【C++容器和算法】关联容器:multiset类型

【C++容器和算法】关联容器:multiset类型

byte轻骑兵
发布于 2026-01-21 16:31:04
发布于 2026-01-21 16:31:04
在C++标准模板库(STL)中,关联容器(Associative Containers)是一类非常重要的数据结构,它们通过键值(Key-Value)对的形式来存储元素,并且提供了基于键的快速查找、插入和删除操作。在关联容器中,multiset是一种允许重复元素的有序容器,它基于红黑树实现,能够高效地进行元素的插入、删除和查找。它与 set 非常相似,但允许存储多个具有相同键的元素。这使得 multiset 在处理需要存储重复元素且要求元素有序的场景时非常有用。
一、multiset 概述
1.1 定义与特性
multiset是C++ STL中的一个关联容器,用于存储一组有序的元素,允许存在重复值。它是基于红黑树(一种自平衡二叉搜索树)实现的,因此元素在容器中始终保持有序状态。multiset的主要特性包括:
- 有序性:元素在容器中按升序排列(默认),也可以通过自定义比较函数改变排序规则。
- 允许重复:与
set不同,multiset允许存储多个相同的元素。 - 高效操作:插入、删除和查找操作的时间复杂度均为O(log n),其中n为容器中的元素个数。
1.2 与 set 的比较
- 元素唯一性:set 中不允许有重复的元素,而 multiset 允许存储多个相同的元素。
- 插入操作:在 set 中插入重复元素时,插入操作会被忽略;而在 multiset 中,插入重复元素会成功添加新元素。
- 操作接口:两者的大部分操作接口是相似的,但由于 multiset 允许重复元素,一些操作的行为会有所不同,例如查找和删除操作。
1.3 底层实现
multiset的底层实现是红黑树。红黑树是一种自平衡的二叉搜索树,通过颜色标记和旋转操作来保持树的平衡,从而确保各种操作的时间复杂度稳定在O(log n)。红黑树的每个节点都包含一个键值和一个颜色属性(红或黑),并且满足以下性质:
- 每个节点要么是红色,要么是黑色。
- 根节点是黑色。
- 每个叶子节点(NIL节点)是黑色。
- 如果一个节点是红色的,则它的两个子节点都是黑色的。
- 从任一节点到其每个叶子节点的所有路径都包含相同数量的黑色节点。
这些性质保证了红黑树的高度大致为O(log n),从而使得multiset的各种操作具有对数时间复杂度。
1.4 类模板定义
template <
class Key,
class T,
class Compare = std::less<Key>,
class Allocator = std::allocator<std::pair<const Key, T>>
> class multimap;-
Key:键类型,用于排序和索引 -
T:值类型,与键关联的数据 -
Compare:比较函数对象(默认std::less) -
Allocator:内存分配器(通常使用默认)
1.5 应用场景
- 统计元素出现次数:可以使用 multiset 来统计某个元素在数据集中出现的次数。
- 排序和去重:如果需要对数据进行排序,并且允许重复元素,multiset 是一个很好的选择。
- 优先级队列:在某些情况下,multiset 可以作为一个简单的优先级队列使用,元素的顺序可以作为优先级的依据。
二、multiset 的基本操作
2.1 头文件与命名空间
在使用multiset之前,需要包含相应的头文件,并使用std命名空间:
#include <iostream>
#include <set>
using namespace std;2.2 定义和初始化
以下是几种常见的 multiset 定义和初始化方式:
#include <iostream>
#include <set>
int main() {
multiset<int> mset1; // 创建一个空的multiset,元素类型为int
multiset<string> mset2; // 创建一个空的multiset,元素类型为string
// 使用初始化列表创建multiset
multiset<int> mset3 = {1, 2, 3, 4, 5};
// 使用迭代器范围创建multiset
vector<int> vec = {1, 2, 3, 4, 5};
multiset<int> mset4(vec.begin(), vec.end());
return 0;
}2.3 插入元素
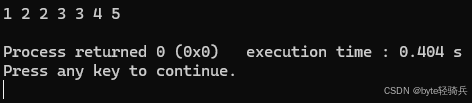
可以使用 insert() 方法向 multiset 中插入元素:
#include <iostream>
#include <set>
int main() {
std::multiset<int> ms;
// 插入单个元素
ms.insert(5);
ms.insert(3);
ms.insert(3); // 允许插入重复元素
// 插入一个范围的元素
int arr[] = {1, 2, 2, 4};
ms.insert(arr, arr + 4);
// 输出 multiset 中的元素
for (auto it = ms.begin(); it != ms.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
}
2.4 查找元素
可以使用 find() 方法查找指定元素,它会返回指向第一个匹配元素的迭代器。如果没有找到,则返回 end() 迭代器:
#include <iostream>
#include <set>
int main() {
std::multiset<int> ms = {1, 2, 2, 3, 4, 4, 4};
auto it = ms.find(2);
