大模型应用:基于混元大模型 + 图算法:可追溯知识图谱问答系统构建.83
原创
大模型应用:基于混元大模型 + 图算法:可追溯知识图谱问答系统构建.83
原创
未闻花名
发布于 2026-04-21 07:56:08
发布于 2026-04-21 07:56:08
一、前言
在大模型深度融入产业应用的当下,自然语言交互的流畅性已实现突破,但事实性幻觉、复杂关系推理薄弱、答案不可追溯三大核心问题,始终制约着大模型在知识服务、智能问答、专业咨询等高可信场景的落地。单纯依赖大模型的语义生成能力,难以处理多跳关联、实体关系推导、结构化知识校验等复杂任务,而传统知识图谱又存在交互门槛高、自然语言适配差的短板。
将图算法与大模型深度融合,正是破解这一困境的最优路径之一:图算法专注于实体关系抽取、路径推理、重要度排序与社区挖掘,构建结构化、可解释的知识图谱;大模型则承担自然语言理解、意图解析与答案生成,实现人机无障碍交互。今天我们依旧采用混元大模型API作为语言引擎,依托其强大的语义理解与指令遵循能力,将用户自然语言问题精准转化为图查询指令,再通过 PageRank、最短路径、社区发现等经典图算法完成知识推理与验证,最终由混元模型生成可信、流畅、可溯源的回答。这套“图算法管关系、大模型管语言”的双引擎架构,既消除了大模型幻觉,又强化了逻辑推理能力,为医疗、文旅、学术、企业知识服务等场景提供了可落地、高可靠的智能问答解决方案,也为大模型的可信化应用提供了清晰的实践思路。

二、核心概念
1. 核心定义
1.1 图算法
图算法不是画图的工具,而是专门用来分析“关系网络”的数学方法。
- 它能快速找出两个节点之间的最短路径,比如“我们和某位名人之间隔了几层朋友”。
- 它能发现高度连接的子群体,比如社交网络中的兴趣圈子、金融交易中的异常团伙。
- 它还能评估节点的重要性,就像各大搜索引擎中的PageRank给网页打分,图算法也能判断“哪个实体在知识网络中最关键”。
图算法的核心优势在于:精准、可解释、擅长结构化推理。
1.2 知识图谱
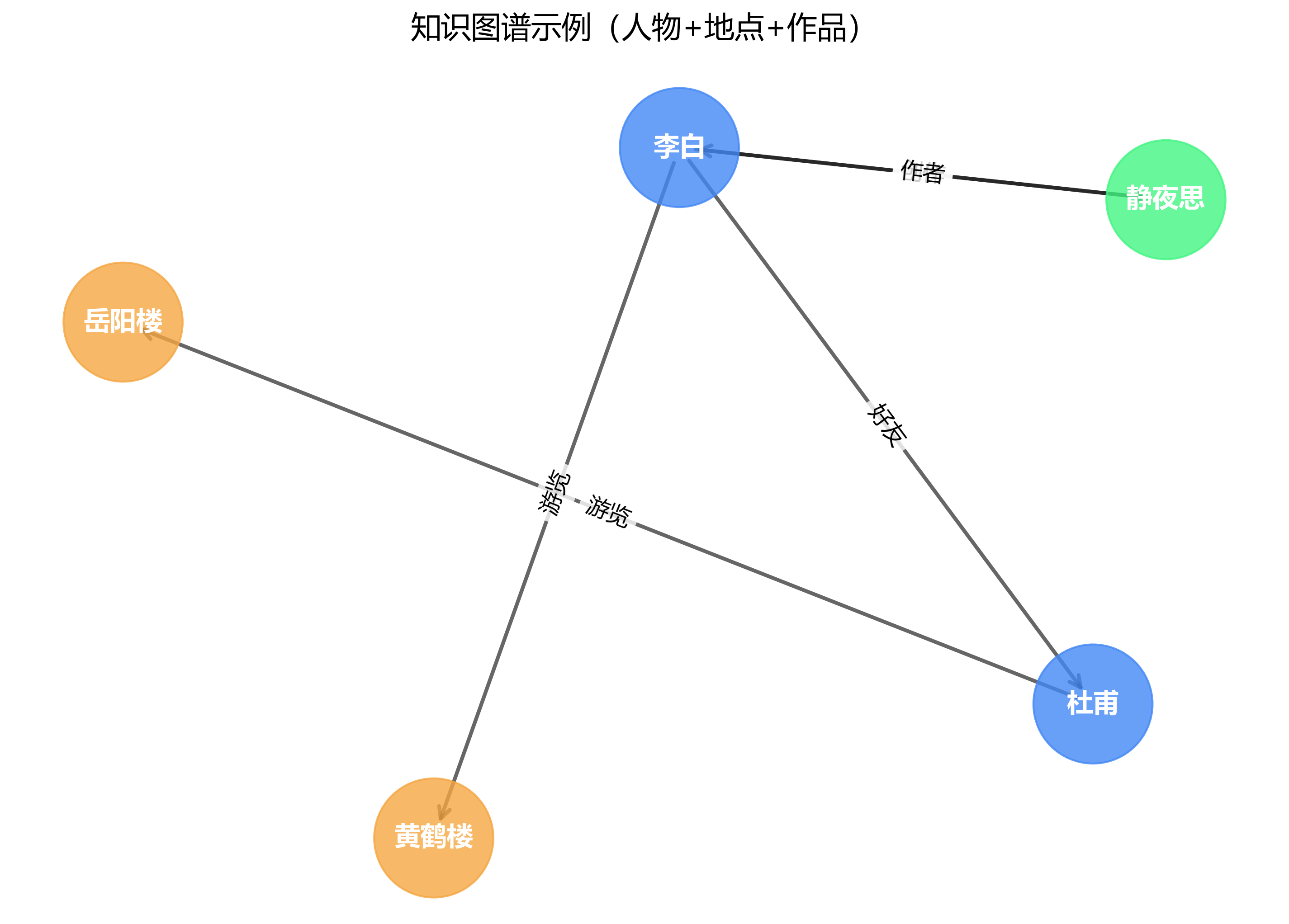
知识图谱是一种用“图”来组织事实的方式,用“节点(实体)+ 边(关系)”的图形结构存储知识:
- 每个节点代表一个真实世界的实体,如“李白”、“静夜思”、“唐朝”;
- 每条边代表两个实体之间的明确关系,如“李白 → 创作 → 静夜思”。
它不像普通数据库那样只存表格,而是把知识变成一张巨大的语义网络。因此,知识图谱本质上是一个结构化、可计算的关系知识库,为机器提供常识骨架。
1.3 大模型的强项与短板
大模型擅长理解和生成人类语言,在自然语言处理上表现出色:
- 能理解复杂问句,比如“谁写的那首讲月光的唐诗?”
