CentOS 7 + Docker 部署 KWDB 3.1.0 全流程:三次踩坑记录与跨模查询实测
原创
CentOS 7 + Docker 部署 KWDB 3.1.0 全流程:三次踩坑记录与跨模查询实测
原创
一只牛博
发布于 2026-02-28 09:29:28
发布于 2026-02-28 09:29:28
摘要:本文记录了在 CentOS 7.6 云服务器上通过 Docker 部署 KaiwuDB(KWDB)3.1.0 单节点的完整过程,其中遭遇了三个非文档覆盖的坑点——Docker 启动命令格式错误、时序表与关系表不能建在同一数据库、TAG 列不能在普通列中重复定义。排坑完成后,通过跨数据库 JOIN 实测了 KWDB 的多模融合查询能力,6.7ms 完成时序数据与关系数据的联合检索。适合打算在 CentOS 7/Linux 环境首次部署 KWDB 的读者参考。
背景与环境
手上有一台闲置的阿里云 ECS,没什么特别的业务跑,正好 KaiwuDB 征文,于是决定把 KWDB 3.1.0 装上去试试。主要目的是体验它的多模融合能力——同时管理时序数据和关系数据,并用一条 SQL 把两者联合查询出来。
服务器的基本信息如下:
- 系统:CentOS Linux 7.6.1810 (Core)
- 内核:3.10.0-957.el7.x86_64(满足 KWDB 对内核版本 ≥ 3.10 的要求)
- CPU:4 核
- 磁盘:40G,使用了 13G,剩余 28G,挂载在
/dev/vda1
服务器上已经装好了 Docker,所以跳过 Docker 安装流程,直接从拉取镜像开始。
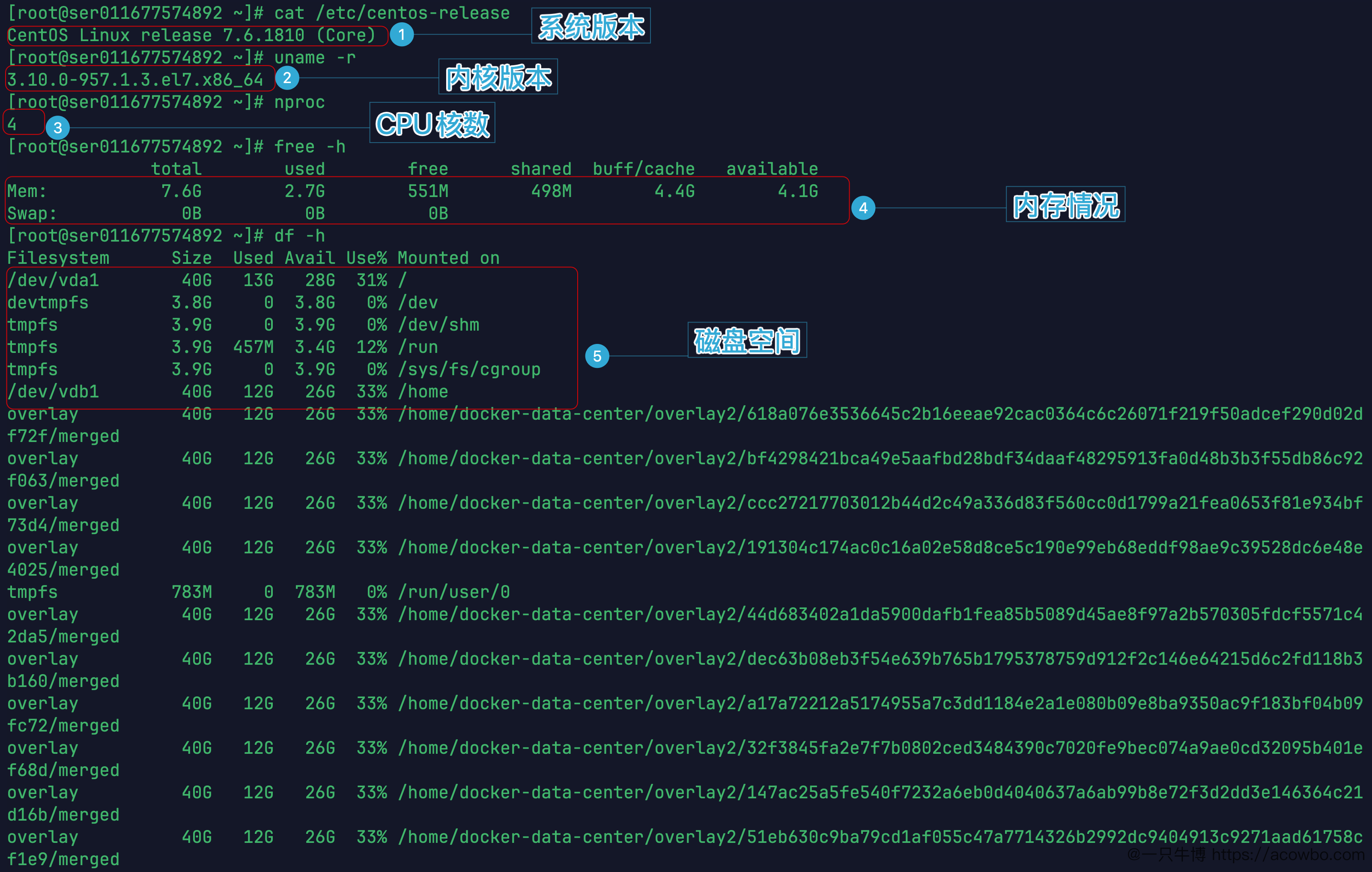
服务器环境信息截图
拉取镜像
KWDB 在阿里云容器镜像仓库有官方镜像,国内访问速度比 DockerHub 快很多:
docker pull registry.cn-hangzhou.aliyuncs.com/kwdb/kwdb:3.1.0镜像分三层下载,总大小 401MB,拉取过程正常。
docker images | grep kwdb可以看到镜像 ID 为 u309746d65e,是 3 周前构建的 3.1.0 版本,确认拉取成功。
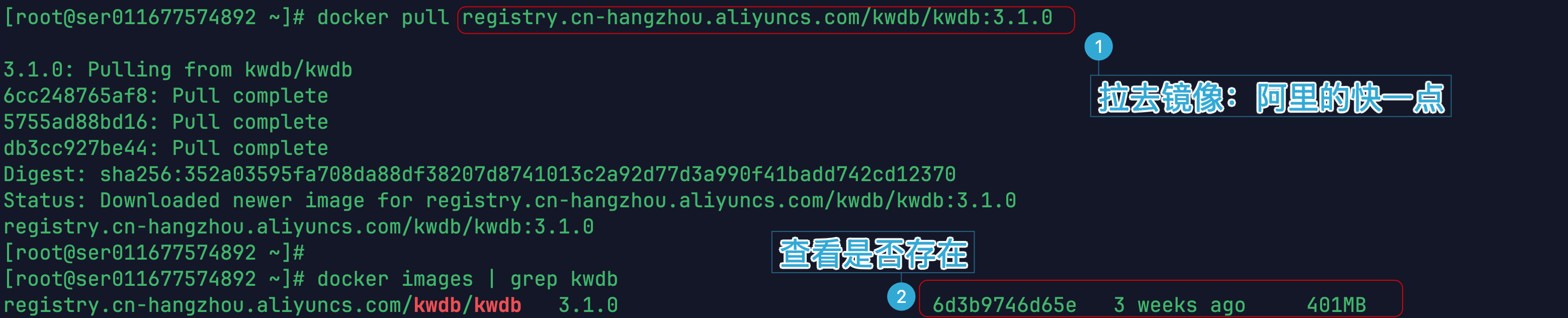
拉取镜像成功截图
启动容器:踩坑一
按照对 CockroachDB(KWDB 的亲戚)的使用印象,我在 docker run 后面加了 start-single-node --insecure 参数,期望它像 CockroachDB 那样工作,结果立刻报错:
exec: "start-single-node": executable file not found in $PATH: unknown改成 kwbase start-single-node --insecure 依然报同样的错——kwbase 也找不到。
这里的原因是:KWDB 3.1.0 镜像内置了启动脚本作为 ENTRYPOINT,容器启动时会自动执行数据库初始化和服务启动流程,不需要也不应该在 docker run 后面再传命令。正确的启动方式是直接运行容器:
docker run -d \
--name kwdb \
-p 26257:26257 \
-p 18080:8080 \
-v /acowbo/docker-compose-project/kwdb/data:/kwdb/data \
registry.cn-hangzhou.aliyuncs.com/kwdb/kwdb:3.1.0去掉额外命令后,容器正常启动。docker ps | grep kwdb 输出显示容器 ID 96e35949c980,状态 Up 29 seconds,26257 和 18080 端口均已正常映射。
docker logs kwdb日志里出现以下关键信息,说明节点启动完成:
KWDB node starting at 2026-02-27 03:51:46.66022888 +0000 UTC (took 3.1s)
build: 3.1.0 @ 2026/02/02 10:31:37
sql: postgresql://root@0.0.0.0:26257?sslmode=disable
store[0]: path=/kwdb/data
storage engine: rocksdb
ts storage engine: kwtsdb
status: initialized new cluster
clusterID: be9323c1-0bc3-44c6-87b1-2628d4d627b8
nodeID: 1有几个细节值得关注:日志显示了两个存储引擎,rocksdb 负责关系数据,kwtsdb 是 KWDB 自研的时序存储引擎,这也是它能同时高效处理两种数据模型的底层基础。另外日志里有 WARNING: RUNNING IN INSECURE MODE! 的提示,这是预期行为,测试环境使用 insecure 模式不需要配置 TLS 证书。
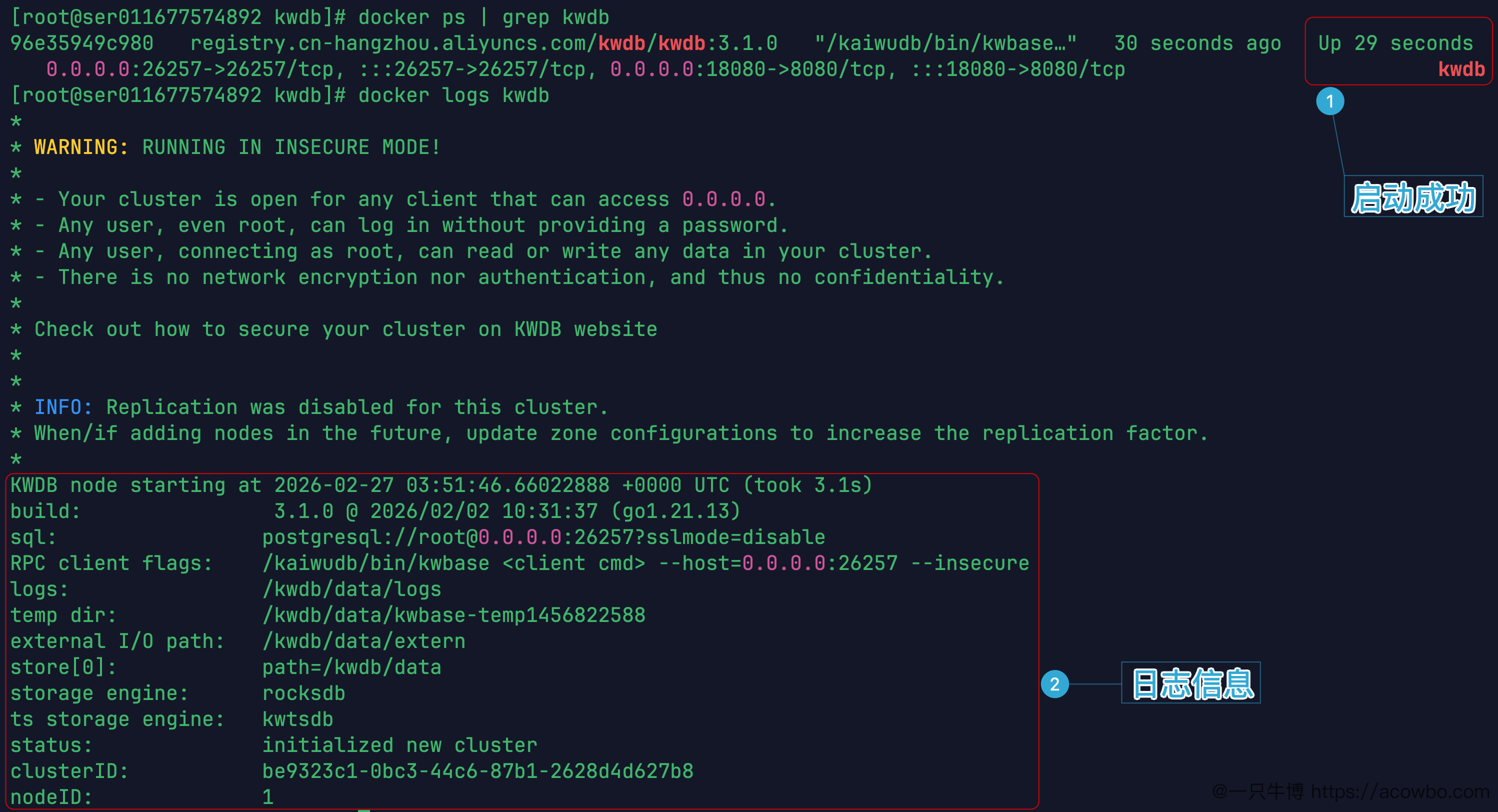
容器启动成功与日志截图
连接数据库
进入容器内部:
docker exec -it kwdb /bin/bash进去后想直接用 ./kwbase sql 连接,报找不到文件。用 find 搜一下路径:
find / -name "kwbase" 2>/dev/null找到了,真实路径是 /kaiwudb/bin/kwbase,不在当前目录也不在 $PATH 里。用完整路径连接:
./kaiwudb/bin/kwbase sql --insecure --host=localhost:26257连接成功后看到欢迎信息:
Welcome to the KWDB SQL shell.
