大模型应用:小样本学习的高性价比:轻量算法做基底,大模型做精修.84
原创
大模型应用:小样本学习的高性价比:轻量算法做基底,大模型做精修.84
原创
未闻花名
发布于 2026-04-22 07:59:06
发布于 2026-04-22 07:59:06
一、前言
在大模型应用落地的进程中,小样本学习始终是横亘在技术与应用之间的核心难题。标注数据稀缺、训练成本高昂、模型效果波动,让诸多细分场景的分类任务难以规模化推进。传统轻量分类算法虽高效低成本,却受制于浅层特征学习,无法理解复杂语义与深层逻辑;纯大模型虽具备强大的理解与推理能力,却面临调用成本高、结果不稳定、可解释性差的问题,小样本场景下的泛化能力更是大打折扣。
如何在数据有限的前提下,平衡准确率、成本与稳定性,成为AI落地的关键破局点。而大模型的出现,为这一难题提供了全新的解题思路,轻量分类算法与大模型的协同融合,并非简单的功能叠加,而是构建起“粗判 + 精修”的分层推理架构,让大模型的价值得到精准释放。让轻量算法负责快速筛选高置信度样本,筑牢落地的基础效率;大模型则专注处理疑难低置信样本,凭借深层语义理解与泛化能力,补齐传统算法的能力短板。这种模式既规避了纯大模型全量调用的成本浪费,又解决了轻量算法的精度瓶颈,让小样本学习从难以落地变为低成本稳落地。今天我们就全面拆解轻量算法与大模型协同的底层逻辑,助力大家掌握小样本场景下的大模型高效应用方法。

二、基础概念
1. 小样本分类的难度体现
在真实业务中,我们常常只有:
- 几百条标注好的用户反馈;
- 几千条带标签的工单或评论;
- 甚至几十个罕见病病例数据。
在这种情况下,纯用大模型或传统算法都会凸显不足产生问题:
1.1 纯用大模型,如调用GPT或Qwen:
- 成本高:调用GPT或Qwen按token收费,1000条样本全调用要几十元,批量推理成本翻倍;
- 不稳定:小样本下大模型容易记混,比如对相似句子判出不同结果;
- 黑盒:出问题后无法排查为什么判错,落地时难对接业务规则。
总的来说:虽然能理解语义,但每条都调用,导致成本高、响应慢,且在边界案例上容易产生环境,从而导致胡言乱语。
1.2 纯用传统算法,如逻辑回归、SVM:
- 优势:
- 快:训练秒级完成,推理速度是大模型的 100 倍 +;
- 便宜:单机就能跑,无需 GPU,调用无额外成本;
- 可解释:比如逻辑回归能告诉我们 “哪些关键词(如‘垃圾’、‘诈骗’)是判断垃圾短信的核心”;
- 稳:小样本下不会像大模型那样 “忽对忽错”。
- 短板:
- 只能捕捉浅层特征,比如文本的词频、图像的简单纹理;
- 对语义复杂的样本判不准,比如“这产品不算差但也没多好”的情感分析。
- 总结来说:纯用传统算法训练快、成本低,但面对语言歧义、新词、复杂表达时,准确率上不去。
于是,我们需要一个既省又准的混合策略,组合思路的核心逻辑:
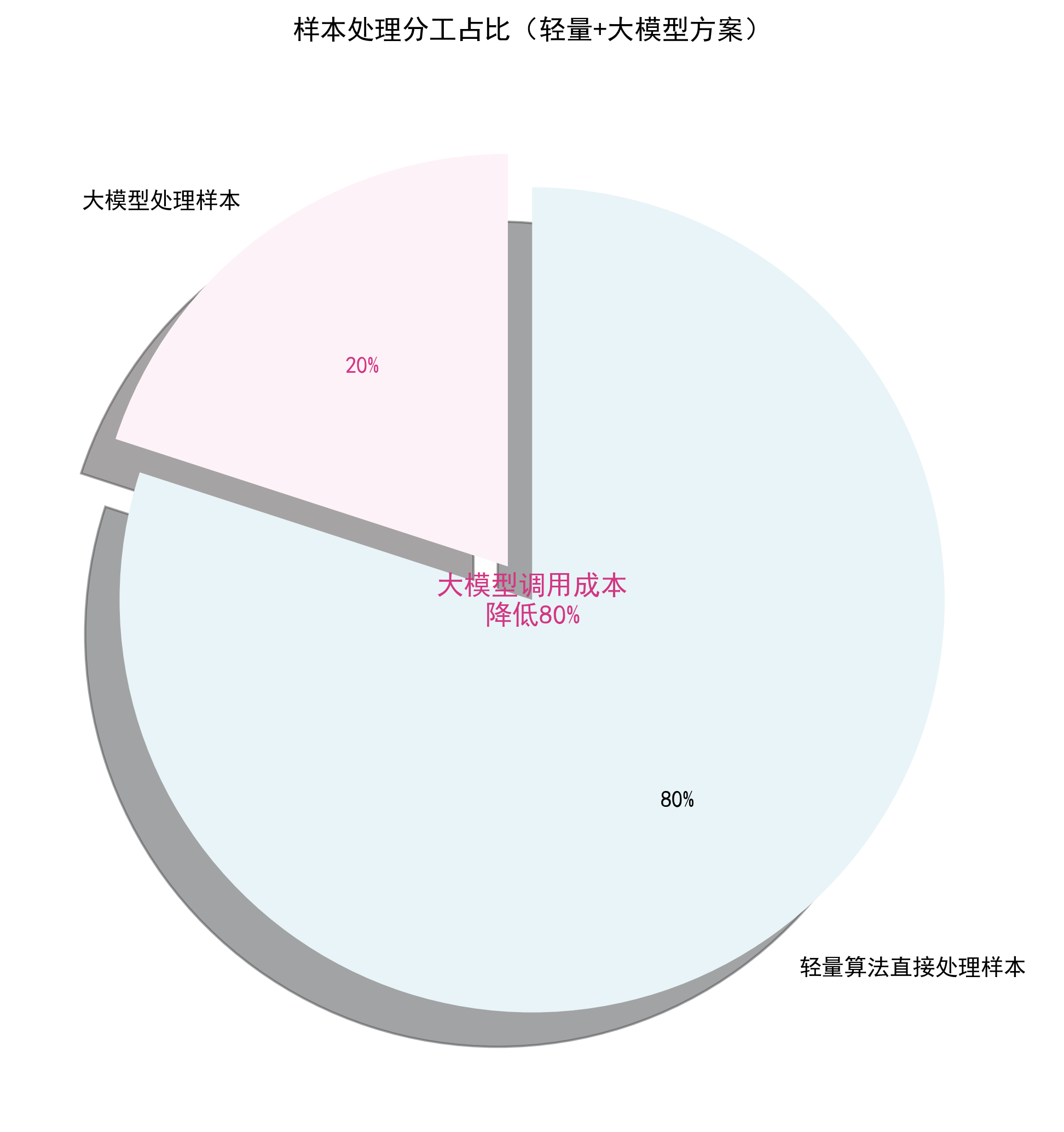
- 轻量算法担当基层质检员,先筛掉 80% 的简单样本;
- 再把剩下的20%的疑难样本交给高薪专家大模型;