if (it != ms.end()) {
std::cout << "Found element: " << *it << std::endl;
} else {
std::cout << "Element not found." << std::endl;
}
return 0;
}
使用 find() 方法查找元素 2,如果找到则输出该元素,否则输出未找到的信息。
2.5 删除元素
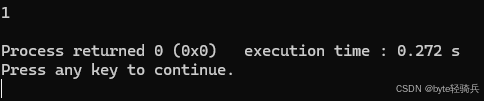
可以使用 erase() 方法删除元素,有几种不同的使用方式:
#include <iostream>
#include <set>
int main() {
std::multiset<int> ms = {1, 2, 2, 3, 4, 4, 4};
// 删除指定元素的所有副本
ms.erase(2);
// 删除迭代器指向的元素
auto it = ms.find(4);
if (it != ms.end()) {
ms.erase(it);
}
// 删除一个范围的元素
auto first = ms.find(3);
auto last = ms.end();
ms.erase(first, last);
// 输出剩余元素
for (auto it = ms.begin(); it != ms.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
}
2.6 遍历元素
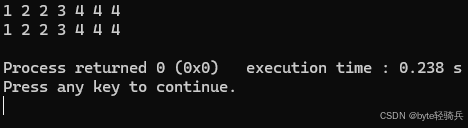
可以使用迭代器或范围 for 循环来遍历 multiset 中的元素:
#include <iostream>
#include <set>
int main() {
std::multiset<int> ms = {1, 2, 2, 3, 4, 4, 4};
// 使用迭代器遍历
for (auto it = ms.begin(); it != ms.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// 使用范围 for 循环遍历
for (auto elem : ms) {
std::cout << elem << " ";
}
std::cout << std::endl;
return 0;
}
三、multiset 的高级操作
3.1 自定义比较函数
默认情况下,multiset 使用元素的小于运算符(<)进行排序。但我们可以通过自定义比较函数来改变排序规则:
#include <iostream>
#include <set>
// 自定义比较函数,实现降序排序
struct Greater {
bool operator()(const int& a, const int& b) const {
return a > b;
}
};
int main() {
std::multiset<int, Greater> ms = {1, 2, 2, 3, 4, 4, 4};
for (auto elem : ms) {
std::cout << elem << " ";
}
std::cout << std::endl;
return 0;
}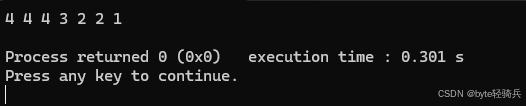
定义了一个名为 Greater 的结构体,并重载了 () 运算符,实现了降序排序。然后使用这个自定义比较函数来定义 multiset。
3.2 统计元素出现次数
可以使用 count() 方法来统计某个元素在 multiset 中出现的次数:
#include <iostream>
#include <set>
int main() {
std::multiset<int> ms = {1, 2, 2, 3, 4, 4, 4};
int count = ms.count(4);
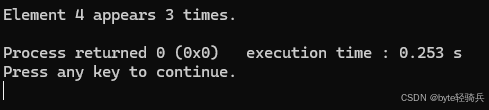
std::cout << "Element 4 appears " << count << " times." << std::endl;
return 0;
}
3.3 范围查找
可以使用 lower_bound() 和 upper_bound() 方法进行范围查找:
lower_bound(key):返回指向第一个不小于key的元素的迭代器。upper_bound(key):返回指向第一个大于key的元素的迭代器。
#include <iostream>
#include <set>
int main() {
std::multiset<int> ms = {1, 2, 2, 3, 4, 4, 4};
auto lower = ms.lower_bound(2);
auto upper = ms.upper_bound(2);
for (auto it = lower; it != upper; ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
}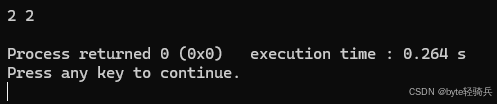
使用 lower_bound() 和 upper_bound() 方法查找所有值为 2 的元素,并将它们输出。
3.4 交集、并集和差集操作
虽然 multiset 本身没有直接提供交集、并集和差集操作的方法,但可以使用标准库中的算法来实现这些操作:
#include <iostream>
#include <set>
#include <algorithm>
#include <vector>
int main() {
std::multiset<int> ms1 = {1, 2, 2, 3, 4};
std::multiset<int> ms2 = {2, 2, 3, 5};