Server version: KaiwuDB 3.1.0 (x86_64-linux-gnu, built 2026/02/02 10:31:37, go1.21.13, gcc 11.4.0)
Cluster ID: be9323c1-0bc3-44c6-87b1-2628d4d627b8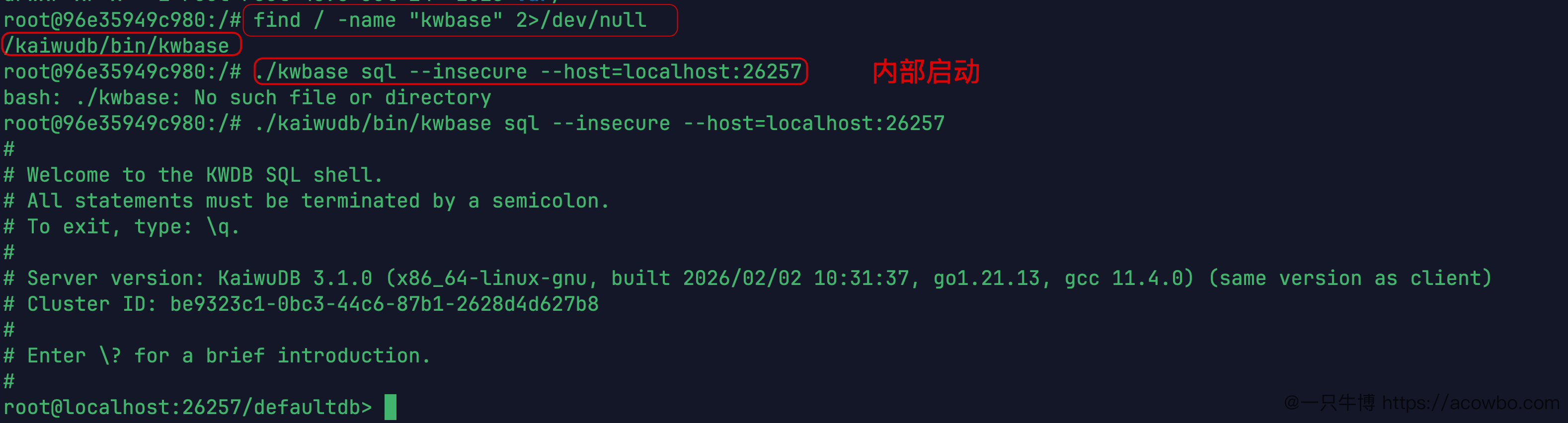
进入容器并连接SQL截图
用 SELECT version(); 确认版本,返回 KaiwuDB 3.1.0 (x86_64-linux-gnu, built 2026/02/02 10:31:37, go1.21.13, gcc 11.4.0),查询耗时 1.135ms。
建库建表:踩坑二和踩坑三
踩坑二:时序表不能建在关系库里
在 factory_monitor 关系数据库里建时序表,马上报错:
ERROR: can not create timeseries table in relational database "factory_monitor"
SQLSTATE: 42809KWDB 对数据库类型有严格区分:CREATE DATABASE 建的是关系型数据库,只能存放普通表;时序表必须建在用 CREATE TS DATABASE 创建的时序数据库里。两者完全隔离,不能混建。
所以正确的做法是建两个数据库分别用于不同类型的数据:
CREATE TS DATABASE ts_factory; -- 时序数据库,存传感器数据
CREATE DATABASE rel_factory; -- 关系数据库,存设备台账踩坑三:TAG 列在 TAGS 里定义,不能在普通列重复
切换到 ts_factory 后建时序表,又踩了一个坑:
ERROR: duplicate column name: "device_id"原因是我在主列里写了 device_id INT NOT NULL,又在 TAGS (device_id INT NOT NULL) 里写了第二遍,系统认为列名重复了。
