大模型应用:从静态到动态:增量聚类+混元大模型破解无限流数据智能处理难题.98
原创
大模型应用:从静态到动态:增量聚类+混元大模型破解无限流数据智能处理难题.98
原创
未闻花名
发布于 2026-05-06 08:10:10
发布于 2026-05-06 08:10:10
一、前言
在大数据时代,无限流数据已成为企业和机构的核心数据资产,如实时产生的舆情信息、客服工单、系统日志,但这类数据具有无界性、实时性、非结构化三大特征,传统的批量聚类算法(如 K-Means)和人工标注模式已无法满足“边产生、边处理、边应用”的需求。而增量聚类算法与大模型的结合,恰好能解决这一棘手的难题,增量聚类实现数据流的动态聚类,大模型完成聚类结果的实时智能打标,让大模型从处理静态数据走向驾驭无限流数据。
今天我们就由浅入深拆解“增量聚类 + 大模型”的核心逻辑,了解其概念和原理、业务的执行流程、详细的示例实现,深入的理解这一技术组合的实践逻辑。

二、核心概念
1. 什么是无限流数据
1.1 定义与特征
无限流数据指的是持续产生、无固定边界、无法一次性加载到内存或磁盘中处理的数据,典型代表包括:
- 实时舆情:社交媒体每秒产生的评论、微博、小红书笔记;
- 实时工单:客服系统每分钟新增的用户咨询工单;
- 实时日志:服务器、APP 每秒输出的运行日志、错误日志。
这类数据有三个核心特征,也是传统处理方式的痛点:
特征 | 具体表现 | 传统批量处理的问题 |
|---|---|---|
实时性 | 数据产生后需秒级、分钟级处理,否则失去价值(如舆情热点需及时响应) | 批量算法需等待数据积累,无法实时输出结果 |
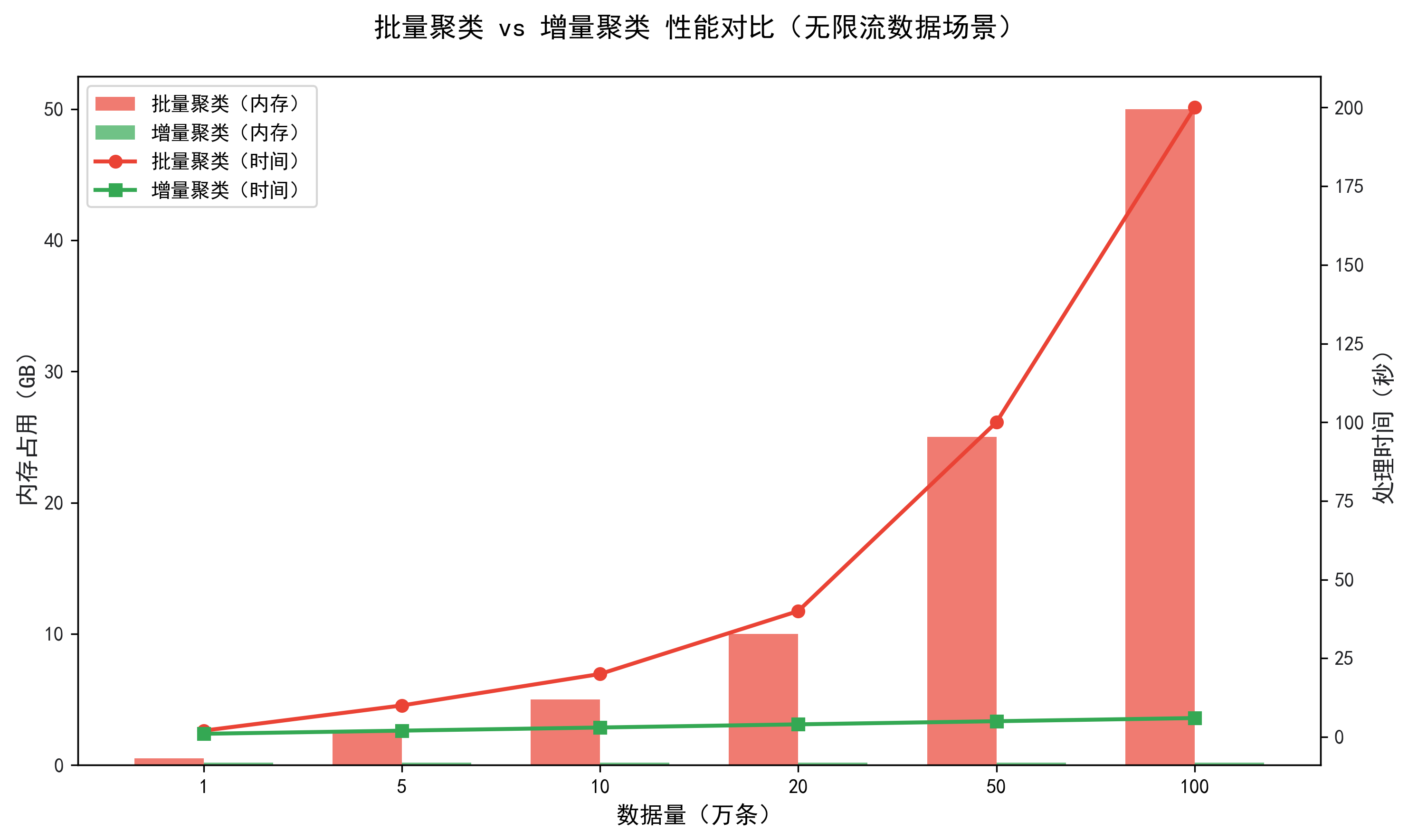
无界性 | 数据持续产生,总量无限,无法一次性加载到内存进行聚类、分析 | 批量聚类(如 K-Means)需全量数据,内存撑爆 |
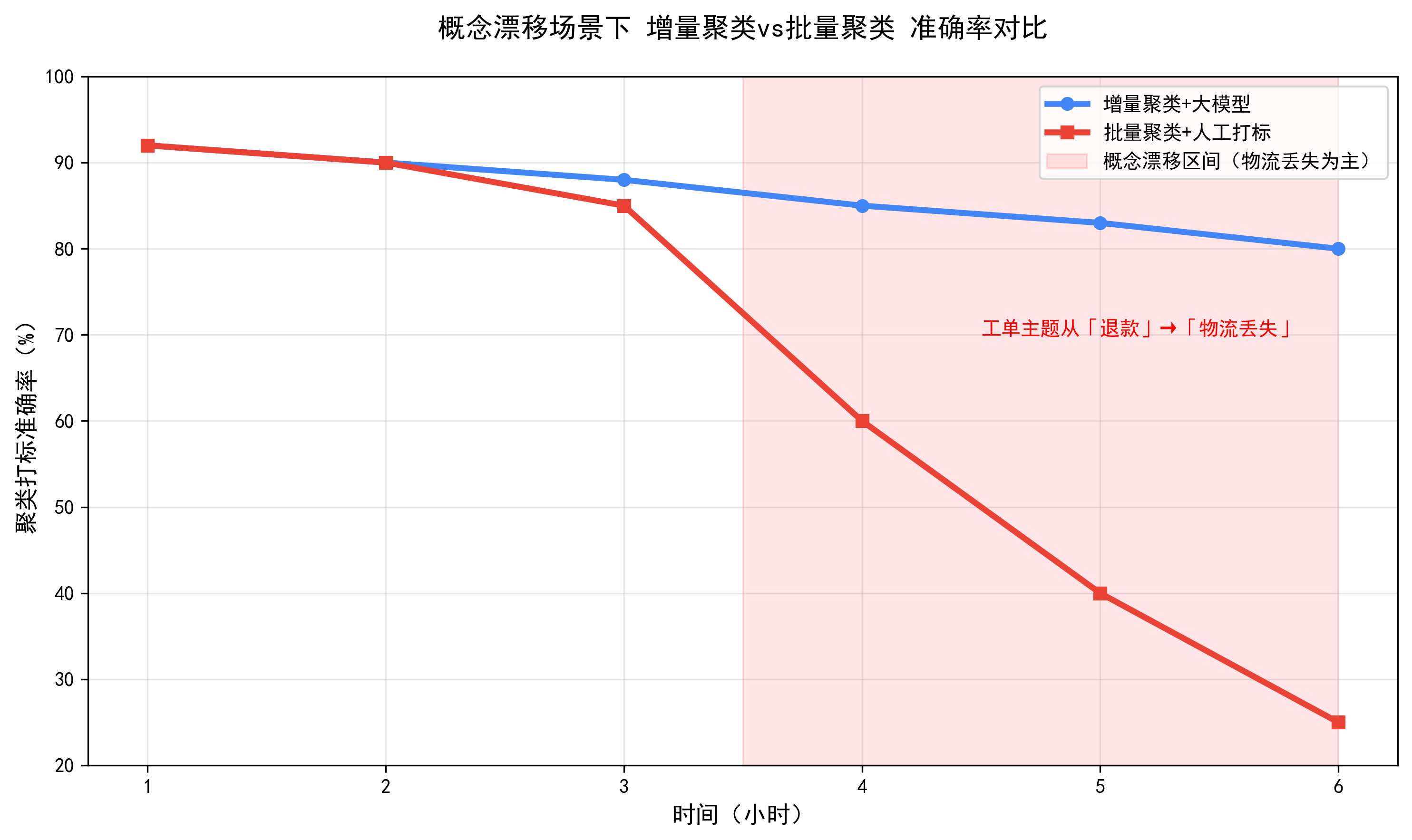
概念漂移 | 数据的分布、含义会随时间变化(如工单主题从 “退款” 变为 “物流”) | 批量模型训练后固定,无法适配数据分布变化 |
1.2 增量聚类 + 大模型的价值
传统方案的两个核心问题:
- 1. 聚类层面:批量聚类算法(K-Means、层次聚类)需要“先收集所有数据,再聚类”,无法处理持续流入的无限流数据;
- 2. 打标层面:聚类后的类别需要人工标注,如“聚类 1 = 退款问题”,效率低、成本高,且无法实时完成。
而“增量聚类 + 大模型”的组合恰好解决这两个问题:
- 增量聚类:数据来一条或一批,就更新一次聚类结果,无需等待全量数据,适配无限流;
- 大模型:聚类结果产生后,实时对类别进行语义化打标,如“该聚类包含100条工单,核心诉求是‘快递丢失理赔’”,替代人工,实现端到端自动化。
2. 增量聚类:动态更新的聚类算法
2.1 增量聚类的核心定义
增量聚类是一类“边接收数据、边更新聚类结构”的算法,核心目标是:在不重新计算全量数据的前提下,将新数据融入已有的聚类结果中。对比传统批量聚类,两者的核心差异如下:
2.1.1 批量聚类(如 K-Means)
- 数据处理方式:一次性输入全量数据,计算所有聚类中心
- 内存占用:需加载全量数据,内存占用随数据量线性增长
- 实时性:低,需等待数据收集完成
- 概念漂移适配:差,模型训练后固定,无法适配数据分布变化
- 计算效率:低,全量数据重新计算,时间复杂度高
2.1.2 增量聚类(如增量 K-Means、StreamKM++)
- 数据处理方式:分批次输入数据,每批数据更新聚类中心
- 内存占用:仅需保存聚类中心和少量统计信息,内存稳定
- 实时性:高,数据到即处理
- 概念漂移适配:好,可通过动态调整聚类中心适配分布变化
- 计算效率:高,仅计算新数据与现有聚类的距离
批量聚类 vs 增量聚类内存占用和处理时间的性能对比:
概念漂移场景下,批量聚类 vs 增量聚类的准确性对比:
2.2 增量聚类的核心思想
我们用整理书架的例子理解增量聚类:
- 批量聚类:先把所有书堆在地上,再按“小说、历史、科技”分类摆到书架上,重点:需一次性处理所有书;
- 增量聚类:书架上已经摆好了部分书,表示已经存在聚类,新买回来一本书,好比我们的新数据,直接对比这本书和书架上各类书的相似度,放到对应的格子里,融入现有聚类;如果这本书和所有格子的书都不相似,就新增一个格子,好比新增聚类。
增量聚类的核心操作只有三个:
