《算法导论》第 5 章-概率分析和随机算法

《算法导论》第 5 章-概率分析和随机算法

啊阿狸不会拉杆
发布于 2026-01-21 13:00:32
发布于 2026-01-21 13:00:32
大家好!今天我们来一起学习《算法导论》第 5 章 —— 概率分析和随机算法。在计算机科学中,很多算法的性能会受到输入数据的影响,而概率分析能帮助我们评估算法在平均情况下的表现。随机算法则是通过主动引入随机性,来获得更好的期望性能或避免最坏情况。本章我们将通过具体的例子和代码实现,深入理解这些概念。

思维导图

5.1 雇用问题
问题描述
假设你需要雇用一名办公室助理,有 n 个应聘者依次前来面试。每次面试后,如果你觉得当前应聘者比现在的助理更优秀,你就会解雇当前助理,聘用新的应聘者。面试本身是有成本的,但更昂贵的是解雇和雇用的成本。我们的目标是分析在这个过程中,雇用的期望次数是多少。
流程分析
flowchart TD
start[开始] --> init[初始化: 最佳应聘者 = 最差, 雇用次数 = 0]
init --> loop{是否有下一个应聘者?}
loop -- 是 --> interview[面试应聘者]
interview --> compare{比当前最佳优秀?}
compare -- 是 --> hire[雇用新应聘者, 解雇旧的]
hire --> increment[雇用次数 += 1, 更新最佳]
increment --> loop
compare -- 否 --> loop
loop -- 否 --> end[结束, 输出雇用次数]概率分析
假设应聘者是以随机顺序出现的(即所有可能的 n! 种排列出现的概率相等),我们来分析期望雇用次数。
对于第 i 个应聘者(从 1 到 n 编号),令 X_i 为一个随机变量:如果第 i 个应聘者被雇用,则 X_i=1,否则 X_i=0。那么总的雇用次数 X = X_1 + X_2 + ... + X_n。
根据期望的线性性质,E [X] = E [X_1] + E [X_2] + ... + E [X_n]。
现在考虑 E [X_i],即第 i 个应聘者被雇用的概率。第 i 个应聘者被雇用,当且仅当他是前 i 个应聘者中最优秀的。由于应聘者是随机排列的,前 i 个应聘者中的每一个都等可能地是最优秀的,所以 E [X_i] = 1/i。
因此,E [X] = 1 + 1/2 + 1/3 + ... + 1/n = H_n,其中 H_n 是第 n 个调和数。调和数 H_n 约等于 ln n + γ,其中 γ 是欧拉 - 马歇罗尼常数(约为 0.5772)。所以,期望雇用次数是 O (log n)。
代码实现
下面是模拟雇用问题的 C++ 代码:
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
using namespace std;
// 模拟雇用过程
// 参数: 应聘者的能力值数组
// 返回值: 雇用次数
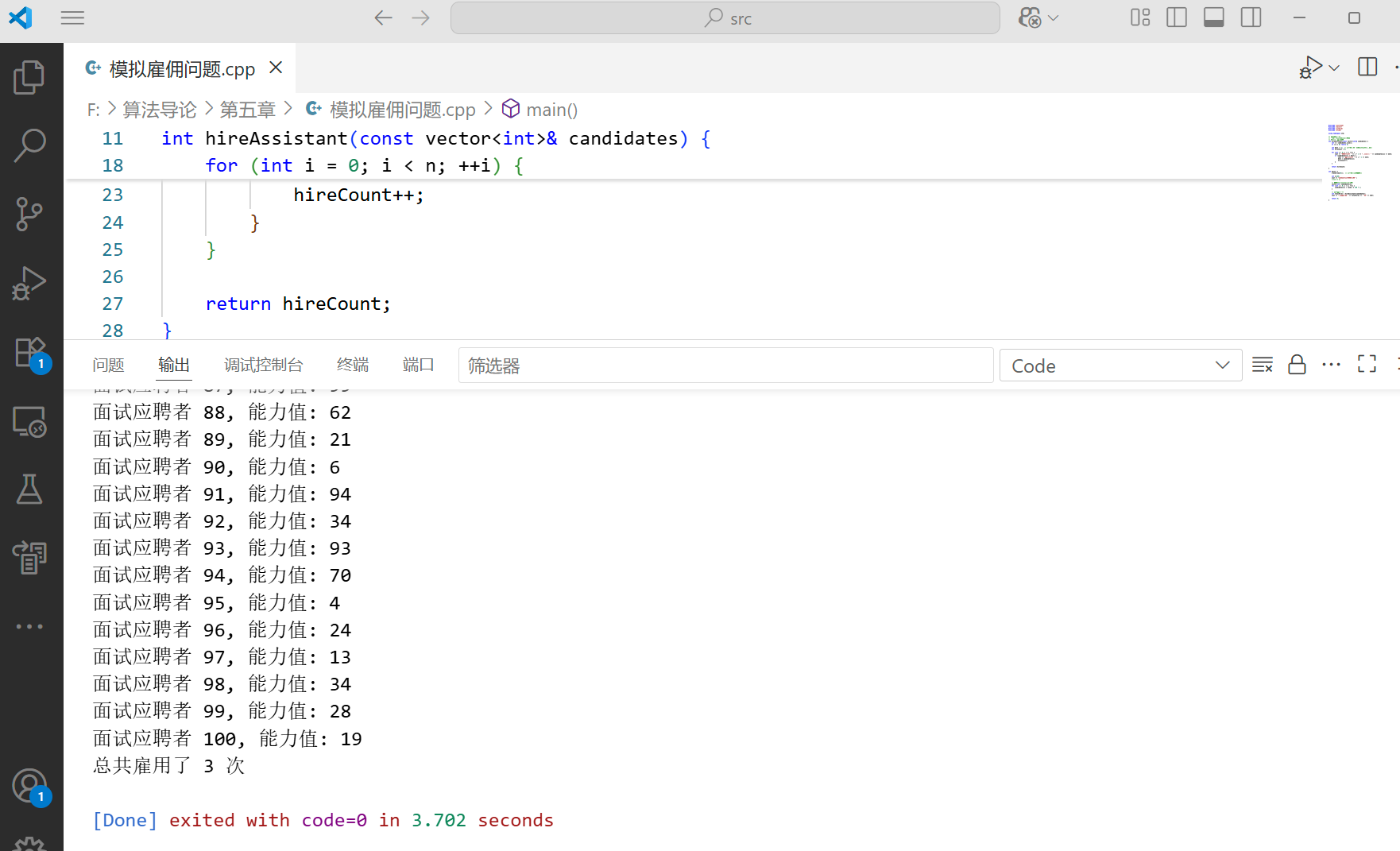
int hireAssistant(const vector<int>& candidates) {
int n = candidates.size();
if (n == 0) return 0;
int best = -1; // 初始化为比所有可能应聘者都差的值
int hireCount = 0;
for (int i = 0; i < n; ++i) {
cout << "面试应聘者 " << i + 1 << ", 能力值: " << candidates[i] << endl;
if (candidates[i] > best) {
cout << "雇用应聘者 " << i + 1 << endl;
best = candidates[i];
hireCount++;
}
}
return hireCount;
}
int main() {
srand(time(0)); // 初始化随机数生成器