KWDB 时序表里的 TAG 列是一种特殊的元数据列,用来标识每条时序数据属于哪个设备(类似 InfluxDB 的 tag 概念),它在 TAGS (...) 中单独定义,不能出现在普通列区域。正确的建表语句:
USE ts_factory;
CREATE TABLE sensor_data (
k_timestamp TIMESTAMPTZ NOT NULL, -- 时间戳
temperature FLOAT, -- 温度(指标列)
pressure FLOAT, -- 压力(指标列)
vibration FLOAT -- 振动(指标列)
) TAGS (device_id INT NOT NULL) PRIMARY TAGS(device_id)
ACTIVETIME 1 DAY;device_id 只出现在 TAGS 里,主列只保留随时间变化的指标数据。ACTIVETIME 1 DAY 是时序表的数据有效时间窗口设置。
关系表正常建在 rel_factory 里:
USE rel_factory;
CREATE TABLE device_info (
device_id INT PRIMARY KEY,
device_name VARCHAR(50),
location VARCHAR(100),
device_type VARCHAR(30),
install_date DATE
);SHOW TABLES 确认,ts_factory 下的 sensor_data 类型是 TIME SERIES TABLE,rel_factory 下的 device_info 类型是 BASE TABLE,两种表类型区分得很明确。
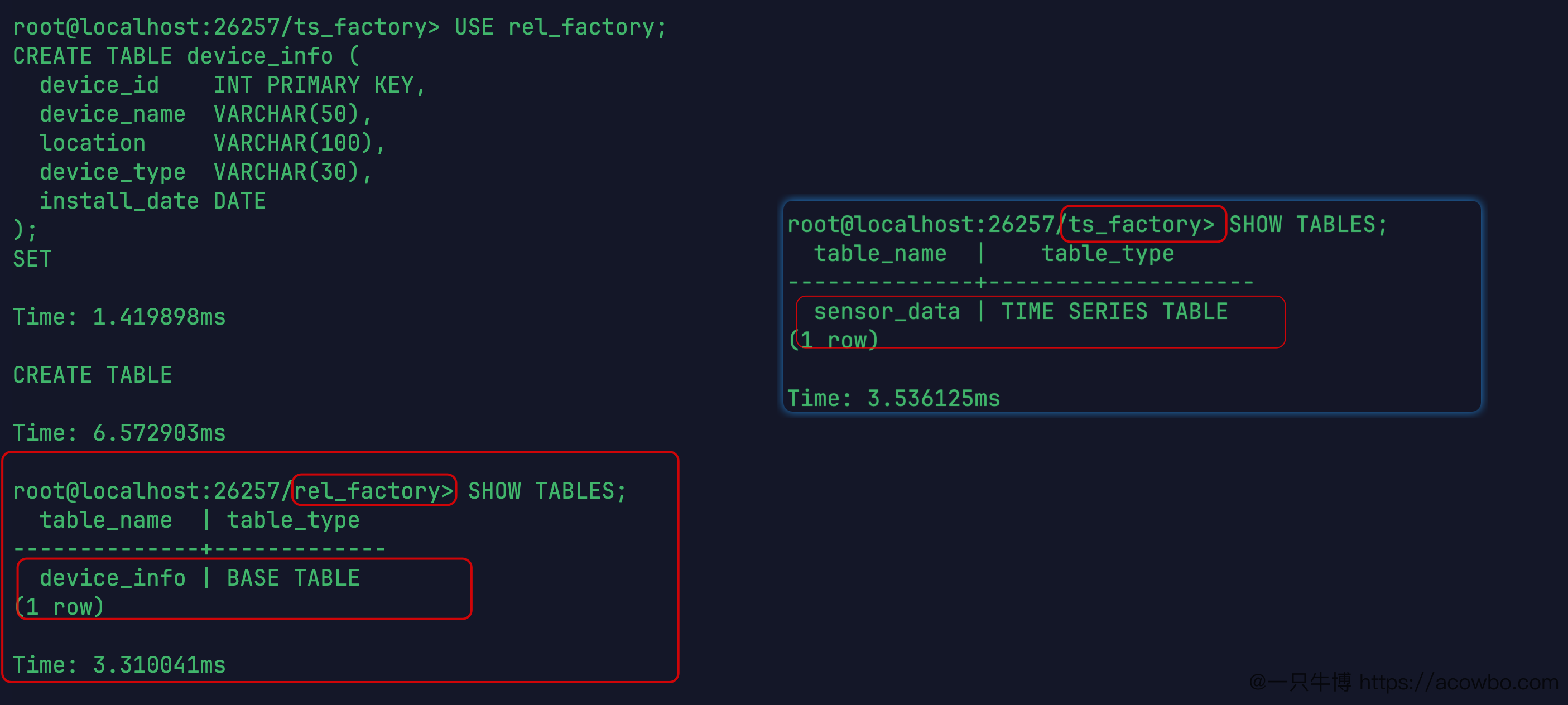
两种数据库建表成功截图
插入测试数据
关系表写入三条设备台账:
USE rel_factory;
INSERT INTO device_info VALUES
(1, '1号电机', '车间A-001', '电机', '2023-01-15'),
(2, '2号电机', '车间A-002', '电机', '2023-03-20'),
