大模型应用:TextRank+混元大模型:轻量化算法与大模型协同的文本摘要实践.99
原创
大模型应用:TextRank+混元大模型:轻量化算法与大模型协同的文本摘要实践.99
原创
未闻花名
发布于 2026-05-07 08:00:00
发布于 2026-05-07 08:00:00
一、前言
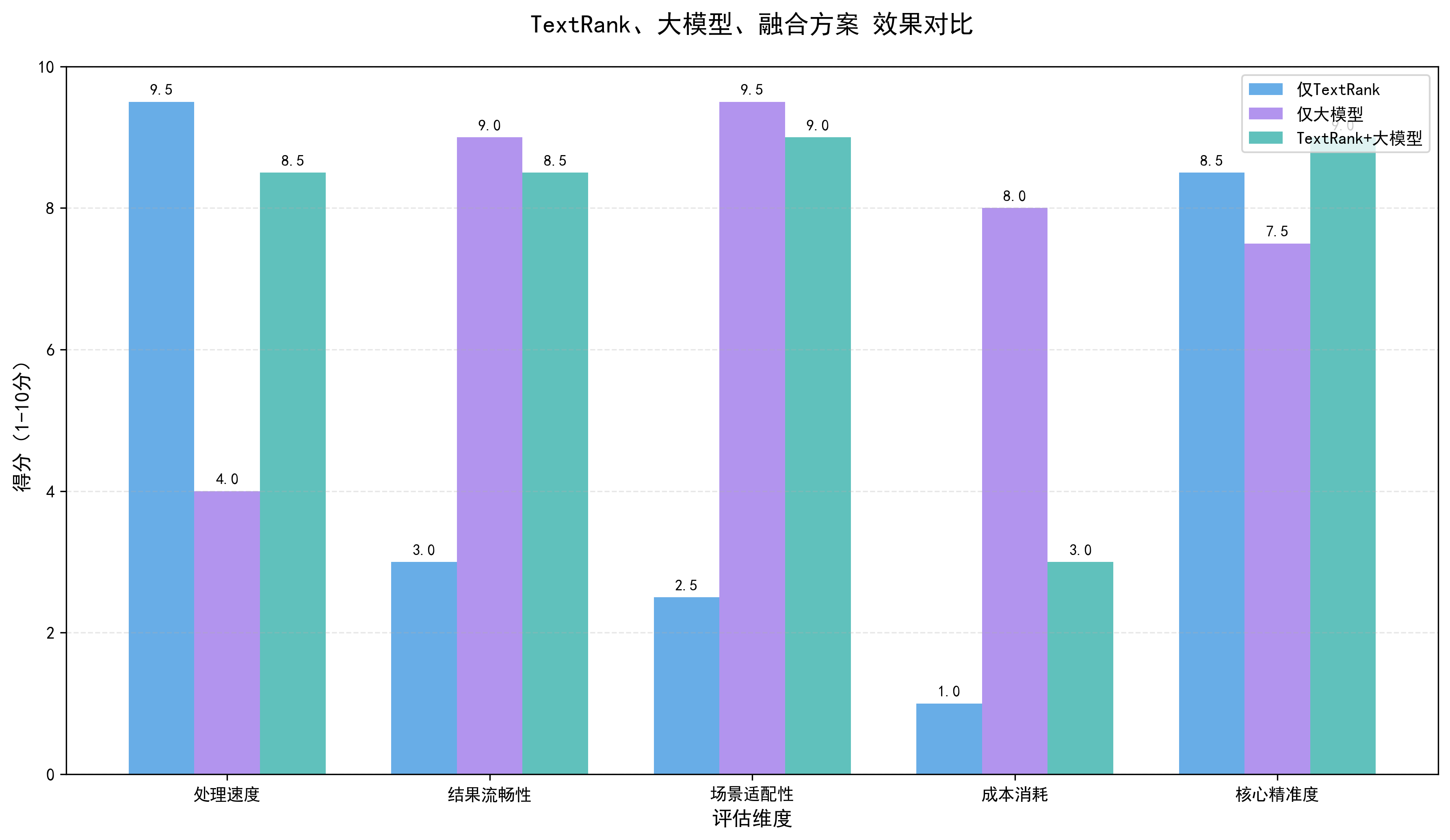
在信息爆炸的时代,我们通常会经历的场景,论文写作、会议记录、文章阅读,长文本的高效处理成为刚需,我们既需要快速抓住文本核心,了解整体的框架纲领形成粗摘,又需要得到流畅、精准、符合场景需求的优质摘要,达到精摘。单纯依赖轻量算法(如TextRank)虽能快速提取核心信息,但结果往往生硬、碎片化;单纯依赖大模型虽能生成优质文本,但成本高、易出现幻觉且对长文本处理效率低。
今天我们根据这些核心场景,结合“TextRank 算法做粗摘 + 大模型做精摘、润色”的融合方案,梳理核心概念、讲解基础原理、落地具体实现,一起探索这一高效的文本处理方案。

二、核心概念
1. 文本摘要的核心
文本摘要的本质是在保留核心语义的前提下,将长文本压缩为短文本;关键词提取则是从文本中筛选出最能代表内容核心的词汇或短语。二者是自然语言处理NLP中最基础也最实用的任务,常见应用场景包括:
- 学术场景:论文摘要自动生成、文献核心观点提取;
- 办公场景:会议记录要点总结、工作报告精简;
- 内容创作:长文核心观点提炼、自媒体文案浓缩;
- 信息检索:搜索引擎结果摘要、知识库内容标签化。
对于这些场景,我们有两个核心诉求:
- 效率:处理速度快、资源消耗低,尤其面对海量长文本;
- 质量:摘要或关键词精准、流畅、符合人类阅读习惯,无冗余、无遗漏。
单纯的轻量算法或大模型都无法同时满足这两个诉求:
- 轻量算法(如 TextRank、TF-IDF):速度快、资源消耗低,但生成的摘要碎片化,关键词可能存在语义孤立问题;
- 大模型:生成的文本流畅、语义完整,但处理长文本时速度慢、token 消耗高,且易因上下文过载丢失核心信息。
因此,轻量算法做粗摘,抓核心,并结合大模型做精摘,润色扩展成为兼顾效率与质量的最优解,这也是今天我们要阐明的核心思想。
2. 粗摘:轻量算法输出
“粗摘”是轻量算法对文本的初步处理结果,本文以TextRank为例,具备以下特征:
- 核心导向:只保留文本中权重最高的句子或词汇,不追求流畅性;
- 形式特征:句子可能是碎片化的,比如直接截取原文句子,关键词可能是孤立的,无上下文关联;
- 核心价值:快速过滤冗余信息,锁定文本核心骨架,为大模型处理缩小范围。
例如,对一篇5000字的论文,TextRank粗摘可能提取出5-8个核心句子,总计约500字,或10-15个核心关键词,这些内容是论文的骨架,但直接阅读体验差。
3. 精摘:大模型输出
“精摘”是大模型基于粗摘结果,结合场景需求生成的最终摘要或关键词,具备以下特征:
- 质量导向:在保留粗摘核心信息的基础上,优化语言表达、补充语义关联、适配场景需求;
- 形式特征:句子流畅、逻辑连贯,关键词附带简短解释,符合人类阅读习惯;
- 核心价值:将“机器提取的核心”转化为“人类可直接使用的优质内容”。
例如,基于上述论文的500字粗摘,大模型可以分点或段落形式生成200字左右的流畅摘要,或10个带简短释义的关键词,直接用于论文投稿、文献综述等场景。
4. TextRank 算法
TextRank是一种基于图论的无监督排序算法:
- 核心思想是“投票机制”,文本中的句子或词汇作为图的节点,节点间的关联度作为边的权重,通过迭代计算节点的“重要性”权重,最终筛选出权重最高的节点作为核心句子或关键词。
- 它的核心优势是:无需训练数据,无监督、计算速度快、适配任意语言,仅需基础的文本分词,是轻量粗摘的首选算法。
5. 大模型LLM
大语言模型是基于海量文本数据训练的深度学习模型,具备强大的自然语言理解和自然语言生成能力,核心优势是:
- 理解语义:能精准理解粗摘内容的核心含义;
- 生成优质文本:能将碎片化的粗摘转化为流畅、符合场景的精摘;
- 灵活扩展:可根据需求调整输出形式,如“学术风格”、“口语化风格”、“分点总结”。
6. 融合方案的优势