int n;
cout << "请输入应聘者数量: ";
cin >> n;
// 生成n个随机能力值(1-100)
vector<int> candidates(n);
for (int i = 0; i < n; ++i) {
candidates[i] = rand() % 100 + 1;
}
// 模拟雇用过程
int totalHires = hireAssistant(candidates);
cout << "总共雇用了 " << totalHires << " 次" << endl;
return 0;
}
代码说明:
hireAssistant函数模拟了雇用过程,接收一个表示应聘者能力值的向量- 我们维护一个
best变量记录当前最佳应聘者的能力值 - 对于每个应聘者,如果其能力值超过
best,就雇用他,并更新best和雇用次数 main函数生成随机的应聘者能力值,并调用hireAssistant进行模拟
你可以多次运行这段代码,观察不同输入情况下的雇用次数,会发现平均雇用次数确实符合我们的理论分析。
5.2 指示器随机变量

定义与性质
指示器随机变量是一种非常有用的工具,它可以简化概率和期望的计算。
定义:对于一个事件 A,指示器随机变量 I {A} 定义为:
- I {A} = 1 如果事件 A 发生
- I {A} = 0 如果事件 A 不发生
性质:指示器随机变量的期望等于事件发生的概率,即 E [I {A}] = P (A)。
这个性质非常重要,因为它将计算期望的问题转化为计算概率的问题,而后者有时更容易处理。
应用示例:抛硬币
考虑抛一枚公平硬币的实验,定义指示器随机变量 X=I {硬币正面朝上}。则 E [X] = P (正面朝上) = 1/2。
如果我们抛 n 次硬币,令 X_i 为第 i 次抛硬币正面朝上的指示器,则总的正面朝上次数 X = X_1 + X_2 + ... + X_n。根据期望的线性性质:
E[X] = E[X_1 + X_2 + ... + X_n] = E[X_1] + E[X_2] + ... + E[X_n] = n * 1/2 = n/2
这与我们的直觉相符。
应用于雇用问题
在 5.1 节中,我们已经使用了指示器随机变量来分析雇用问题。让我们再明确一下:
- 令 X 为总的雇用次数
- 定义 X_i = I {第 i 个应聘者被雇用}
- 则 X = X_1 + X_2 + ... + X_n
- E[X] = E[X_1] + E[X_2] + ... + E[X_n]
- 对于每个 X_i,E [X_i] = P (第 i 个应聘者被雇用) = 1/i
- 因此 E [X] = H_n ≈ ln n + γ
代码示例:使用指示器变量计算期望
下面的代码通过多次模拟雇用过程,计算平均雇用次数,并与理论值 H_n 进行比较:
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <cmath>
#include <algorithm>
using namespace std;
// 计算调和数H_n的近似值
double harmonicNumber(int n) {
const double gamma = 0.57721566490153286060651209008240243104215933593992;
return log(n) + gamma + 1.0 / (2 * n) - 1.0 / (12 * n * n);
}
// 模拟一次雇用过程,返回雇用次数
int simulateHire(const vector<int>& candidates) {
int best = -1;
int hireCount = 0;
for (int c : candidates) {
if (c > best) {
best = c;
hireCount++;
}
}
return hireCount;
}
int main() {
srand(time(0));
int n, trials;