- 1. 相似度计算:判断新数据与现有每个聚类中心的相似度,如欧式距离、余弦相似度;
- 2. 归属判断:如果相似度高于阈值,将新数据归入该聚类,并更新聚类中心,如取均值;
- 3. 新增聚类:如果所有相似度都低于阈值,以该新数据为核心,创建新聚类。
3. 大模型的核心角色
3.1 大模型不是聚类器,而是语义解析器
基于大模型的强大能力,我们考虑:“大模型能不能直接做增量聚类?” 答案是:不适合。
原因很简单:大模型的核心优势是“语义理解、自然语言生成”,而非“数值型聚类计算”。增量聚类的核心是“高效的距离计算、聚类中心更新”,这是传统算法的强项;而聚类后的“类别是什么意思”,是大模型的强项。
大模型在整个流程中的核心作用分为三类:
- 聚类前:数据预处理,将非结构化文本(如工单、舆情)转为向量(Embedding),如将“我的快递丢了,能理赔吗?”转为768维向量表示;
- 聚类后:聚类打标,对每个聚类的核心内容进行语义总结,生成人类可理解的标签,如聚类包含100条工单→标签:"快递丢失理赔咨询"
- 动态优化:概念漂移适配,当聚类分布变化时,重新解析聚类语义,调整标签,如工单主题从“快递丢失”变为“快递延迟”,需要更新标签
3.2 大模型处理无限流数据的关键:轻量化与实时性
大模型通常处理单条或批量文本,怎么处理无限流数据,核心是两个优化:
- 轻量化调用:不使用大模型处理每一条数据,而是处理“聚类结果”,每个聚类包含多条数据,大幅降低调用成本和延迟;
- 流式调用或批量调用:将短时间内的聚类结果批量传给大模型打标,如每分钟处理一次聚类结果,平衡实时性和成本;
- 缓存复用:对重复的聚类语义(如“退款问题”)缓存大模型的打标结果,避免重复调用。
简单来说:大模型处理的是“聚类后的聚合数据”,而非“原始无限流数据”,这是大模型能处理无限流数据的核心逻辑。
4. 概念总结
- 1. 无限流数据的核心特征是实时性、无界性、概念漂移,传统批量处理无法适配;
- 2. 增量聚类的核心是“边接收数据、边更新聚类”,无需全量数据,适配无限流;
- 3. 大模型的核心作用是“语义解析”:将聚类的数值结果转为人类可理解的标签,而非直接做聚类;
- 4. 两者结合的核心逻辑:增量聚类处理“无限流数据的动态分组”,大模型处理“分组结果的语义化”。
三、基础原理
1. 传统 K-Means 聚类的核心逻辑
要理解增量聚类,首先要掌握传统 K-Means 的核心步骤,因为增量 K-Means 是最易理解的增量聚类算法:
- 1. 初始化:随机选择 K 个数据点作为初始聚类中心;
- 2. 分配阶段:计算每个数据点到 K 个聚类中心的距离,将数据点分配到距离最近的聚类;
- 3. 更新阶段:重新计算每个聚类的中心,即所有数据点的均值;
- 4. 迭代:重复“分配 - 更新”,直到聚类中心不再变化。
K-Means 的核心问题:每次迭代都需要全量数据,如果数据是持续流入的,如每秒100条工单,无法每次都重新计算全量数据的聚类中心,这就是增量 K-Means 要解决的问题。
完整的细节可以参考往期文章《构建AI智能体:三十九、中文新闻智能分类:K-Means聚类与Qwen主题生成的融合应用》;
2. 增量 K-Means:最简的增量聚类算法
增量 K-Means 是传统 K-Means 的增量版本,核心思想是:不保存全量数据,只保存每个聚类的“统计信息”,包括聚类中心、数据点数量、总和,新数据到来时仅更新这些统计信息。 我们用公式和通俗解释结合的方式讲解:
2.1 核心统计信息
对每个聚类Ci,保存三个核心信息:
- ni:聚类Ci中已有的数据点数量;
- μi:聚类Ci的当前中心(向量);
- Si:聚类Ci中所有数据点的向量总和(Si =ni ×μi)。
2.2 新数据到来时的更新逻辑
假设新数据点为x(向量):
- 1. 步骤 1:分配:计算x到所有聚类中心μi的距离,如欧式距离,找到距离最近的聚类Cj;
- 2. 步骤 2:更新统计信息:
- 聚类Cj的数量:nj =nj +1;
- 聚类Cj的总和:Sj =Sj +x;
- 聚类Cj的新中心:μj =Sj/nj;
- 3. 步骤 3:判断是否新增聚类:如果x到所有聚类中心的距离都大于预设阈值,则新建一个聚类C_(k+1),其中n_(k+1) =1,S_(k+1) =x,μ_(k+1) =x。
2.3 通俗解释
还是用整理书架的例子:
- 现有聚类:书架上有 3 个格子(聚类),每个格子标注了“核心特征”(聚类中心),比如“小说格子”的核心特征是“虚构、故事、人物”;