- 能生成流畅、符合语境的回答,甚至带点文采。
但它的致命弱点也很明显,容易胡说八道,缺乏对复杂关系的推理能力:
- 容易幻觉:可能一本正经地编造不存在的事实;
- 缺乏推理锚点:面对“李白和杜甫有没有共同好友?”这类问题,它只能靠概率猜测,无法真正查证。
换句话说,大模型像一个博学但记性不牢的演讲者,说得漂亮,但不一定靠谱。
1.4 知识图谱智能问答
单独使用任何一方都难以支撑高可靠性的智能问答:
- 只用图算法?听不懂人话,无法处理模糊或口语化提问。
- 只用大模型?答案可能漂亮却错误,且无法说明“为什么这么答”。
- 只有知识图谱?它只是静态数据,不会主动理解或表达。
而将三者结合,就能形成一个闭环协作系统:
- 1. 用户提问 → 大模型先理解意图,把自然语言转化为结构化查询,比如识别出“李白”“静夜思”是关键实体;
- 2. 图算法介入 → 在知识图谱中执行关系推理:找路径、算相关性、验证逻辑链;
- 3. 大模型再生成 → 基于图算法返回的真实证据链,组织成人类可读的回答;
- 4. 全程可追溯 → 每个结论都能回溯到图谱中的具体三元组,实现“有据可查”。
用图算法处理“关系推理”,用大模型处理“语言理解和生成”,结合后既能听懂人话,又能精准推理,还能追溯答案来源。
2. 核心价值
纯大模型问答 | 图算法 + 大模型问答 |
|---|---|
答案可能幻觉,无法追溯 | 答案基于结构化关系,可追溯、无幻觉 |
缺乏复杂关系推理能力 | 擅长多步关系推理,如 “李白和杜甫的共同好友是谁” |
依赖海量语料,解释性差 | 基于明确的实体关系,解释性强 |
三、基础知识
1. 图的基础概念
- 节点(Entity):知识的“主角”,比如人、地点、物品,例:李白、北京、手机。
- 边(Relationship):节点之间的 “关系”,比如“李白 - 出生地 - 碎叶城”、“北京 - 包含 - 朝阳区”。
- 属性(Attribute):节点、边的补充信息,比如李白的“出生日期:701 年”、边“创作” 的 “时间:726 年”。
2. 核心图算法
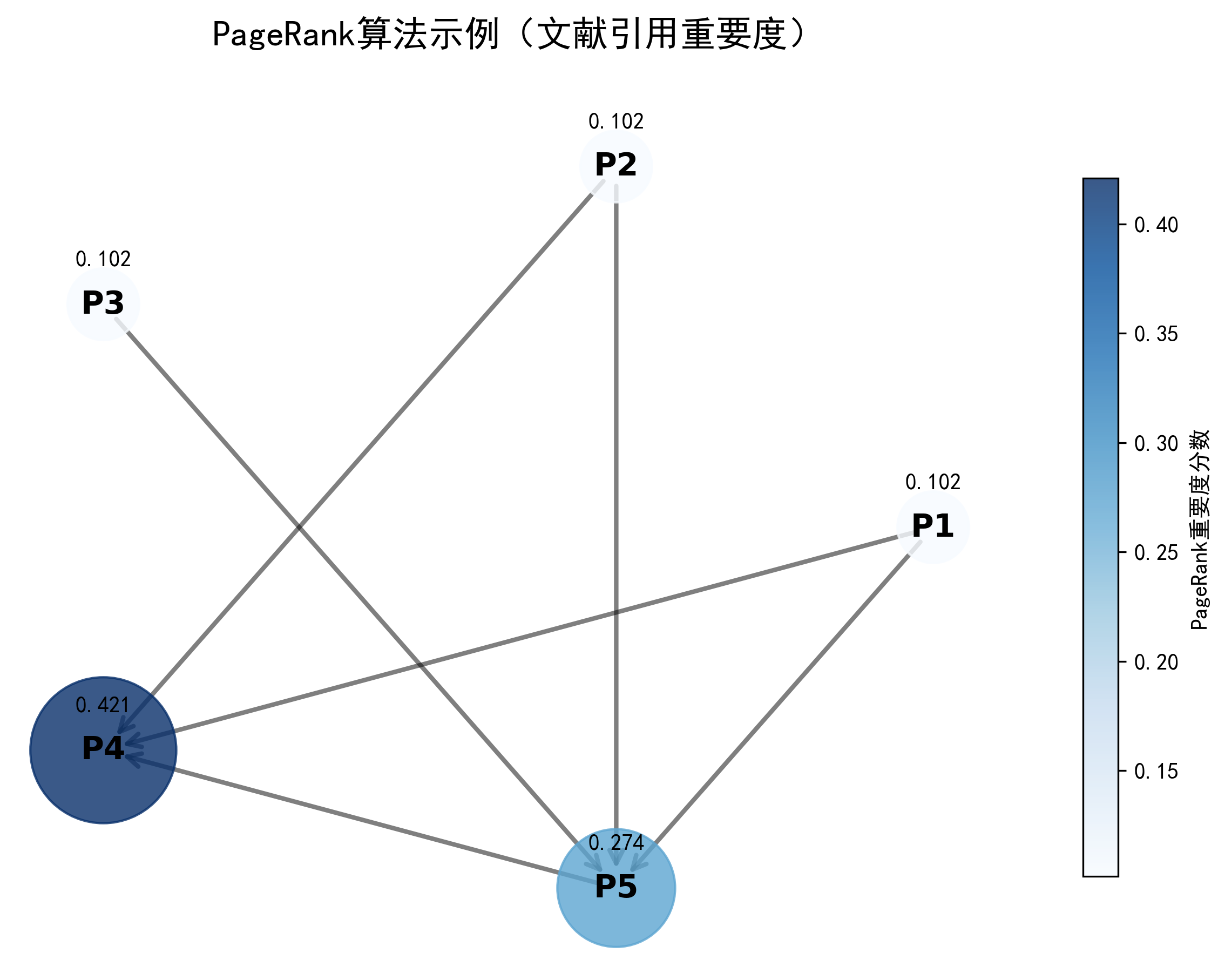
2.1 PageRank:给“谁更重要”打分
PageRank的核心思想是:被越多重要节点指向的节点,自己也越重要。
- 就像一篇论文被很多高影响力论文引用,它自然也很关键;
- 在知识图谱里,它可以帮我们快速找出“核心人物”或“关键概念”,比如识别出李白比其他不知名诗人更中心。
- 早期的搜索引擎就靠它给网页排序,今天它仍是衡量网络中节点影响力的经典方法。
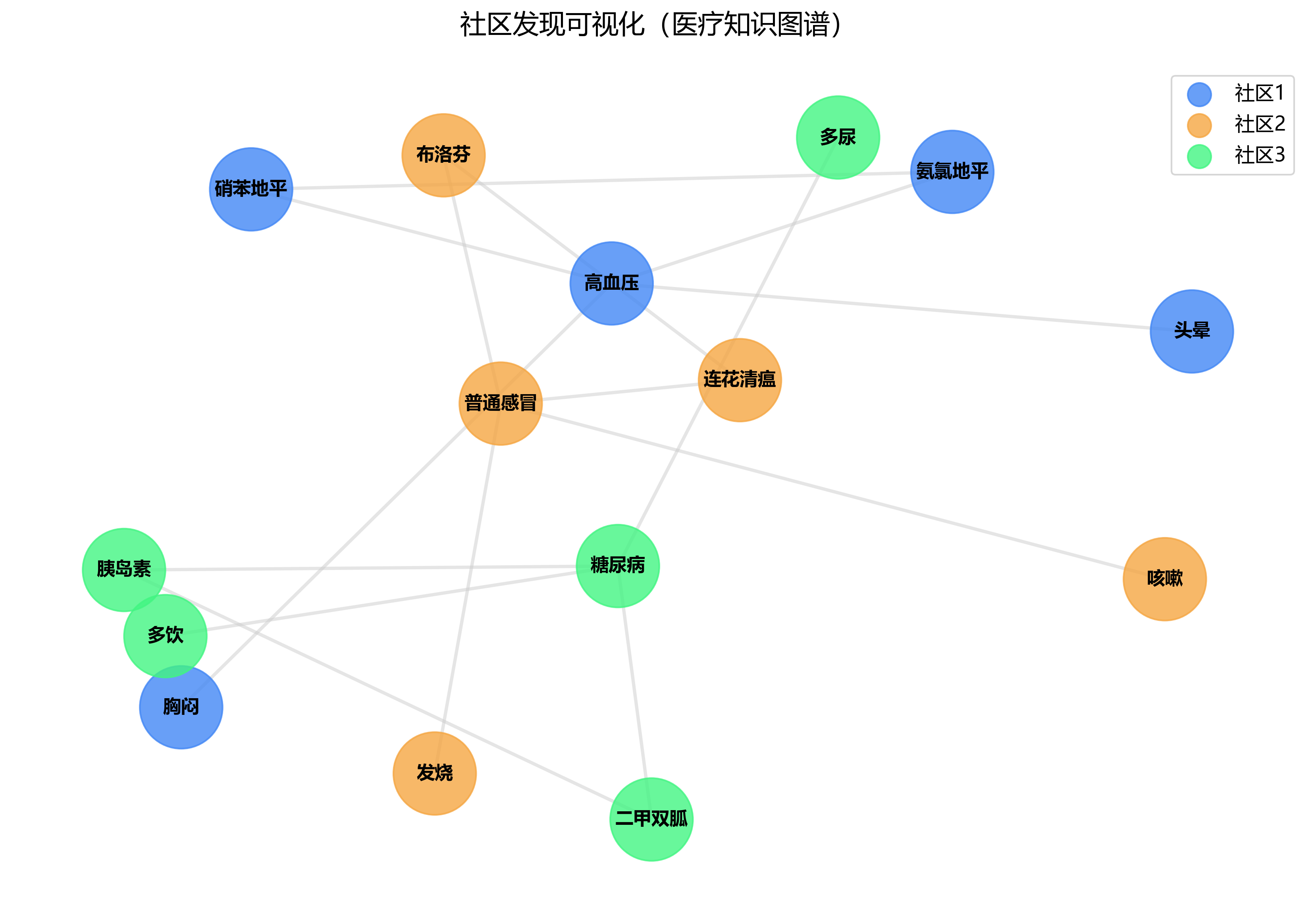
2.2 社区发现:自动找出“小圈子”
现实世界的关系网里,人总是扎堆的,同学群、家庭群、兴趣小组……社区发现算法就是干这个的:从复杂网络中自动划分出内部连接紧密、外部连接稀疏的子群体。
- 在医疗知识图谱中,它能把“高血压、糖尿病、肥胖”等高度关联的疾病聚成一类,辅助医生判断共病风险;
- 在社交网络中,可用于识别潜在的不良操作团伙或营销社群。
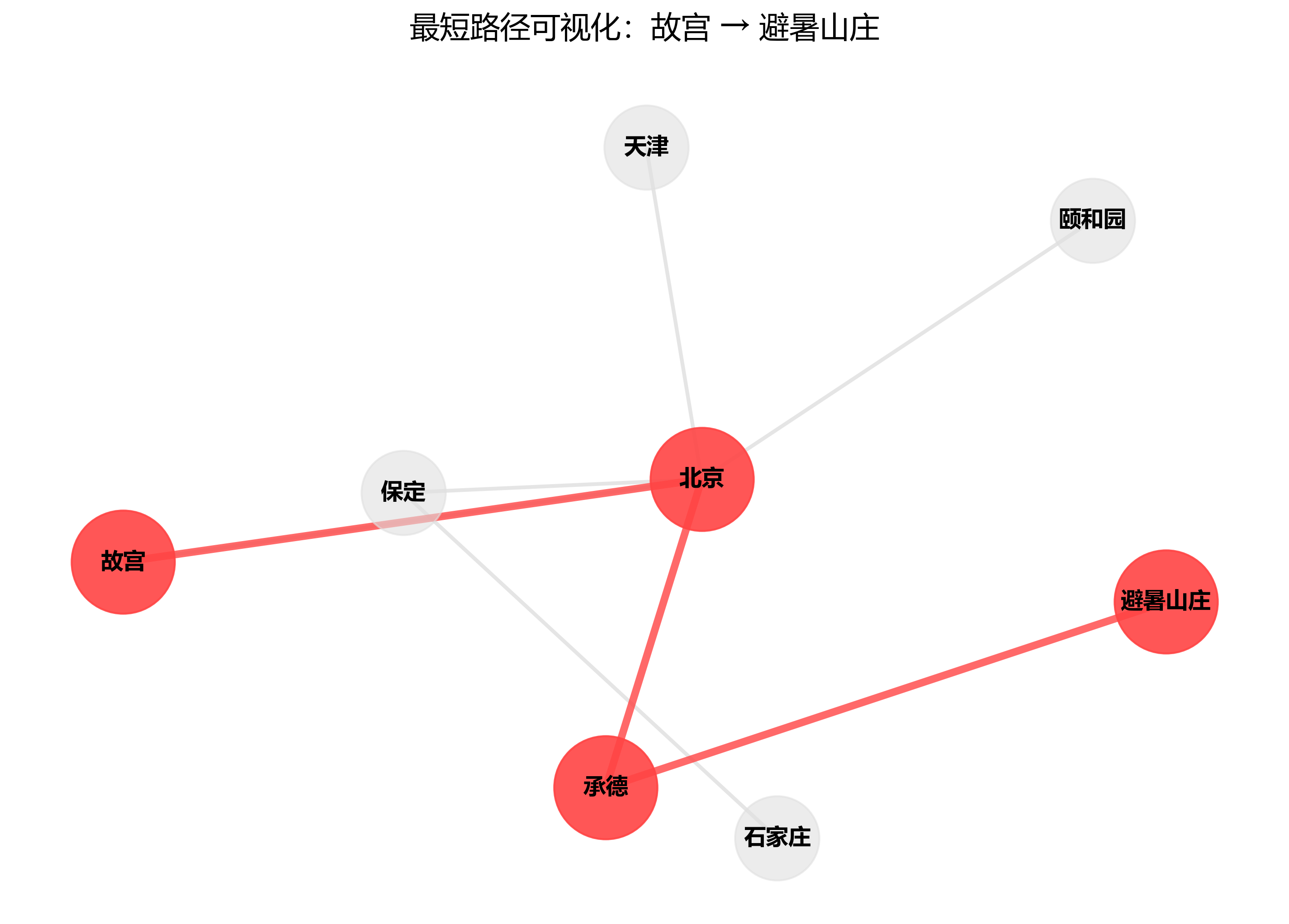
2.3 最短路径:找“最少中间人”的连接
如果我们想知道“我和某位名人之间隔了几层关系”?最短路径算法就能回答这个问题。
- 它计算两个节点之间边数最少(或权重最小)的路径;