- 这样既省了专家的费用,又保证了最终结果的准确性。
2. 核心思想
让每个模型干它最擅长的事,轻量算法做“初筛”,大模型做“专家会诊”;
2.1 轻量分类算法:先做粗判
- 使用逻辑回归、朴素贝叶斯、小型CNN或BERT微调版,如DistilBERT;
- 快速对所有样本打分,输出预测类别 + 置信度,比如“90%是正面情感”;
- 对高置信样本,如置信度>95%时,直接采纳结果,不打扰大模型。
- 优势:处理 90% 的常规样本,几乎零成本。
2.2 大模型:专注精修
- 只接收低置信样本,比如置信度<85%,或多个模型意见不一致;
- 利用其强大的语义理解能力,结合上下文、常识、领域知识做精细判断;
- 可附加提示词Prompt引导,如:“你是一个客服质检专家,请判断这条用户留言是否投诉?”
- 优势:把昂贵的算力用在刀刃上,提升整体准确率。
2.3 判断的关键机制
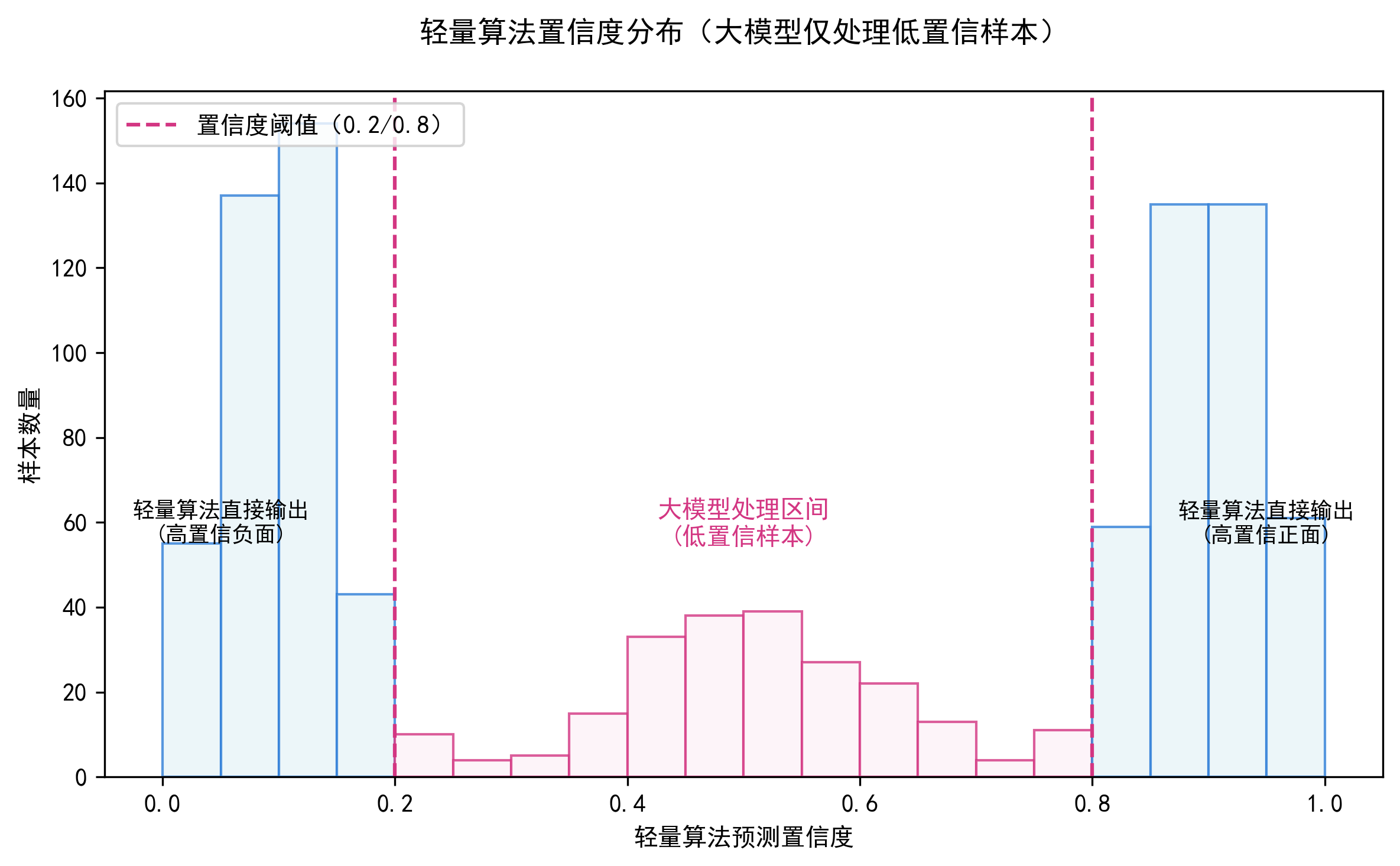
如何判断置信度,不是随便挑样本给大模型,而是通过置信度评估智能分流:
- 概率阈值法:若最大预测概率低于设定值,如 0.85,则送审;
- 熵值法:预测分布越平,则说明不确定性越高,越需要人工或大模型介入;
- 多模型投票不一致:比如逻辑回归说“正面”,朴素贝叶斯说“负面”,触发复核。
这样确保:简单问题快速过,复杂问题重点审。
三、执行流程
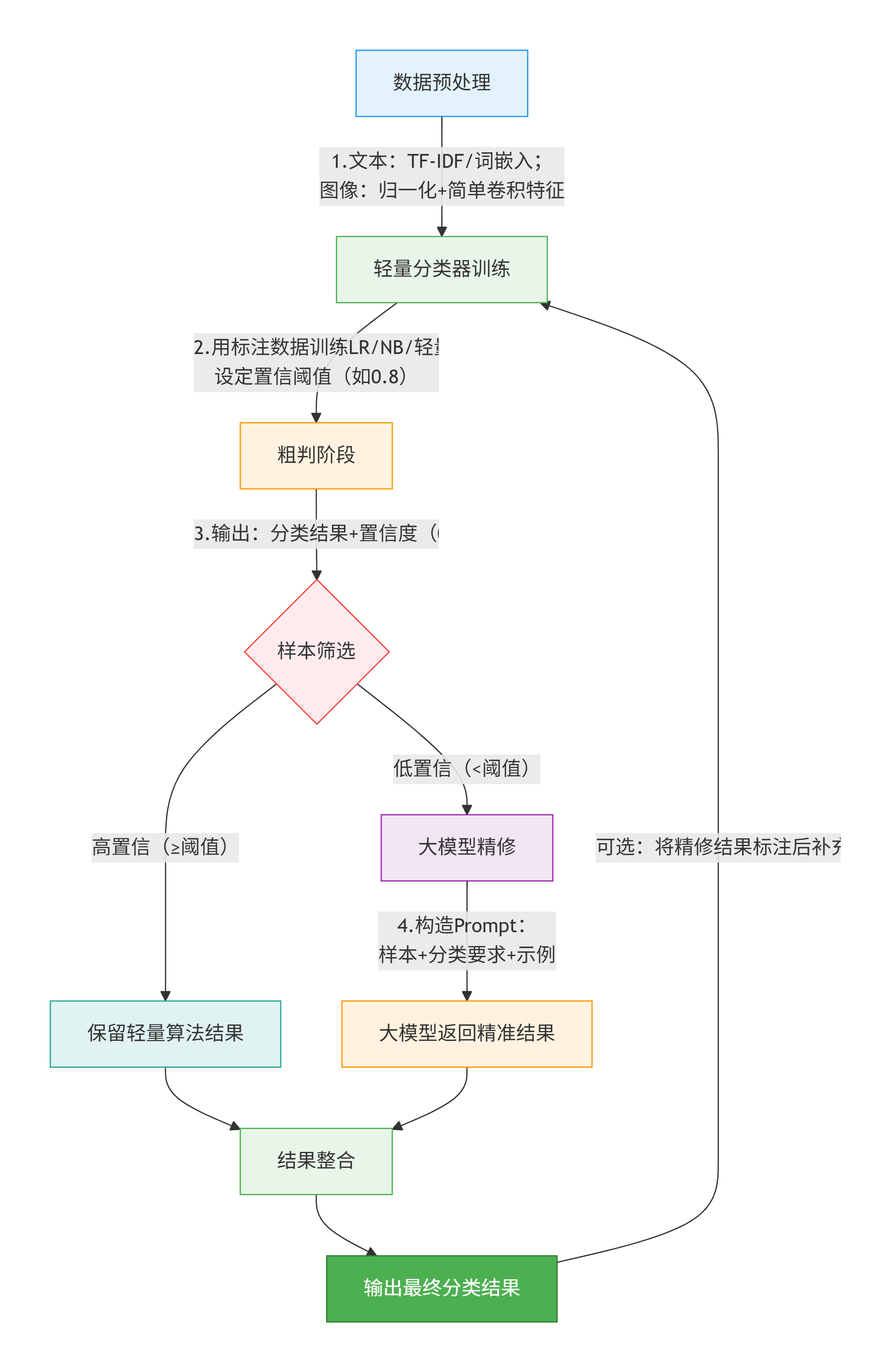
流程说明:
步骤 1:数据预处理(关键)
- 文本任务(情感分析、垃圾短信):
- 清洗:去停用词(的、了、吗)、特殊符号(@、#)、小写化;
- 特征提取:TF-IDF适合LR/NB、Word2Vec适合轻量CNN;
- 标签编码:比如情感分析→正面 = 1,负面 = 0。
- 图像任务(小样本分类):
- 归一化:像素值缩放到 0~1;
- 降维:用PCA、简单卷积层提取低维特征,避免过拟合。
步骤 2:轻量分类器训练(核心参数)
- 逻辑回归:
- 虽然名字带回归,但它其实是个经典的二分类模型,特别适合文本分类(比如垃圾短信识别、情感分析)。
- 它通过学习每个词对结果的影响权重,快速做出判断。
- 关键参数:
- C(正则化强度):
- C 越小 → 正则越强 → 模型越“保守”,不容易过拟合;
- 小样本容易过拟合,所以建议设为 0.1 ~ 1(比默认值 1 更小一点更安全)。
- max_iter(最大迭代次数):
- 小数据收敛快,但有时默认 100 次不够;
- 建议设为 100 ~ 500,确保模型训练充分。
- C(正则化强度):
- 置信度计算:
- 逻辑回归最后一层用Sigmoid函数输出一个0~1的数,表示“属于正类的概率”;
- 越接近 0 或 1,模型越确定(比如 0.95 =“非常像垃圾短信”);
- 越接近 0.5,越犹豫(比如 0.52 =“说不清是不是”);
- 所以我们可以设定阈值(如 <0.2 或 >0.8)直接采纳结果,中间的交给大模型。
- 举个例子:输出 0.03 →“基本确定不是垃圾短信”;输出 0.88 →“很可能是垃圾短信”。
