LangChain源码解析:Function Call是如何被执行的

LangChain源码解析:Function Call是如何被执行的

烟雨平生
发布于 2026-04-21 14:24:02
发布于 2026-04-21 14:24:02
本文基于 langchain 1.2.15、langchain-core 1.3.0、langgraph 1.1.8 源码拆解
大家都知道 LLM 根据用户的问题找到需要的 Function Call,然后执行。
但这个过程在代码层面是如何实现的呢?
LLM 只能输入文本、输出文本——在 LLM 选中一个 Function Call 后,LangChain 是如何触发真实代码的执行、拿到结果、再送回去和 LLM 继续聊的?
今天把这件事从源码层面讲透。
01 先跑起来
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain.agents import create_agent
@tool
def get_weather(city: str) -> str:
"""查询指定城市的天气"""
return f"{city}今天晴,25°C"
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
agent = create_agent(llm, [get_weather])
result = agent.invoke({
"messages": [{"role": "user", "content": "北京今天天气怎么样?"}]
})
print(result["messages"][-1].content)
# → 今天北京天气晴,气温25°C就这几行代码。
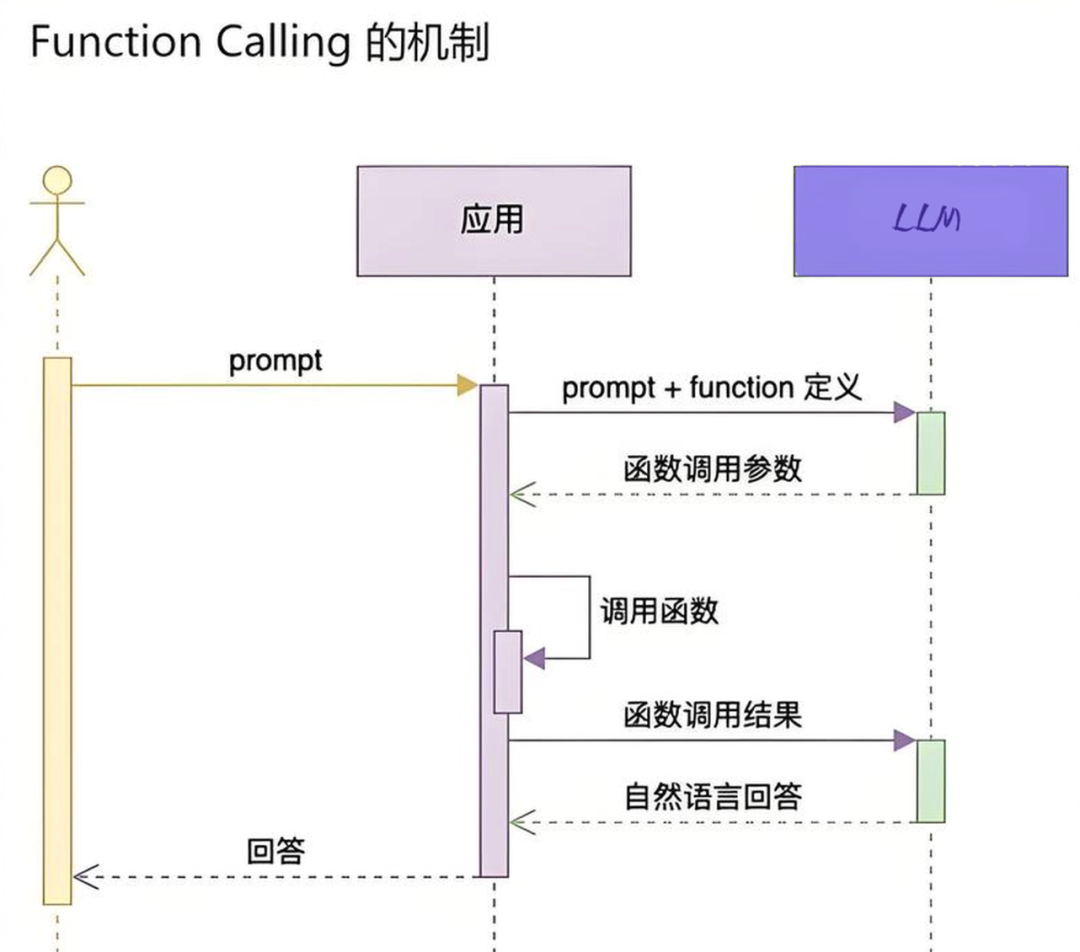
大模型返回“函数调用参数”到“调用函数”这一步是怎么实现的呢?接下来拆开看内部原理。
02 整体架构:LangGraph 状态图
LangChain 1.x 的 Agent 底层是一张有向状态图(StateGraph),由 LangGraph 库驱动。
create_agent 的源码第一行导入就是 from langgraph.graph.state import StateGraph——LangChain 在这里只是对 LangGraph 做了上层封装。
这张图只有两个节点,在 model 和 tools 之间来回跳转:
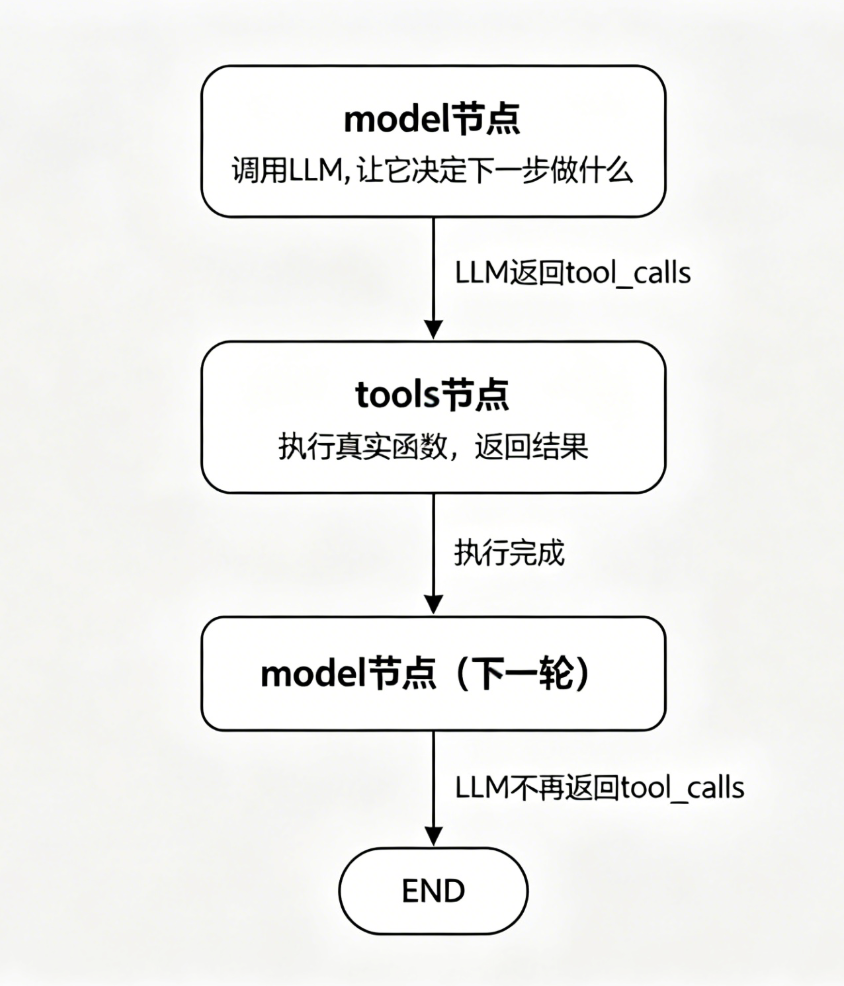
model 节点:调用 LLM 时传入工具描述(JSON schema),LLM 根据对话历史决定是直接回答,还是调用某个工具。
tools 节点:拿到 LLM 返回的 tool_calls 后,根据函数名找到对应的真实函数,调用它,拿到返回值包装成 ToolMessage。
节点之间的边是条件判断:
- model 输出里有
tool_calls→ 跳到 tools 节点 - tools 执行完成 → 跳回 model 节点