对于初次接触而言,选择“TextRank + 大模型”的融合方案,有三个核心优势:
- 降低学习门槛:无需深入掌握大模型的复杂调参、部署技巧,先通过简单的 TextRank 算法实现能提取核心,再借助大模型的 API 快速实现优质输出,循序渐进;
- 降低落地成本:TextRank 仅需基础 Python 环境即可运行,大模型可直接调用 API,无需本地部署,无需昂贵的算力资源;
- 提升实用价值:相比单纯用 TextRank 生成能用但不好用的结果,或单纯用大模型生成好用但贵且慢的结果,融合方案兼顾能用和好用,可直接落地到日常工作或学习中。
三、基础知识
1. TextRank 的核心原理
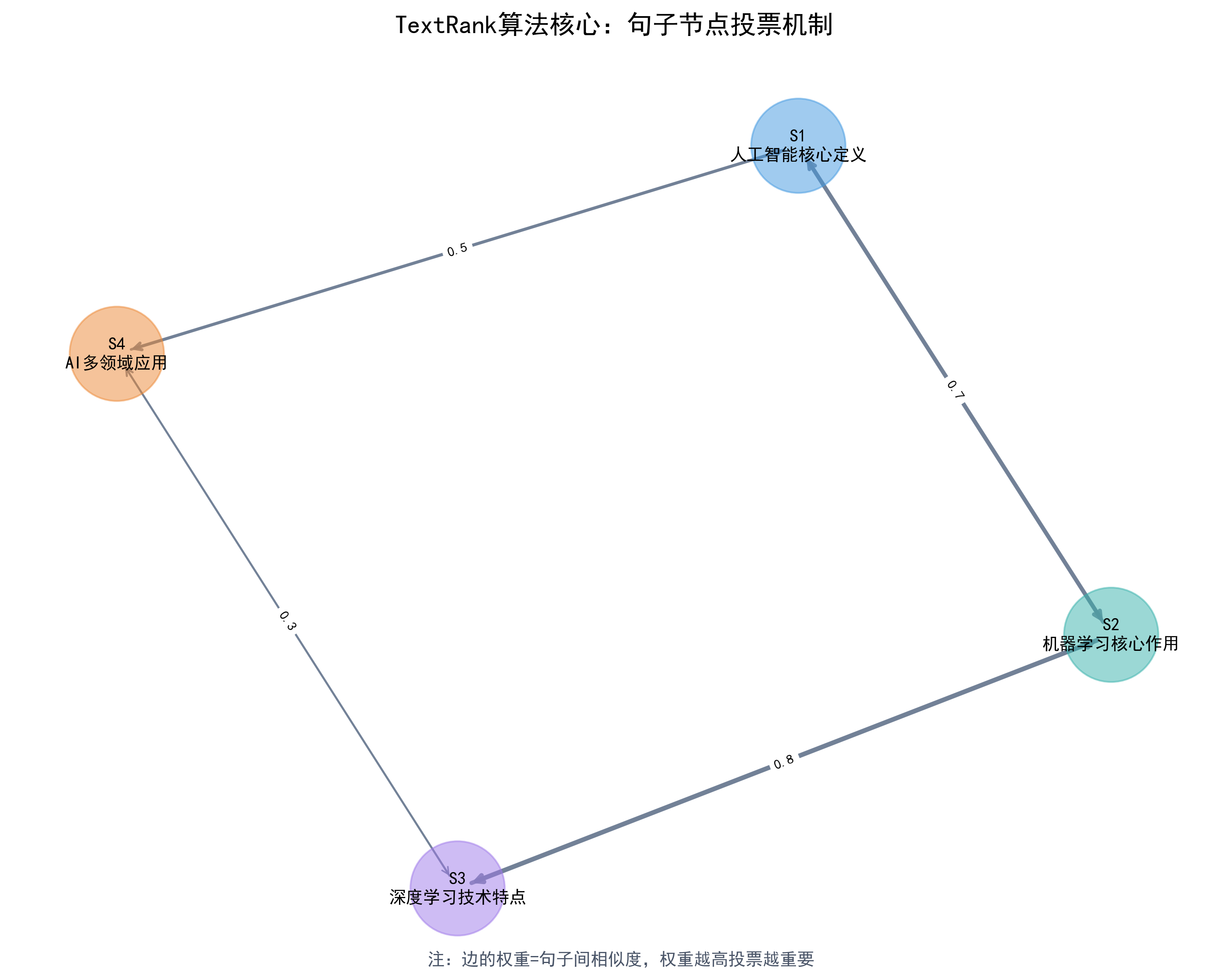
TextRank的核心是“图论 + 投票机制,我们先通过一个生活化的例子理解TextRank的核心逻辑:
假设我们要评选班级核心人物,规则是:
- 1. 每个同学可以给其他同学投票,投票权重取决于关系亲密程度,比如同桌权重10,普通同学权重5;
- 2. 一个同学的“核心程度”= 所有投他的同学的“核心程度”× 投票权重的总和;
- 3. 先给每个同学初始“核心程度”,比如都是1,然后反复计算,直到结果稳定;
- 4. 最终“核心程度”最高的同学,就是班级核心人物。
TextRank 的逻辑完全一致:
- “班级同学”= 文本中的句子或词汇;
- “投票权重”= 句子或词汇间的相似度、关联度;
- “核心程度”= 句子或词汇的TextRank权重;
- “反复计算直到稳定”= 算法的迭代收敛过程;
- “班级核心人物”= 文本的核心句子或关键词。
2. TextRank 的数学原理
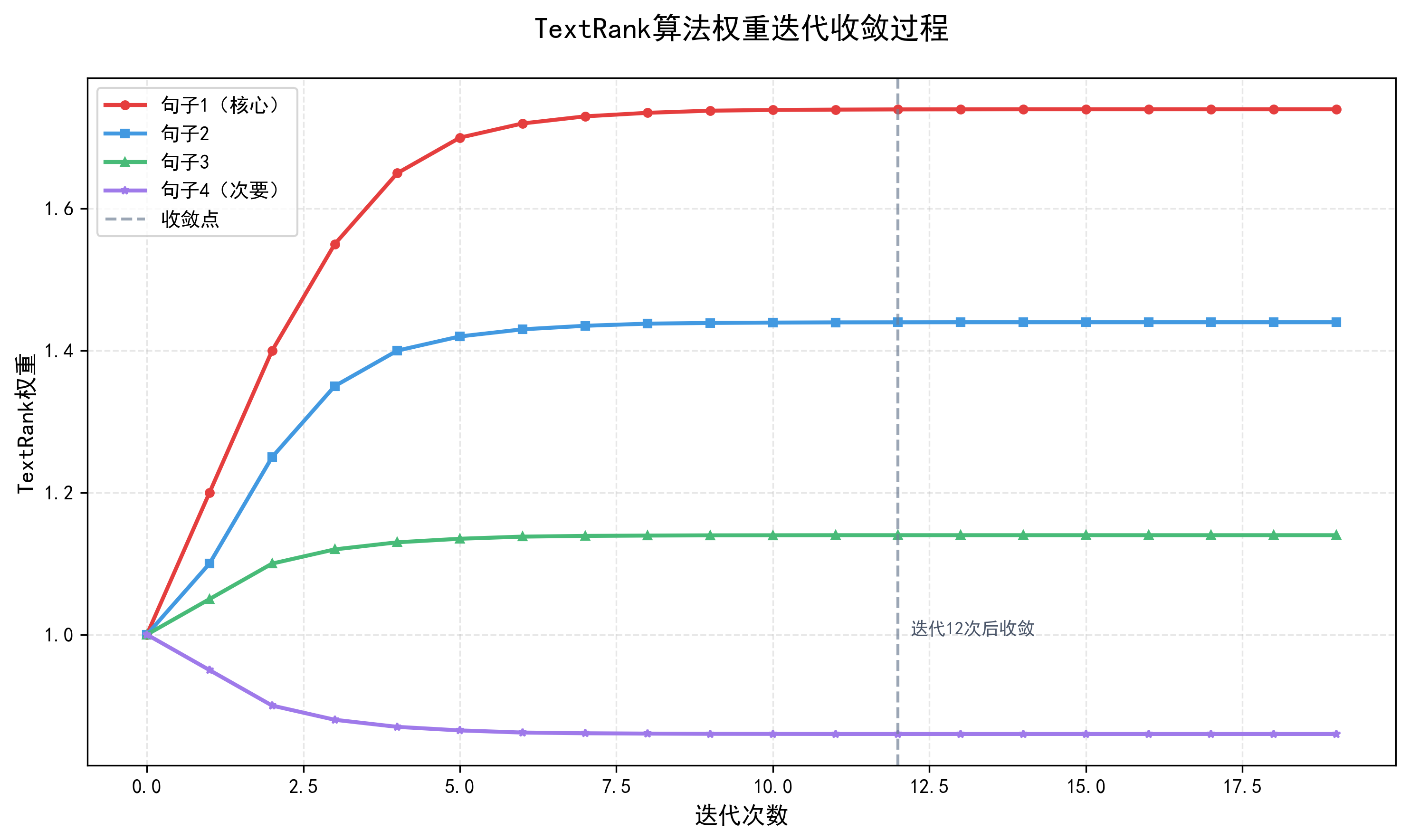
TextRank 的核心迭代公式如下:
各参数的通俗解释:
- WS(V_i):节点V_i,句子或词汇的权重,表示核心程度
- {d}:阻尼系数,通常取0.85,表示“节点有85%的概率接受其他节点的投票,15%的概率随机跳转,类比:同学有85%的概率参考他人投票,15%的概率凭直觉;
- {In(V_i)}:所有指向V_i的节点,即所有给V_i投票的节点;
- {Out(V_j)}:节点V_j指向的所有节点,即V_j给哪些节点投了票;
- {w_{jk}}:节点V_j到V_i的权重,即V_j给V_i的投票权重;
核心含义:一个节点的权重 = 基础权重(1-d) + 所有投它的节点的“加权权重”之和。
迭代收敛:算法会从初始权重(所有节点权重 = 1)开始,反复代入公式计算,直到相邻两次迭代的权重变化小于一个极小值,比如 0.0001,此时认为结果稳定,迭代停止。
3. TextRank 的核心应用
TextRank 主要用于两个场景:提取核心句子做文本粗摘、提取核心关键词做关键词粗提,二者的原理一致,仅节点定义不同。
3.1 句子级TextRank
句子级TextRank实现“粗摘核心句子”的步骤拆解:

- 1. 文本分段与句子拆分:将长文本拆分为独立的句子,比如按句号、感叹号拆分,得到句子列表S=[S1 ,S2 ,...,Sn];
- 2. 句子向量化:将每个句子转化为“数值向量”,比如用 TF-IDF、词袋模型,目的是量化句子的语义;
- 类比:把“我喜欢吃苹果”转化为 [1,0,1,1,0,...],其中1表示包含“我”、“喜欢”、“苹果”,0表示不包含其他词汇;
- 3. 构建图结构:
- 节点:每个句子Si作为一个节点;
- 边:计算任意两个句子Si和Sj的相似度,比如余弦相似度,如果相似度大于阈值,比如 0.1,则在两个节点间建立一条边,边的权重 = 相似度;
- 核心逻辑:语义越相似的句子,相互投票的权重越高;
- 4. 迭代计算权重:代入TextRank 公式,迭代计算每个句子的权重,直到收敛;
- 5. 筛选核心句子:按权重从高到低排序,选取前N个句子作为粗摘结果,N 可根据文本长度调整,比如长文本选10个,短文本选3个。
3.2 词汇级TextRank
词汇级TextRank实现"粗提关键词"的步骤拆解:

- 1. 文本分词与过滤:将文本分词,比如中文用 jieba 分词,过滤掉停用词,如“的”、“了”、“是”等无意义词汇,得到词汇列表W=[W1 ,W2 ,...,Wm];
- 2. 构建共现图:
- 节点:每个词汇Wi作为一个节点;
- 边:设定一个“窗口大小”,比如5,遍历文本时,若两个词汇出现在同一个窗口内,则建立一条边,边的权重 = 共现次数;
- 类比:窗口大小5表示"看连续5个词汇",比如“我/喜欢/吃/苹果/甜的”中,“喜欢”和“吃”、“苹果”都在窗口内,会建立边;
- 3. 迭代计算权重:代入TextRank公式,迭代计算每个词汇的权重,直到收敛;
- 4. 筛选核心词汇:按权重从高到低排序,选取前M个词汇作为粗提关键词,M通常选10-15个;
- 5. 关键词合并:将相邻的核心词汇合并为短语,比如“人工智能”、“机器学习”,提升关键词的语义完整性。
4. TextRank 的优势与局限性
4.1 优势
- 无监督学习:无需标注训练数据,拿到文本即可直接处理,对初学者极其友好;
- 计算高效:基于图的迭代计算复杂度低,即使处理万字长文本,也能在几秒内完成;
- 语言无关:仅需基础的分词或句子拆分,可适配中文、英文等任意语言;
- 结果可解释:权重越高的句子、词汇,越贴近文本核心,结果有依据。
4.2 局限性
- 碎片化:提取的核心句子是原文截取的,无逻辑连贯,阅读体验差;
- 语义孤立:关键词仅为单个词汇,无上下文解释,可能无法理解其在文本中的含义;
- 无场景适配:无法根据场景调整结果,比如学术场景需要严谨,口语场景需要通俗;
- 易受噪声影响:若文本中有重复内容,会导致对应句子、词汇权重过高,影响结果精准度。
这些局限性,正是大模型可以完美弥补的,这也是“TextRank + 大模型”融合方案的核心逻辑。
四、执行流程
从文本输入、预处理、核心提取、粗摘结果到最终精摘输出的完整执行流程:
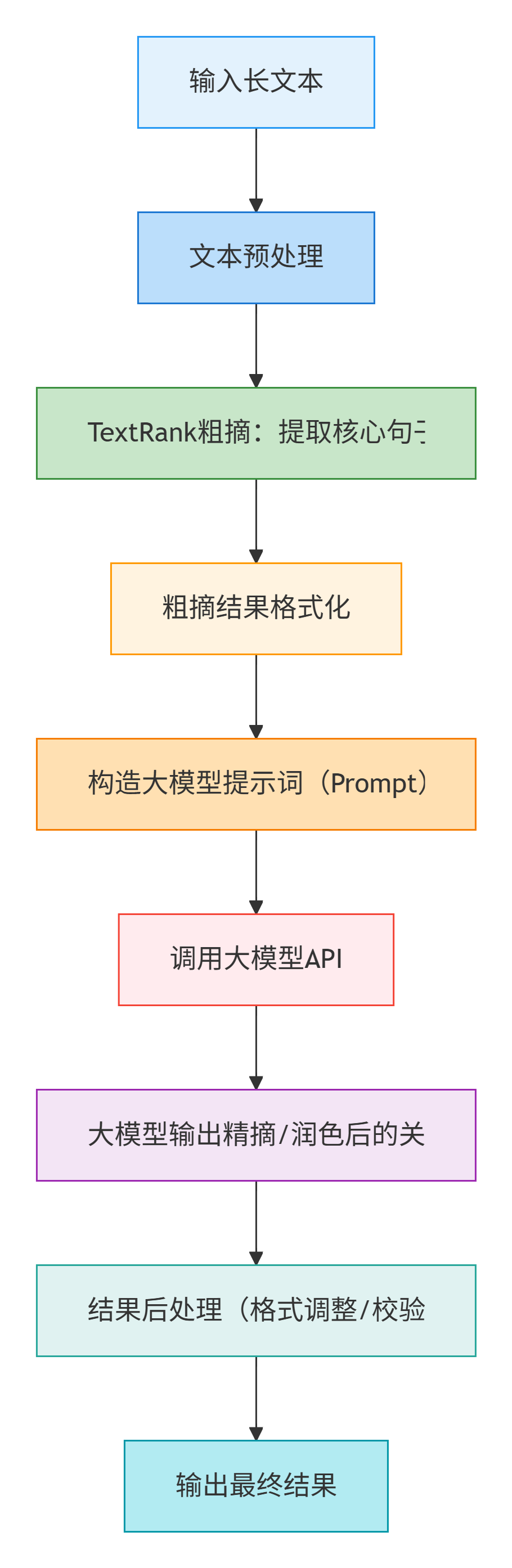
流程说明:
- 1. 输入长文本:接收需要处理的原始长文本内容,如文章、报告、新闻等
- 2. 文本预处理:清洗文本,去除特殊字符、HTML标签;中文分词、去除停用词等基础处理
- 3. TextRank粗摘
- 核心句子提取:通过TextRank算法计算句子权重,选出重要性高的句子
- 关键词提取:同时提取文本中的核心关键词
- 4. 粗摘结果格式化:将粗摘的句子和关键词整理为标准格式,如JSON,便于大模型理解
- 5. 构造大模型提示词:设计Prompt模板,将粗摘结果作为上下文,要求大模型进行精炼、润色
- 6. 调用大模型API:向大模型发送请求,传入构造好的提示词,等待返回结果
- 7. 大模型输出精摘/润色结果:大模型返回优化后的摘要文本,语言更流畅、重点更突出
- 8. 结果后处理:对模型输出进行格式校验、去重、长度调整等后处理操作
- 9. 输出最终结果:生成高质量的最终摘要,供业务系统使用
五、示例:文本摘要提取与润色
1. 文本预处理
文本预处理是所有 NLP 任务的第一步,目的是“清洗文本噪声,为后续处理铺路”。预处理无需复杂过程,核心完成以下4件事:
1.1 文本清洗
- 去除无关字符:比如HTML标签(<p>``<br>)、特殊符号(★、■、@)、多余空格、换行;
- 统一格式:比如将全角符号(。,!)转为半角(.,!);
import re
def clean_text(text):
"""
文本清洗:去除特殊符号、多余空格、HTML标签
"""
# 去除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 去除特殊符号(保留中文、英文、数字、常见标点)
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9,。!?;:""''()()、]', '', text)
# 去除多余空格和换行
text = re.sub(r'\s+', ' ', text).strip()
return text
# 测试
raw_text = "<p> 这是一篇测试文本★!包含HTML标签、特殊符号,还有多余的空格 </p>"
cleaned_text = clean_text(raw_text)