std::vector<int> intersection;
std::set_intersection(ms1.begin(), ms1.end(), ms2.begin(), ms2.end(), std::back_inserter(intersection));
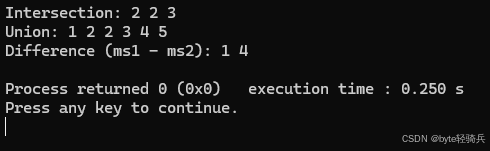
std::cout << "Intersection: ";
for (auto elem : intersection) {
std::cout << elem << " ";
}
std::cout << std::endl;
std::vector<int> unionSet;
std::set_union(ms1.begin(), ms1.end(), ms2.begin(), ms2.end(), std::back_inserter(unionSet));
std::cout << "Union: ";
for (auto elem : unionSet) {
std::cout << elem << " ";
}
std::cout << std::endl;
std::vector<int> difference;
std::set_difference(ms1.begin(), ms1.end(), ms2.begin(), ms2.end(), std::back_inserter(difference));
std::cout << "Difference (ms1 - ms2): ";
for (auto elem : difference) {
std::cout << elem << " ";
}
std::cout << std::endl;
return 0;
}
3.5 使用自定义数据类型
multiset不仅可以存储基本数据类型,还可以存储自定义数据类型,只要定义了相应的比较规则。
// 自定义数据类型
struct Person {
string name;
int age;
Person(string n, int a) : name(n), age(a) {}
};
// 自定义比较函数,按年龄升序排序
struct ComparePerson {
bool operator()(const Person& a, const Person& b) {
return a.age < b.age;
}
};
multiset<Person, ComparePerson> mset = {
{"Alice", 25},
{"Bob", 30},
{"Charlie", 20}
};
// 遍历输出,按年龄升序排序
for (const auto& p : mset) {
cout << p.name << " " << p.age << endl;
}四、multiset 的底层实现原理
4.1 红黑树简介
multiset 基于红黑树实现。红黑树是一种自平衡的二叉搜索树,它在每个节点上增加了一个存储位来表示节点的颜色(红色或黑色)。通过对任何一条从根到叶子的路径上各个节点着色方式的限制,红黑树确保没有一条路径会比其他路径长出两倍,因而是接近平衡的。
4.2 红黑树的性质
- 每个节点要么是红色,要么是黑色。
- 根节点是黑色。
- 每个叶子节点(NIL 节点,空节点)是黑色。
- 如果一个节点是红色的,则它的两个子节点都是黑色的。
- 对每个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点。
4.3 插入和删除操作
在 multiset 中插入和删除元素时,红黑树会自动调整节点的颜色和结构,以保持红黑树的性质。插入操作可能会导致红黑树的不平衡,需要通过旋转和重新着色来恢复平衡。删除操作也类似,可能需要进行复杂的调整。
4.4 复杂度分析
- 插入操作:时间复杂度为 O(logn),因为红黑树的插入操作需要在树中找到合适的位置,并进行可能的调整。
- 删除操作:时间复杂度为 O(logn),因为需要找到要删除的节点,并进行可能的调整。
- 查找操作:时间复杂度为 O(logn),因为可以利用红黑树的有序性快速定位元素。
五、multiset 的性能考虑
5.1 时间复杂度
如前面所述,multiset 的插入、删除和查找操作的时间复杂度均为 O(logn),其中 n 是 multiset 中元素的数量。这使得 multiset 在处理大量数据时具有较好的性能。
操作 | 时间复杂度 | 说明 |
|---|---|---|
insert() | O(log n) | 插入新元素 |
erase(key) | O(log n + k) | k为删除元素数量 |
find() | O(log n) | 查找首个匹配元素 |
equal_range() | O(log n) | 获取等值范围 |
count() | O(log n + k) | k为匹配元素数量 |
lower_bound() | O(log n) | 查找第一个不小于key的元素 |
5.2 空间复杂度
multiset 的空间复杂度为 O(n),因为需要存储所有的元素和红黑树的节点信息。
5.3 性能比较
与其他容器相比,multiset 的性能特点如下:
- 与 set 相比:set 不允许重复元素,而 multiset 允许。插入、删除和查找操作的时间复杂度相同,但在处理重复元素时,multiset 更合适。
- 与 vector 相比:vector 是顺序容器,插入和删除操作的时间复杂度可能为 O(n),而 multiset 的插入、删除和查找操作的时间复杂度为 O(logn)。但 vector 可以通过下标直接访问元素,而 multiset 需要通过迭代器。