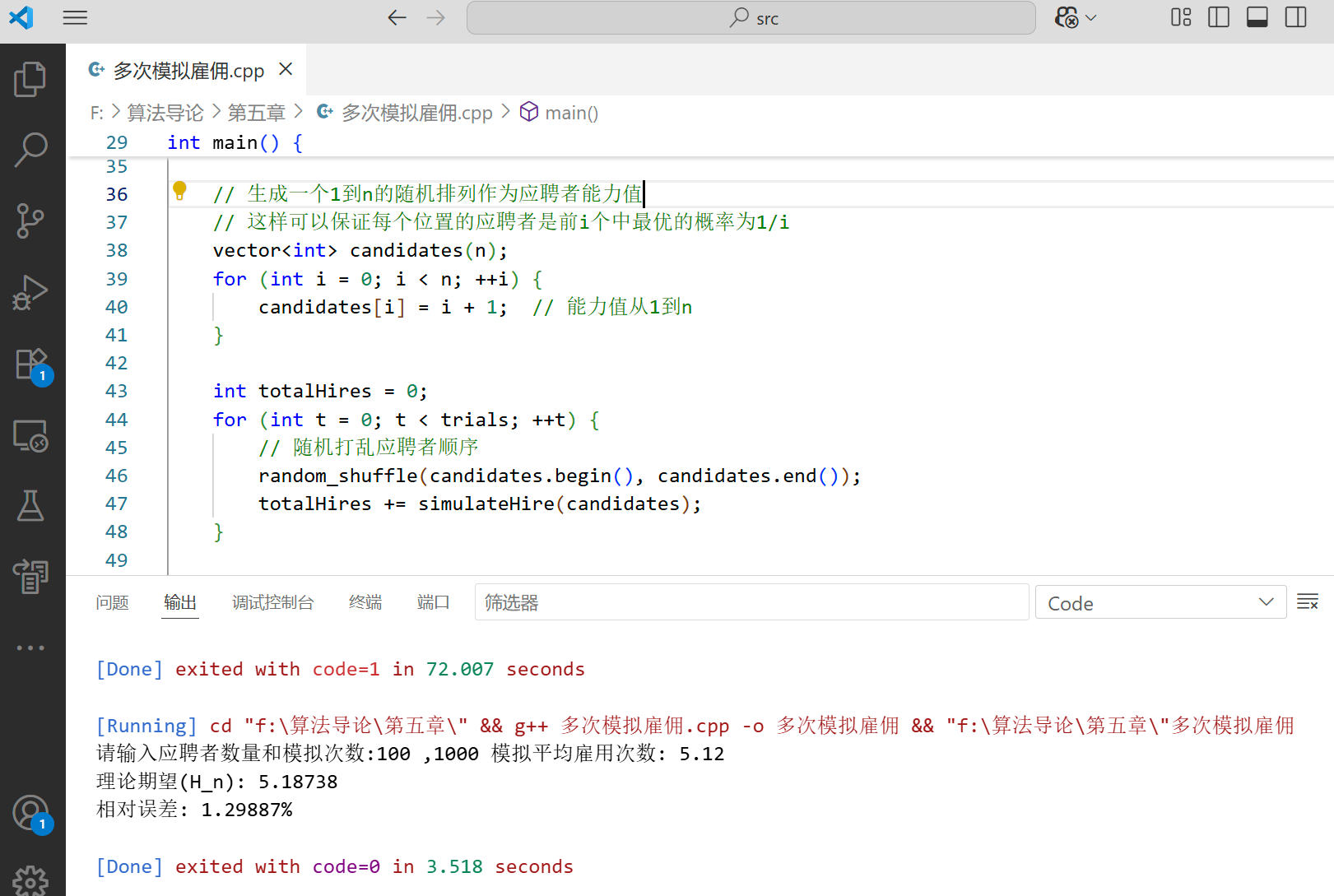
cout << "请输入应聘者数量和模拟次数: ";
cin >> n >> trials;
// 生成一个1到n的随机排列作为应聘者能力值
// 这样可以保证每个位置的应聘者是前i个中最优的概率为1/i
vector<int> candidates(n);
for (int i = 0; i < n; ++i) {
candidates[i] = i + 1; // 能力值从1到n
}
int totalHires = 0;
for (int t = 0; t < trials; ++t) {
// 随机打乱应聘者顺序
random_shuffle(candidates.begin(), candidates.end());
totalHires += simulateHire(candidates);
}
double avgHires = static_cast<double>(totalHires) / trials;
double theoreticalValue = harmonicNumber(n); // 修正:使用英文变量名
cout << "模拟平均雇用次数: " << avgHires << endl;
cout << "理论期望(H_n): " << theoreticalValue << endl; // 修正:使用英文变量名
cout << "相对误差: " << abs(avgHires - theoreticalValue) / theoreticalValue * 100 << "%" << endl; // 修正:使用英文变量名
return 0;
}
代码说明:
- 我们使用 1 到 n 的随机排列作为应聘者的能力值,这样可以保证每个应聘者是前 i 个中最优的概率为 1/i
- 通过多次模拟,计算平均雇用次数
- 将模拟结果与调和数 H_n 的理论值进行比较
- 可以看到,随着模拟次数的增加,模拟结果会越来越接近理论值
5.3 随机算法
与概率分析的区别
在概率分析中,我们假设输入符合某种分布,然后分析算法在这种分布下的平均性能。而随机算法则是在算法中引入随机性(如随机排列输入),使得算法的性能不依赖于输入的分布。
随机算法的优势在于:
- 不需要假设输入的分布
- 可以避免最坏情况的输入
- 通常更容易分析
随机化雇用算法
在雇用问题中,如果我们不能保证应聘者是随机到达的,我们可以主动随机化应聘者的顺序。这样,无论原始输入如何,我们都能保证期望雇用次数为 O (log n)。
随机化雇用算法的流程图:
flowchart TD
start[开始] --> input[输入应聘者列表]
input --> shuffle[随机打乱应聘者顺序]
shuffle --> init[初始化: 最佳应聘者 = 最差, 雇用次数 = 0]
init --> loop{是否有下一个应聘者?}
loop -- 是 --> interview[面试应聘者]
interview --> compare{比当前最佳优秀?}
compare -- 是 --> hire[雇用新应聘者, 解雇旧的]
hire --> increment[雇用次数 += 1, 更新最佳]
increment --> loop
compare -- 否 --> loop
loop -- 否 --> end[结束, 输出雇用次数]代码实现
下面是随机化雇用算法的实现:
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <algorithm>
using namespace std;
// 随机化雇用算法
int randomizedHireAssistant(vector<int> candidates) { // 注意这里是传值,会复制一份
int n = candidates.size();
if (n == 0) return 0;
// 随机打乱应聘者顺序