- 新数据:新买回来一本书《三体》;
- 分配:对比《三体》和3个格子的核心特征,发现和“科幻小说格子”最像;
- 更新:把《三体》放进“科幻小说格子”,并更新格子的核心特征,加入“科幻、宇宙”;
- 新增聚类:如果新买回来的是一本《经济学原理》,和所有格子都不像,就新增一个“经济学格子”。
2.4 增量 K-Means 的优势与局限
优势:
- 内存占用低:仅保存聚类中心、数量、总和,无需保存全量数据;
- 实时性高:新数据到来后毫秒级更新聚类;
- 实现简单:基于传统 K-Means 改造,初学者易理解。
局限:
- 需要预设 K 值,即聚类数量,无法动态调整;
- 对“概念漂移”的适配性一般,聚类中心更新较慢;
- 对异常值敏感,单个异常数据可能新增不必要的聚类。
3. 更合适的增量聚类算法:StreamKM++
针对增量 K-Means 的局限,StreamKM++ 是专门为数据流设计的增量聚类算法,核心优化是:
- 动态 K 值:无需预设聚类数量,可根据数据分布动态新增、合并聚类;
- 分阶段处理:将数据分为“微批次”(Mini-Batch),先在本地聚类,再合并到全局聚类,平衡效率和精度;
- 离群点检测:自动过滤异常数据,如无意义的乱码工单,避免新增无效聚类。
StreamKM++ 的核心流程:

- 1. 缓冲阶段:收集一小批数据,如100条,称为“微批次”;
- 2. 局部聚类:对微批次数据做 K-Means 聚类,得到局部聚类中心;
- 3. 全局更新:将局部聚类中心与全局聚类中心对比,合并相似的聚类,更新全局统计信息;
- 4. 离群点清理:定期清理数据量过少的聚类,如仅包含1条数据的聚类,减少噪声。
StreamKM++ 是实际应用处理流数据的常用算法,比增量 K-Means 更实用,后续我们也会更深入的详细讲解。
四、执行流程
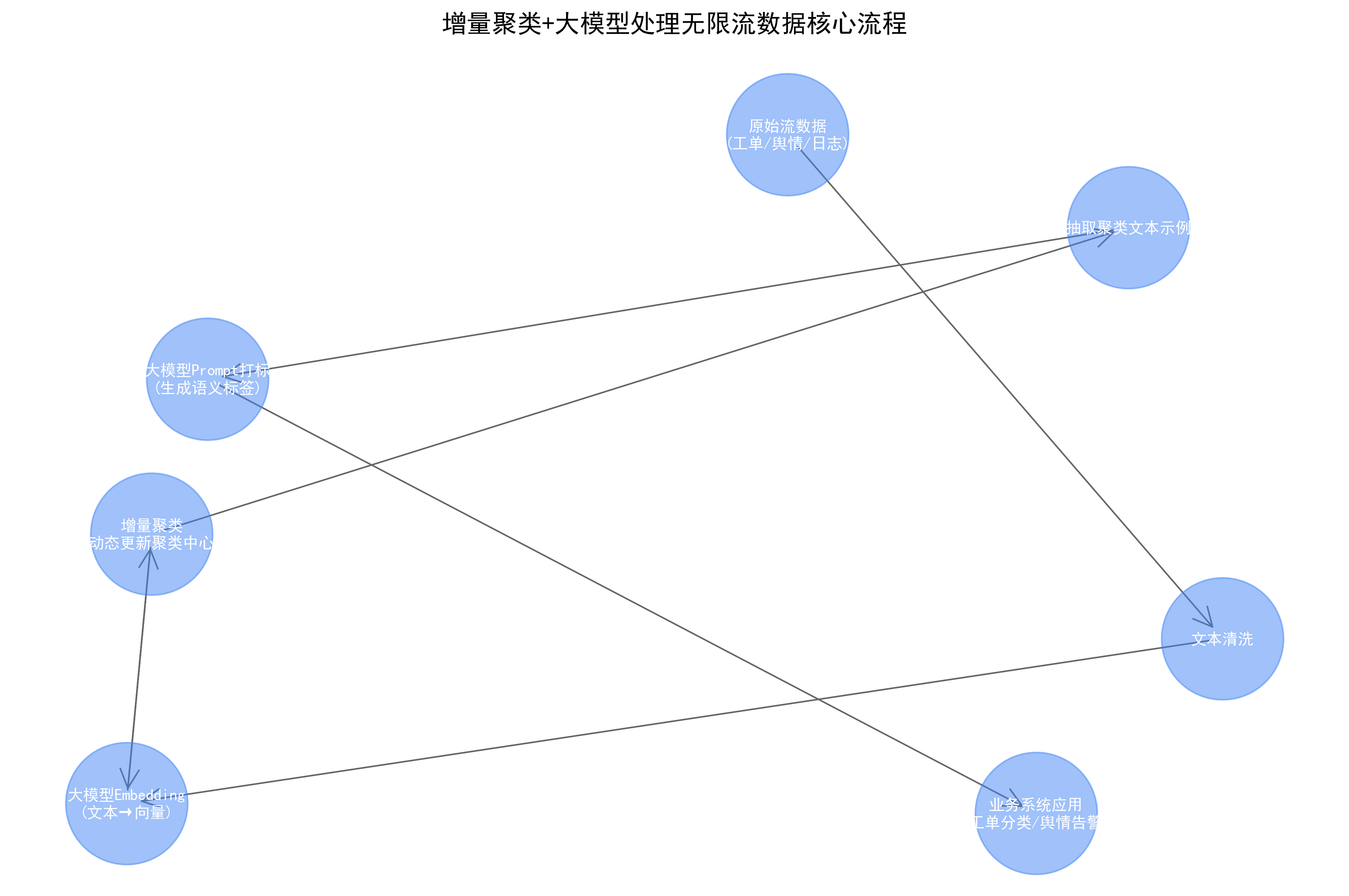
我们通过完整的执行流程,了解流程的核心特性:
- 闭环性:增量聚类的结果会实时更新聚类中心,适配新数据;业务反馈会优化聚类阈值,提升精度;
- 分层处理:大模型只处理“Embedding转换”和“打标”两个环节,增量聚类处理核心的分组逻辑;
- 实时性:每个环节都是流式处理,无需等待全量数据,适配无限流数据的实时需求。

流程说明:
- 1. 原始流数据:实时接入的原始文本数据流,如用户日志、客服对话、社交媒体帖文
- 2. 大模型Embedding转换:将原始文本通过大模型转换为高维语义向量,用于后续聚类计算
- 3. 增量聚类算法:对新数据向量进行实时聚类,支持动态更新已有聚类结果
- 4. 聚类结果:生成当前数据的聚类分组,每个分组包含语义相似的文本集合
- 5. 抽取聚类文本示例:从每个聚类中抽取代表性文本片段,如聚类中心附近样本,供打标使用
- 6. 大模型Prompt打标:将聚类示例输入大模型,通过Prompt工程自动生成聚类标签,如“退款咨询类”
- 7. 生成聚类标签:输出可读性强的聚类名称和描述,供业务系统直接使用
- 8. 业务系统应用:将带标签的聚类结果应用于业务场景,如客服工单分类、用户意图分析
- 9. 实时更新聚类中心:随着新数据不断流入,动态调整聚类中心位置,保持聚类准确性
- 10. 反馈优化聚类阈值:根据业务系统使用效果,调整聚类算法的距离阈值、密度参数等,形成闭环优化
五、示例:实时工单分类
步骤 1:需求定义与数据准备
- 1. 需求定义,明确业务目标:
- 处理对象:客服系统实时工单,每秒新增5-10条;
- 聚类目标:将工单按语义分组,每组对应一个业务问题;
- 打标目标:为每个聚类生成简洁的业务标签,如“快递丢失理赔”;
- 实时性要求:从工单产生到标签生成,延迟≤1 分钟。
- 2. 数据格式梳理,工单数据的典型格式(JSON):
{
"ticket_id": "10001",
"content": "我的快递丢了,已经3天了,能理赔吗?",
"create_time": "2026-02-25 10:00:01",
"user_id": "u89765"
}- 3. 数据预处理规则
- 过滤无效工单:内容为空、乱码、仅含标点的工单;
- 文本清洗:去除多余空格、特殊符号,如“!!!快递丢了!”→“快递丢了”;
- 去重:去除完全重复的工单,如用户重复提交的相同内容。
步骤 2:文本Embedding处理
from sentence_transformers import SentenceTransformer