print(cleaned_text) 输出结果:
这是一篇测试文本!包含HTML标签、特殊符号,还有多余的空格
1.2 句子拆分
应用句子级TextRank将清洗后的文本拆分为独立句子,中文通常按 “。!?;” 拆分,示例代码:
import re
def split_sentences(text):
"""
拆分句子:按中文标点拆分,返回句子列表
"""
# 按。!?;拆分,保留标点
sentences = re.split(r'(。|!|?|;)', text)
# 重组句子(避免标点单独成句)
sentences = [s1 + s2 for s1, s2 in zip(sentences[0::2], sentences[1::2])]
# 过滤空句子
sentences = [s.strip() for s in sentences if s.strip()]
return sentences
# 测试
text = "这是第一句话。这是第二句话!这是第三句话?"
sentences = split_sentences(text)
print(sentences) 输出结果:
['这是第一句话。', '这是第二句话!', '这是第三句话?']
1.3 分词与停用词过滤
应用词汇级TextRank进行中文分词,推荐使用jieba库,停用词可使用通用停用词表,可从网上下载,或使用内置简单列表,示例代码:
import jieba
# 通用停用词列表(简化版,可扩展)
STOP_WORDS = {'的', '了', '是', '我', '你', '他', '她', '它', '们', '在', '有', '就', '都', '而', '及', '与', '着', '过', '也', '还', '吧', '吗', '呢', '啊', '哦', '哈', '哎', '嗨', '和', '或', '但', '却', '能', '能够', '可以', '将', '要', '会', '一个', '一些', '这种', '这个', '那个', '等', '使', '被', '由', '对', '为', '于', '以'}
# 自定义关键词词典(强制保留的词汇)
CUSTOM_KEYWORDS = {'人工智能', '机器学习', '深度学习', '自然语言处理', '计算机视觉', '神经网络', '算法', '数据', '模型'}
# 将自定义关键词加载到jieba词典中,确保正确分词
for word in CUSTOM_KEYWORDS:
jieba.add_word(word, freq=1000) # 设置较高频率确保优先匹配
def tokenize_text(text, custom_keywords=None):
"""
分词并过滤停用词
:param text: 待分词文本
:param custom_keywords: 自定义关键词集合(强制保留)
"""
# 如果没有传入自定义词典,使用全局默认词典
if custom_keywords is None:
custom_keywords = CUSTOM_KEYWORDS
# 分词(精确模式)
words = jieba.lcut(text)
# 过滤停用词、空字符串和标点符号,但保留自定义关键词
words = [word for word in words
if (word in custom_keywords) or
(word not in STOP_WORDS and word.strip() and word not in ',。!?;:""''()()、')]
return words
# 测试
text = "我喜欢吃苹果,苹果是一种很甜的水果"
words = tokenize_text(text)
print(words) 输出结果:
Building prefix dict from the default dictionary ... Loading model from cache C:\Users\Admin\AppData\Local\Temp\jieba.cache Loading model cost 0.511 seconds. Prefix dict has been built successfully. ['喜欢', '吃', '苹果', '苹果', '一种', '很甜', '水果']