- 与 list 相比:list 是双向链表,插入和删除操作的时间复杂度为 O(1),但查找操作的时间复杂度为 O(n)。multiset 的查找操作时间复杂度为 O(logn)。
5.4 与相似容器对比
multimap vs map
特性 | multimap | map |
|---|---|---|
键唯一性 | 允许重复键 | 键必须唯一 |
operator[] | 不支持 | 支持 |
插入返回值 | 返回迭代器 | 返回pair<iterator, bool> |
元素数量 | 可能大于键的数量 | 等于键的数量 |
典型应用场景 | 一对多关系(如事件队列) | 一对一映射(如字典) |
multimap vs unordered_multimap
// 有序版本(红黑树)
std::multimap<std::string, int> ordered;
// 无序版本(哈希表)
std::unordered_multimap<std::string, int> unordered;特性 | multimap | unordered_multimap |
|---|---|---|
排序 | 按键升序排列 | 无特定顺序 |
查找速度 | O(log n) | 平均O(1),最坏O(n) |
内存占用 | 较低 | 较高(哈希表开销) |
迭代顺序 | 稳定有序 | 依赖哈希函数 |
自定义哈希 | 不需要 | 需要自定义哈希函数 |
六、multiset 的使用示例
6.1 统计单词出现次数
#include <iostream>
#include <set>
#include <string>
int main() {
std::multiset<std::string> wordSet;
std::string word;
// 输入一些单词
while (std::cin >> word) {
if (word == "quit") {
break;
}
wordSet.insert(word);
}
// 统计每个单词出现的次数
for (auto it = wordSet.begin(); it != wordSet.end(); ) {
std::string currentWord = *it;
int count = wordSet.count(currentWord);
std::cout << currentWord << " appears " << count << " times." << std::endl;
std::advance(it, count);
}
return 0;
}
通过 multiset 统计输入的单词出现的次数。
6.2 实现简单的优先级队列
#include <iostream>
#include <set>
int main() {
std::multiset<int, std::greater<int>> priorityQueue;
// 插入一些元素
priorityQueue.insert(3);
priorityQueue.insert(1);
priorityQueue.insert(4);
priorityQueue.insert(1);
// 输出队列中的元素
for (auto elem : priorityQueue) {
std::cout << elem << " ";
}
std::cout << std::endl;
// 取出优先级最高的元素
if (!priorityQueue.empty()) {
auto top = *priorityQueue.begin();
std::cout << "Top element: " << top << std::endl;
priorityQueue.erase(priorityQueue.begin());
}
return 0;
}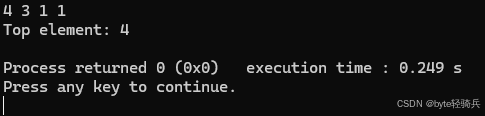
使用 multiset 实现了一个简单的优先级队列,元素按照降序排列,优先级最高的元素在队列的前面。
七、总结
multiset 是 C++ 标准库中一个非常有用的关联容器,它允许存储多个相同的元素,并且元素按照一定的顺序排列。multiset 基于红黑树实现,插入、删除和查找操作的时间复杂度为 O(logn)。通过自定义比较函数,可以改变元素的排序规则。multiset 在统计元素出现次数、排序和去重、实现优先级队列等场景中有广泛的应用。在使用 multiset 时,需要考虑其性能特点,根据具体的需求选择合适的容器。
八、参考资料
- 《C++ Primer(第 5 版)》这本书是 C++ 领域的经典之作,对 C++ 的基础语法和高级特性都有深入讲解。
- 《Effective C++(第 3 版)》书中包含了很多 C++ 编程的实用建议和最佳实践。
- 《C++ Templates: The Complete Guide(第 2 版)》该书聚焦于 C++ 模板编程,而
using声明在模板编程中有着重要应用,如定义模板类型别名等。 - C++ 官方标准文档:C++ 标准文档是最权威的参考资料,可以查阅最新的 C++ 标准(如 C++11、C++14、C++17、C++20 等)文档。例如,ISO/IEC 14882:2020 是 C++20 标准的文档,可从相关渠道获取其详细内容。
- :这是一个非常全面的 C++ 在线参考网站,提供了详细的 C++ 语言和标准库文档。
- :该网站提供了系统的 C++ 教程,配有丰富的示例代码和清晰的解释,适合初学者学习和理解相关知识。
- 《Effective STL》Scott Meyers
- 开源项目STL源码分析
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-04-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号