大模型应用:从粗排到混元大模型生成:交叉熵、余弦重排序的全流程实践.97
原创
大模型应用:从粗排到混元大模型生成:交叉熵、余弦重排序的全流程实践.97
原创
未闻花名
发布于 2026-05-05 10:24:28
发布于 2026-05-05 10:24:28
一、前言
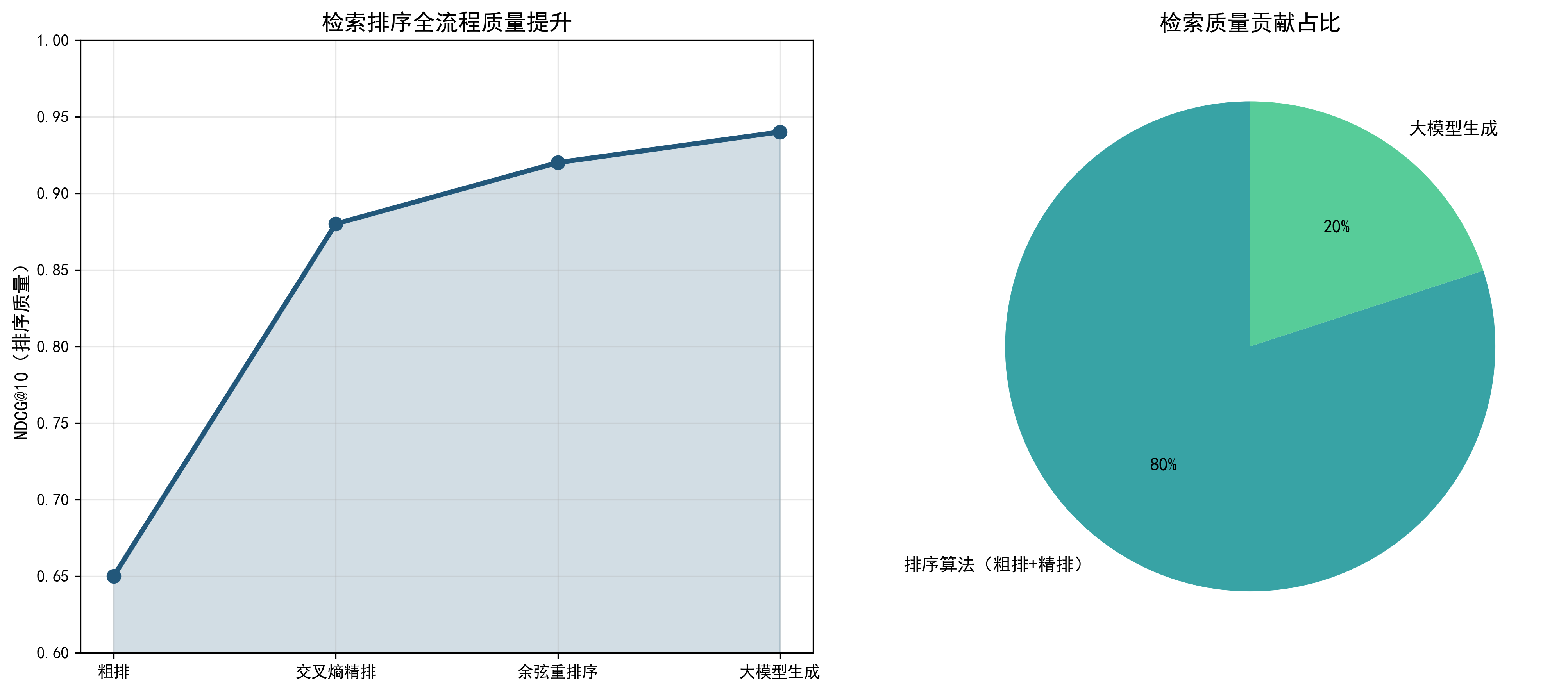
在推荐系统、问答系统、搜索引擎等依赖“检索 - 排序”的 AI 场景中,一个普遍被验证的结论是:检索质量的 80% 由排序算法决定,仅 20% 依赖大模型的最终优化。这并非否定大模型的价值,而是明确了“先算法精排、后大模型赋能”的核心逻辑,排序算法解决“把优质候选集筛选出来”的基础问题,大模型解决“把筛选后的结果打磨得更贴合人类需求”的增值问题。
今天我们结合核心概念、基础原理、执行流程,详细的梳理“粗排→算法精排(交叉熵排序 / 余弦重排序)→大模型生成”的完整体系,建立对检索排序的完整认知。

二、基础知识
1. 检索排序的核心目标
检索排序的本质是“从海量候选集中,按照与用户需求的匹配度输出最优结果序列”。比如:
- 推荐系统:从百万商品中,按“用户购买意愿”排序输出 Top10 商品;
- 问答系统:从千万知识库片段中,按“回答用户问题的准确性”排序输出 Top5 答案;
- 搜索引擎:从亿级网页中,按“与搜索词的相关性”排序输出 Top20 网页。
这个过程中,排序是核心,如果排序算法把优质候选集排在后面,哪怕大模型再强,也只能巧妇难为无米之炊;反之,排序算法筛选出高质量候选集后,大模型只需做精细化优化,就能让结果更贴合需求。
2. 检索排序的三层架构
2.1 粗排
粗排的核心目标是快速缩小候选集范围,要在海量数据中,用低成本、高效率的方式筛选出 Top N候选集,比如从100万条数据中筛选出1000条。
- 特点:速度快、计算成本低,排序精度不高;
- 常用方法:
- 简单规则排序:如按“点击量”、“收藏量”、“发布时间”等单一维度排序;
- 轻量级模型:如逻辑回归(LR)、FM(因子分解机),仅使用少量核心特征(如用户 ID、物品 ID、点击次数);
- 向量检索:用预训练的轻量级 Embedding 模型生成用户 / 物品向量,通过余弦相似度快速筛选出相似度较高的候选集。
2.2 算法精排
精排是检索排序的核心环节,为了提升排序准确性,也是决定 80% 检索质量的关键。它的目标是“在粗排的候选集基础上,用更复杂的算法和更丰富的特征,精准计算每个候选项的匹配度,输出 Top K 候选集”,比如从1000条中筛选出100条。
- 特点:计算精度高、使用特征丰富,速度略慢于粗排,但候选集已缩小,整体耗时可控;
- 核心精排算法:
- 交叉熵排序:基于“预测匹配标签”的损失函数优化排序模型,核心是让模型学会区分“正样本(匹配的候选项)”和“负样本(不匹配的候选项)”;
- 余弦重排序:基于向量余弦相似度,对精排结果做二次优化,解决“算法排序后仍存在的局部相似度偏差”。
2.3 大模型生成
大模型生成是精细化优化结果的最后一公里,目标是“在精排的 Top K 候选集基础上,结合用户需求生成更贴合人类语言习惯、更精准的最终结果”。
- 特点:不负责“筛选候选集”,只负责“优化候选集的呈现形式、内容细节”;
- 核心作用:
- 内容润色:将精排后的答案片段整合成流畅、易懂的自然语言;
- 意图对齐:结合用户的上下文需求,调整结果的优先级,比如用户问“新手怎么学 Python”,精排可能返回“基础语法”、“项目实战”、“视频教程”等候选项,大模型可根据“新手”这个关键词,优先强调“基础语法”并补充入门建议;
- 个性化生成:根据用户的历史偏好、语言风格,生成个性化的结果,比如对技术小白用通俗语言,对专业人士用技术术语。
2.4 大模型的核心作用
2.4.1 内容整合与润色
- 排序算法输出的是“候选项列表”,如10个答案片段,而用户需要的是完整、流畅的回答;
- 大模型能将碎片化的候选项整合成结构化、易理解的内容。
2.4.2 意图对齐与个性化
- 排序算法基于通用特征排序,如关键词匹配、历史点击,但无法精准捕捉用户的隐性意图;
- 大模型能通过理解用户问题的上下文,调整结果的优先级和内容。
2.4.3 自然语言交互与生成
- 排序算法输出的是“排序分数”或“候选项列表”,无法直接与用户交互;
- 大模型能以自然语言的形式输出结果,提升用户体验。
2.4.4 少量样本的排序优化
- 当标注数据不足时,大模型可通过提示词工程实现少量样本的排序优化,比如给大模型输入“以下是用户问题和候选答案,请按匹配度排序,并说明理由”;
- 大模型能基于自身的知识,对精排结果做微调。
2.5 排序算法与大模型的协同
未来的检索排序系统,会是“排序算法 + 大模型”的深度协同,而非谁替代谁:
- 排序算法的“模型化”:用大模型提取特征,如BERT提取文本特征,提升排序算法的精度;
- 大模型的“轻量化”:针对排序后的候选集,使用轻量化大模型,降低生成成本;
- 端到端训练:将粗排、精排、大模型生成整合到一个框架中,通过联合训练优化整体效果,如用强化学习,将用户对大模型生成结果的反馈,反向优化排序算法的参数。
3. 基础数学原理
3.1 余弦相似度
余弦相似度是余弦重排序的核心,用于衡量两个向量之间的 “方向相似度”,值越大表示越相似(范围:[-1,1])。假设存在两个向量 A=(a1, a2,..., an)和B=(b1 ,b2 ,...,bn),余弦相似度计算公式为:
- 通俗理解:把向量想象成“箭头”,余弦相似度就是两个箭头之间的夹角,夹角越小,相似度越高;夹角为 0° 时,相似度 = 1,表示完全相同;夹角为 90° 时,相似度 = 0,表示完全无关。