(3, '压力泵01', '车间B-001', '泵', '2023-06-10');3 条记录写入耗时 2.2ms。
时序表写入 7 条传感器数据,覆盖三台设备在 2026-02-27 08:00~08:20 的采集记录,其中 1 号电机的温度在 08:20 达到了 86.9℃:
USE ts_factory;
INSERT INTO sensor_data(k_timestamp, device_id, temperature, pressure, vibration) VALUES
('2026-02-27 08:00:00+08', 1, 72.5, 101.3, 0.12),
('2026-02-27 08:10:00+08', 1, 75.8, 102.1, 0.15),
('2026-02-27 08:20:00+08', 1, 86.9, 103.5, 0.31),
('2026-02-27 08:00:00+08', 2, 68.2, 100.8, 0.09),
('2026-02-27 08:10:00+08', 2, 69.5, 101.2, 0.11),
('2026-02-27 08:00:00+08', 3, 55.3, 205.6, 0.22),
('2026-02-27 08:10:00+08', 3, 56.1, 206.0, 0.24);INSERT 7 条,耗时 3.29ms。
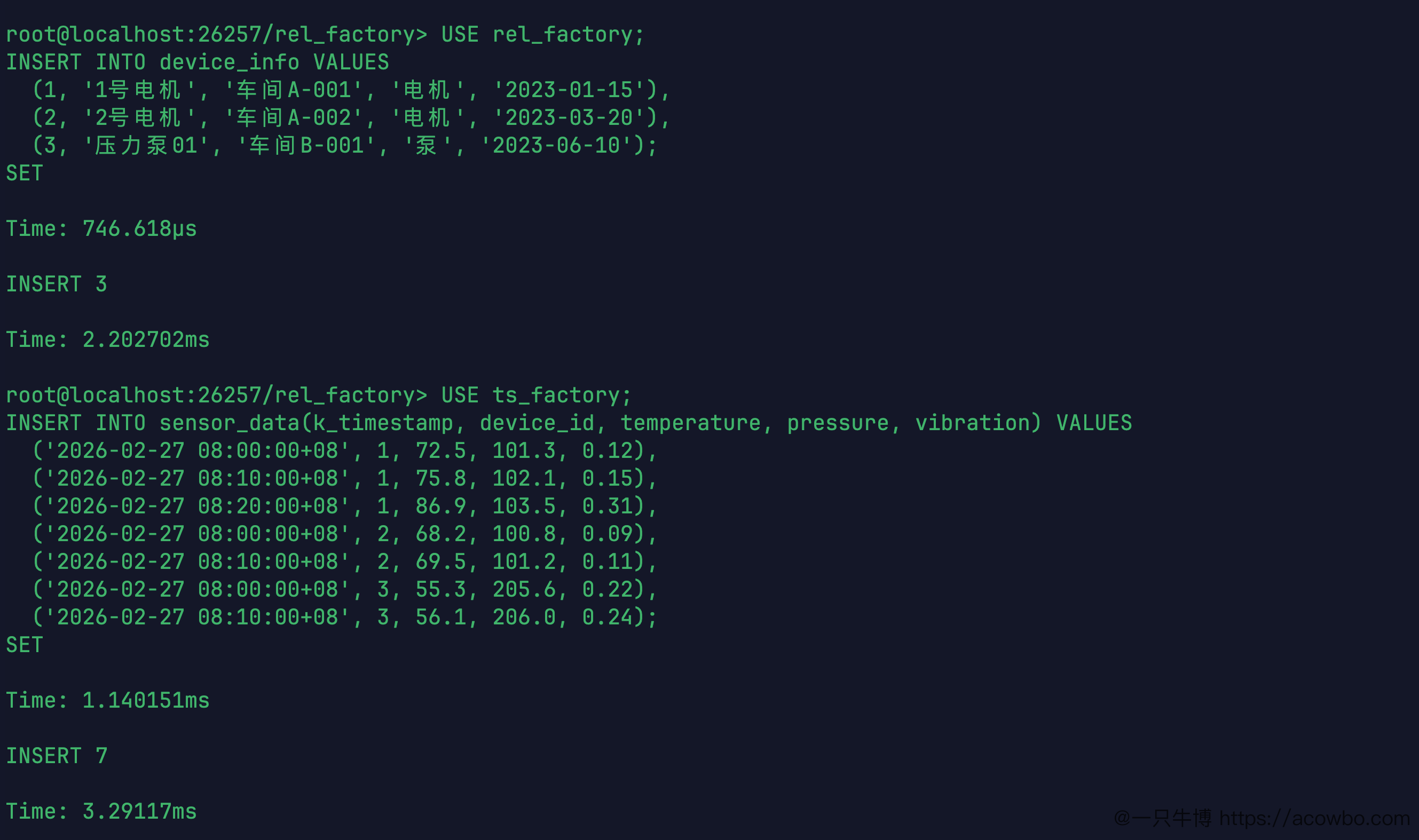
插入测试数据截图
跨模查询实测
数据准备完毕,正式测试 KWDB 的核心能力。跨模查询的语法和普通 SQL 的 JOIN 完全一致,区别只是表名需要带上数据库名前缀:
SELECT
d.device_name,
d.location,
s.temperature,
s.pressure,
s.k_timestamp
FROM ts_factory.sensor_data s
JOIN rel_factory.device_info d ON s.device_id = d.device_id
WHERE s.k_timestamp > '2026-02-27 07:59:00+08'