from modelscope import snapshot_download
cache_dir = "D:\\modelscope\\hub"
model_dir = snapshot_download(
model_id="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
cache_dir=cache_dir,
revision="master" # 或指定分支/commit
)
# 1. 加载Embedding模型(轻量级Sentence-BERT)
model = SentenceTransformer("D:\\modelscope\\hub\\sentence-transformers\\paraphrase-multilingual-MiniLM-L12-v2")
def get_local_embedding(text):
"""本地生成Embedding向量"""
# 返回384维向量
embedding = model.encode(text, normalize_embeddings=True)
return embedding
# 测试
text = "我的快递丢了,能理赔吗?"
embedding = get_local_embedding(text)
print(f"Embedding向量长度:{len(embedding)}") 输出结果:
Embedding向量长度:384
步骤 3:增量聚类算法实现
我们选择 StreamKM++ 的简化版,MiniBatchKMeans,scikit-learn 内置,简单易实现
import numpy as np
from sklearn.cluster import MiniBatchKMeans
from sklearn.metrics import pairwise_distances_argmin_min
class IncrementalClustering:
def __init__(self, n_clusters=5, batch_size=100):
"""
初始化增量聚类器
:param n_clusters: 初始聚类数量
:param batch_size: 微批次大小
"""
self.n_clusters = n_clusters
self.batch_size = batch_size
# 初始化MiniBatchKMeans(增量K-Means)
self.cluster_model = MiniBatchKMeans(
n_clusters=n_clusters,
batch_size=batch_size,
random_state=42,
init_size=1000 # 初始聚类中心数量
)
# 保存每个聚类的文本示例(用于后续打标)
self.cluster_texts = {i: [] for i in range(n_clusters)}
# 保存聚类中心
self.cluster_centers = None
def update_cluster(self, embeddings, texts):
"""
增量更新聚类
:param embeddings: 新数据的Embedding向量列表(np.array)
:param texts: 对应的文本列表
:return: 聚类结果(每个数据的聚类标签)
"""
# 训练模型(增量更新)
labels = self.cluster_model.partial_fit(embeddings).predict(embeddings)
# 更新聚类中心
self.cluster_centers = self.cluster_model.cluster_centers_
# 保存每个聚类的文本示例(最多保存20条,避免内存占用)
for label, text in zip(labels, texts):
if len(self.cluster_texts[label]) < 20:
self.cluster_texts[label].append(text)
return labels
def get_cluster_examples(self):
"""获取每个聚类的文本示例"""
return self.cluster_texts
def get_nearest_text(self, center, texts):