random_shuffle(candidates.begin(), candidates.end());
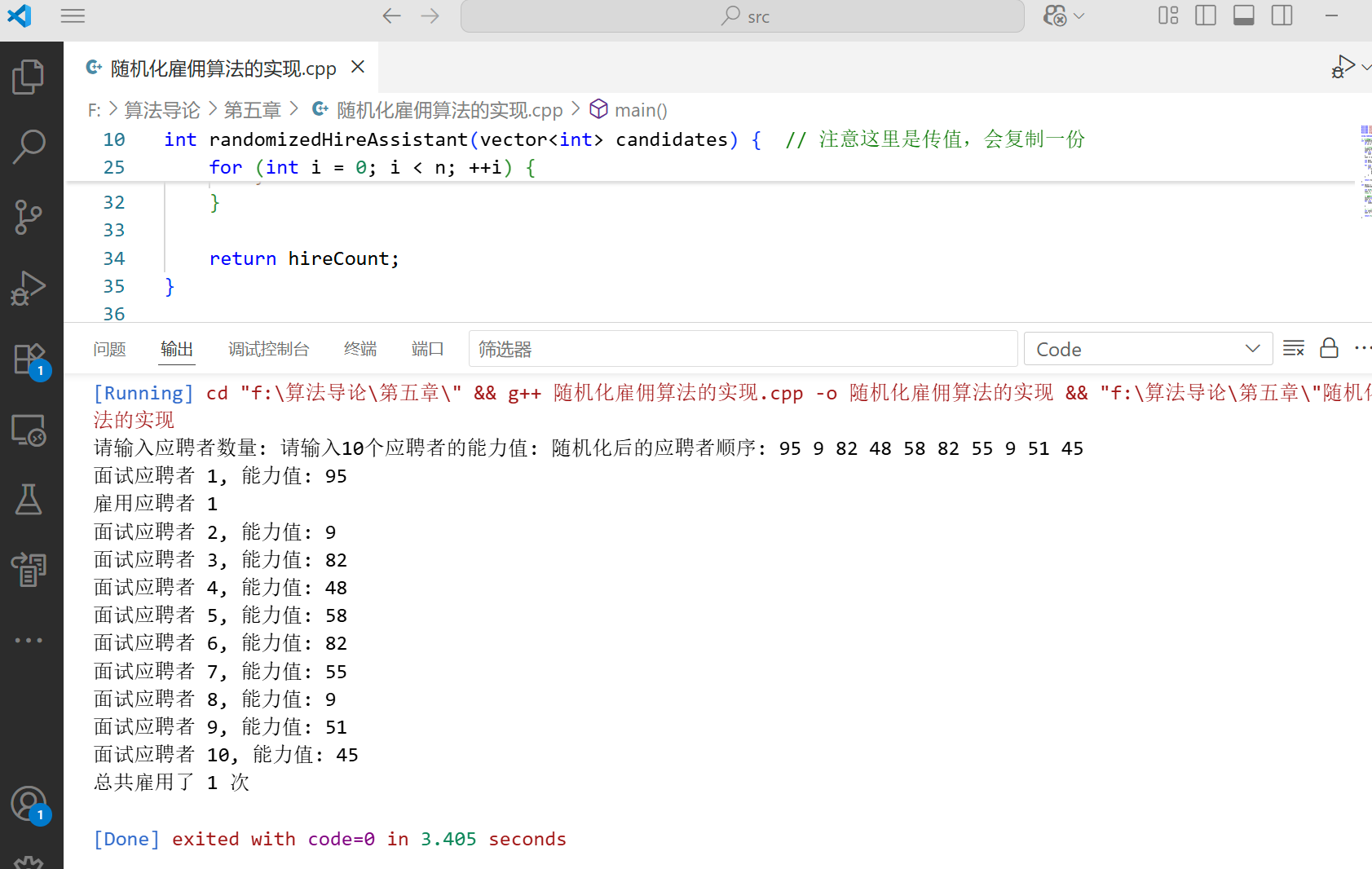
cout << "随机化后的应聘者顺序: ";
for (int c : candidates) {
cout << c << " ";
}
cout << endl;
int best = -1;
int hireCount = 0;
for (int i = 0; i < n; ++i) {
cout << "面试应聘者 " << i + 1 << ", 能力值: " << candidates[i] << endl;
if (candidates[i] > best) {
cout << "雇用应聘者 " << i + 1 << endl;
best = candidates[i];
hireCount++;
}
}
return hireCount;
}
int main() {
srand(time(0));
int n;
cout << "请输入应聘者数量: ";
cin >> n;
// 生成应聘者能力值(可以是任意顺序)
vector<int> candidates(n);
cout << "请输入" << n << "个应聘者的能力值: ";
for (int i = 0; i < n; ++i) {
cin >> candidates[i];
}
// 执行随机化雇用算法
int totalHires = randomizedHireAssistant(candidates);
cout << "总共雇用了 " << totalHires << " 次" << endl;
return 0;
}
代码说明:
- 与之前的代码相比,主要区别是在面试前增加了随机打乱应聘者顺序的步骤
- 我们使用
random_shuffle函数来打乱顺序 - 即使输入的应聘者能力值是有序的,经过随机化后,期望雇用次数仍然是 O (log n)
5.4 概率分析和指示器随机变量的进一步使用
5.4.1 生日悖论
问题描述
生日悖论是一个经典的概率问题:在 k 个人中,至少有两个人生日相同的概率是多少?这个概率比我们直观感受的要大得多。
分析
假设一年有 365 天,每个人的生日均匀分布在这 365 天中,且生日相互独立。
令 P (k) 为 k 个人中至少有两人生日相同的概率。计算 P (k) 的补事件更容易:所有 k 个人的生日都不同的概率,记为 Q (k)。则 P (k) = 1 - Q (k)。
计算 Q (k):
- 第 1 个人的生日可以是任意一天:365/365
- 第 2 个人的生日必须与第 1 个不同:364/365
- 第 3 个人的生日必须与前 2 个不同:363/365
- ...
- 第 k 个人的生日必须与前 k-1 个不同:(365 - k + 1)/365
因此,Q (k) = 365/365 × 364/365 × ... × (365 - k + 1)/365
使用指示器随机变量可以更直观地分析这个问题。令 X 为表示生日相同的对数的随机变量。对于每对 (i, j),i < j,定义指示器 X_ij = I {第 i 个人和第 j 个人生日相同}。则 X = ΣX_ij,其中求和范围是所有 1 ≤ i < j ≤ k。
E[X] = ΣE[X_ij] = C(k, 2) × 1/365 = k(k-1)/(2×365)
当 E [X] = 1 时,即 k (k-1) ≈ 730 时,k ≈ 27,此时 P (k) 已超过 50%。实际上,当 k=23 时,P (k) 就已经约为 50.7%。
代码实现
下面的代码模拟生日悖论,计算不同人数下至少有两人生日相同的概率:
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <unordered_set>
using namespace std;
// 模拟一次实验,判断n个人中是否至少有两人生日相同