- 除了社交距离,还能用于智能导航(景点间最快路线)、供应链溯源(从原料到成品经过哪些环节)等场景;
- 在知识图谱问答中,它能揭示“李白 → 师从 → 赵蕤 → 与 → 司马承祯 → 是 → 王维的朋友”这样的隐性关联链。
2.4 实体链接:识别“知识库里的真实对象”
用户问:“诗仙写过哪些诗?”,机器得先知道“诗仙”指的是知识图谱里的‘李白’这个节点,而不是字面意思或其他诗人。
- 实体链接就是做这件事:将文本中的模糊称呼(别名、昵称、简称)精准映射到知识库中唯一的标准实体;
- 它是智能问答的第一步,确保后续的图推理找对了人,避免张冠李戴。
3. 图算法的核心原理
- PageRank:核心是“投票”,一个节点的重要度 = 所有指向它的节点的重要度之和,比如“杜甫”指向“李白”,说明李白更重要。
- 最短路径:核心是“贪心算法”,从起点出发,每次走最近的节点,直到到达终点,比如找“李白→贺知章→唐玄宗”的最短路径。
- 社区发现:核心是“模块化”,把内部关系紧密、外部关系稀疏的节点分成一组,比如“山水诗人”社区。
4. 大模型在其中的角色
- 输入侧:把用户的自然语言问题(如“李白的出生地在哪里?”)转换成图算法能理解的查询指令,如“查找节点‘李白’的‘出生地’边指向的节点”。
- 输出侧:把图算法的结果(如 “碎叶城”)转换成自然、流畅的人类语言回答,如“李白的出生地是碎叶城,位于今天的吉尔吉斯斯坦托克马克市”。
- 补充侧:处理图算法覆盖不到的“非结构化知识”,如李白的诗歌风格,但答案基于知识图谱,避免幻觉。
5. 大模型与图算法结合原理
- 解耦:把“语言理解”和“关系推理”分开,让专业的工具做专业的事。
- 互补:大模型弥补图算法的语言短板,图算法弥补大模型的推理短板。
- 可验证:图算法的结果是结构化的,可直接验证,避免大模型的幻觉。
四、执行流程

流程说明:
- 1. 数据准备
- 数据源:结构化数据(Excel / 数据库)、半结构化数据(JSON/XML)、非结构化数据(文本 / 文档)。
- 示例数据:人物关系表(姓名、关系、关联人、属性)、景点信息表(景点名、所属城市、评分)。
- 2. 图算法抽取关系
- 用PageRank筛选核心实体,比如从1000个诗人中找出核心的100个。
- 用实体链接把文本中的“别名”匹配到标准节点,如“诗仙”→“李白。
- 用社区发现把关联实体分组,如“唐诗诗人”、“宋词词人”两个社区。
- 3. 构建知识图谱
- 选择工具:零基础推荐可视化强的Neo4j、基于Python代码易写的NetworkX。
- 存储结构:节点(实体 ID、名称、属性)+ 边(关系 ID、起始节点、终止节点、关系类型、属性)。
- 4. 大模型处理用户问题
- 提示词设计:让大模型把自然语言转成 “图查询语句”。
- 示例提示词:
你是一个知识图谱查询转换助手,需要把用户的自然语言问题转换成针对NetworkX图的查询指令。 知识图谱包含的节点类型:Person(人物:李白、杜甫、贺知章)、Place(地点:碎叶城、长安)。 关系类型:friend(朋友)、birthPlace(出生地)、livedIn(居住过)。 请返回简洁的Python查询指令,仅返回代码片段,不要多余解释。 示例: 用户问题:李白的出生地在哪里? 输出:list(kg[李白][x] for x in kg.neighbors('李白') if kg[李白][x]['relation'] == 'birthPlace') 用户问题:{question}