"""获取离聚类中心最近的文本(最具代表性)"""
if len(texts) == 0:
return ""
# 计算距离
distances = pairwise_distances_argmin_min([center], texts)[1][0]
# 找到最近的文本
nearest_idx = np.argmin(distances)
return texts[nearest_idx]代码解释:
- __init__:初始化 MiniBatchKMeans 模型,设置聚类数量和批次大小;
- update_cluster:核心增量更新方法,接收新数据的 Embedding 和文本,更新聚类结果;
- get_cluster_examples:获取每个聚类的文本示例,用于后续大模型打标;
- get_nearest_text:找到每个聚类最具代表性的文本,即离中心最近的,提升打标精度。
步骤 4:大模型打标实现
我们基于混元大模型实现聚类打标,Prompt 设计是核心:
def cluster_labeling(cluster_examples):
"""
对聚类结果进行打标(使用腾讯混元大模型)
:param cluster_examples: 每个聚类的文本示例(dict,{聚类标签: [文本1, 文本2,...]})
:return: 聚类标签映射({聚类标签: 打标结果})
"""
from openai import OpenAI
# 配置混元API
api_key = 'sk-bWlJPKjBrSFGoQ0Ys***********************'
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
label_mapping = {}
for cluster_id, examples in cluster_examples.items():
if len(examples) == 0:
label_mapping[cluster_id] = "未知主题"
continue
# 构建Prompt
prompt = f"""
你是一个专业的客服工单分类分析师,需要根据以下文本示例总结聚类的核心内容:
文本示例:
{chr(10).join([f"- {text}" for text in examples[:10]])}
总结要求:
1. 用不超过20个字的标题概括聚类核心内容;
2. 标题要简洁、准确,符合客服工单场景;
3. 避免模糊表述,如"其他问题""未知主题";
4. 核心要突出用户诉求,如"快递丢失理赔咨询""退款申请处理"。
"""
try:
# 调用混元大模型
completion = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{'role': 'system', 'content': '你是一个专业的客服工单分类分析师'},
{'role': 'user', 'content': prompt}
],
temperature=0.1,
max_tokens=50
)
# 提取打标结果
label = completion.choices[0].message.content.strip()
label_mapping[cluster_id] = label
except Exception as e:
print(f"聚类{cluster_id}打标失败:{e}")
label_mapping[cluster_id] = f"未识别-{cluster_id}"
return label_mapping代码解释:
- cluster_labeling:接收聚类文本示例,为每个聚类生成标签;
- Prompt 设计要点:明确角色(客服工单分析师)、给出示例、限定输出要求(长度、准确性);
- 温度参数(temperature):设置为 0.1,确保输出结果稳定,避免同一聚类生成不同标签。
步骤 5:流数据接收与处理
import time
import json
# 1. 模拟流数据生成(初学者测试用)
def generate_simulated_tickets():
"""生成模拟工单数据"""
ticket_templates = [
"我的快递丢了,能理赔吗?",
"快递延迟了3天,要求赔偿",
"退款申请提交后,商家不处理",
"商品质量有问题,要求退货",
"物流信息不更新,怎么办?"