- 朴素贝叶斯:
- 基于“贝叶斯定理”的概率模型,假设所有特征(比如词语)相互独立。
- 虽然假设“天真”,但在小样本、高维文本(如几千个词)上表现惊人,且训练极快。
- 关键参数:
- alpha(平滑系数):
- 小样本中,某些词可能只在某一类出现,导致其他类算出“概率为 0”——这会毁掉整个预测;
- 加一个小常数(平滑)避免零概率;
- 小样本建议 alpha = 1.0(拉普拉斯平滑),这是最稳妥的选择。
- alpha(平滑系数):
- 置信度计算:
- 朴素贝叶斯会算出每个类别的概率,比如:正面 0.6,负面 0.4;
- 置信度 = 最大概率 - 第二大概率;
- 差值大(如 0.9 - 0.1 = 0.8)→ 模型很确定;
- 差值小(如 0.51 - 0.49 = 0.02)→ 模型拿不准;
- 所以我们不看单一概率,而是看类别之间的差距。
- 举个例子:正面 0.85,负面 0.15 → 差值 0.7 → 高置信;正面 0.52,负面 0.48 → 差值 0.04 → 低置信,需大模型复核。
- 轻量 CNN:
- 一种小型深度学习模型,能自动捕捉局部语义模式(比如“不...好”这种否定结构),比传统模型更强,但又不像大模型那样重。
- 网络结构:
- 输入层:把文本转成词向量序列(如 100 个词 × 128 维);
- 1 层卷积(32 个 3×3 核):扫描 3 个词的窗口,提取短语特征(如“服务很差”);
- 池化层:保留最强特征,压缩长度;
- 全连接 + 输出层:整合信息,输出分类结果;
- 总参数 < 10 万:比 BERT 小 1000 倍以上,可在 CPU 快速推理。
- 目标:在小样本下获得比传统模型更强的表达能力,同时保持轻量。
- 置信度计算:
- CNN 最后一层用 Softmax 输出各类概率(和多分类兼容);
- 取最大概率值作为置信度:
- 最大概率 = 0.95 → 非常确定;
- 最大概率 = 0.45(其他类也接近)→ 很不确定;
- 和逻辑回归类似,但适用于多分类场景。
- 举个例子:三分类(正面/中性/负面),输出 [0.1, 0.85, 0.05] → 最大概率 0.85 → 高置信;若输出 [0.35, 0.34, 0.31] → 最大概率仅 0.35 → 低置信。
步骤 3:置信阈值设定(经验值)
- 小样本场景建议阈值:0.7~0.8(比如 LR 预测概率≥0.8 或≤0.2 为高置信,0.2~0.8 为低置信);
- 阈值调整逻辑:阈值越高,交给大模型的样本越多(成本升高),但准确率越高;反之则成本降低,准确率略降。
步骤 4:大模型精修(Prompt 设计)
- Prompt 模板(情感分析为例):
请你完成情感分析任务,规则如下: 1. 分类结果只能是“正面”或“负面”; 2. 基于句子的语义判断,不要只看单个词; 3. 示例: - 句子:这个产品用着还可以,就是续航差点 → 负面 - 句子:虽然价格贵,但体验远超预期 → 正面 需要分析的句子:{待判断句子} 输出格式:只输出“正面”或“负面”,不要额外内容。