- 应用场景:在排序中,我们会把“用户需求”和“候选项”都转换成向量,通过计算余弦相似度衡量匹配度。
3.2 交叉熵损失
交叉熵是交叉熵排序的核心,用于衡量“模型预测概率分布”与“真实标签分布”之间的差异,值越小表示模型预测越准确。对于二分类场景(正样本/负样本),交叉熵损失公式为:
- 符号说明:
- yi:真实标签(正样本 = 1,负样本 = 0);
- pi:模型预测为正样本的概率;
- N:样本数量。
- 通俗理解:
- 如果样本是正样本(yi =1),模型预测概率pi越接近 1,损失越小;
- 如果是负样本(yi =0),pi越接近 0,损失越小。
- 交叉熵排序的核心是通过最小化这个损失,让模型学会给正样本更高的排序分数。
4. 排序算法决定80%的检索质量
举一个直观的例子:
- 坏情况:粗排 + 精排算法差,从100万条候选集中筛选出的100条里,只有10条是真正匹配用户需求的;此时哪怕大模型再强,也只能从这10条里选,最终结果的质量上限很低。
- 好情况:粗排 + 精排算法好,筛选出的100条里有90条是匹配的;此时大模型只需做简单的润色或排序微调,就能输出高质量结果。
大模型的核心能力是“生成和理解自然语言”,而非“从海量数据中筛选优质候选集”,筛选候选集需要的是“高效的算法 + 精准的特征工程”,这正是排序算法的强项。因此,检索质量的核心瓶颈在排序算法,而非大模型。
三、精排算法原理
1. 交叉熵排序原理
交叉熵排序是“有监督的排序算法”,核心是训练一个模型,通过交叉熵损失优化模型参数,让模型能给“匹配的候选项”输出更高的分数,给不匹配的输出更低的分数。
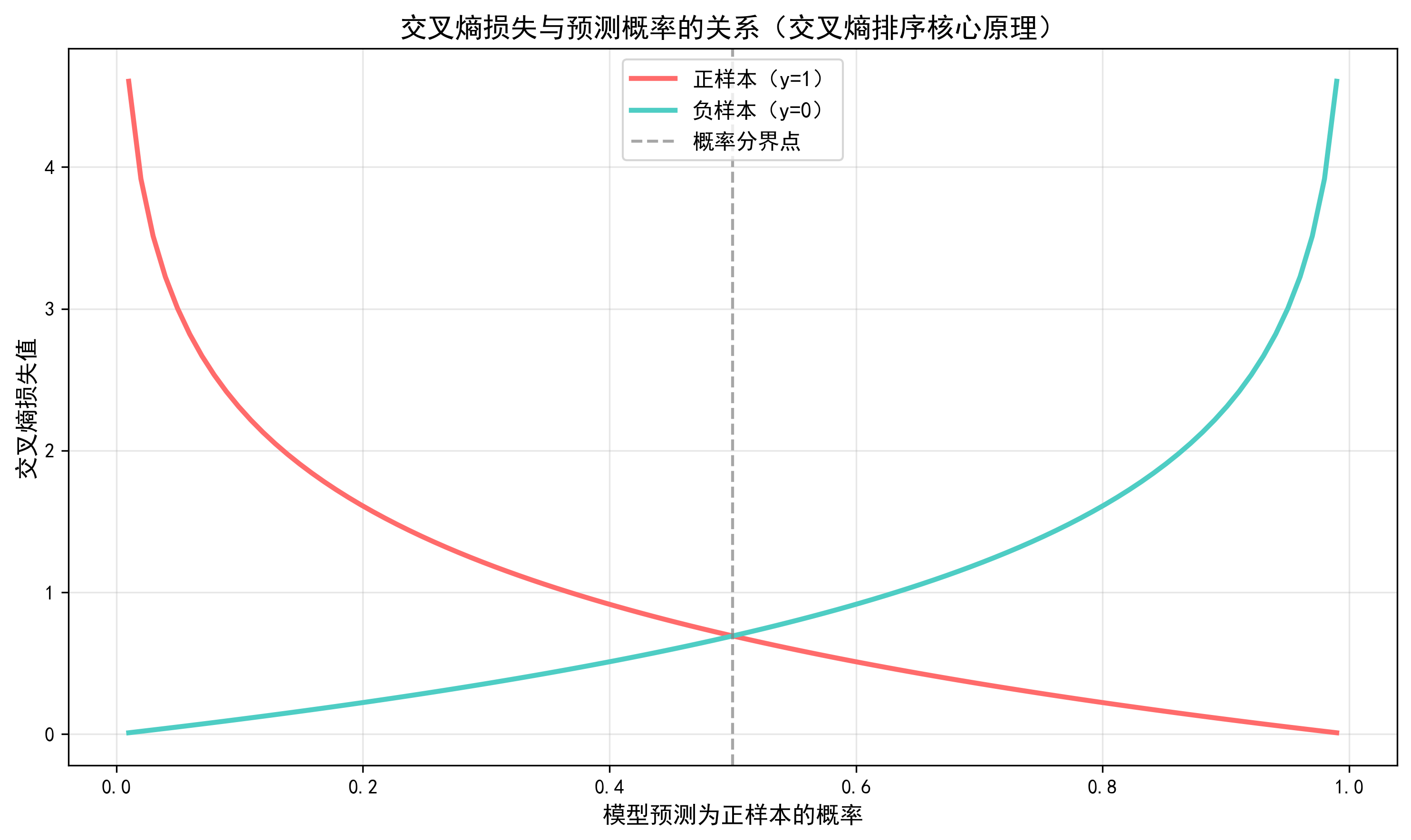
图示说明:正样本概率越接近 1、负样本概率越接近 0,损失越小
1.1 核心流程
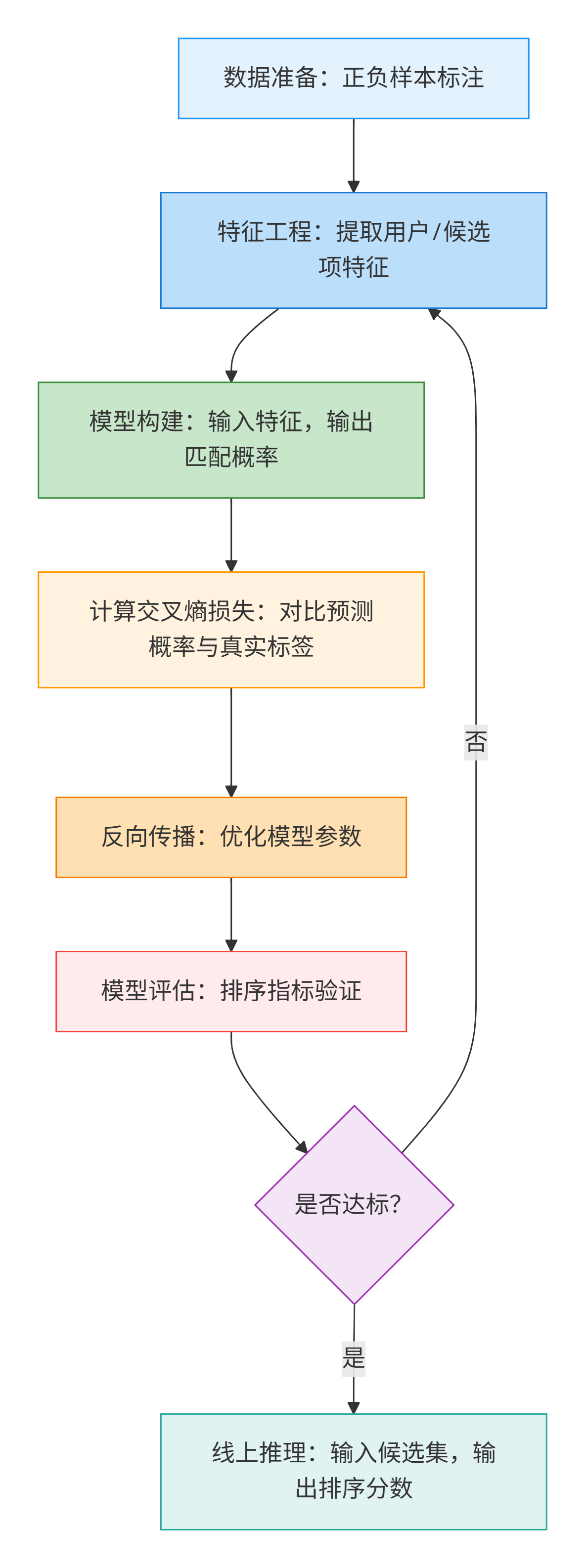
1.2 关键步骤
步骤 1:数据准备(正负样本标注)
- 正样本:与用户需求匹配的候选项,比如用户问“Python 怎么安装”,答案“Python 官网下载安装包的步骤” 就是正样本;
- 负样本:与用户需求不匹配的候选项,比如 “Java 安装步骤” 就是负样本;
- 标注原则:
- 正样本数量可以少,但必须精准;
- 负样本要多样化,比如随机负样本、难负样本(看似匹配但实际不匹配的样本),提升模型的区分能力。
步骤 2:特征工程(排序算法的灵魂)
特征是模型判断“匹配度”的依据,交叉熵排序常用的特征分为三类:
- 用户特征:用户 ID、历史点击或收藏记录、用户画像,如年龄、职业、兴趣标签;
- 候选项特征:候选项 ID、内容特征(如文本长度、关键词、分类标签)、统计特征(如点击量、点赞量);
- 交叉特征:用户与候选项的交互特征,如用户是否点击过该候选项、用户兴趣标签与候选项分类的匹配数。
举例:对于问答系统的答案排序,特征可以是:
- 答案特征:答案包含的关键词数量、答案长度、答案的历史采纳率
- 用户特征:用户是否是新手、用户的历史问题领域、用户的点赞偏好
- 交叉特征:答案关键词与用户问题关键词的重合数、答案领域与用户历史问题领域的匹配度
步骤 3:模型构建
交叉熵排序的模型可以是简单的线性模型(如 LR),也可以是复杂的深度学习模型(如 DNN、Transformer),核心是 “输入特征→输出匹配概率”。
以简单的 LR 模型为例:
- 模型公式:p=σ(W⋅X+b)
- X:特征向量;
- W:权重矩阵;
- b:偏置项;
- σ:sigmoid 函数,将输出映射到 [0,1],作为匹配概率。
- 模型输出的p就是“候选项与用户需求匹配的概率”,概率越高,排序越靠前。
步骤 4:损失计算与参数优化
将模型输出的概率p代入交叉熵损失公式,通过梯度下降算法最小化损失,更新权重W和偏置b。
梯度下降的核心逻辑:
- 计算损失对W和b的梯度,实际就是求导数;
- 按梯度的反方向更新参数:W=W−η⋅∇W(η是学习率);
- 重复迭代,直到损失收敛,不再明显下降。
步骤 5:模型评估
排序模型的评估不能用“准确率”,而是用“排序指标”,常用的有:
- MRR(Mean Reciprocal Rank):平均倒数排名,计算“第一个正确候选项的排名倒数的平均值”,值越大越好,范围:(0,1];
- NDCG@K(Normalized Discounted Cumulative Gain):归一化折损累计增益,衡量前 K 个结果的排序质量,值越大越好,范围:[0,1];
核心逻辑:排名越靠前的正确候选项,贡献的“增益”越高,排名靠后的增益被“折损”。
步骤 6:线上推理
训练好的模型部署后,输入粗排后的候选集特征,模型输出每个候选项的匹配概率,按概率从高到低排序,得到精排结果。
1.3 优缺点
- 优点:
- 1. 有监督学习,能充分利用标注数据,排序精度高;
- 2. 支持复杂特征和复杂模型,适配不同场景,包括推荐、问答、搜索;
- 3. 损失函数直观,优化目标明确,最小化预测与真实标签的差异。
- 缺点:
- 1. 依赖高质量的标注数据,标注成本高;
- 2. 模型训练和线上推理的计算成本高于规则排序;
- 3. 对特征工程的依赖度高,特征质量差会直接导致排序效果差。
2. 余弦重排序原理
余弦重排序是“无监督的二次排序算法”,核心是在交叉熵排序或其他精排算法的结果基础上,通过计算候选项之间的余弦相似度,调整排序顺序,解决算法排序后仍存在的局部相似度偏差。
2.1 余弦重排序的作用