ORDER BY s.k_timestamp DESC;查询结果:
device_name | location | temperature | pressure | k_timestamp
-------------+-----------+-------------+----------+--------------------------
1号电机 | 车间A-001 | 86.9 | 103.5 | 2026-02-27 00:20:00+00:00
2号电机 | 车间A-002 | 69.5 | 101.2 | 2026-02-27 00:10:00+00:00
压力泵01 | 车间B-001 | 56.1 | 206 | 2026-02-27 00:10:00+00:00
1号电机 | 车间A-001 | 75.8 | 102.1 | 2026-02-27 00:10:00+00:00
1号电机 | 车间A-001 | 72.5 | 101.3 | 2026-02-27 00:00:00+00:00
2号电机 | 车间A-002 | 68.2 | 100.8 | 2026-02-27 00:00:00+00:00
压力泵01 | 车间B-001 | 55.3 | 205.6 | 2026-02-27 00:00:00+00:00
(7 rows)
Time: 6.70042ms7 条数据,跨两个不同类型的数据库联合查询,耗时 6.7ms。时间戳列显示的是 UTC 时间,比北京时间少 8 小时,08:20 存储后显示为 00:20,这是 TIMESTAMPTZ 类型的正常行为,查询时按本地时区的字符串过滤即可。
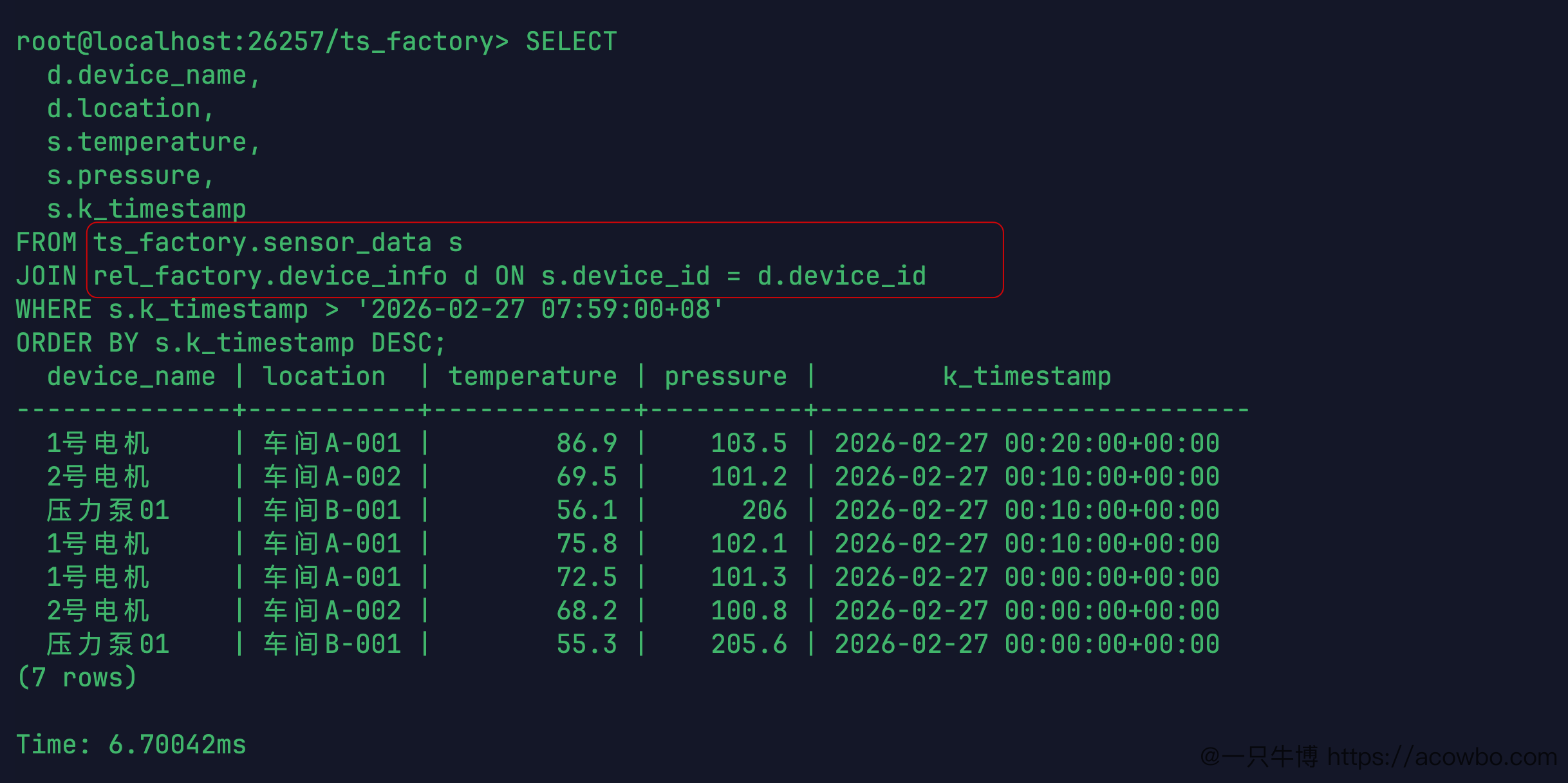
跨模查询结果截图
再跑一个聚合版本,统计每台设备在这段时间内的平均温度、峰值温度和数据点数:
SELECT
d.device_name,
d.device_type,
AVG(s.temperature) AS avg_temp,
MAX(s.temperature) AS max_temp,
COUNT(*) AS data_points