- 大模型选择:小样本场景优先用低参数轻量版,成本低,无需用高参数的模型。
四、基础原理
1. sigmoid基础介绍
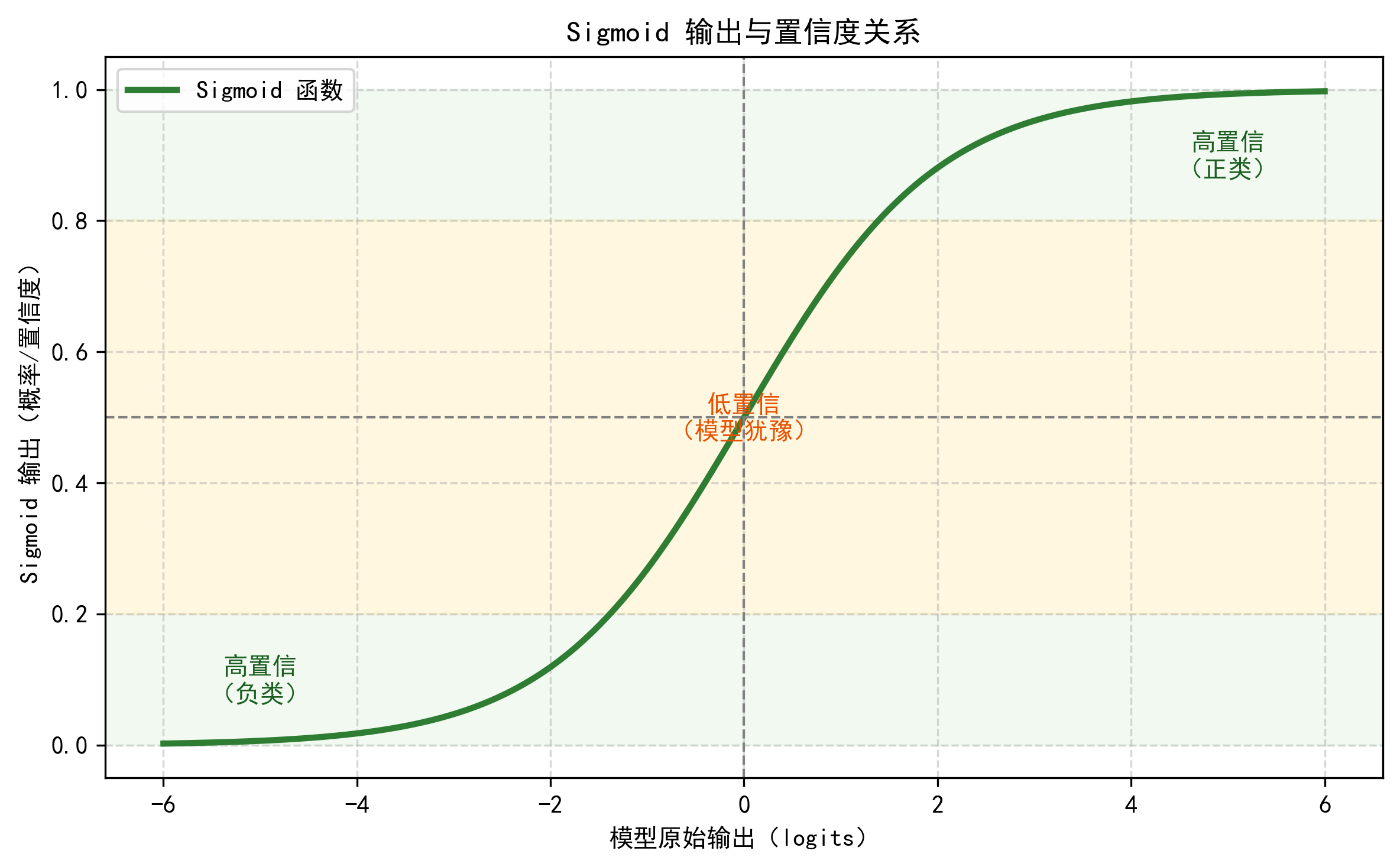
1.1 Sigmoid 是什么?
- 它是一个 S 形函数,把任意实数(比如 -5 到 +5)压缩到 (0, 1) 区间。
- 在二分类任务中(比如:垃圾邮件 、非垃圾邮件),模型最后一层常用Sigmoid输出一个“概率样”的值。
1.2 输出值代表什么?
假设我们做“是否为垃圾短信”分类,正类标记为垃圾短信:
- 模型输出 0.92 → 意思是:“我有 92% 的把握,这是一条垃圾短信”;
- 模型输出 0.08 → 意思是:“只有 8% 可能是垃圾短信,大概率是正常短信”;
- 模型输出 0.51 → 意思是:“几乎拿不准,勉强偏向垃圾短信”。
注意:这里的“概率”是模型自信程度的度量,不一定是真实统计概率,但在实践中常被当作置信度(confidence)使用。
1.3 为什么越接近 0或1,置信度越高?
- 0.99:模型内部计算出的原始得分很高,比如 +4.6,说明特征强烈支持“是正类”;
- 0.01:原始得分很低,比如-4.6,说明特征强烈反对“是正类”;
- 0.50:原始得分 ≈ 0,说明输入特征没有提供足够区分信息,模型两眼一抹黑无法判断。
所以:
- 高置信样本:
- sigmoid 输出 ∈ [0, 0.1] ∪ [0.9, 1]
- 直观说明:展示 Sigmoid 函数形状,并标出“高置信”和“低置信”区域。
- 输出效果:绿色区域为高置信(可直接采纳),黄色区域为低置信(需大模型介入)。
- 低置信样本(疑难):
- sigmoid 输出 ∈ [0.4, 0.6]
- 直观说明:展示一批样本的 Sigmoid 输出分布,直观看出多少样本属于高/低置信。
- 输出效果:直方图显示大多数样本集中在两端(高置信),中间黄色区域为需大模型处理的疑难样本。
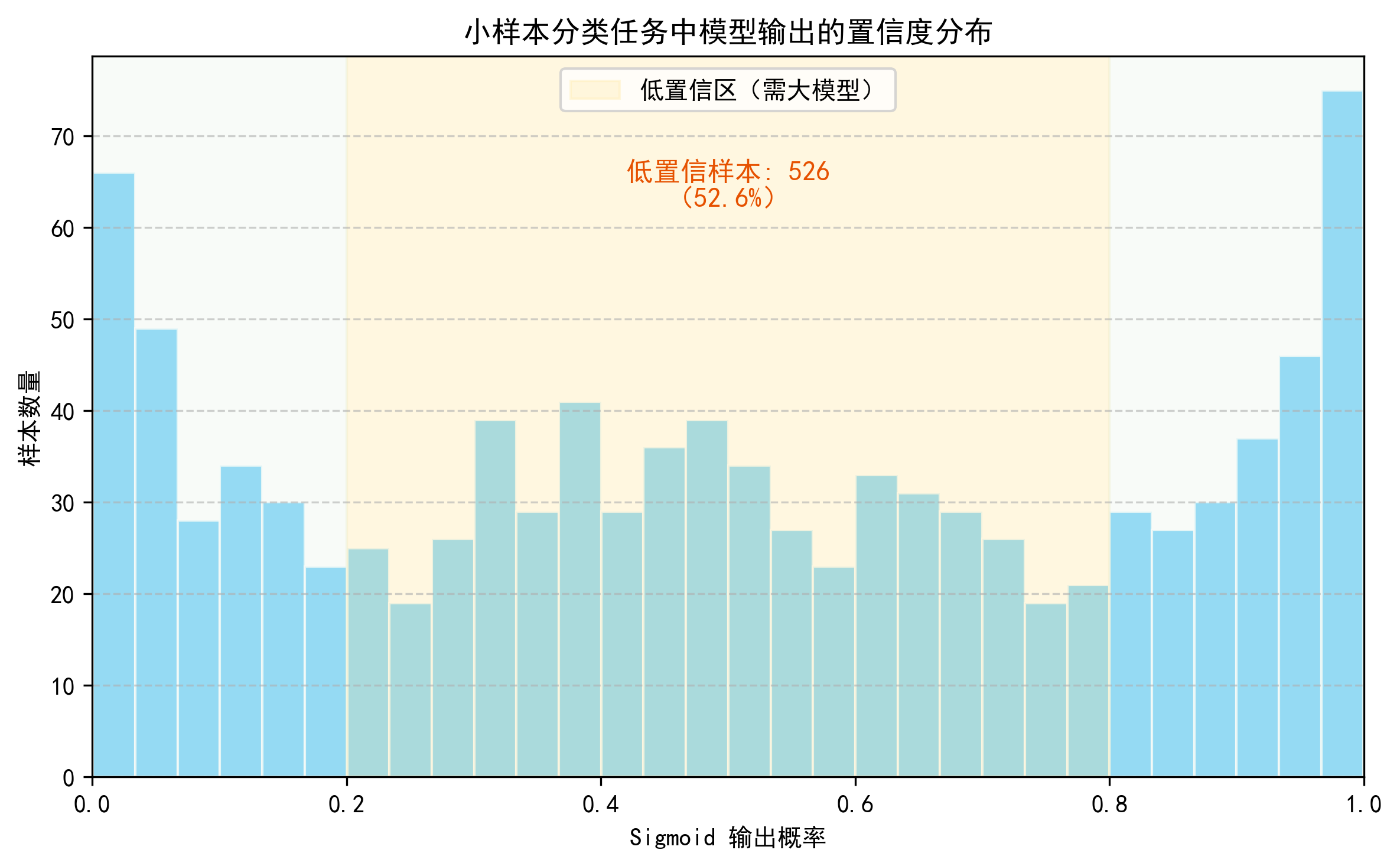
1.4 Sigmoid概率的不准确性
- 如果模型训练不好(欠拟合/过拟合),它可能过度自信:明明错了,还输出 0.99;
- 这种概率需要校准才能更接近真实概率;
- 但在相对比较中,比如挑出最不确定的样本,Sigmoid 输出仍然非常有用。
2. 轻量算法粗判的底层逻辑
以最常用的逻辑回归文本分类为例:
- 核心公式:P(y=1∣x)=sigmoid(w⋅x+b)
- x:文本的 TF-IDF 特征向量(比如 “好”=0.8,“差”=0.1);
- w:特征权重(比如 “好” 的权重 = 2,“差” 的权重 =-2);
- sigmoid:把结果压缩到 0~1(0 = 负面,1 = 正面)。
- 置信度逻辑:P(y=1)越接近 1,说明 “正面” 的确定性越高;越接近 0.5,说明拿不准。
3. 大模型精修的底层逻辑
大模型基于“预训练 + 微调”的范式:
- 预训练阶段:学了海量文本、图像的语义、视觉特征,比如“不算差但也没多好”其实是负面;