交叉熵排序是“基于单个候选项与用户需求的匹配度”排序,但忽略了“候选项之间的相似性”,比如:
- 交叉熵排序输出的 Top5 结果中,第 2、3、4 名是高度相似的,比如都是“Python 安装的 Windows 步骤”,而第 5 名是“Python 安装的 Mac 步骤”,对使用 Mac 的用户更有价值;
- 此时如果直接输出,会导致结果冗余,且可能把更有价值的候选项排在后面;
- 余弦重排序通过计算候选项之间的相似度,合并冗余项、提升差异化高且匹配的候选项排名。
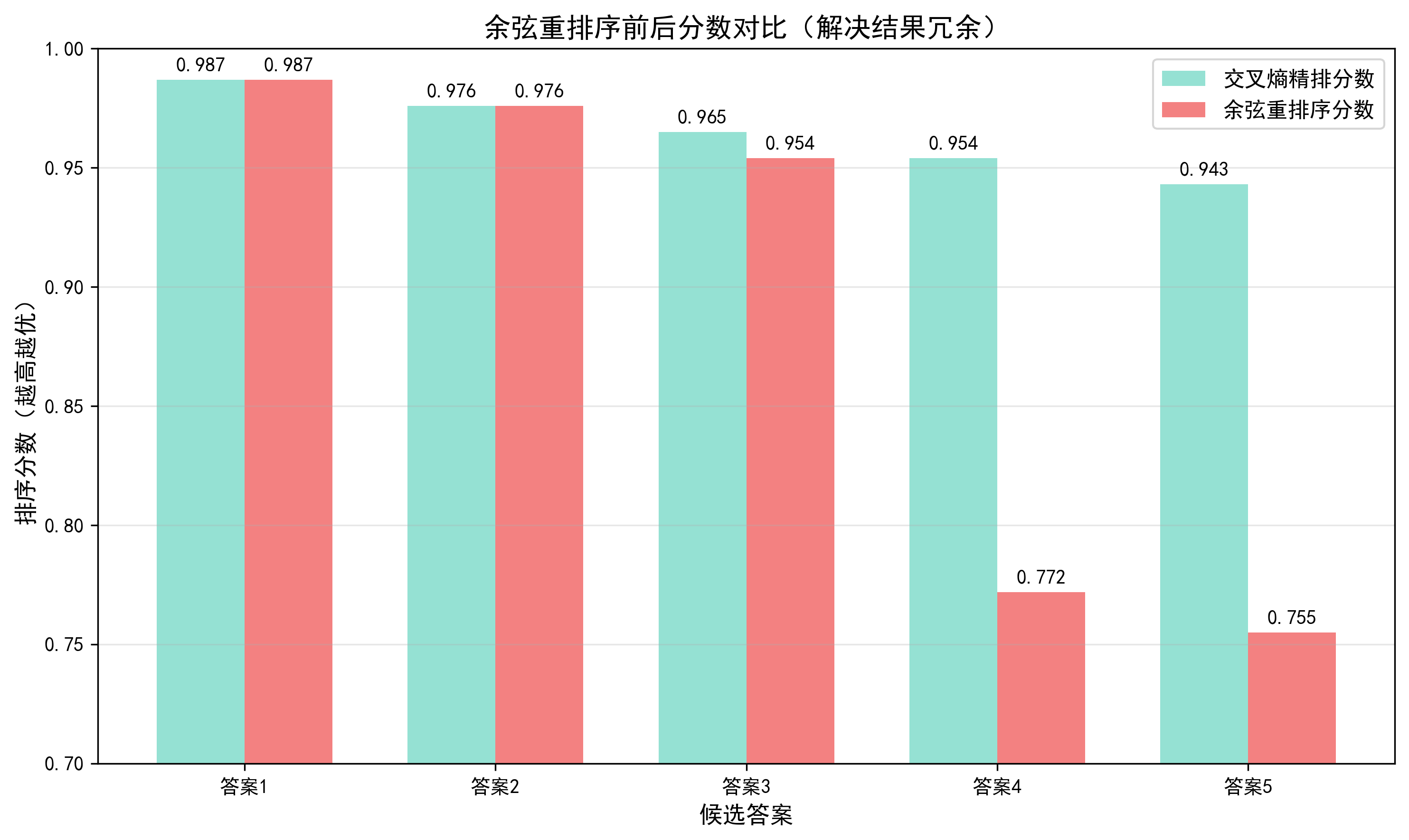
图示说明:余弦重排序对 “高相似度候选答案” 的分数惩罚效果,答案分数会下降
2.2 核心流程

2.3 关键步骤
步骤 1:候选项向量化
将每个候选项(如答案文本、商品描述)转换成固定维度的向量(Embedding),常用方法:
- 轻量级模型:Word2Vec、TF-IDF+PCA;
- 深度学习模型:BERT、RoBERTa、Sentence-BERT,专为句子向量设计,效果最优。
步骤 2:计算相似度矩阵
假设有K个候选项,生成K×K的相似度矩阵S,其中S_i,j表示第i个候选项和第j个候选项的余弦相似度。
步骤 3:相似度加权
核心思路:“惩罚”与前面候选项高度相似的项,“奖励”差异化高的项。常用加权公式:
- 符号说明:
- \text{score}'_i:重排序后的分数;
- \text{score}_i:交叉熵排序的原始分数;
- \alpha :惩罚系数,范围:0~1,越大惩罚越重;
- \max_{j<i} S_{ij}:第i个候选项与前面所有候选项的最大相似度。
- 通俗理解:如果第i个候选项和前面的候选项高度相似(maxSi,j大),则score_i′会降低;如果相似度低,则score_i′基本不变。
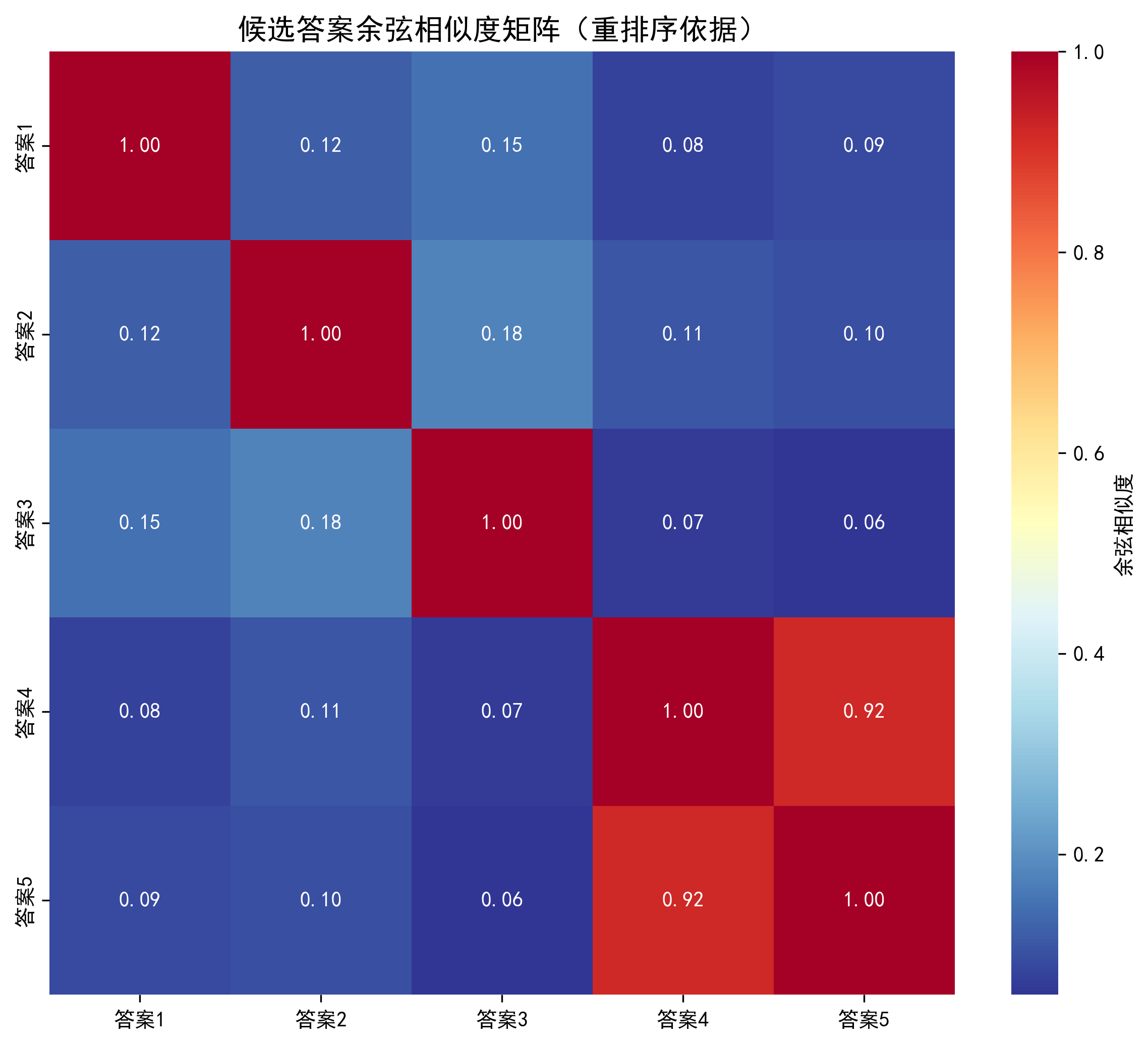
图示说明:这张热力图是余弦重排序的“决策依据”,它直观告诉我们:哪些候选答案是高度相似的,需要被“惩罚”。
- 矩阵里的数值范围是 0~1,越接近 1,代表两个答案的语义或内容越像;
- 答案 4 和答案 5 的相似度是 0.92,几乎快一模一样了,而它们和答案1/2/3的相似度只有 0.1 左右,完全不相关。
步骤 4:重新排序
按score_i′从高到低排序,得到余弦重排序后的结果。
2.4 优缺点
- 优点:
- 无监督学习,无需标注数据,部署成本低;
- 能有效解决结果冗余问题,提升排序的多样性;
- 计算速度快,候选集已缩小到 Top K,K通常≤100;
- 缺点:
- 依赖高质量的 Embedding 向量,向量质量差会导致重排序效果差;
- 惩罚系数α需要人工调参,不同场景的最优值不同;
- 仅做二次优化,无法弥补粗排、精排的核心误差。
3. 两者协同优势
将两种算法结合,能发挥 1+1>2 的效果:
- 交叉熵排序解决“核心匹配度”问题:确保筛选出的候选项与用户需求高度匹配;
- 余弦重排序解决“结果冗余”问题:确保排序结果的多样性,避免重复推荐或回答;
- 两者结合后,精排结果既精准又多样,为后续大模型生成打下坚实基础。
四、执行流程
以“问答系统答案排序”为例,完整流程如下:

流程说明:
- 1. 用户输入问题:接收用户自然语言查询,如“新手怎么学Python?”
- 2. 粗排(Top 1000):从海量知识库中快速检索,筛选出1000个相关答案,确保召回率
- 3. 交叉熵排序(Top 100):用更精确的模型计算语义匹配度,筛选出100个高质量答案
- 4. 余弦重排序(Top 10):计算答案间的语义相似度,增加多样性,避免内容重复
- 5. 大模型生成:整合Top 10答案的核心信息,生成连贯、完整的自然语言回复
- 6. 输出给用户:将最终生成的答案展示给用户
五、示例:从粗排到大模型生成
我们以问答系统示例,实现从粗排、算法精排(交叉熵排序、余弦重排序)、大模型生成的完整示例;
步骤 1:数据准备
我们模拟一个简单的问答知识库,包含“Python 学习”相关的答案:
import pandas as pd
import numpy as np
# 模拟问答知识库
knowledge_base = pd.DataFrame({
"answer_id": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15],
"answer_text": [
"Python安装需要下载官网安装包,安装时勾选Add Python to PATH",
"零基础学Python先学基础语法:变量、循环、条件判断",
"Python新手推荐廖雪峰教程、菜鸟教程、B站黑马视频",
"Python小项目推荐:计算器、简易爬虫、天气查询工具",
"Java安装需要下载JDK,配置环境变量", # 负样本
"Python进阶学习:函数、类、模块、异常处理",
"Python办公自动化:Excel处理、Word生成、邮件发送",
"C++基础语法:变量、循环、指针", # 负样本
"Python环境管理:Anaconda安装与使用",
"Python调试技巧:print调试、pdb调试工具",
"Python付费课程推荐:XX训练营、XX网课",
"机器学习入门:Python+Scikit-learn实现线性回归",
"Python书籍推荐:《Python编程:从入门到实践》",
"HTML基础语法:标签、属性、布局", # 负样本
"Python代码规范:PEP8规范、注释编写"
],