- model 输出里没有
tool_calls→ 结束
图引擎在这个循环里来回跳,直到 LLM 决定不再调用工具。
03 源码拆解
3.1 create_agent:构建状态图
源码文件:langchain/agents/factory.py
def create_agent(model, tools, ...):
# 创建状态图,状态里只有一个核心字段:messages(所有对话历史)
graph = StateGraph(AgentState)
# 添加 model 节点:调用 LLM
graph.add_node("model", model_node)
# 添加 tools 节点:用 LangGraph 内置的 ToolNode 封装所有工具
tool_node = ToolNode(tools)
graph.add_node("tools", tool_node)
# 添加边
graph.add_edge(START, "model") # 入口:先调用 model
# 条件边:model → tools(有 tool_calls 时)
# model → END(无 tool_calls 时)
graph.add_conditional_edges(
"model",
_make_model_to_tools_edge(...), # 判断条件:tool_calls 是否为空
{"tools": "tools", END: END}
)
# tools → model(工具执行完,回 LLM 看结果)
graph.add_edge("tools", "model")
return graph.compile()条件边的判断函数检查 LLM 输出的 AIMessage.tool_calls 是否为空——非空就去 tools 节点,为空就结束。
3.2 model 节点
当图执行到 model 节点时,底层做的事:
# 从 AgentState["messages"] 取出所有历史对话
messages = state["messages"]
# 调用 LLM,传入两样东西
response = llm.invoke(
messages, # 历史对话(LLM 知道上下文)
tools=[get_weather] # 工具描述(JSON schema)
)工具描述是 @tool 装饰器从函数签名自动提取的,包含函数名、参数名、参数类型、docstring 描述。LLM 通过这个 schema 知道有哪些函数可以调用、每个函数需要什么参数。
LLM 的返回:当你传入 tools 参数时,OpenAI API 直接在响应里返回一个结构化字段 tool_calls,内容是一个列表,每个元素包含 id、name、args:
AIMessage(
content="",
tool_calls=[{
"id": "call_abc123",
"name": "get_weather",
"args": {"city": "北京"} # 已经是 dict,不需要 JSON 解析
}]