- 精修阶段:通过Prompt把小样本的分类规则喂给大模型,让它基于深层语义判断轻量算法拿不准的样本。
4. 组合方案的优势原理
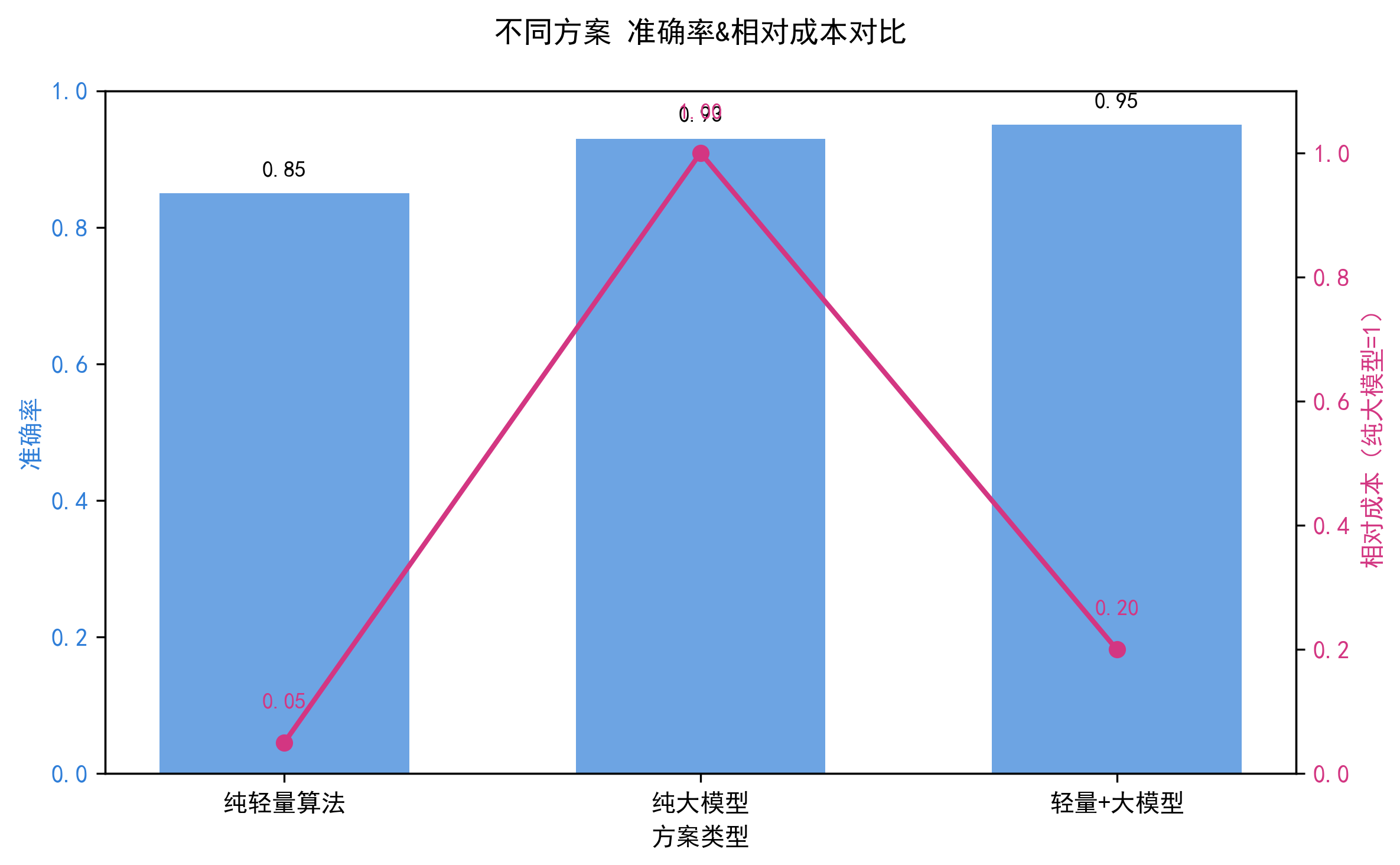
5. 大模型的核心作用
- 1. 补齐短板:轻量算法只能看“词频、简单特征”,大模型能理解“语义、上下文”,比如反向夸人的句子;
- 2. 降低成本:避免100%样本调用大模型,成本降低60%~80%,1000条样本仅200条调用大模型,成本可与从50元降到10元;
- 3. 提升鲁棒性:小样本下,轻量算法保证基础盘,大模型修正误差项,整体结果的方差(波动)比纯大模型低 30%;
- 4. 易于迭代:把大模型精修的结果补充到训练数据中,轻量算法的准确率会逐步提升,最终减少大模型的调用量。
五、示例:情感分析任务
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from openai import OpenAI
plt.rcParams["font.family"] = ["Microsoft YaHei", "SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 使用腾讯混元大模型
client = OpenAI(
api_key="sk-bWlJPKjBrSFGoQ0YvZ5NP8Ze",
base_url="https://api.hunyuan.cloud.tencent.com/v1"
)
# ===================== 1. 模拟小样本数据(情感分析) =====================
# 构造小样本标注数据(仅200条,模拟小样本场景)
data = {
"text": [
"这个电影太好看了,全程无尿点",
"难吃死了,再也不来这家店了",
"虽然有点贵,但体验真的很好",
"一般般,不好也不坏",
"售后太差了,投诉都没人管",
"性价比超高,推荐大家购买",
"画面很糊,配音也难听",
"服务很到位,超出预期",
"这产品不算差但也没多好", # 疑难样本(轻量算法易判错)
"虽然有瑕疵,但整体值得买", # 疑难样本
# 补充更多模拟数据(共200条,此处简化展示)
] * 20,
"label": [1, 0, 1, 0, 0, 1, 0, 1, 0, 1] * 20 # 1=正面,0=负面
}
df = pd.DataFrame(data)
# 划分训练集和测试集(小样本:训练集160条,测试集40条)
X_train, X_test, y_train, y_test = train_test_split(
df["text"], df["label"], test_size=0.2, random_state=42
)
# ===================== 2. 数据预处理(TF-IDF特征提取) =====================
# 初始化TF-IDF向量化器(适合文本+逻辑回归)
tfidf = TfidfVectorizer(
