用 400 行核心代码打造一个极简的 MoltBot(OpenClaw),这货现在叫 tele-code
原创
用 400 行核心代码打造一个极简的 MoltBot(OpenClaw),这货现在叫 tele-code
原创
老码小张
发布于 2026-02-06 17:07:57
发布于 2026-02-06 17:07:57
我用一个周末,把 Telegram 变成了远程操控本地 AI 编程工具OpenCode的遥控器。这篇文章不是教程,更像是一次"边想边做"的技术探索记录。
起因仅仅只是一个朴素的需求,事情的起因其实很简单——我在用 OpenCode[1](一个本地运行的 AI 编程终端工具),它很强大,甚至我觉得可能比 Claude code 还好用那么一点点。
open code
但有个问题:我必须坐在电脑前才能用它。
前两天我在外面吃饭,突然想起一个 bug 的修复思路,掏出手机,盯着微信发呆——如果我能直接在 微信 或者说Telegram 里也行,直接给我电脑上的 OpenCode 发消息,让它帮我改代码,然后把结果发回来,那该多好?
这让我想到了 openClaw[2](当然这货的前身叫 moltbot),说是因为 macmini 卖断货,就是因为它。但 openClaw 做得比较重,我只需要一个极简版本:一个跑在我自己电脑上的中间件,把 Telegram 消息桥接到本地 OpenCode 实例。
所以我决定自己造一个,原因其实就是这,我觉得我这个需求并没有特别的复杂。

这是我在 tel 上发了一个消息给到 tel-code,他在我本地电脑上干活后,把结果给我
第一个问题:这东西的架构应该长什么样?
我先画了一张草图:
Telegram 用户(手机) <--> Bridge Server(本地) <--> OpenCode(本地)看起来很简单,但仔细想就会冒出一堆问题:
- 1. Telegram 怎么接消息? Webhook 还是 Polling?
- 2. OpenCode 怎么驱动? 有 SDK 吗?能编程调用吗?
- 3. 中间结果怎么同步? AI 生成代码是流式的,用户等几十秒看到一坨文字,体验很差。
- 4. 会话怎么管理? Telegram 的 chatId 和 OpenCode 的 session 怎么对应?
一个一个来。
Webhook vs Polling:我肯定只选简单的
Webhook 需要一个公网可访问的 HTTPS 地址。我这个东西跑在自己电脑上,搞个 ngrok 或者 Cloudflare Tunnel?太折腾了。
Polling 就够了。 Telegraf 框架的 bot.launch() 直接就是 long polling,零配置,启动就能收消息。在"自用"场景下,polling 的延迟(通常几百毫秒)完全可以接受。
探索OpenCode SDK,我发现 opencode-sdk-js
翻了一下 OpenCode 的生态,发现了 @opencode-ai/sdk[3]。这个 SDK 提供了完整的编程接口:
// 创建会话
const session = await client.session.create();
// 发送消息(异步,不阻塞)
await client.session.promptAsync({
path: { id: sessionId },
body: { parts: [{ type: 'text', text: '帮我修复这个 bug' }] }
});
// 订阅事件流(SSE)
const { stream } = await client.event.subscribe();
forawait (const event of stream) {
// 实时接收 AI 的输出
}关键发现:它有 SSE 事件流。这意味着我不需要轮询 OpenCode 的状态,AI 每生成一段文字,我就能立刻收到通知。这对实时推送到 Telegram 至关重要。
他不光可以创建创建会话,还有列出所有 session 的这个能力,这对于我们远程指挥 open code 至关重要。
那么,我的核心设计,其实就是做好事件驱动的桥接
想明白上面这些,架构就清晰了:
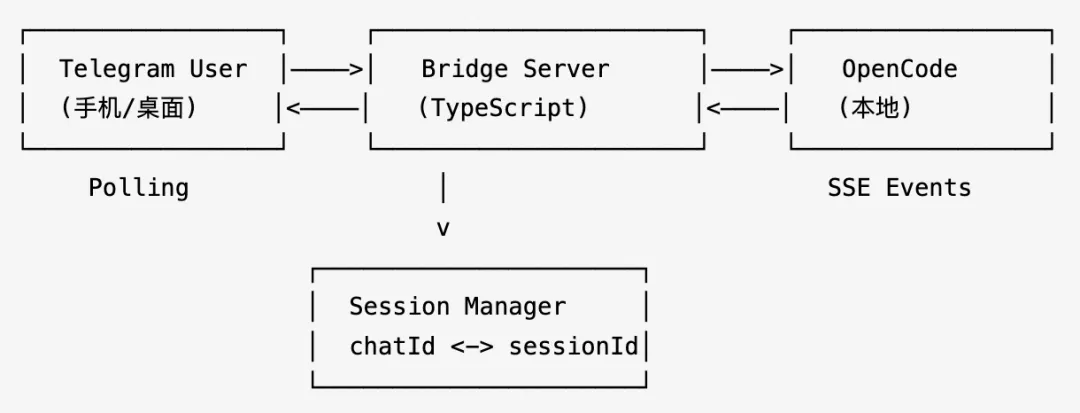
图片
我的核心思路是:用 Telegram Polling 收消息,用 OpenCode SSE 收结果,中间用一个 Session Manager 把两边对应起来。
整个数据流:
- 用户在 Telegram 发 "帮我完善下XX 逻辑"
- Bridge 收到消息,查 Session Manager,找到(或创建)对应的 OpenCode Session
- Bridge 调
promptAsync()把消息转发给 OpenCode - OpenCode 开始干活,通过 SSE 流式输出结果
- Bridge 收到
message.part.updated事件,调 Telegram 的editMessageText实时更新消息 - OpenCode 完成,发出
session.idle事件,Bridge 发送最终结果
那么,我为什么用 promptAsync 而不是 prompt?
