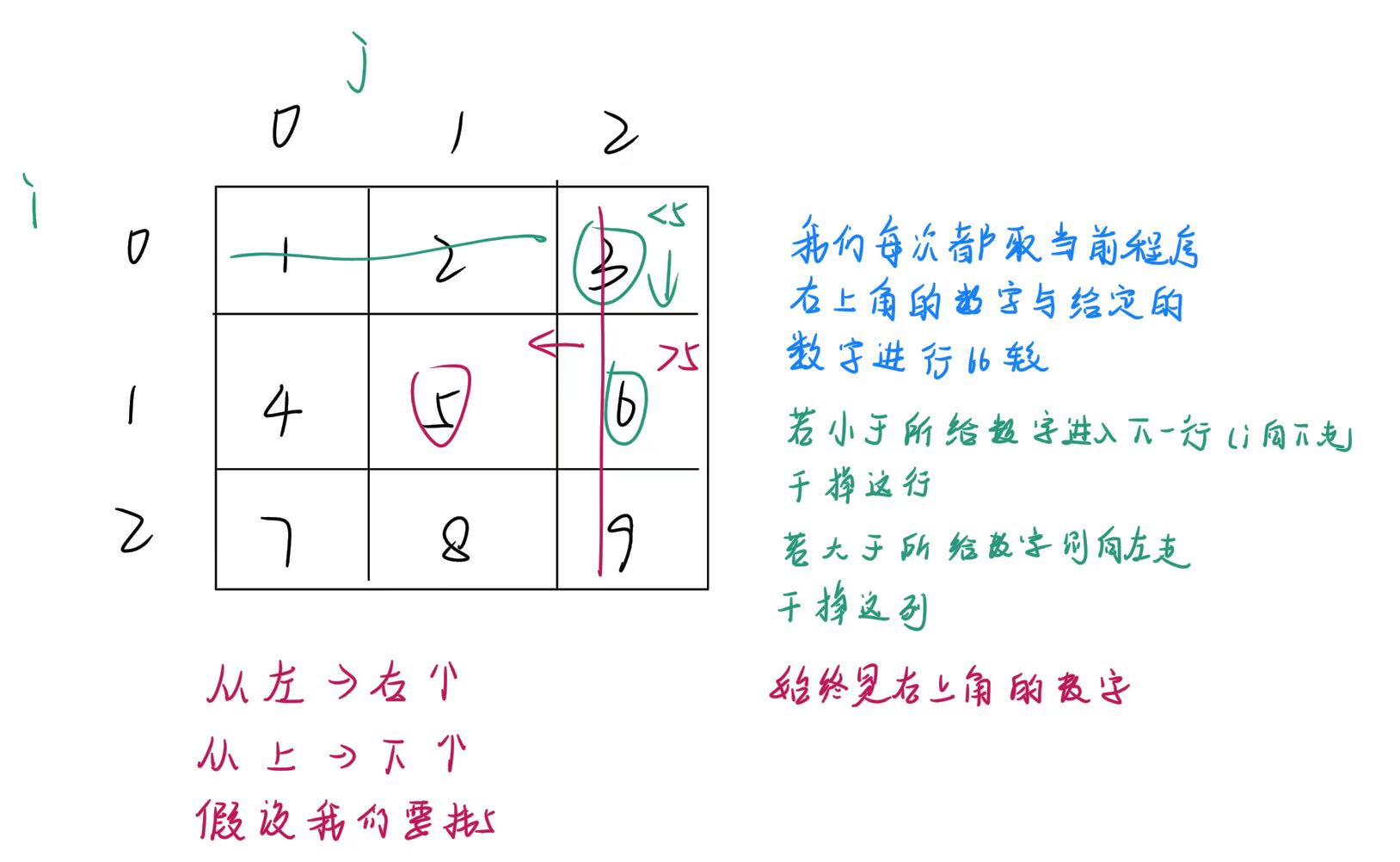
#include<stdio.h>
int func(int arr[3][3], int x, int y, int key)
{
int i = 0;;
int j = y - 1;
while (i < x && j >= 0)
{
if (arr[i][j] < key)
i++;
else if (arr[i][j] > key)
j--;
else
return 1;
}
return 0;
}
int main()
{
int arr[3][3] = { {1,2,3},{4,5,6},{7,8,9} };
int ret = func(arr, 3, 3, 5);//5是我们要找的数字
if (ret == 1)
printf("找到了\n");
else
printf("没找到\n");
return 0;
}四、指针博客<中>例题解析
1、冒泡排序
介绍:这是一种非常典型的排序算法,它的本质核心思想就是通过俩俩相邻的元素进行比较。
思路:假设我们现在要去排序一个数组中的n个元素,将他改为升序,我们本质上就是将i与i+1个元素进行比较然后一步步将他们所有的都比较一编,便可以实现这组数组的升序。
实践
#include<stdio.h>
void bubble_sort(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int tap = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tap;
}
}
}
}
int main()
{
int arr[10] = { 2,34,5,6,6,87,8,0,1,3 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}优化:这段代码还是存在一些缺陷的,比如假设给出的数组本身就是一个有着高度排序性的升序数组,那么原本我们只要执行一至两次便可以实现排序,但是按照上述的代码我们会一步步按部就班的执行完,这样的代码就会存在效率低下的问题,于是我们便给出下面的优化:
#include<stdio.h>
void bubble_sort(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int flag = 1;//假设这一趟已经有序了