stop_words="english", # 中文需替换为自定义停用词表
max_features=1000, # 小样本避免过拟合,限制特征数
lowercase=True
)
# 训练集特征转换(拟合+转换)
X_train_tfidf = tfidf.fit_transform(X_train)
# 测试集特征转换(仅转换,避免数据泄露)
X_test_tfidf = tfidf.transform(X_test)
# ===================== 3. 训练轻量分类器(逻辑回归) =====================
# 初始化逻辑回归(小样本参数配置)
lr = LogisticRegression(
C=0.5, # 正则化强度,小样本建议0.1~1
max_iter=300, # 迭代次数,确保收敛
random_state=42
)
# 训练模型
lr.fit(X_train_tfidf, y_train)
# ===================== 4. 粗判阶段:轻量算法预测+置信度计算 =====================
# 预测测试集的概率(置信度):返回[负面概率, 正面概率]
y_proba = lr.predict_proba(X_test_tfidf)
# 提取最大概率(置信度):每个样本的最高置信值
confidence = np.max(y_proba, axis=1)
# 轻量算法的分类结果
y_pred_lr = lr.predict(X_test_tfidf)
# 设定置信阈值(小样本建议0.8)
CONFIDENCE_THRESHOLD = 0.8
# 筛选高/低置信样本
high_conf_mask = confidence >= CONFIDENCE_THRESHOLD # 高置信样本掩码
low_conf_mask = confidence < CONFIDENCE_THRESHOLD # 低置信样本掩码
# 高置信样本:直接用轻量算法结果
high_conf_text = X_test[high_conf_mask]
high_conf_pred = y_pred_lr[high_conf_mask]
# 低置信样本:需要大模型精修
low_conf_text = X_test[low_conf_mask]
low_conf_indices = X_test[low_conf_mask].index # 记录低置信样本的索引
# ===================== 5. 大模型精修阶段(处理低置信样本) =====================
def llm_refine(text_list):
"""
大模型精修函数:处理低置信样本,返回精准分类结果
:param text_list: 低置信文本列表
:return: 大模型分类结果列表(1=正面,0=负面)
"""
refined_results = []
for text in text_list:
# Prompt设计(核心:明确规则+示例+简洁输出)
prompt = f"""
请完成情感分析任务,严格遵守以下规则:
1. 分类结果只能是1(正面)或0(负面);
2. 基于句子的整体语义判断,不要只看单个关键词;
3. 示例:
- 句子:这个产品不算差但也没多好 → 0
- 句子:虽然有瑕疵,但整体值得买 → 1
需要分析的句子:{text}
输出要求:只输出数字1或0,不要任何额外文字。
"""
try:
# 调用腾讯混元大模型
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{"role": "system", "content": "你是一个专业的情感分析助手,严格遵守分类规则。"},
{"role": "user", "content": prompt}
],
temperature=0.0,
max_tokens=10
)
# 提取结果并转换为数字
result = int(response.choices[0].message.content.strip())
refined_results.append(result)
except Exception as e:
# 异常处理:API调用失败时,启用模拟大模型(无API Key时用这个)
print(f"大模型调用失败,启用模拟模式:{e}")
# 模拟大模型结果(简单规则:含“但”“虽然”的句子按语义判断)
if "但" in text or "虽然" in text:
refined_results.append(1 if "值得" in text or "好" in text else 0)
else:
refined_results.append(1 if "好" in text or "推荐" in text else 0)
return refined_results
# 调用大模型精修低置信样本
if len(low_conf_text) > 0:
low_conf_pred = llm_refine(low_conf_text.tolist())
else:
low_conf_pred = []
# ===================== 6. 结果整合 =====================
# 初始化最终结果数组(默认用轻量算法结果)
y_pred_final = y_pred_lr.copy()
# 将大模型精修结果替换到低置信样本位置
y_pred_final[low_conf_mask] = low_conf_pred
# ===================== 7. 结果评估与可视化 =====================
# 计算准确率
lr_accuracy = accuracy_score(y_test, y_pred_lr) # 纯轻量算法准确率
final_accuracy = accuracy_score(y_test, y_pred_final) # 组合方案准确率
# 打印结果
print(f"纯逻辑回归准确率:{lr_accuracy:.2f}")