prompt 是阻塞的——等 AI 完全输出完才返回。如果任务要跑几分钟,整个 Bridge 就卡在那里,无法处理其他消息。promptAsync 立即返回,结果通过事件流异步推送。这是正确的选择。有异步绝对不用同步,哈哈 。
流式更新,让 Telegram 消息"动起来"
这是整个项目体验最好的部分,也是踩坑最多的部分。
思路: AI 每输出一段话,我就编辑 Telegram 里的那条消息,把内容追加上去。用户看到的效果就像 AI 在"打字"。
openCodeService.on('message.part.updated', async (event) => {
// 只处理文本类型的 part
if (event.part?.type !== 'text') return;
// 累积内容
const newContent = event.delta
? currentContent + event.delta
: event.content;
// 编辑 Telegram 消息
await telegramService.editMessage(chatId, messageId, newContent);
});但这里有一个大坑:Telegram 的 API 有限流。
如果 AI 输出很快(比如每秒 10+ 个 token),每个 token 都调一次 editMessageText,Telegram 会返回 429 Too Many Requests。
解决方案非常简单,收集一波在发过去,简单说就是节流(Throttle)。
const EDIT_THROTTLE_MS = 1000; // 每秒最多编辑一次
functionshouldThrottle(chatId: number): boolean {
const now = Date.now();
const lastTime = lastEditTime.get(chatId) || 0;
if (now - lastTime < EDIT_THROTTLE_MS) {
returntrue; // 跳过这次编辑,内容已经累积了,下次一起更新
}
lastEditTime.set(chatId, now);
returnfalse;
}策略是"累积内容,定期刷新"——每次收到事件都累积文本,但只有间隔超过 1 秒才真正去编辑消息。这样用户看到的是每秒刷新一次的效果,既流畅又不会被限流。
任务完成时(session.idle 事件),无论节流状态如何,都会做一次最终更新,确保用户看到完整结果。
另一个坑:Telegram 消息的 4096 字符限制
Telegram 单条消息最大 4096 字符。AI 生成的代码经常超过这个限制。
解决方案:智能分割。
export functionsplitMessage(text: string, maxLength = 4096): string[] {
if (text.length <= maxLength) return [text];
constmessages: string[] = [];
let remaining = text;
while (remaining.length > 0) {
if (remaining.length <= maxLength) {
messages.push(remaining);
break;
}
let splitIndex = maxLength - TRUNCATION_SUFFIX.length;
// 尽量在换行符处分割,而不是暴力截断
const lastNewline = remaining.lastIndexOf('\n', splitIndex);
if (lastNewline > splitIndex * 0.5) {
splitIndex = lastNewline;
}
messages.push(remaining.slice(0, splitIndex) + '\n\n... (message truncated)');
remaining = remaining.slice(splitIndex).trim();
}
return messages;
}关键点是:不要在代码块中间截断。 尽量找到最近的换行符来分割,这样每段消息至少在视觉上是完整的。当然多说强情况,我们其实不需要看代码块。
自动发现 OpenCode 服务器
最初我在 .env 里硬编码了 OpenCode 的端口号。但很快发现一个问题:OpenCode 每次启动可能监听不同的端口。
查了一下本地的进程:
opencode 63724 TCP localhost:4096 (LISTEN)
opencode 64736 TCP localhost:60123 (LISTEN)
opencode 99508 TCP localhost:57194 (LISTEN)三个 opencode 实例,三个不同端口。硬编码端口号显然不行。
解决方案:端口探测。
async initialize(): Promise<void> {
if (config.opencode.port) {
// 如果用户明确指定了端口,直接连
this.client = createOpencodeClient({ baseUrl: `http://127.0.0.1:${port}` });
} else {
// 否则,逐个探测常见端口
const commonPorts = [4096, 60123, 57194, 8080, 3000];
for (const port of commonPorts) {
const testClient = createOpencodeClient({ baseUrl: `http://127.0.0.1:${port}` });
try {
const response = await testClient.session.list();
if (!response.error) {
this.client = testClient; // 找到了!