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
flag = 0;//发生交换就说明,无序
int tap = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tap;
}
}
if (flag == 1)
break;//这一趟没交换就说明已经有序,无序后续排序了
}
}
int main()
{
int arr[10] = { 2,34,5,6,6,87,8,0,1,3 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}虽说在原有基础上改动不大,却大大提高了代码的工作效率。
2、经典笔试题
备注:此题目是《剑指offer》中收录的一道和字符串相关的笔试题
#include <stdio.h>
int main()
{
char str1[] = "hello bit.";
char str2[] = "hello bit.";
const char *str3 = "hello bit.";
const char *str4 = "hello bit.";
if(str1 ==str2)
printf("str1 and str2 are same\n");
else
printf("str1 and str2 are not same\n");
if(str3 ==str4)
printf("str3 and str4 are same\n");
else
printf("str3 and str4 are not same\n");
return 0;
}解析

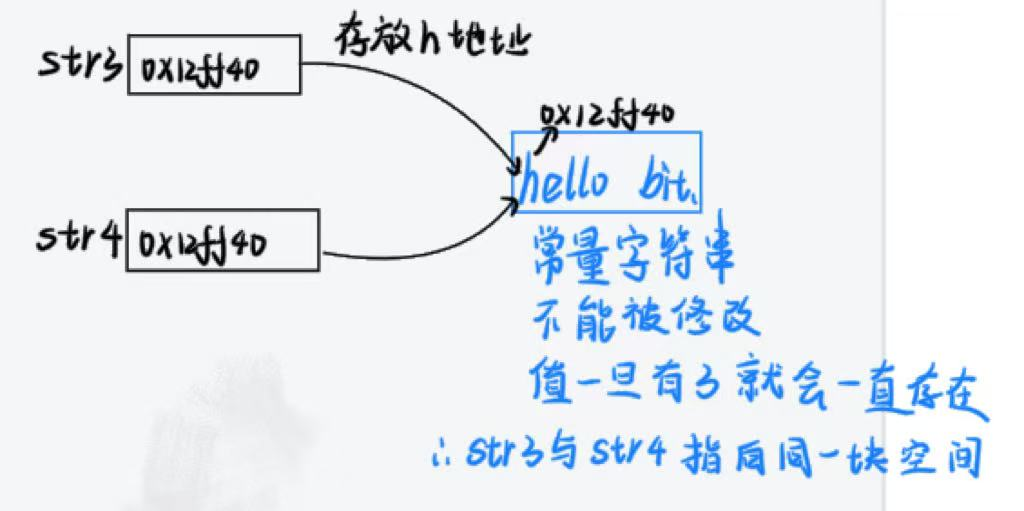
这里str3和str4指向的是一个同一个常量字符串。C/C++会把常量字符串存储到单独的一个内存区域,当几个指针指向同一个字符串的时候,他们实际会指向同一块内存。但是用相同的常量字符串去初始化不同的数组的时候就会开辟出不同的内存块。所以str1和str2不同,str3和str4相同。
3、找单身狗
内容:一个数组中只有两个数字是出现一次,其他所有数字都出现了两次。编写一个函数找出这两个只出现一次的数字。
例如:
有数组的元素是:1,2,3,4,5,1,2,3,4,6
只有5和6只出现1次,要找出5和6.