]
while True:
# 随机选择模板生成工单
content = np.random.choice(ticket_templates)
ticket = {
"ticket_id": f"sim_{int(time.time())}",
"content": content,
"create_time": time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()),
"user_id": f"u_{np.random.randint(1000, 9999)}"
}
yield ticket
# 模拟每秒生成1条工单
time.sleep(1)
# 2. 流数据处理主逻辑
def stream_processing():
"""实时流数据处理"""
# 初始化增量聚类器
clusterer = IncrementalClustering(n_clusters=5, batch_size=10)
# 缓存批次数据(每10条处理一次)
batch_embeddings = []
batch_texts = []
batch_size = 10
# 生成模拟数据
ticket_generator = generate_simulated_tickets()
for ticket in ticket_generator:
text = ticket["content"]
# 清洗文本
text = text.strip().replace("!", "").replace("?", "")
if not text:
continue
# 获取Embedding
embedding = get_local_embedding(text)
if embedding is None:
continue
# 添加到批次
batch_embeddings.append(embedding)
batch_texts.append(text)
# 批次满了,更新聚类
if len(batch_embeddings) >= batch_size:
# 转换为numpy数组
embeddings_np = np.array(batch_embeddings)
# 增量更新聚类
labels = clusterer.update_cluster(embeddings_np, batch_texts)
# 获取聚类示例,打标
cluster_examples = clusterer.get_cluster_examples()
label_mapping = cluster_labeling(cluster_examples)
# 输出结果
print(f"\n=== 批次处理结果({time.strftime('%Y-%m-%d %H:%M:%S')})===")
for i, (text, label) in enumerate(zip(batch_texts, labels)):
print(f"工单{i+1}:{text} → 聚类{label} → 标签:{label_mapping[label]}")
# 清空批次
batch_embeddings = []
batch_texts = []
# 启动处理
if __name__ == "__main__":
stream_processing()代码解释:
- generate_simulated_tickets:生成模拟工单数据,模拟实时流;
- stream_processing:核心处理逻辑,每收集10条工单,批次大小,更新一次聚类并打标;
- 输出结果:打印每条工单的聚类标签和大模型生成的业务标签,方便查看。
输出结果:
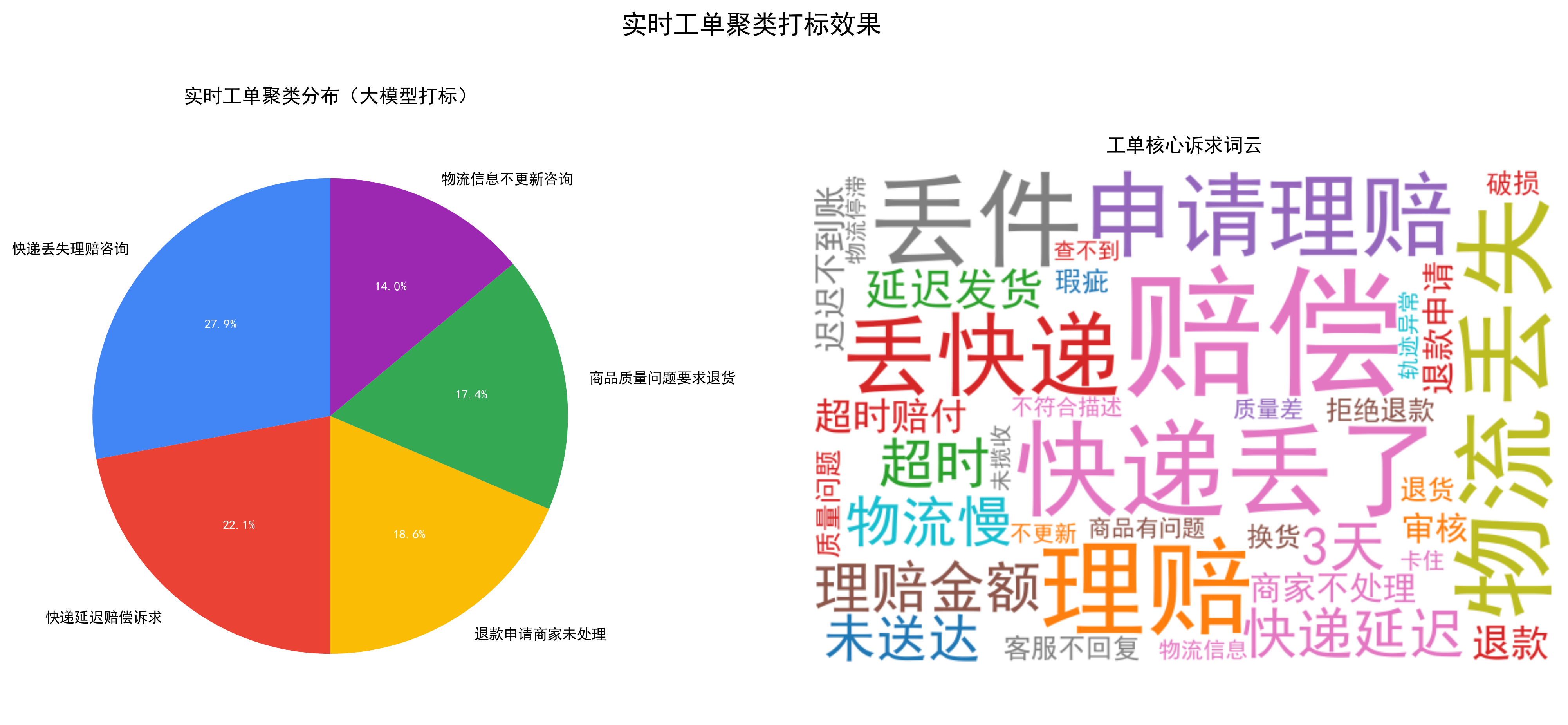
=== 批次处理结果(2026-02-25 22:45:45)=== 工单1:商品质量有问题,要求退货 → 聚类1 → 标签:商品质量问题,要求退换货 工单2:退款申请提交后,商家不处理 → 聚类3 → 标签:退款申请商家未处理 工单3:我的快递丢了,能理赔吗 → 聚类2 → 标签:快递丢失理赔咨询 工单4:物流信息不更新,怎么办 → 聚类0 → 标签:物流信息更新问题 工单5:快递延迟了3天,要求赔偿 → 聚类4 → 标签:快递延误赔偿 工单6:我的快递丢了,能理赔吗 → 聚类2 → 标签:快递丢失理赔咨询 工单7:退款申请提交后,商家不处理 → 聚类3 → 标签:退款申请商家未处理 工单8:我的快递丢了,能理赔吗 → 聚类2 → 标签:快递丢失理赔咨询 工单9:商品质量有问题,要求退货 → 聚类1 → 标签:商品质量问题,要求退换货 工单10:商品质量有问题,要求退货 → 聚类1 → 标签:商品质量问题,要求退换货 === 批次处理结果(2026-02-25 22:46:01)=== 工单1:快递延迟了3天,要求赔偿 → 聚类4 → 标签:快递延误赔偿 工单2:我的快递丢了,能理赔吗 → 聚类2 → 标签:快递丢失理赔咨询 工单3:物流信息不更新,怎么办 → 聚类0 → 标签:物流信息更新问题 工单4:我的快递丢了,能理赔吗 → 聚类2 → 标签:快递丢失理赔咨询 工单5:退款申请提交后,商家不处理 → 聚类3 → 标签:退款申请超时未处理 工单6:快递延迟了3天,要求赔偿 → 聚类4 → 标签:快递延误赔偿 工单7:快递延迟了3天,要求赔偿 → 聚类4 → 标签:快递延误赔偿 工单8:退款申请提交后,商家不处理 → 聚类3 → 标签:退款申请超时未处理 工单9:退款申请提交后,商家不处理 → 聚类3 → 标签:退款申请超时未处理 工单10:我的快递丢了,能理赔吗 → 聚类2 → 标签:快递丢失理赔咨询 ........
步骤 6:结果输出与业务集成
聚类和打标结果需要输出到业务系统,如工单管理平台,可以通过 Flask 搭建简易 API:
from flask import Flask, jsonify
app = Flask(__name__)
# 全局变量保存最新的聚类标签映射
latest_label_mapping = {}
@app.route("/api/cluster_labels", methods=["GET"])
def get_cluster_labels():
"""获取最新的聚类标签"""
return jsonify({
"status": "success",
"timestamp": time.strftime("%Y-%m-%d %H:%M:%S"),
"data": latest_label_mapping
})
# 修改stream_processing中的打标部分,更新全局变量
def stream_processing():
global latest_label_mapping
# ... 原有逻辑 ...
label_mapping = cluster_labeling(cluster_examples)
# 更新全局变量
latest_label_mapping = label_mapping
# ... 原有逻辑 ...
# 启动Flask服务
if __name__ == "__main__":
# 多线程启动:一个线程处理流数据,一个线程启动Flask服务
import threading
t = threading.Thread(target=stream_processing)
t.start()
app.run(host="0.0.0.0", port=5000)访问http://localhost:5000/api/cluster_labels即可获取最新的聚类标签结果,业务系统可通过 API 调用集成。
六、总结
通过对增量聚类结合大模型应用的完整了解,最大的感悟就是技术融合才是破局关键。以前单纯的认为大模型只能处理静态文本,增量聚类只是单纯的算法工具,没想到两者结合,居然能解决无限流数据这个难题,让大模型从离线工具变成了实时引擎。我们不用一开始就追求复杂的算法,先把核心逻辑吃透,增量聚类负责 动态分组,大模型负责语义翻译,一步步来反而更稳。建议先从模拟数据入手,把代码跑通,再替换成真实数据,慢慢优化参数和 Prompt。
在实际项目落地时不用盲目追求高精尖,优先用轻量化模型和批量处理,平衡好实时性和成本才是关键。技术的价值终究是落地到业务,把这个组合用在舆情、工单这些场景里,真正解决实际问题,才是学习的意义。
附录:完整示例代码
from sentence_transformers import SentenceTransformer
from modelscope import snapshot_download
cache_dir = "D:\\modelscope\\hub"
model_dir = snapshot_download(
model_id="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
cache_dir=cache_dir,
revision="master" # 或指定分支/commit
)
# 1. 加载Embedding模型(轻量级Sentence-BERT)
model = SentenceTransformer("D:\\modelscope\\hub\\sentence-transformers\\paraphrase-multilingual-MiniLM-L12-v2")
def get_local_embedding(text):
"""本地生成Embedding向量"""
# 返回384维向量
embedding = model.encode(text, normalize_embeddings=True)
return embedding
# 测试
text = "我的快递丢了,能理赔吗?"