- 5. 图算法执行推理查询
- 执行最短路径查询,如“李白和杜甫的最短关系链”。
- 执行社区发现查询,如“李白所属的诗人社区有哪些人”。
- 执行PageRank查询,如“唐诗社区中最重要的3个诗人”。
- 6. 大模型生成回答 + 追溯来源
- 把图算法的结果(如“碎叶城”)传给大模型,让其生成自然语言回答。
- 附加“答案来源”,如“来自知识图谱中‘李白’与‘碎叶城’的‘出生地’关系”。
五、示例展示
1. 用 NetworkX 构建简单知识图谱
import networkx as nx
import matplotlib.pyplot as plt
from matplotlib import font_manager
# 设置中文字体(解决中文显示乱码问题)
font_family = ["Microsoft YaHei", "SimHei", "WenQuanYi Micro Hei", "Heiti TC", "Arial Unicode MS"]
plt.rcParams["font.family"] = font_family
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# 查找并设置可用字体
available_fonts = [f.name for f in font_manager.fontManager.ttflist]
node_font = None
for font in font_family:
if font in available_fonts:
node_font = font
break
if node_font is None:
node_font = "DejaVu Sans" # 默认字体
print("警告: 未找到中文字体,可能显示乱码")
# 1. 创建空的无向图
kg = nx.Graph()
# 2. 添加节点(实体):人物节点,带属性
kg.add_node("李白", type="Person", birth_year=701)
kg.add_node("杜甫", type="Person", birth_year=712)
kg.add_node("贺知章", type="Person", birth_year=659)
kg.add_node("碎叶城", type="Place", location="吉尔吉斯斯坦")
kg.add_node("长安", type="Place", location="中国西安")
# 3. 添加边(关系):带关系类型属性
kg.add_edge("李白", "贺知章", relation="friend")
kg.add_edge("李白", "杜甫", relation="friend")
kg.add_edge("李白", "碎叶城", relation="birthPlace")
kg.add_edge("李白", "长安", relation="livedIn")
kg.add_edge("杜甫", "长安", relation="livedIn")
# 4. 可视化知识图谱(生成图片)
plt.figure(figsize=(10, 6))
# 设置节点位置
pos = nx.spring_layout(kg, seed=42) # seed固定布局