FROM ts_factory.sensor_data s
JOIN rel_factory.device_info d ON s.device_id = d.device_id
GROUP BY d.device_name, d.device_type
ORDER BY avg_temp DESC;结果:
device_name | device_type | avg_temp | max_temp | data_points
-------------+-------------+----------+----------+-------------
1号电机 | 电机 | 78.4 | 86.9 | 3
2号电机 | 电机 | 68.85 | 69.5 | 2
压力泵01 | 泵 | 55.7 | 56.1 | 2
(3 rows)
Time: 7.858095ms1 号电机均温 78.4℃,峰值 86.9℃,已经接近需要关注的范围。聚合跨模查询耗时 7.86ms,GROUP BY 的开销也控制在可接受范围内。
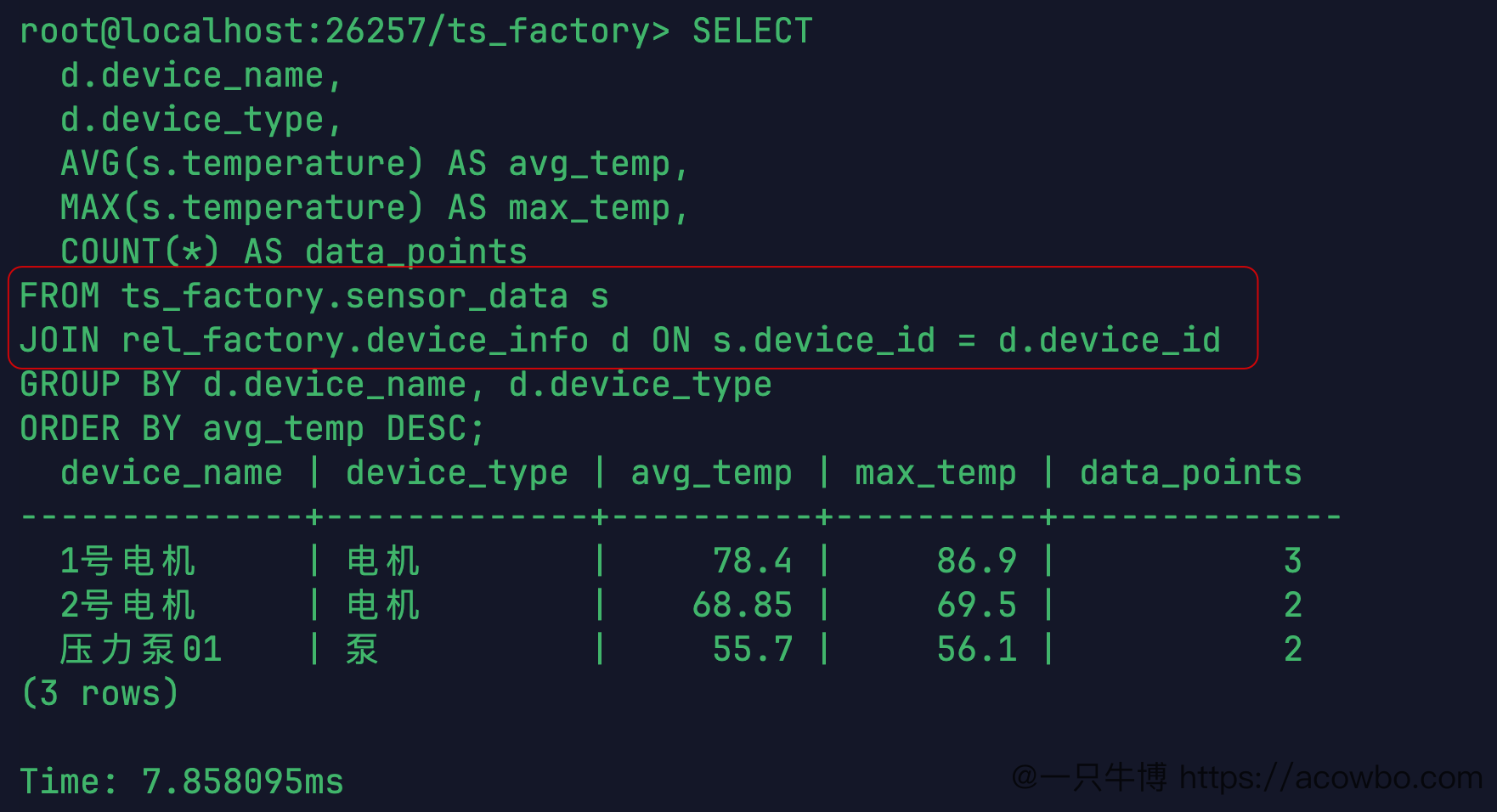
聚合跨模查询结果截图
总结
整个部署过程大约花了一个小时,真正对着文档按步骤走的时间并不多,大半时间都消耗在排查那三个坑上。Docker 启动命令不需要额外参数,这个坑主要是从 CockroachDB 带来的先入为主的印象;时序库与关系库必须分开建,这是 KWDB 多模架构的设计约束,用过 InfluxDB 的人可能会觉得直觉上不太一样;而 TAG 列的定义规则,则是在建表语法上需要特别注意的细节。把这三个坑绕开之后,后续的操作就很顺滑,跨模查询的语法和平时写 MySQL 的 JOIN 没有本质差异,学习成本低。从性能上看,7ms 以内完成跨两个异构数据库的联合聚合查询,在单节点 4 核的服务器上表现出色,对于需要同时管理设备台账和传感器数据的 IoT 场景来说,这个方案在工程实践中具有实际价值。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号