1.4 文本长度适配
如果文本过长,比如超过10000字,可按段落拆分后分别处理,再合并粗摘结果,避免单次处理的图节点过多导致计算变慢。
2. TextRank 粗摘
这一步提供完整的 TextRank 实现代码,包括句子级和词汇级的实现,无需依赖复杂库;
2.1 句子级TextRank:提取核心句子
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
class TextRankSentence:
def __init__(self, sentences, custom_keywords=None, damping=0.85, max_iter=100, tol=1e-4):
"""
句子级TextRank初始化
:param sentences: 句子列表
:param custom_keywords: 自定义关键词集合(用于增强句子权重)
:param damping: 阻尼系数
:param max_iter: 最大迭代次数
:param tol: 收敛阈值
"""
# 如果没有传入自定义词典,使用全局默认词典
if custom_keywords is None:
custom_keywords = CUSTOM_KEYWORDS
self.custom_keywords = custom_keywords
self.sentences = sentences
self.damping = damping
self.max_iter = max_iter
self.tol = tol
# 构建TF-IDF向量器(用于句子向量化)
self.vectorizer = TfidfVectorizer(stop_words='english') # 中文停用词可自定义
# 句子相似度矩阵
self.sim_matrix = self._build_sim_matrix()
# 句子权重
self.sentence_weights = self._calculate_weights()
def _build_sim_matrix(self):
"""
构建句子相似度矩阵
"""
# 将句子列表转为TF-IDF向量
tfidf_matrix = self.vectorizer.fit_transform(self.sentences)
# 计算余弦相似度矩阵
sim_matrix = cosine_similarity(tfidf_matrix)
# 将相似度矩阵的对角线置0(句子不与自身相似)
np.fill_diagonal(sim_matrix, 0)
return sim_matrix
def _calculate_weights(self):
"""
迭代计算句子权重
"""
n = len(self.sentences)
# 初始化权重:所有句子权重为1
weights = np.ones(n) / n
# 迭代计算
for _ in range(self.max_iter):
new_weights = np.ones(n) * (1 - self.damping) / n
for i in range(n):
# 计算所有指向i的节点的加权权重
sum_weight = 0
for j in range(n):
if self.sim_matrix[j][i] > 0:
# 分母:j指向的所有节点的相似度之和
sum_sim_j = np.sum(self.sim_matrix[j])
if sum_sim_j == 0:
continue
sum_weight += self.sim_matrix[j][i] / sum_sim_j * weights[j]
new_weights[i] += self.damping * sum_weight
# 判断是否收敛
if np.linalg.norm(new_weights - weights) < self.tol:
break
weights = new_weights