"label": [1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1] # 1=正样本,0=负样本
})
# 用户问题
user_question = "新手怎么学Python?"步骤 2:粗排(向量检索)
使用 Sentence-BERT 生成向量,FAISS 做向量检索:
from sentence_transformers import SentenceTransformer
from modelscope import snapshot_download
import faiss
cache_dir = "D:\\modelscope\\hub"
model_dir = snapshot_download(
model_id="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
cache_dir=cache_dir,
revision="master" # 或指定分支/commit
)
# 1. 加载Embedding模型(轻量级Sentence-BERT)
embedding_model = SentenceTransformer("D:\\modelscope\\hub\\sentence-transformers\\paraphrase-multilingual-MiniLM-L12-v2")
# 2. 知识库文本向量化
answer_texts = knowledge_base["answer_text"].tolist()
answer_embeddings = embedding_model.encode(answer_texts, convert_to_numpy=True)
# 3. 构建FAISS索引
dimension = answer_embeddings.shape[1] # 向量维度:384
index = faiss.IndexFlatL2(dimension) # 暴力检索(适合小数据集)
index.add(answer_embeddings)
# 4. 用户问题向量化
question_embedding = embedding_model.encode([user_question], convert_to_numpy=True)
# 5. 向量检索:筛选Top 10候选集(粗排)
k = 15 # 增大候选集,确保有足够的正负样本
distances, indices = index.search(question_embedding, k)
# 6. 提取粗排结果
rough_ranking_results = knowledge_base.iloc[indices[0]]
print("粗排结果:")
print(rough_ranking_results[["answer_id", "answer_text", "label"]])输出结果:
粗排结果: answer_id answer_text label 12 13 Python书籍推荐:《Python编程:从入门到实践》 1 5 6 Python进阶学习:函数、类、模块、异常处理 1 2 3 Python新手推荐廖雪峰教程、菜鸟教程、B站黑马视频 1 1 2 零基础学Python先学基础语法:变量、循环、条件判断 1 10 11 Python付费课程推荐:XX训练营、XX网课 1 11 12 机器学习入门:Python+Scikit-learn实现线性回归 1 3 4 Python小项目推荐:计算器、简易爬虫、天气查询工具 1 9 10 Python调试技巧:print调试、pdb调试工具 1 0 1 Python安装需要下载官网安装包,安装时勾选Add Python to PATH 1 14 15 Python代码规范:PEP8规范、注释编写 1 7 8 C++基础语法:变量、循环、指针 0 6 7 Python办公自动化:Excel处理、Word生成、邮件发送 1 8 9 Python环境管理:Anaconda安装与使用 1 13 14 HTML基础语法:标签、属性、布局 0 4 5 Java安装需要下载JDK,配置环境变量 0 标签分布:{1: 12, 0: 3}
步骤 3:交叉熵排序(精排)
使用逻辑回归模型,基于交叉熵损失训练,对粗排结果做精排:
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.preprocessing import StandardScaler
# 1. 特征工程:提取文本匹配特征
def extract_features(question_embedding, answer_embeddings, distances, answer_texts, user_question):
"""提取特征:向量相似度、向量距离、关键词重合数"""
# (1)向量余弦相似度
question_vec = question_embedding[0].reshape(1, -1)
cosine_sim = cosine_similarity(question_vec, answer_embeddings)[0]
# (2)向量距离(L2)
# distances 已经是L2距离了
# (3)关键词重合数(简单中文分词:按字符提取)
# 提取常见中文关键词
import re
question_keywords = set(re.findall(r'[\u4e00-\u9fa5]+|[a-zA-Z]+', user_question))