return;
}
} catch {
// 这个端口不行,试下一个
}
}
// 都找不到?那就自己启动一个
const result = awaitcreateOpencode({ hostname: '127.0.0.1' });
this.client = result.client;
}
}三级降级策略: 指定端口 -> 自动发现 -> 自己启动。零配置也能用。
模型切换来解决,应对 API 限流
测试时遇到了另一个问题:OpenCode 默认模型的 API 频繁返回限流错误:
"High concurrency usage of this API, please reduce concurrency..."但 OpenCode 支持很多免费模型。为什么不能让用户通过 Telegram 切换模型?
于是加了 /model 和 /models 命令:
/models -- 查看可用模型
/model 1 -- 快速切换到 DeepSeek Chat
/model google gemini-2.0-flash -- 指定任意模型实现上,在 SessionState 里加了一个 model 字段,发送 prompt 时带上即可:
await client.session.promptAsync({
path: { id: sessionId },
body: {
parts: [{ type: 'text', text }],
...(model && { model }), // 有指定模型就用,没有就用默认
},
});最终的文件结构
tele-code/
├── src/
│ ├── index.ts # 入口:编排所有服务的启动顺序
│ ├── config.ts # 配置:类型安全的环境变量加载
│ ├── services/
│ │ ├── telegram.ts # Telegram Bot 封装(Telegraf)
│ │ ├── opencode.ts # OpenCode SDK 封装 + SSE 事件流
│ │ └── session.ts # 会话状态管理(chatId <-> sessionId)
│ ├── handlers/
│ │ └── message.ts # 消息处理:命令、文本、事件回调
│ └── utils/
│ └── formatter.ts # 消息格式化和分割
├── .env # 配置(Bot Token、代理等)
├── package.json
└── tsconfig.json7 个源文件,核心逻辑不到 400 行。
和 openClaw 的关系
写完之后回头看,这个项目本质上就是一个极简版的 openClaw。
openClaw(前身 moltbot)做的事情是:把 AI 能力接入聊天平台。它的架构更完整,支持多用户、多平台、任务队列、权限管理等等。
而我的 tele-code 只保留了最核心的链路:
能力 | openClaw | tele-code |
|---|---|---|
聊天平台 | 多平台 | 仅 Telegram |
AI 后端 | 多种 | 仅 OpenCode |
用户管理 | 完整 | 单用户/简单白名单 |
会话管理 | 持久化 | 内存 |
消息同步 | 完整 | 流式文本 |
部署方式 | 云端/本地 | 本地 |
但核心抽象是一样的:Session 映射 + 事件驱动的消息桥接。
如果你理解了 tele-code 的设计,再去看 openClaw 的源码,会发现它就是在这个骨架上加了更多的肉:持久化存储、任务队列、多 agent 支持、工具调用可视化等等。
让我们回顾一下几个关键的设计决策
- Polling 而非 Webhook — 本地运行不需要公网地址,简单即正义
- promptAsync + SSE 而非 prompt 阻塞 — 异步是唯一正确的选择
- editMessageText + Throttle 实现流式 — 1 秒刷新一次,平衡体验和限流
- 端口自动探测 — 避免硬编码,零配置体验
- Session Manager 做桥接 — Telegram chatId 和 OpenCode sessionId 的映射是整个系统的"胶水"
- 模型可切换 — 应对限流,也给了用户选择的自由
有时候最好的工具不是功能最全的,而是刚好够用的。400 行代码,解决了"在手机上远程指挥 AI 写代码"这个需求。如果需要更多,openClaw 已经在那里了。
telegram 是否 可以换成迪斯科?换成飞书,换成企业微信,其实技术上一点问题都没有。就在于你自己的需求是怎么样的。
需要源码?可以加入我的小范围群进行交流。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号