return weights
def get_top_sentences(self, top_k=5):
"""
获取权重最高的top_k个句子
:param top_k: 返回的句子数量
:return: 核心句子列表(按原文顺序排列)
"""
# 计算每个句子中自定义关键词的出现次数,作为额外的权重因子
keyword_boost = []
for sentence in self.sentences:
# 统计句子中包含的自定义关键词数量
count = sum(1 for kw in self.custom_keywords if kw in sentence)
# 权重提升因子:每包含一个自定义关键词,权重提升20%
boost = 1 + count * 0.2
keyword_boost.append(boost)
# 将TextRank权重与自定义关键词权重相乘
boosted_weights = self.sentence_weights * np.array(keyword_boost)
# 按提升后的权重排序,获取索引
top_indices = np.argsort(boosted_weights)[-top_k:][::-1]
# 返回核心句子(按原文顺序排列)
top_sentences = [self.sentences[i] for i in sorted(top_indices)]
return top_sentences
# 测试
if __name__ == "__main__":
# 示例文本
text = """
人工智能是一门旨在使计算机系统能够模拟、延伸和扩展人类智能的技术科学。
它涵盖了机器学习、深度学习、自然语言处理、计算机视觉等多个子领域。
机器学习是人工智能的核心,它使计算机能够从数据中学习并改进性能,而无需显式编程。
深度学习是机器学习的一个分支,基于神经网络,能够处理复杂的非线性关系。
自然语言处理则专注于使计算机理解和生成人类语言,是人工智能落地的重要方向。
随着算力的提升和数据量的增长,人工智能在医疗、金融、教育等领域的应用越来越广泛。
未来,人工智能将继续推动产业升级,改变人们的生活方式,但也需要关注伦理和安全问题。
"""
# 预处理
cleaned_text = clean_text(text)
sentences = split_sentences(cleaned_text)
# 初始化TextRank
textrank = TextRankSentence(sentences)
# 获取核心句子(粗摘)
top_sentences = textrank.get_top_sentences(top_k=3)
print("TextRank粗摘核心句子:")
for i, sent in enumerate(top_sentences, 1):
print(f"{i}. {sent}")输出结果:
TextRank粗摘核心句子: 1. 它涵盖了机器学习、深度学习、自然语言处理、计算机视觉等多个子领域。 2. 机器学习是人工智能的核心,它使计算机能够从数据中学习并改进性能,而无需显式编程。 3. 深度学习是机器学习的一个分支,基于神经网络,能够处理复杂的非线性关系。
2.2 词汇级TextRank:提取核心关键词
import numpy as np
from collections import defaultdict
class TextRankKeyword:
def __init__(self, words, custom_keywords=None, window_size=5, damping=0.85, max_iter=100, tol=1e-4):
"""
词汇级TextRank初始化
:param words: 分词后的词汇列表
:param custom_keywords: 自定义关键词集合(优先返回)
:param window_size: 共现窗口大小
:param damping: 阻尼系数
:param max_iter: 最大迭代次数
:param tol: 收敛阈值
"""
# 如果没有传入自定义词典,使用全局默认词典
if custom_keywords is None:
custom_keywords = CUSTOM_KEYWORDS
self.custom_keywords = custom_keywords
self.words = words
self.window_size = window_size
self.damping = damping
self.max_iter = max_iter
self.tol = tol
# 构建词汇共现图
self.graph = self._build_graph()
# 词汇权重
self.word_weights = self._calculate_weights()
def _build_graph(self):
"""
构建词汇共现图(邻接表形式)
"""
graph = defaultdict(dict)
# 遍历词汇,构建共现关系
for i in range(len(self.words)):
# 窗口范围:[i-window_size, i+window_size]
start = max(0, i - self.window_size)
end = min(len(self.words), i + self.window_size + 1)
# 遍历窗口内的其他词汇
for j in range(start, end):
if i == j:
continue
word_i = self.words[i]
word_j = self.words[j]
# 更新共现权重(共现一次,权重+1)
if word_j in graph[word_i]:
graph[word_i][word_j] += 1
else:
graph[word_i][word_j] = 1
return graph
def _calculate_weights(self):
"""
迭代计算词汇权重
"""
# 词汇列表(去重)
unique_words = list(set(self.words))
word2idx = {word: idx for idx, word in enumerate(unique_words)}
n = len(unique_words)
# 初始化权重:所有词汇权重为1
weights = np.ones(n) / n
# 构建邻接矩阵
adj_matrix = np.zeros((n, n))
for word_i in self.graph:
for word_j in self.graph[word_i]:
i = word2idx[word_i]
j = word2idx[word_j]
adj_matrix[i][j] = self.graph[word_i][word_j]
# 迭代计算
for _ in range(self.max_iter):
new_weights = np.ones(n) * (1 - self.damping) / n
for i in range(n):
sum_weight = 0
for j in range(n):
if adj_matrix[j][i] > 0:
# 分母:j指向的所有节点的权重之和
sum_adj_j = np.sum(adj_matrix[j])
if sum_adj_j == 0:
continue
sum_weight += adj_matrix[j][i] / sum_adj_j * weights[j]
new_weights[i] += self.damping * sum_weight
# 判断是否收敛
if np.linalg.norm(new_weights - weights) < self.tol:
break
weights = new_weights
# 转换为{词汇: 权重}的字典
word_weights = {unique_words[i]: weights[i] for i in range(n)}
return word_weights
def get_top_keywords(self, top_k=10, only_custom=False):
"""
获取权重最高的top_k个关键词