# 过滤掉标点和停用词
stop_words = {'怎么', '如何', '是', '的', '吗'}
question_keywords = question_keywords - stop_words
keyword_overlap = []
for text in answer_texts:
answer_keywords = set(re.findall(r'[\u4e00-\u9fa5]+|[a-zA-Z]+', text))
overlap = len(question_keywords & answer_keywords)
keyword_overlap.append(overlap)
# (4)特征合并:相似度越大越好,距离越小越好
# 距离取负值,使得距离越小分数越高
features = np.column_stack([cosine_sim, -distances, keyword_overlap])
return features
# 2. 为粗排结果提取特征
rough_answer_texts = rough_ranking_results["answer_text"].tolist()
rough_labels = rough_ranking_results["label"].values
rough_answer_embeddings = answer_embeddings[indices[0]]
features = extract_features(question_embedding, rough_answer_embeddings, distances[0], rough_answer_texts, user_question)
print(f"\n特征矩阵形状: {features.shape}")
print(f"特征列含义: [余弦相似度, -L2距离, 关键词重合数]")
print(f"前3个样本的特征:")
print(features[:3])
import re
question_keywords = set(re.findall(r'[\u4e00-\u9fa5]+|[a-zA-Z]+', user_question))
print(f"问题关键词: {question_keywords}")
# 3. 训练交叉熵排序模型(逻辑回归,损失函数为交叉熵)
# 使用 lbfgs 求解器,支持二分类
ranking_model = LogisticRegression(solver='lbfgs', random_state=42, max_iter=1000)
# 检查是否有足够的正负样本
if len(set(rough_labels)) < 2:
print("\n警告:粗排结果中只有一个类别,无法训练排序模型!")
print("直接使用粗排距离作为排序分数")
rough_ranking_results["fine_score"] = -distances[0] # 距离越小分数越高
else:
print(f"\n标签分布: {rough_labels}")
ranking_model.fit(features, rough_labels)
print(f"模型系数: {ranking_model.coef_}")
print(f"模型截距: {ranking_model.intercept_}")
# 4. 预测匹配概率(精排分数)
fine_ranking_scores = ranking_model.predict_proba(features)[:, 1] # 正样本概率
print(f"预测分数: {fine_ranking_scores[:5]}")
rough_ranking_results["fine_score"] = fine_ranking_scores
# 5. 精排结果:按分数排序,取Top 5
fine_ranking_results = rough_ranking_results.sort_values(by="fine_score", ascending=False).head(10)
print("\n交叉熵精排结果(Top 10):")
print(fine_ranking_results[["answer_id", "answer_text", "fine_score", "label"]])输出结果:
特征矩阵形状: (15, 3) 特征列含义: [余弦相似度, -L2距离, 关键词重合数] 前3个样本的特征: [[ 0.77090418 -7.90510368 1. ] [ 0.67816496 -10.6061821 1. ] [ 0.61285162 -12.32204628 1. ]] 问题关键词: {'新手怎么学', 'Python'} 标签分布: [1 1 1 1 1 1 1 1 1 1 0 1 1 0 0] 模型系数: [[0.0898246 0.34052198 0.78514702]] 模型截距: [8.38018606] 预测分数: [0.9985615 0.996369 0.99346778 0.99234575 0.99102127] 交叉熵精排结果(Top 10): answer_id answer_text fine_score label 12 13 Python书籍推荐:《Python编程:从入门到实践》 0.998562 1 5 6 Python进阶学习:函数、类、模块、异常处理 0.996369 1 2 3 Python新手推荐廖雪峰教程、菜鸟教程、B站黑马视频 0.993468 1 1 2 零基础学Python先学基础语法:变量、循环、条件判断 0.992346 1 10 11 Python付费课程推荐:XX训练营、XX网课 0.991021 1 11 12 机器学习入门:Python+Scikit-learn实现线性回归 0.982300 1 3 4 Python小项目推荐:计算器、简易爬虫、天气查询工具 0.979337 1 9 10 Python调试技巧:print调试、pdb调试工具 0.962889 1 0 1 Python安装需要下载官网安装包,安装时勾选Add Python to PATH 0.957313 1 14 15 Python代码规范:PEP8规范、注释编写 0.937097 1