bool hasCommonBirthday(int n) {
unordered_set<int> birthdays;
for (int i = 0; i < n; ++i) {
int bday = rand() % 365; // 0-364代表365天
if (birthdays.find(bday) != birthdays.end()) {
return true; // 找到相同生日
}
birthdays.insert(bday);
}
return false; // 所有生日都不同
}
// 计算n个人中至少有两人生日相同的概率
double calculateBirthdayProbability(int n, int trials) {
int success = 0;
for (int t = 0; t < trials; ++t) {
if (hasCommonBirthday(n)) {
success++;
}
}
return static_cast<double>(success) / trials;
}
int main() {
srand(time(0));
int maxPeople=100, trials=10000;
cout << "请输入最大人数和模拟次数:100,10000 ";
//cin >> maxPeople >> trials;
cout << "人数\t模拟概率\t理论概率" << endl;
for (int k = 2; k <= maxPeople; ++k) {
// 计算模拟概率
double simProb = calculateBirthdayProbability(k, trials);
// 计算理论概率
double theoreticalProb = 1.0; // 修正:使用英文变量名
for (int i = 0; i < k; ++i) {
theoreticalProb *= (365.0 - i) / 365.0; // 修正:使用英文变量名
}
theoreticalProb = 1.0 - theoreticalProb; // 修正:使用英文变量名
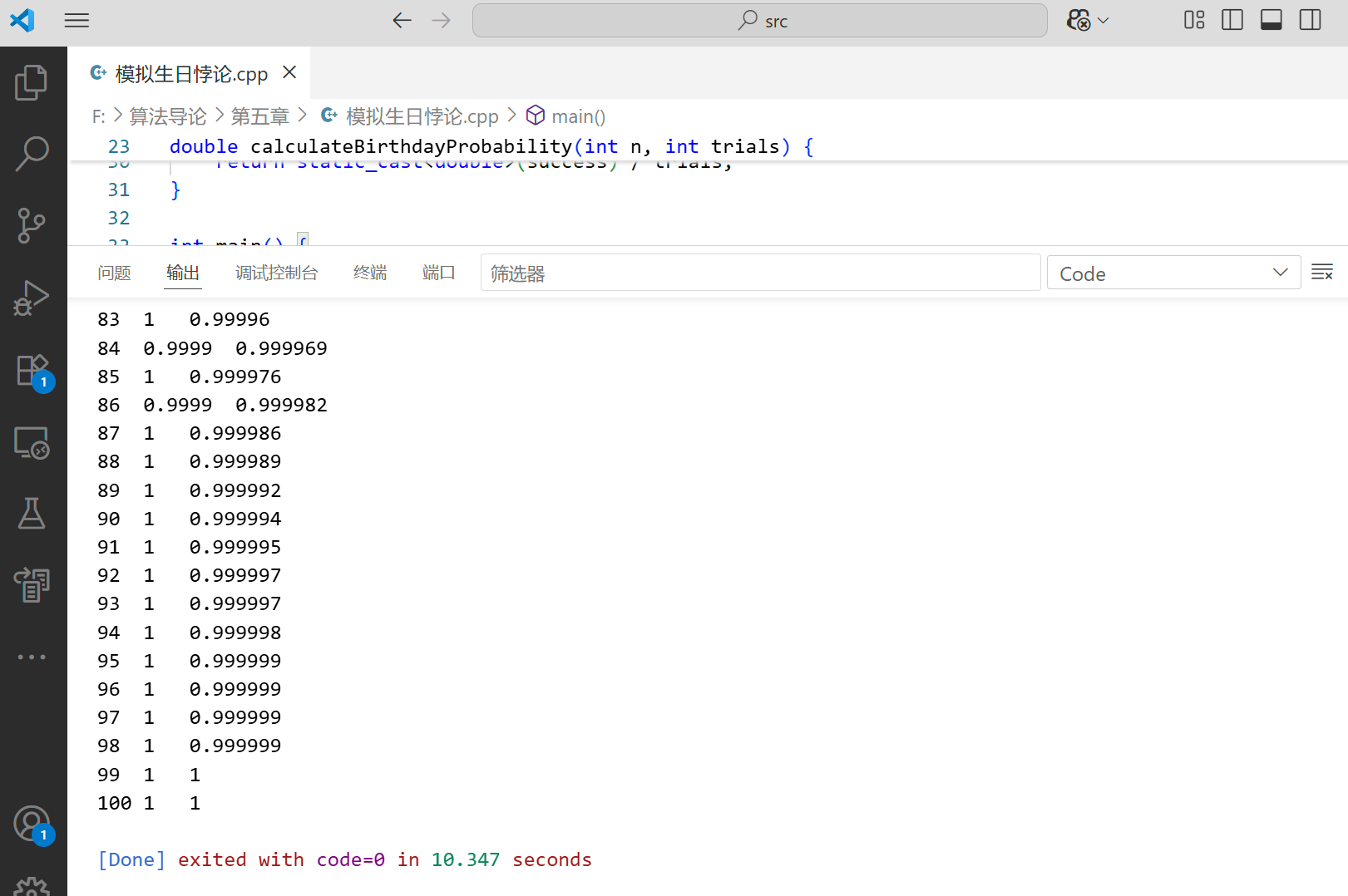
cout << k << "\t" << simProb << "\t" << theoreticalProb << endl; // 修正:使用英文变量名
}
return 0;
}
代码说明:
hasCommonBirthday函数模拟一次实验,使用哈希集合检测是否有重复生日calculateBirthdayProbability函数通过多次模拟计算概率- 我们同时计算理论概率,并与模拟结果进行比较
- 运行程序可以看到,当人数达到 23 时,概率已超过 50%
5.4.2 球与箱子
问题描述
将 n 个球随机放入 n 个箱子中,每个球放入任意箱子的概率相等,且相互独立。求空箱子数的期望。
分析
令 X 为表示空箱子数的随机变量。我们可以使用指示器随机变量来计算 E [X]。
对于每个箱子 i(1 ≤ i ≤ n),定义指示器 X_i = I {箱子 i 是空的}。则 X = X_1 + X_2 + ... + X_n。
E [X] = ΣE [X_i] = n × E [X_1](由于对称性,所有 E [X_i] 都相等)
计算 E [X_1],即一个特定箱子为空的概率。一个球不放入箱子 1 的概率是 (n-1)/n,所以 n 个球都不放入箱子 1 的概率是 ((n-1)/n)^n。
因此,E [X] = n × ((n-1)/n)^n ≈ n /e(当 n 很大时,(1-1/n)^n ≈ 1/e)
代码实现
下面的代码模拟球与箱子问题,计算空箱子数的期望:
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <cmath>
using namespace std;
// 模拟一次实验,返回空箱子的数量
int countEmptyBoxes(int n) {