思路一:我们采用之前学习操作符时学的 ^ 操作符来实现(只适合找一个数据时使用)
实践
#include<stdio.h>
int main()
{
int ret = 0;
int arr[] = { 1,2,3,4,5,4,3,2,1 };
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz; i++)
{
ret = ret ^ arr[i];
//0 ^ a = a
//a ^ a = 0
}
printf("%d", ret);
return 0;
}思路二:我们采取异或分组的方法
实践
#include<stdio.h>
void find(int arr[], int* p1, int* p2, int sz)
{
//1、整体异或得到5 ^ 6的结果存到tap中
int tap = 0;
for (int i = 0; i < sz; i++)
{
tap = tap ^ arr[i];
}
//2、算出tap中哪一位是1 pos位置记录下来
int pos;
for (int i = 0; i < 32; i++)
{
if ((tap >> i) & 1 == 1)
{
pos = i;
break;
}
}
//3、再次遍历数组的每个数字,看pos位置的是不是0或者1分到2个组
for (int i = 0; i < sz; i++)
{
if ((arr[i] >> pos) & 1 == 1)
{
*p1 = *p1 ^ arr[i];
}
else
{
*p2 = *p2 ^ arr[i];
}
}
}
int main()
{
int a = 0;
int b = 0;
int arr[] = { 1,2,3,4,5,1,2,3,4,6 };
int sz = sizeof(arr) / sizeof(arr[10]);
find(arr, &a, &b, sz);
printf("%d %d", a, b);
return 0;
}4、KiKi想获得某年某月有多少天,请帮他编程实现
内容:获得月份天数_牛客题霸_牛客网
实践:
#include<stdio.h>
int main()
{
int y, m;
int days[12] = { 31,28,31,20,31,30,31,31,30,31,30,31 };
while (scanf("%d %d", &y, &m) != EOF)
{
int day = days[m - 1];
if ((y % 4 == 0 && y % 100 != 0) || y % 400 == 0)
{
if (m == 2)
day += 1;
}
printf("%d\n", day);
}
return 0;
}五、指针博客<下>例题解析
1、qsort函数的模拟实现
思路:这里看似排序的数据是任意类型的,但是本质上还是冒泡排序的算法思想
实践一:整型数据
#include<stdio.h>
int cmp_int(const void* p1, const void* p2)
{
return (*(int*)p1 - *(int*)p2);
}
void Swap(char* buf1, char* buf2, size_t width)
{
int i = 0;
char tap = 0;
for (i = 0; i < width; i++)
{
//传址调用
tap = *buf1;
*buf1 = *buf2;
*buf2 = tap;
buf1++;
buf2++;
}
}
void print_arr(int arr[10], int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void bubble_sort(void* base, size_t sz, size_t width, int(*cmp)(const void* p1, const void* p2))
{
for (int i = 0; i < sz - 1; i++)
{
for (int j = 0; j < sz - 1 - i; j++)
{
//if(arr[j] > arr[j + 1]) // 交换
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0)
{
//交换
Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
}
}
}
}
void test1()
{
int arr[10] = { 12,3,4,5,6,7,9,0,10,29 };
int sz = sizeof(arr) / sizeof(arr[10]);
print_arr(arr, sz);
bubble_sort(arr, sz, sizeof(arr[0]), cmp_int);
print_arr(arr, sz);
}
int main()
{
test1();
return 0;
}实践二:结构类型数据
#include<stdio.h>
#include<string.h>
struct Stu
{
char name[20];
int age;
};
void Swap(char* buf1, char* buf2, size_t width)
{
int i = 0;
char tap = 0;
for (i = 0; i < width; i++)
{
//传址调用
tap = *buf1;
*buf1 = *buf2;
*buf2 = tap;
buf1++;
buf2++;
}
}
void print_arr(int arr[10], int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void bubble_sort(void* base, size_t sz, size_t width, int(*cmp)(const void* p1, const void* p2))
{
for (int i = 0; i < sz - 1; i++)
{
for (int j = 0; j < sz - 1 - i; j++)
{
//if(arr[j] > arr[j + 1]) // 交换
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0)
{
//交换
Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
}
}
}
}
int cmp_stu_by_age(const void* p1, const void* p2)
{
/*return ((*(struct Stu*)p1).age - (*(struct Stu*)p2).age);*/
return (((struct Stu*)p1)->age - ((struct Stu*)p2)->age);
}
void print_Stu_age(struct Stu arr[], int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%s:%d\n", arr[i].name, arr[i].age);
}
printf("\n");
}
void test1()
{
struct Stu arr[] = { {"xiaozhulaoshi",17},{"xiaofuxing",18},{"xiaohuangdi",19} };
int sz = sizeof(arr) / sizeof(arr[10]);
bubble_sort(arr, sz, sizeof(arr[10]), cmp_stu_by_age);
print_Stu_age(arr, sz);
}
int cmp_stu_by_name(const void* p1, const void* p2)
{
return strcmp(((struct Stu*)p1)->name, ((struct Stu*)p2)->name);
}
void print_Stu_name(struct Stu arr[], int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%s:%d\n", arr[i].name, arr[i].age);
}
printf("\n");
}
void test2()
{
struct Stu arr[] = { {"xiaozhulaoshi",17},{"xiaofuxing",18},{"xiaohuangdi",19} };
int sz = sizeof(arr) / sizeof(arr[10]);
bubble_sort(arr, sz, sizeof(arr[10]), cmp_stu_by_name);
print_Stu_name(arr, sz);
}
int main()
{
test1();
test2();
return 0;
}六、总结及下期预告
本文详细解析了C语言中指针与数组的常见面试题,涵盖了一维数组、二维数组、字符数组的sizeof和strlen操作,以及指针运算、字符串处理、排序算法等核心知识点。通过20余个典型例题的代码实现和图解分析,深入讲解了指针在不同场景下的应用,包括数组名在不同上下文中的含义、指针加减运算、冒泡排序优化、qsort函数模拟实现等内容。文章还提供了字符串逆序、左旋、查找等实用案例,并针对阿里巴巴等大厂面试题进行解析。最后介绍了如何利用指针高效解决"找单身狗"等算法问题,为读者系统梳理了指针相关的重点难点,是备战C语言面试的实用指南。下期将重点讲解结构体、联合体等复杂数据类型的使用技巧。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-08-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号