)3.3 tools 节点
源码:langgraph/prebuilt/tool_node.py(LangGraph 内置)
当图路由到 tools 节点时,LangGraph 内置的 ToolNode 执行这个逻辑:
class ToolNode:
def _execute_tool_sync(self, request, config, ...):
call = request.tool_call
# 根据函数名找到工具(字典查找)
tool = self.tools_by_name[call["name"]]
# 调用 tool.invoke 执行
response = tool.invoke(call_args, config)
# 把结果包装成 ToolMessage
return ToolMessage(
content=str(response),
tool_call_id=call["id"],
name=call["name"],
status="success",
)tools_by_name 是创建 ToolNode 时构建的 {函数名: 工具实例} 字典,Key是工具名称Val是StructuredTool实例。@tool 装饰器把你的函数包装成一个 StructuredTool 对象,函数引用直接存在 self._run 里。工具字典在调用create_agent(llm,[函数])时创建,通常写在全局函数中由框架启动时自动执行一次。为了复用。
3.4 BaseTool.invoke
源码:langchain_core/tools/base.py
tool.invoke() 是 LangChain 所有工具的统一执行入口:
def invoke(input, config=None, **kwargs):
# _prep_run_args 把 ToolCall 拆解成参数
tool_input, run_kwargs = _prep_run_args(input, config)
# 内部逻辑:
# if input["type"] == "tool_call":
# tool_input = input["args"].copy() # {"city": "北京"}
return self.run(tool_input, **run_kwargs)
# → self._run(city="北京") # 最终调用原函数调用链路是:invoke → run → _to_args_and_kwargs(把 dict 拆成参数)→ _run(执行原函数)。
3.5 AgentState
AgentState 定义图的共享状态:
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], add_messages]核心只有一个字段:messages(对话历史)。
add_messages 是一个 reducer 函数,告诉图引擎如何把新消息合并到已有列表里。
第1轮:
messages = [HumanMessage("北京天气怎么样?")]