embedding = get_local_embedding(text)
print(f"Embedding向量长度:{len(embedding)}")
import numpy as np
from sklearn.cluster import MiniBatchKMeans
from sklearn.metrics import pairwise_distances_argmin_min
class IncrementalClustering:
def __init__(self, n_clusters=5, batch_size=100):
"""
初始化增量聚类器
:param n_clusters: 初始聚类数量
:param batch_size: 微批次大小
"""
self.n_clusters = n_clusters
self.batch_size = batch_size
# 初始化MiniBatchKMeans(增量K-Means)
self.cluster_model = MiniBatchKMeans(
n_clusters=n_clusters,
batch_size=batch_size,
random_state=42,
init_size=1000 # 初始聚类中心数量
)
# 保存每个聚类的文本示例(用于后续打标)
self.cluster_texts = {i: [] for i in range(n_clusters)}
# 保存聚类中心
self.cluster_centers = None
def update_cluster(self, embeddings, texts):
"""
增量更新聚类
:param embeddings: 新数据的Embedding向量列表(np.array)
:param texts: 对应的文本列表
:return: 聚类结果(每个数据的聚类标签)
"""
# 训练模型(增量更新)
labels = self.cluster_model.partial_fit(embeddings).predict(embeddings)
# 更新聚类中心
self.cluster_centers = self.cluster_model.cluster_centers_
# 保存每个聚类的文本示例(最多保存20条,避免内存占用)
for label, text in zip(labels, texts):
if len(self.cluster_texts[label]) < 20:
self.cluster_texts[label].append(text)
return labels
def get_cluster_examples(self):
"""获取每个聚类的文本示例"""
return self.cluster_texts
def get_nearest_text(self, center, texts):
"""获取离聚类中心最近的文本(最具代表性)"""
if len(texts) == 0:
return ""
# 计算距离
distances = pairwise_distances_argmin_min([center], texts)[1][0]
# 找到最近的文本
nearest_idx = np.argmin(distances)
return texts[nearest_idx]
def cluster_labeling(cluster_examples):
"""
对聚类结果进行打标(使用腾讯混元大模型)
:param cluster_examples: 每个聚类的文本示例(dict,{聚类标签: [文本1, 文本2,...]})
:return: 聚类标签映射({聚类标签: 打标结果})
"""
from openai import OpenAI
# 配置混元API
api_key = 'sk-bW**********************5NP8Ze'
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
label_mapping = {}
for cluster_id, examples in cluster_examples.items():
if len(examples) == 0:
label_mapping[cluster_id] = "未知主题"
continue
# 构建Prompt
prompt = f"""
你是一个专业的客服工单分类分析师,需要根据以下文本示例总结聚类的核心内容:
文本示例:
{chr(10).join([f"- {text}" for text in examples[:10]])}
总结要求:
1. 用不超过20个字的标题概括聚类核心内容;
2. 标题要简洁、准确,符合客服工单场景;
3. 避免模糊表述,如"其他问题""未知主题";
4. 核心要突出用户诉求,如"快递丢失理赔咨询""退款申请处理"。
"""
try:
# 调用混元大模型
completion = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{'role': 'system', 'content': '你是一个专业的客服工单分类分析师'},
{'role': 'user', 'content': prompt}
],
temperature=0.1,
max_tokens=50
)
# 提取打标结果
label = completion.choices[0].message.content.strip()
label_mapping[cluster_id] = label
except Exception as e:
print(f"聚类{cluster_id}打标失败:{e}")
label_mapping[cluster_id] = f"未识别-{cluster_id}"
return label_mapping
import time
import json
# 1. 模拟流数据生成(初学者测试用)
def generate_simulated_tickets():
"""生成模拟工单数据"""
ticket_templates = [
"我的快递丢了,能理赔吗?",
"快递延迟了3天,要求赔偿",
"退款申请提交后,商家不处理",
"商品质量有问题,要求退货",
"物流信息不更新,怎么办?"
]
while True:
# 随机选择模板生成工单
content = np.random.choice(ticket_templates)
ticket = {
"ticket_id": f"sim_{int(time.time())}",
"content": content,
"create_time": time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()),
"user_id": f"u_{np.random.randint(1000, 9999)}"
}
yield ticket
# 模拟每秒生成1条工单
time.sleep(1)
# 2. 流数据处理主逻辑
def stream_processing():
"""实时流数据处理"""
# 初始化增量聚类器
clusterer = IncrementalClustering(n_clusters=5, batch_size=10)
# 缓存批次数据(每10条处理一次)
batch_embeddings = []
batch_texts = []
batch_size = 10
# 生成模拟数据
ticket_generator = generate_simulated_tickets()
for ticket in ticket_generator:
text = ticket["content"]
# 清洗文本
text = text.strip().replace("!", "").replace("?", "")
if not text:
continue
# 获取Embedding
embedding = get_local_embedding(text)
if embedding is None:
continue
# 添加到批次
batch_embeddings.append(embedding)
batch_texts.append(text)
# 批次满了,更新聚类
if len(batch_embeddings) >= batch_size:
# 转换为numpy数组
embeddings_np = np.array(batch_embeddings)
# 增量更新聚类
labels = clusterer.update_cluster(embeddings_np, batch_texts)
# 获取聚类示例,打标
cluster_examples = clusterer.get_cluster_examples()
label_mapping = cluster_labeling(cluster_examples)
# 输出结果
print(f"\n=== 批次处理结果({time.strftime('%Y-%m-%d %H:%M:%S')})===")
for i, (text, label) in enumerate(zip(batch_texts, labels)):
print(f"工单{i+1}:{text} → 聚类{label} → 标签:{label_mapping[label]}")
# 清空批次
batch_embeddings = []
batch_texts = []
# 启动处理
if __name__ == "__main__":
stream_processing()原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号