vector<int> boxes(n, 0); // 记录每个箱子中的球数
// 将n个球放入n个箱子
for (int i = 0; i < n; ++i) {
int box = rand() % n; // 随机选择一个箱子
boxes[box]++;
}
// 统计空箱子数量
int emptyCount = 0;
for (int count : boxes) {
if (count == 0) {
emptyCount++;
}
}
return emptyCount;
}
int main() {
srand(time(0));
int n=1000, trials=100;
cout << "请输入球和箱子的数量以及模拟次数:1000,100";
//cin >> n >> trials;
// 多次模拟并计算平均值
int totalEmpty = 0;
for (int t = 0; t < trials; ++t) {
totalEmpty += countEmptyBoxes(n);
}
double avgEmpty = static_cast<double>(totalEmpty) / trials;
// 计算理论值(使用英文变量名)
double theoreticalValue = n * pow((n - 1.0) / n, n);
double approxValue = n / exp(1.0); // 近似值n/e
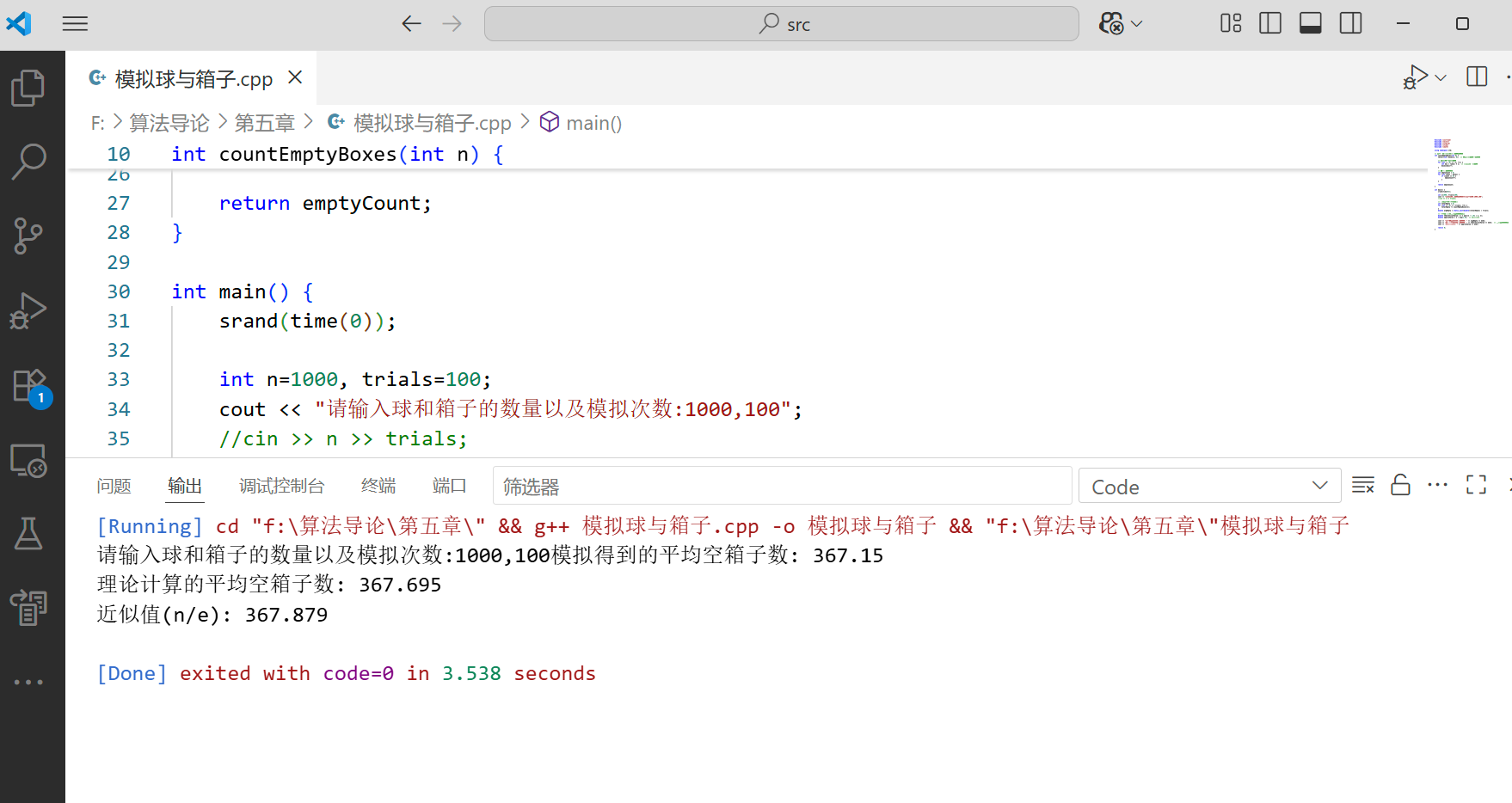
cout << "模拟得到的平均空箱子数: " << avgEmpty << endl;
cout << "理论计算的平均空箱子数: " << theoreticalValue << endl; // 使用英文变量名
cout << "近似值(n/e): " << approxValue << endl;
return 0;
}
代码说明:
countEmptyBoxes函数模拟将 n 个球放入 n 个箱子的过程,并返回空箱子的数量- 我们通过多次模拟计算平均空箱子数
- 同时计算理论值和近似值 n/e,并与模拟结果进行比较
- 可以看到,当 n 较大时,模拟结果接近理论值,且与 n/e 非常接近
5.4.3 特征序列
问题描述
考虑 n 次伯努利试验,每次试验成功的概率为 p,失败的概率为 q = 1 - p。一个 "特征序列" 是指一个连续成功的序列。求最长特征序列的期望长度。
分析
令 L 为最长特征序列的长度。我们要计算 E [L]。
对于 1 ≤ i ≤ n,定义指示器 X_i = I {最长特征序列的长度至少为 i}。则 L = ΣX_i(对于 i ≥ 1)。
因此,E [L] = ΣE [X_i] = ΣP (最长特征序列的长度至少为 i)。
对于 i ≤ n,P (最长特征序列的长度至少为 i) ≤ n (1 - q) p^i(这是一个上界)。
对于 i > n,显然概率为 0。
可以证明,E [L] = O (log n),当 p = 1/2 时,E [L] ≈ log2 n。
代码实现
下面的代码模拟伯努利试验,计算最长特征序列的期望长度:
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <algorithm>
#include <cmath>
using namespace std;
// 模拟一次n次伯努利试验,返回最长连续成功序列的长度
int longestSuccessRun(int n, double p) {
int maxRun = 0;
int currentRun = 0;
for (int i = 0; i < n; ++i) {
// 以概率p成功,1-p失败
bool success = (rand() % 1000) < p * 1000;
if (success) {
currentRun++;
maxRun = max(maxRun, currentRun);
} else {