→ model 输出 AIMessage(tool_calls=[...])
→ tools 输出 ToolMessage(...)
→ messages = [Human, AIMessage, ToolMessage]
第2轮:
→ model 输入 [Human, AIMessage, ToolMessage]
→ LLM 看到工具已执行,直接输出最终回答
→ 没有 tool_calls → 结束每轮 messages 都累积,图引擎自动把完整历史传给下一轮 LLM。
04 完整执行流程

05 常见疑问
LLM 返回的是文本还是结构化数据?
当你调用 llm.invoke(messages, tools=[...]) 时,tools 参数是传给 OpenAI API 的。API 直接在响应里返回结构化字段 tool_calls,LangChain 只是把它包装成 AIMessage.tool_calls。不是从文本里解析的。
如果 LLM 幻觉了,返回一个不存在的函数名怎么办?
ToolNode 查字典时发现函数名不存在,返回一条 ToolMessage(status="error"):
Error: Requested tool 'get_weatherrr' not available.
Available tools: get_weather, get_time这条错误消息被写回 messages,下一轮 LLM 会看到它,通常会自动纠正。
会无限循环吗?
不会。LangGraph 内置了 recursion_limit,默认 10007 次。每次 model ↔ tools 跳一个来回算一次。超过上限直接抛异常。正常情况下 LLM 一两次就会纠正,远到不了这个上限。
是反射调用吗?
不是。@tool 装饰器在定义时就把函数包装成 StructuredTool 对象,引用存在 tools_by_name 字典里。执行时是 tools_by_name[name] 字典查找 + 普通方法调用,没有 getattr 等反射操作。
多个 tool_calls 同时返回怎么办?
LLM 可以在一次响应里返回多个 tool_calls。ToolNode 并行执行所有工具,把所有 ToolMessage 一起写回 messages,然后统一回到 model 节点。
我之前用的是 LangChain v0.3,有什么变化?
v0.3 用的是 AgentExecutor + create_tool_calling_agent,底层是 Python while 循环。v1.x 全部替换为 LangGraph StateGraph:
# v0.3(已废弃)
from langchain.agents import AgentExecutor, create_tool_calling_agent
agent_executor = AgentExecutor(agent=agent, tools=[...])
result = agent_executor.invoke({"input": "..."})
# v1.x(当前)
from langchain.agents import create_agent
agent = create_agent(model=llm, tools=[...])
result = agent.invoke({"messages": [{"role": "user", "content": "..."}]})注意输入格式也变了:{"input": "..."} → {"messages": [...]}。
05 常见疑问

四个关键点:
- tool_calls 是 API 直接返回的结构化数据,不是 LangChain 从文本里解析的
- 函数分发靠字典查找
tools_by_name[name],不是反射 - 幻觉不会崩溃:ToolNode 返回错误提示,LLM 自纠
- 不会无限循环:recursion_limit 兜底,默认 10007 次
https://github.com/langchain-ai/langchain
一文讲清:LLM、CoT、Function Calling、MCP、Skills、Agent、Agent OS
别再问LLM、Workflow、Function Call、MCP、Skill、Agent、OpenClaw是什么了,看完这篇秒懂!有配套源码
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号