# 绘制节点
nx.draw_networkx_nodes(kg, pos, node_size=3000, node_color="lightblue")
# 绘制边
nx.draw_networkx_edges(kg, pos, width=2, edge_color="gray")
# 绘制节点标签
nx.draw_networkx_labels(kg, pos, font_size=12, font_weight="bold", font_family=node_font)
# 绘制边的关系标签
edge_labels = nx.get_edge_attributes(kg, "relation")
nx.draw_networkx_edge_labels(kg, pos, edge_labels=edge_labels, font_size=10, font_family=node_font)
# 隐藏坐标轴
plt.axis("off")
# 保存图片
plt.savefig("83.用NetworkX构建简单知识图谱 knowledge_graph.png", dpi=300, bbox_inches="tight")
plt.show()
# 输出图谱基本信息
print("知识图谱节点数:", kg.number_of_nodes())
print("知识图谱边数:", kg.number_of_edges())
print("李白的所有关系:", list(kg.edges("李白")))输出结果:
知识图谱节点数: 5 知识图谱边数: 5 李白的所有关系: [('李白', '贺知章'), ('李白', '杜甫'), ('李白', '碎叶城'), ('李白', '长安')]
结果图示:
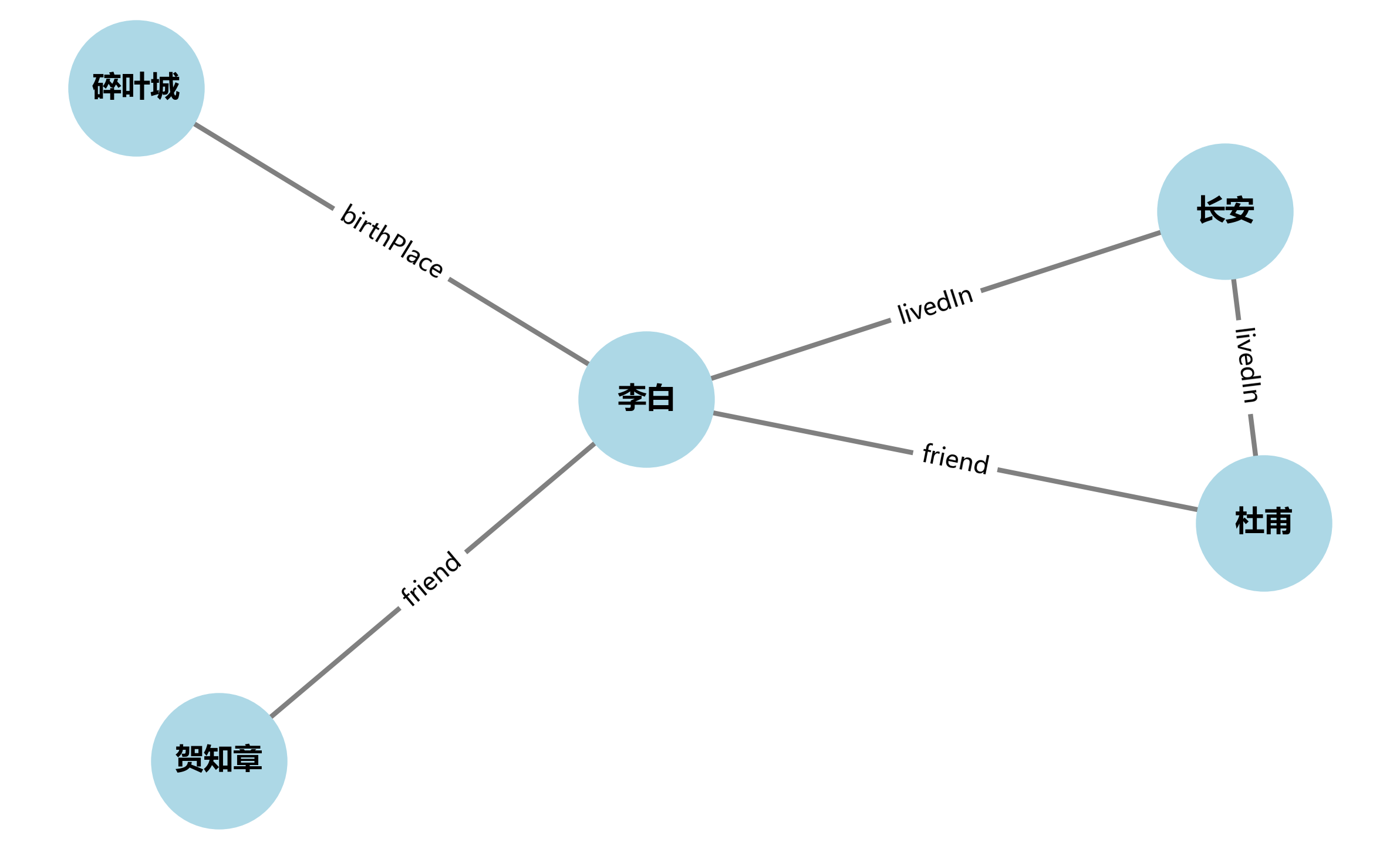
- 蓝色节点:实体(李白、杜甫、贺知章、碎叶城、长安)。
- 灰色边:实体之间的关系(friend、birthPlace、livedIn)。
- 节点标签:实体名称。
- 边标签:关系类型。
2. 图算法实战(最短路径 + PageRank)
import networkx as nx
import matplotlib.pyplot as plt
from matplotlib import font_manager
# 设置中文字体(解决中文显示乱码问题)
font_family = ["Microsoft YaHei", "SimHei", "WenQuanYi Micro Hei", "Heiti TC", "Arial Unicode MS"]
plt.rcParams["font.family"] = font_family
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# 查找并设置可用字体
available_fonts = [f.name for f in font_manager.fontManager.ttflist]
node_font = None
for font in font_family:
if font in available_fonts:
node_font = font
break
if node_font is None:
node_font = "DejaVu Sans" # 默认字体
print("警告: 未找到中文字体,可能显示乱码")
# 1. 创建空的无向图
kg = nx.Graph()