步骤 4:余弦重排序
对精排结果做余弦重排序,优化多样性:
def cosine_re_ranking(candidates, embedding_model, alpha=0.8):
"""
余弦重排序
参数:
- candidates: 精排结果DataFrame,包含answer_text和fine_score
- embedding_model: Sentence-BERT模型
- alpha: 惩罚系数
返回:
- re_ranked_candidates: 重排序后的结果
"""
# 1. 候选项向量化
answer_texts = candidates["answer_text"].tolist()
embeddings = embedding_model.encode(answer_texts, convert_to_numpy=True)
# 2. 计算相似度矩阵
similarity_matrix = cosine_similarity(embeddings)
# 3. 初始化重排序分数
re_ranking_scores = candidates["fine_score"].values.copy()
# 4. 遍历每个候选项,计算加权分数
for i in range(1, len(re_ranking_scores)):
# 取当前项与前面所有项的最大相似度
max_similarity = np.max(similarity_matrix[i, :i])
# 加权分数
re_ranking_scores[i] = re_ranking_scores[i] * (1 - alpha * max_similarity)
# 5. 更新分数并排序
candidates["re_score"] = re_ranking_scores
re_ranked_candidates = candidates.sort_values(by="re_score", ascending=False)
return re_ranked_candidates
# 执行余弦重排序
re_ranked_results = cosine_re_ranking(fine_ranking_results, embedding_model, alpha=0.8)
print("\n余弦重排序结果:")
print(re_ranked_results[["answer_id", "answer_text", "fine_score", "re_score"]])输出结果:
余弦重排序结果: answer_id answer_text fine_score re_score 12 13 Python书籍推荐:《Python编程:从入门到实践》 0.998562 0.998562 0 1 Python安装需要下载官网安装包,安装时勾选Add... 0.957313 0.527326 9 10 Python调试技巧:print调试、pdb调试工具 0.962889 0.486215 11 12 机器学习入门:Python+Scikit-learn实现线性回归 0.982300 0.478992 3 4 Python小项目推荐:计算器、简易爬虫、天气查询工具 0.979337 0.471634 14 15 Python代码规范:PEP8规范、注释编写 0.937097 0.461750 1 2 零基础学Python先学基础语法:变量、循环、条件判断 0.992346 0.440093 10 11 Python付费课程推荐:XX训练营、XX网课 0.991021 0.414431 5 6 Python进阶学习:函数、类、模块、异常处理 0.996369 0.402303 2 3 Python新手推荐廖雪峰教程、菜鸟教程、B站黑马视频 0.993468 0.401953
步骤 5:大模型生成最终回答
以调用混元大模型为例,整合重排序结果生成最终回答:
import os
from openai import OpenAI
import json
# 配置混元大模型API Key(需替换为自己的)
api_key = os.environ.get('TENCENT_API_KEY', 'sk-*******************vZ5NP8Ze')
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
def generate_answer_with_llm(question, candidates):
"""
调用混元大模型生成最终回答
参数:
- question: 用户问题
- candidates: 重排序后的候选答案
"""
# 构建Prompt
candidate_texts = candidates["answer_text"].tolist()