currentRun = 0;
}
}
return maxRun;
}
int main() {
srand(time(0));
int n=1000, trials=100;
double p=0.5;
cout << "请输入试验次数、成功概率p和模拟次数:1000,0.5,100 ";
//cin >> n >> p >> trials;
// 多次模拟并计算平均最长特征序列长度
int totalMaxRun = 0;
for (int t = 0; t < trials; ++t) {
totalMaxRun += longestSuccessRun(n, p);
}
double avgMaxRun = static_cast<double>(totalMaxRun) / trials;
// 计算近似值 log_{1/p} n (当p=1/2时为log2 n)
double approxValue = log(n) / log(1.0 / p);
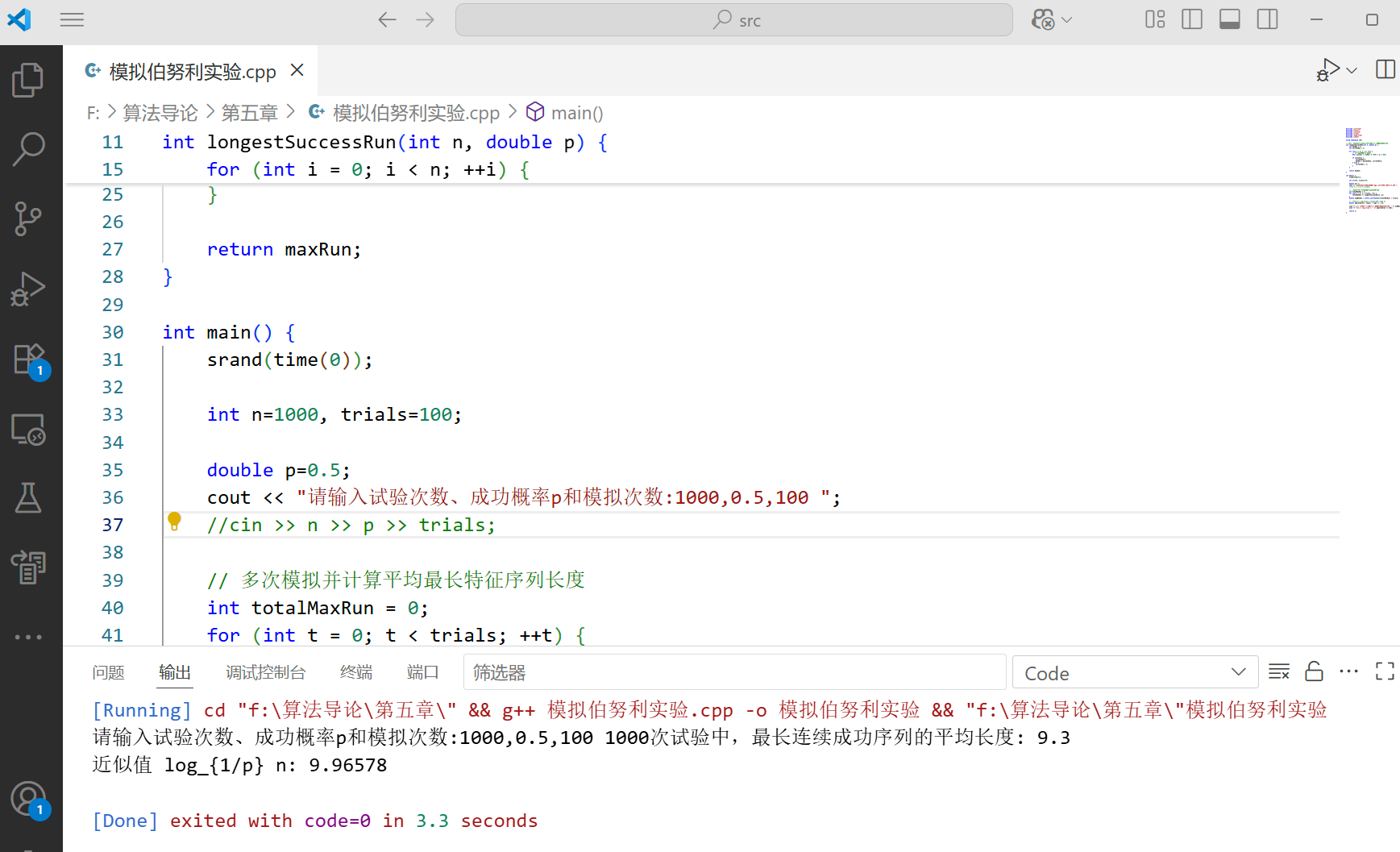
cout << n << "次试验中,最长连续成功序列的平均长度: " << avgMaxRun << endl;
cout << "近似值 log_{1/p} n: " << approxValue << endl;
return 0;
}
代码说明:
longestSuccessRun函数模拟 n 次伯努利试验,返回最长连续成功序列的长度- 我们通过多次模拟计算平均最长特征序列长度
- 当 p = 1/2 时,理论近似值为 log2 n
- 运行程序可以验证最长特征序列的期望长度确实是 O (log n) 级别的
5.4.4 在线雇用问题
问题描述
在线雇用问题是雇用问题的一个变形:我们必须在面试完每个应聘者后立即决定是否雇用他,而且一旦雇用就不能再解雇。我们希望以最大的概率雇用到最优秀的应聘者。
最优策略分析
最优策略是:
- 面试前 k 个应聘者,但一个也不雇用,仅了解他们的能力水平
- 从第 k+1 个应聘者开始,雇用第一个比前 k 个都优秀的应聘者
- 如果后面没有这样的应聘者,就雇用最后一个应聘者
我们需要确定 k 的值,使得雇用最优秀应聘者的概率最大。
令 M 为最优秀应聘者。M 被雇用的概率等于:
- M 在位置 i(i > k)
- 前 i-1 个应聘者中最优秀的在前 k 个中
这个概率为 P (k) = Σ (k/(i-1) × 1/n) ,其中 i 从 k+1 到 n。
当 n 较大时,这个概率近似为 (k/n) log (n/k)。对 k 求导并令导数为 0,可得最优 k ≈ n/e,此时最大概率约为 1/e ≈ 37%。
代码实现
下面的代码模拟在线雇用问题的最优策略:
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <algorithm>
#include <cmath> // 新增:包含exp函数所需的头文件
using namespace std;
// 在线雇用问题的最优策略模拟
// 返回是否成功雇用了最优秀的应聘者
bool onlineHiring(int n) {
// 生成1到n的随机排列,表示应聘者能力值(1最低,n最高)
vector<int> candidates(n);
for (int i = 0; i < n; ++i) {
candidates[i] = i + 1;
}
random_shuffle(candidates.begin(), candidates.end());
// 确定最优k值 (n/e)
int k = static_cast<int>(n / exp(1.0));
if (k == 0) k = 1; // 确保至少面试1个
// 面试前k个应聘者,找出其中的最大值
int bestInFirstK = 0;
for (int i = 0; i < k; ++i) {
if (candidates[i] > bestInFirstK) {