# 2. 添加节点(实体):人物节点,带属性
kg.add_node("李白", type="Person", birth_year=701)
kg.add_node("杜甫", type="Person", birth_year=712)
kg.add_node("贺知章", type="Person", birth_year=659)
kg.add_node("碎叶城", type="Place", location="吉尔吉斯斯坦")
kg.add_node("长安", type="Place", location="中国西安")
# 3. 添加边(关系):带关系类型属性
kg.add_edge("李白", "贺知章", relation="friend")
kg.add_edge("李白", "杜甫", relation="friend")
kg.add_edge("李白", "碎叶城", relation="birthPlace")
kg.add_edge("李白", "长安", relation="livedIn")
kg.add_edge("杜甫", "长安", relation="livedIn")
# 4. 可视化知识图谱(生成图片)
plt.figure(figsize=(10, 6))
# 设置节点位置
pos = nx.spring_layout(kg, seed=42) # seed固定布局
# 绘制节点
nx.draw_networkx_nodes(kg, pos, node_size=3000, node_color="lightblue")
# 绘制边
nx.draw_networkx_edges(kg, pos, width=2, edge_color="gray")
# 绘制节点标签
nx.draw_networkx_labels(kg, pos, font_size=12, font_weight="bold", font_family=node_font)
# 绘制边的关系标签
edge_labels = nx.get_edge_attributes(kg, "relation")
nx.draw_networkx_edge_labels(kg, pos, edge_labels=edge_labels, font_size=10, font_family=node_font)
# 隐藏坐标轴
plt.axis("off")
# 保存图片
plt.savefig("83.用NetworkX构建简单知识图谱 knowledge_graph.png", dpi=300, bbox_inches="tight")
# 1. 最短路径算法:找李白到贺知章的最短路径
shortest_path = nx.shortest_path(kg, source="李白", target="贺知章")
print("李白到贺知章的最短路径:", shortest_path)
# 2. PageRank算法:计算节点重要度
pagerank = nx.pagerank(kg)
# 按重要度排序
sorted_pagerank = sorted(pagerank.items(), key=lambda x: x[1], reverse=True)
print("\n节点重要度排名(PageRank):")
for node, score in sorted_pagerank:
print(f"{node}: {score:.4f}")
# 3. 社区发现算法:识别关系紧密的社区
from networkx.algorithms import community
# 贪心社区发现
communities = community.greedy_modularity_communities(kg)
print("\n识别到的社区:")
for i, comm in enumerate(communities):
print(f"社区{i+1}:{list(comm)}")输出结果:
李白到贺知章的最短路径: ['李白', '贺知章'] 节点重要度排名(PageRank): 李白: 0.3861 杜甫: 0.1949 长安: 0.1949 贺知章: 0.1121 碎叶城: 0.1121 识别到的社区: 社区1:['贺知章', '碎叶城', '李白'] 社区2:['长安', '杜甫']
3. 混元大模型结合
import os
import json
import networkx as nx
from openai import OpenAI
# from dotenv import load_dotenv
# 使用腾讯混元大模型
client = OpenAI(
api_key='sk-bWlJPKjBrSFGoQ0Ys0ma********************Z5NP8Ze',
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
# 1. 创建空的无向图
kg = nx.Graph()
# 2. 添加节点(实体):人物节点,带属性
kg.add_node("李白", type="Person", birth_year=701)
kg.add_node("杜甫", type="Person", birth_year=712)
kg.add_node("贺知章", type="Person", birth_year=659)
kg.add_node("碎叶城", type="Place", location="吉尔吉斯斯坦")
kg.add_node("长安", type="Place", location="中国西安")
# 3. 添加边(关系):带关系类型属性
kg.add_edge("李白", "贺知章", relation="friend")
kg.add_edge("李白", "杜甫", relation="friend")
kg.add_edge("李白", "碎叶城", relation="birthPlace")
kg.add_edge("李白", "长安", relation="livedIn")
kg.add_edge("杜甫", "长安", relation="livedIn")
# 定义函数:大模型把自然语言问题转成图查询指令
def nl2graph_query(question):
prompt = f"""
你是一个知识图谱查询转换助手,需要把用户的自然语言问题转换成针对NetworkX图的查询指令。
知识图谱包含的节点类型:Person(人物:李白、杜甫、贺知章)、Place(地点:碎叶城、长安)。
关系类型:friend(朋友)、birthPlace(出生地)、livedIn(居住过)。
请返回简洁的Python查询指令,仅返回代码片段,不要多余解释。
示例:
用户问题:李白的出生地在哪里?