prompt = f"""
请你结合以下候选答案,为用户问题"{question}"生成一个通俗易懂、结构清晰的回答。要求:
1. 优先保留核心步骤,去掉重复内容;
2. 语言风格适合新手,避免专业术语;
3. 结构分为"基础准备""学习步骤""推荐资源"三部分;
4. 回答长度控制在300字以内。
候选答案:
"""
for i, text in enumerate(candidate_texts, 1):
prompt += f"{i}. {text}\n"
try:
# 调用混元大模型
completion = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{'role': 'system', 'content': '你是一个知识问答助手,擅长用通俗易懂的语言解释技术问题'},
{'role': 'user', 'content': prompt}
],
temperature=0.7,
top_p=0.8
)
# 提取生成结果
return completion.choices[0].message.content
except Exception as e:
return f"生成失败:{str(e)}"
# 生成最终回答
final_answer = generate_answer_with_llm(user_question, re_ranked_results)
print("\n大模型生成的最终回答:")
print(final_answer)输出结果:
大模型生成的最终回答: ### 新手怎么学Python? #### 基础准备 首先,你需要准备一台可以运行Python的电脑,并且下载安装Python。你可以访问Python官方网站下载安装包,并在安装过程中勾选“Add Python to PATH”,这样你就可以直接在命令行中使用Python了。 #### 学习步骤 1. **学习基础语法**:了解Python的基本语法,包括变量、循环、条件判断等。 2. **阅读书籍**:推荐《Python编程:从入门到实践》,这本书适合初学者,内容通俗易懂。 3. **在线课程**:可以选择一些免费的零基础课程,比如廖雪峰教程、菜鸟教程或者B站上的黑马视频。 4. **实践项目**:通过做一些小项目来巩固学习成果,比如计算器、简易爬虫或天气查询工具。 5. **进阶学习**:当你对基础语法有一定了解后,可以进一步学习函数、类、模块和异常处理等内容。 #### 推荐资源 - **书籍**:《Python编程:从入门到实践》 - **在线课程**:廖雪峰教程、菜鸟教程、B站黑马视频 - **调试工具**:print调试和pdb调试工具 - **小项目**:计算器、简易爬虫、天气查询工具 通过以上步骤和资源,你可以系统地学习Python,并逐步提高自己的编程能力。
六、总结
通过对粗排→交叉熵精排→余弦重排序→大模型生成这套流程的深入了解,明白检索系统的核心,真的不在大模型,而在排序算法。真正决定 80% 质量的,是前面的排序环节:粗排负责快速缩小范围,交叉熵负责精准打分,余弦重排序解决冗余和多样性问题。这三步把靠谱的候选内容筛出来,后面大模型才有的发挥。如果前面算法拉胯,给大模型一堆垃圾内容,再强的模型也救不回来。简单点就是先把向量检索、精排模型跑通,再用大模型做最后一公里的润色和整合,性价比极高。
我们实际操作优先把特征、相似度、排序损失函数吃透,把精排效果做上去;重排序用来提升多样性,大模型只做锦上添花。不要一上来就全链路大模型,又慢又贵还不稳定。总而言之:排序算法是地基,大模型是装修。地基打好,房子才稳;装修到位,住着才舒服。把这套“算法为主、大模型为辅”的思路用熟,不管是做项目还是面试,都会非常有竞争力。
附录:完整的示例代码
import pandas as pd
import numpy as np
# 模拟问答知识库
knowledge_base = pd.DataFrame({
"answer_id": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15],
"answer_text": [
"Python安装需要下载官网安装包,安装时勾选Add Python to PATH",
"零基础学Python先学基础语法:变量、循环、条件判断",
"Python新手推荐廖雪峰教程、菜鸟教程、B站黑马视频",
"Python小项目推荐:计算器、简易爬虫、天气查询工具",
"Java安装需要下载JDK,配置环境变量", # 负样本
"Python进阶学习:函数、类、模块、异常处理",
"Python办公自动化:Excel处理、Word生成、邮件发送",
"C++基础语法:变量、循环、指针", # 负样本
"Python环境管理:Anaconda安装与使用",
"Python调试技巧:print调试、pdb调试工具",
"Python付费课程推荐:XX训练营、XX网课",
"机器学习入门:Python+Scikit-learn实现线性回归",
"Python书籍推荐:《Python编程:从入门到实践》",
"HTML基础语法:标签、属性、布局", # 负样本
"Python代码规范:PEP8规范、注释编写"
],
"label": [1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1] # 1=正样本,0=负样本
})
# 用户问题
user_question = "新手怎么学Python?"