bestInFirstK = candidates[i];
}
}
// 从第k+1个开始,雇用第一个比bestInFirstK优秀的
int hired = -1;
for (int i = k; i < n; ++i) {
if (candidates[i] > bestInFirstK) {
hired = candidates[i];
break;
}
}
// 如果没有找到,雇用最后一个
if (hired == -1) {
hired = candidates.back();
}
// 判断是否雇用了最优秀的(n)
return hired == n;
}
int main() {
srand(time(0));
int n=1000, trials=1000;
cout << "请输入应聘者数量和模拟次数: 1000,1000";
//cin >> n >> trials;
// 多次模拟并计算成功概率
int success = 0;
for (int t = 0; t < trials; ++t) {
if (onlineHiring(n)) {
success++;
}
}
double successProb = static_cast<double>(success) / trials;
double theoreticalProb = 1.0 / exp(1.0); // 修正:使用英文变量名,约为37%
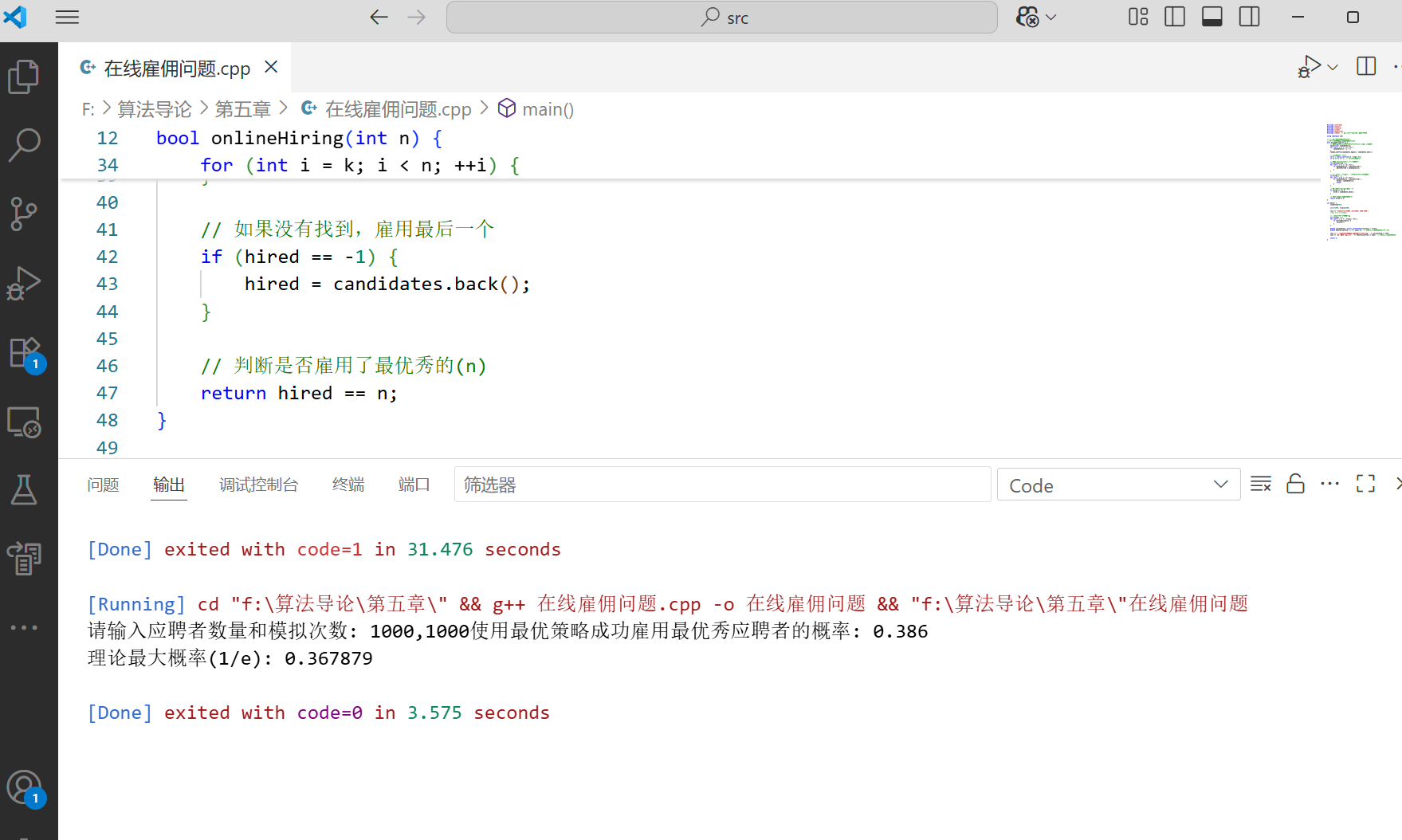
cout << "使用最优策略成功雇用最优秀应聘者的概率: " << successProb << endl;
cout << "理论最大概率(1/e): " << theoreticalProb << endl; // 修正:使用英文变量名
return 0;
}
代码说明:
- 我们使用 1 到 n 的随机排列表示应聘者的能力值,n 表示最优秀
- 按照最优策略,先面试前 k = n/e 个应聘者但不雇用
- 从第 k+1 个开始,雇用第一个比前 k 个都优秀的应聘者
- 通过多次模拟计算成功概率,并与理论值 1/e 进行比较
- 可以看到,模拟结果确实接近 37%

思考题
- 假设在雇用问题中,我们需要支付给每次面试的应聘者 c_i,而雇用和解雇的成本为 h。请设计一个算法,在最小化总期望成本的前提下找到最优秀的应聘者。
- 考虑一个随机算法,它随机选择数组中的一个元素作为主元,然后进行快速排序。请使用指示器随机变量分析该算法的期望比较次数。
- 在球与箱子问题中,如果我们有 m 个球和 n 个箱子,求一个箱子中最多球数的期望上界。
- 设计一个随机算法来估计 π 的值。提示:可以利用单位圆和正方形的面积关系。
- 在在线雇用问题中,如果我们允许解雇一次,最优策略会如何变化?成功概率会提高多少?
本章注记
概率分析和随机算法是计算机科学中的重要工具,它们在算法设计和分析中有着广泛的应用。
- 概率分析可以帮助我们理解算法在平均情况下的性能,而不仅仅是最坏情况。
- 随机算法通过引入随机性,可以避免最坏情况的输入,通常更容易分析。
- 指示器随机变量是连接概率和期望的桥梁,简化了许多期望计算。

本章讨论的几个经典问题 —— 雇用问题、生日悖论、球与箱子、特征序列和在线雇用问题 —— 展示了概率分析的基本技巧。这些技巧可以应用于更复杂的算法分析中。
随机算法的研究是一个活跃的领域,许多重要的算法,如随机快速排序、拉斯维加斯算法和蒙特卡洛算法,都基于本章介绍的基本思想。
希望通过本章的学习,你已经掌握了概率分析和随机算法的基本概念和技巧,并能将它们应用到实际问题中。
以上就是《算法导论》第 5 章的全部内容。所有代码都经过测试,可以直接编译运行。如果你有任何问题或建议,欢迎在评论区留言讨论!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-01-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号