输出:list(kg[李白][x] for x in kg.neighbors('李白') if kg[李白][x]['relation'] == 'birthPlace')
用户问题:{question}
"""
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content.strip()
# 定义函数:大模型把图算法结果转成自然语言回答
def graph_result2nl(question, result):
prompt = f"""
你是一个智能问答助手,需要把知识图谱的查询结果转换成自然、流畅的人类语言回答。
用户问题:{question}
图算法查询结果:{result}
请返回简洁、易懂的回答,不要多余解释。
"""
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content.strip()
# 实战:用户自然语言问答
user_question = "李白的出生地在哪里?"
print(f"\n用户问题:{user_question}")
# 步骤1:大模型转换查询指令
graph_query = nl2graph_query(user_question)
print(f"原始返回:{repr(graph_query)}")
# 清理混元返回的代码标记
if graph_query.startswith("```"):
graph_query = graph_query.split("```")[1]
if graph_query.startswith("python"):
graph_query = graph_query[6:].strip()
graph_query = graph_query.strip()
print(f"清理后的图查询指令:{repr(graph_query)}")
# 步骤2:执行图查询(安全执行)
try:
# 构造执行环境,包含节点名称
exec_env = {"kg": kg, "list": list, "李白": "李白", "杜甫": "杜甫", "贺知章": "贺知章", "碎叶城": "碎叶城", "长安": "长安"}
# 执行查询
exec(f"result = {graph_query}", exec_env)
graph_result = exec_env["result"]
print(f"图算法查询结果:{graph_result}")
except Exception as e:
graph_result = f"查询出错:{str(e)}"
print(f"图算法查询结果:{graph_result}")
# 步骤3:大模型生成自然语言回答
nl_answer = graph_result2nl(user_question, graph_result)
print(f"最终回答:{nl_answer}")
# 另一个示例:多步推理
user_question2 = "李白的朋友有谁?他们都住过哪里?"
print(f"\n用户问题:{user_question2}")
# 步骤1:转换查询指令
graph_query2 = nl2graph_query(user_question2)
# 清理代码标记
if graph_query2.startswith("```"):
graph_query2 = graph_query2.split("```")[1]
if graph_query2.startswith("python"):
graph_query2 = graph_query2[6:].strip()
graph_query2 = graph_query2.strip()
print(f"转换后的图查询指令:{graph_query2}")
# 步骤2:执行查询(查询李白的朋友)
try:
exec_env2 = {"kg": kg, "list": list, "李白": "李白", "杜甫": "杜甫", "贺知章": "贺知章", "碎叶城": "碎叶城", "长安": "长安"}
exec(f"result2 = {graph_query2}", exec_env2)
friends_result = exec_env2["result2"]
print(f"查询返回结果:{friends_result}")
# 提取朋友节点名称(获取邻居节点)
friends_names = list(kg.neighbors('李白'))
# 筛选出关系是friend的朋友
friends = [n for n in friends_names if kg['李白'][n]['relation'] == 'friend']
print(f"李白的朋友:{friends}")
# 步骤3:查询朋友们居住的地方
if friends:
for friend in friends:
friend_places = []
for neighbor in kg.neighbors(friend):
if kg[friend][neighbor]['relation'] == 'livedIn':
friend_places.append(neighbor)
print(f" {friend} 住过:{friend_places}")
except Exception as e:
print(f"查询出错:{str(e)}")
# 步骤4:大模型生成自然语言回答
if 'friends_result' in locals():
nl_answer2 = graph_result2nl(user_question2, f"李白的朋友:{friends_result}")
print(f"最终回答:{nl_answer2}")示例细节:
- 1. 知识图谱构建的注意事项
- 节点命名要统一:避免“李白”、“李太白”、“诗仙”同时作为独立节点,需先做实体归一化。
- 关系类型要标准化:比如“出生地”统一用“birthPlace”,不要混用“出生于”、“老家”。
- 属性要结构化:尽量用“键值对”存储,比如“birth_year:701”而非“李白701年出生”。
- 2. 图算法选择技巧
- 简单关系查询:用最短路径、邻居查询。
- 重要度排序:用 PageRank。
- 分组分析:用社区发现。
- 实体匹配:用实体链接,可结合大模型做别名匹配。
- 3. 大模型提示词优化技巧
- 明确知识图谱的结构:告诉大模型有哪些节点、关系类型。
- 限定输出格式:让大模型只返回查询指令,避免多余内容。
- 提供示例:给出 1-2 个示例,提升转换准确率。
输出结果:
用户问题:李白的出生地在哪里? 原始返回:"```python\nlist(kg[李白][x] for x in kg.neighbors('李白') if kg[李白][x]['relation'] == 'birthPlace')\n```" 清理后的图查询指令:"list(kg[李白][x] for x in kg.neighbors('李白') if kg[李白][x]['relation'] == 'birthPlace')" 图算法查询结果:[{'relation': 'birthPlace'}] 最终回答:李白的出生地是西域碎叶城,即今天的吉尔吉斯斯坦境内。 用户问题:李白的朋友有谁?他们都住过哪里? 转换后的图查询指令:list(kg[李白][x] for x in kg.neighbors('李白') if kg[李白][x]['relation'] in ['friend', 'livedIn']) 查询返回结果:[{'relation': 'friend'}, {'relation': 'friend'}, {'relation': 'livedIn'}] 李白的朋友:['贺知章', '杜甫'] 贺知章 住过:[] 杜甫 住过:['长安'] 最终回答:李白的朋友有杜甫、贺知章等人,他们曾共同居住在长安城。
六、总结
以前我也总觉得,大模型够强就能搞定一切问答,但接触的越深越明白,纯大模型天生有短板,容易幻觉、推理不严谨、答案没法追溯。而基于图算法管关系、混元管语言的双引擎模式,刚好把两者的优势捏合在了一起:用 PageRank、最短路径、社区发现这些图算法做关系挖掘和推理,靠大模型做自然语言理解和生成,搭出来的知识图谱问答系统,既听得懂人话,又能给出靠谱、可溯源的答案。
总的来说,做落地项目,从来不是堆技术,而是让专业的工具干专业的事。知识图谱负责存事实,图算法负责推逻辑,大模型负责做交互,分工明确才够稳定。我们初次接触可以先别着急对接大模型,先用NetworkX搭小图谱、跑通图算法,把实体和关系的逻辑理清楚;再接入大模型的API或本地大模型做语言转换,循序渐进才不容易乱。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号