from sentence_transformers import SentenceTransformer
from modelscope import snapshot_download
import faiss
cache_dir = "D:\\modelscope\\hub"
model_dir = snapshot_download(
model_id="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
cache_dir=cache_dir,
revision="master" # 或指定分支/commit
)
# 1. 加载Embedding模型(轻量级Sentence-BERT)
embedding_model = SentenceTransformer("D:\\modelscope\\hub\\sentence-transformers\\paraphrase-multilingual-MiniLM-L12-v2")
# 2. 知识库文本向量化
answer_texts = knowledge_base["answer_text"].tolist()
answer_embeddings = embedding_model.encode(answer_texts, convert_to_numpy=True)
# 3. 构建FAISS索引
dimension = answer_embeddings.shape[1] # 向量维度:384
index = faiss.IndexFlatL2(dimension) # 暴力检索(适合小数据集)
index.add(answer_embeddings)
# 4. 用户问题向量化
question_embedding = embedding_model.encode([user_question], convert_to_numpy=True)
# 5. 向量检索:筛选Top 10候选集(粗排)
k = 15 # 增大候选集,确保有足够的正负样本
distances, indices = index.search(question_embedding, k)
# 6. 提取粗排结果
rough_ranking_results = knowledge_base.iloc[indices[0]]
print("粗排结果:")
print(rough_ranking_results[["answer_id", "answer_text", "label"]])
print(f"\n标签分布:{rough_ranking_results['label'].value_counts().to_dict()}")
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.preprocessing import StandardScaler
# 1. 特征工程:提取文本匹配特征
def extract_features(question_embedding, answer_embeddings, distances, answer_texts, user_question):
"""提取特征:向量相似度、向量距离、关键词重合数"""
# (1)向量余弦相似度
question_vec = question_embedding[0].reshape(1, -1)
cosine_sim = cosine_similarity(question_vec, answer_embeddings)[0]
# (2)向量距离(L2)
# distances 已经是L2距离了
# (3)关键词重合数(简单中文分词:按字符提取)
# 提取常见中文关键词
import re
question_keywords = set(re.findall(r'[\u4e00-\u9fa5]+|[a-zA-Z]+', user_question))
# 过滤掉标点和停用词
stop_words = {'怎么', '如何', '是', '的', '吗'}
question_keywords = question_keywords - stop_words
keyword_overlap = []
for text in answer_texts:
answer_keywords = set(re.findall(r'[\u4e00-\u9fa5]+|[a-zA-Z]+', text))
overlap = len(question_keywords & answer_keywords)
keyword_overlap.append(overlap)
# (4)特征合并:相似度越大越好,距离越小越好
# 距离取负值,使得距离越小分数越高
features = np.column_stack([cosine_sim, -distances, keyword_overlap])
return features
# 2. 为粗排结果提取特征
rough_answer_texts = rough_ranking_results["answer_text"].tolist()
rough_labels = rough_ranking_results["label"].values
rough_answer_embeddings = answer_embeddings[indices[0]]
features = extract_features(question_embedding, rough_answer_embeddings, distances[0], rough_answer_texts, user_question)
print(f"\n特征矩阵形状: {features.shape}")
print(f"特征列含义: [余弦相似度, -L2距离, 关键词重合数]")
print(f"前3个样本的特征:")
print(features[:3])
import re
question_keywords = set(re.findall(r'[\u4e00-\u9fa5]+|[a-zA-Z]+', user_question))
print(f"问题关键词: {question_keywords}")
# 3. 训练交叉熵排序模型(逻辑回归,损失函数为交叉熵)
# 使用 lbfgs 求解器,支持二分类
ranking_model = LogisticRegression(solver='lbfgs', random_state=42, max_iter=1000)
# 检查是否有足够的正负样本
if len(set(rough_labels)) < 2:
print("\n警告:粗排结果中只有一个类别,无法训练排序模型!")
print("直接使用粗排距离作为排序分数")
rough_ranking_results["fine_score"] = -distances[0] # 距离越小分数越高
else:
print(f"\n标签分布: {rough_labels}")
ranking_model.fit(features, rough_labels)
print(f"模型系数: {ranking_model.coef_}")
print(f"模型截距: {ranking_model.intercept_}")
# 4. 预测匹配概率(精排分数)
fine_ranking_scores = ranking_model.predict_proba(features)[:, 1] # 正样本概率
print(f"预测分数: {fine_ranking_scores[:5]}")
rough_ranking_results["fine_score"] = fine_ranking_scores
# 5. 精排结果:按分数排序,取Top 5
fine_ranking_results = rough_ranking_results.sort_values(by="fine_score", ascending=False).head(10)
print("\n交叉熵精排结果(Top 10):")
print(fine_ranking_results[["answer_id", "answer_text", "fine_score", "label"]])
def cosine_re_ranking(candidates, embedding_model, alpha=0.8):
"""
余弦重排序
参数:
- candidates: 精排结果DataFrame,包含answer_text和fine_score
- embedding_model: Sentence-BERT模型
- alpha: 惩罚系数
返回:
- re_ranked_candidates: 重排序后的结果
"""
# 1. 候选项向量化
answer_texts = candidates["answer_text"].tolist()
embeddings = embedding_model.encode(answer_texts, convert_to_numpy=True)
# 2. 计算相似度矩阵
similarity_matrix = cosine_similarity(embeddings)
# 3. 初始化重排序分数
re_ranking_scores = candidates["fine_score"].values.copy()
# 4. 遍历每个候选项,计算加权分数
for i in range(1, len(re_ranking_scores)):
# 取当前项与前面所有项的最大相似度
max_similarity = np.max(similarity_matrix[i, :i])
# 加权分数
re_ranking_scores[i] = re_ranking_scores[i] * (1 - alpha * max_similarity)
# 5. 更新分数并排序
candidates["re_score"] = re_ranking_scores
re_ranked_candidates = candidates.sort_values(by="re_score", ascending=False)
return re_ranked_candidates
# 执行余弦重排序
re_ranked_results = cosine_re_ranking(fine_ranking_results, embedding_model, alpha=0.8)
print("\n余弦重排序结果:")
print(re_ranked_results[["answer_id", "answer_text", "fine_score", "re_score"]])
import os
from openai import OpenAI
import json
# 配置混元大模型API Key(需替换为自己的)
api_key = os.environ.get('TENCENT_API_KEY', 'sk-*************e')
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
def generate_answer_with_llm(question, candidates):
"""
调用混元大模型生成最终回答
参数:
- question: 用户问题
- candidates: 重排序后的候选答案
"""
# 构建Prompt
candidate_texts = candidates["answer_text"].tolist()
prompt = f"""
请你结合以下候选答案,为用户问题"{question}"生成一个通俗易懂、结构清晰的回答。要求:
1. 优先保留核心步骤,去掉重复内容;
2. 语言风格适合新手,避免专业术语;
3. 结构分为"基础准备""学习步骤""推荐资源"三部分;
4. 回答长度控制在300字以内。
候选答案:
"""
for i, text in enumerate(candidate_texts, 1):
prompt += f"{i}. {text}\n"
try:
# 调用混元大模型
completion = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{'role': 'system', 'content': '你是一个知识问答助手,擅长用通俗易懂的语言解释技术问题'},
{'role': 'user', 'content': prompt}
],
temperature=0.7,
top_p=0.8
)
# 提取生成结果
return completion.choices[0].message.content
except Exception as e:
return f"生成失败:{str(e)}"
# 生成最终回答
final_answer = generate_answer_with_llm(user_question, re_ranked_results)
print("\n大模型生成的最终回答:")
print(final_answer)原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号