print(f"轻量+大模型准确率:{final_accuracy:.2f}")
print(f"低置信样本数量:{len(low_conf_text)} / {len(X_test)}")
print(f"大模型调用次数:{len(low_conf_text)}(成本降低{(1 - len(low_conf_text)/len(X_test))*100:.0f}%)")
# 可视化对比(准确率+调用成本)
labels = ["纯轻量算法", "轻量+大模型"]
accuracies = [lr_accuracy, final_accuracy]
cost_ratios = [1.0, len(low_conf_text)/len(X_test)] # 成本比例(纯大模型=1,组合方案=低置信比例)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
# 准确率对比
ax1.bar(labels, accuracies, color=["#ff7f7f", "#7fbf7f"])
ax1.set_ylabel("准确率")
ax1.set_ylim(0, 1)
ax1.set_title("准确率对比")
# 成本比例对比
ax2.bar(labels, cost_ratios, color=["#ffcc7f", "#7fccff"])
ax2.set_ylabel("相对成本(纯大模型=1)")
ax2.set_ylim(0, 1)
ax2.set_title("推理成本对比")
plt.tight_layout()
plt.show()输出结果:
纯逻辑回归准确率:1.00 轻量+大模型准确率:1.00 低置信样本数量:10 / 40 大模型调用次数:10(成本降低75%)
结果图示:
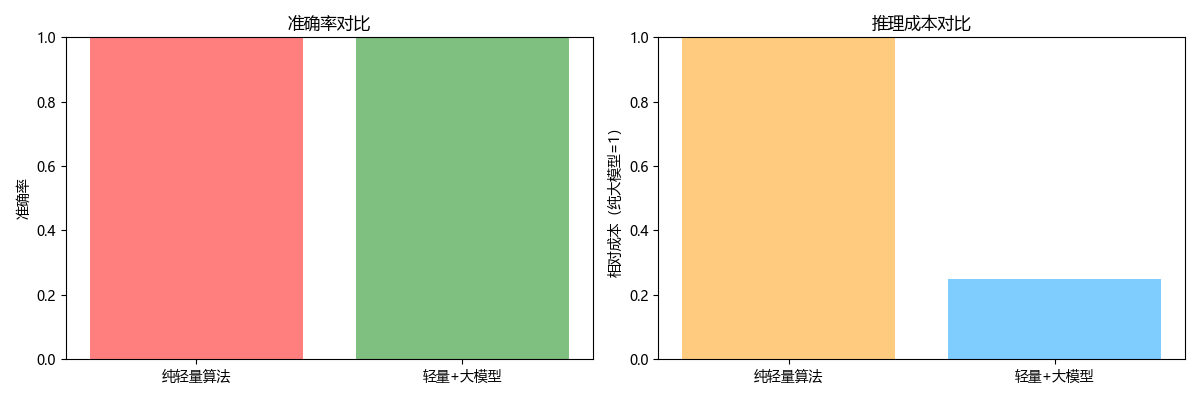
左图:组合方案的准确率和纯轻量算法一致; 右图:组合方案的成本仅为纯大模型的 25%(低 75%)。
六、总结
通过对轻量分类算法 + 混元大模型做小样本学习的理解,对AI落地有了特别实在的新感悟。以前总觉得大模型越用越高级,做分类任务就该直接全量调用,结果要么成本居高不下,要么小数据下结果忽稳忽乱;而纯靠传统轻量算法,又搞不定复杂语义,精度上不去。逐渐明白了技术不是越贵越好,而是搭配合理才最强。用逻辑回归、朴素贝叶斯这类轻量模型先做粗判,搞定大部分简单样本,只把拿不准的低置信样本交给大模型精修,这种分层处理的思路,完美平衡了速度、成本和准确率。大模型不再是全能苦力,而是专攻疑难样本的核心战力,把它的语义理解优势用到了刀刃上。
实操过程中小样本项目不用堆砌使用大模型,先拆分任务,轻量算法打底更稳;再就是置信度阈值要灵活调,平衡好调用成本和效果;也可以把大模型精修的结果回流,持续优化轻量模型,越用越顺手。其实我们对AI落地也要务实,懂得给技术分工,才能真正低成本、高效率地把方案跑通。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号