:param top_k: 返回的关键词数量
:param only_custom: 是否只返回自定义词典中的关键词
"""
# 按权重排序
sorted_keywords = sorted(self.word_weights.items(), key=lambda x: x[1], reverse=True)
if only_custom:
# 只返回自定义词典中的关键词
custom_sorted = [(word, weight) for word, weight in sorted_keywords if word in self.custom_keywords]
top_keywords = [word for word, weight in custom_sorted[:top_k]]
else:
# 返回所有关键词
top_keywords = [word for word, weight in sorted_keywords[:top_k]]
return top_keywords
# 测试
if __name__ == "__main__":
# 示例文本
text = """
人工智能是一门旨在使计算机系统能够模拟、延伸和扩展人类智能的技术科学。
它涵盖了机器学习、深度学习、自然语言处理、计算机视觉等多个子领域。
机器学习是人工智能的核心,它使计算机能够从数据中学习并改进性能,而无需显式编程。
深度学习是机器学习的一个分支,基于神经网络,能够处理复杂的非线性关系。
自然语言处理则专注于使计算机理解和生成人类语言,是人工智能落地的重要方向。
随着算力的提升和数据量的增长,人工智能在医疗、金融、教育等领域的应用越来越广泛。
未来,人工智能将继续推动产业升级,改变人们的生活方式,但也需要关注伦理和安全问题。
"""
# 预处理
cleaned_text = clean_text(text)
words = tokenize_text(cleaned_text)
# 初始化TextRank
textrank = TextRankKeyword(words)
# 获取核心关键词(粗提)
top_keywords = textrank.get_top_keywords(top_k=5)
print("TextRank粗提核心关键词:")
for i, keyword in enumerate(top_keywords, 1):
print(f"{i}. {keyword}")输出结果:
TextRank粗提核心关键词: 1. 人工智能 2. 机器学习 3. 人类 4. 深度学习 5. 计算机
3. 粗摘结果格式化
粗摘结果是“核心句子列表 + 核心关键词列表”,需要格式化后传入大模型,目的是让大模型清晰理解需要处理的核心内容。
def format_rough_result(sentences, keywords):
"""
格式化粗摘结果,用于构造大模型提示词
"""
formatted = f"""
以下是文本的核心句子(粗摘):
{chr(10).join([f"{i+1}. {sent}" for i, sent in enumerate(sentences)])}
以下是文本的核心关键词(粗提):
{chr(10).join([f"{i+1}. {kw}" for i, kw in enumerate(keywords)])}
"""
return formatted.strip()
# 测试
# top_sentences = [
# "人工智能是一门旨在使计算机系统能够模拟、延伸和扩展人类智能的技术科学。",
# "机器学习是人工智能的核心,它使计算机能够从数据中学习并改进性能,而无需显式编程。",
# "随着算力的提升和数据量的增长,人工智能在医疗、金融、教育等领域的应用越来越广泛。"
# ]
# top_keywords = ["人工智能", "机器学习", "深度学习", "自然语言处理", "领域"]
formatted_text = format_rough_result(top_sentences, top_keywords)
print("格式化后的粗摘结果:")
print(formatted_text)输出结果:
格式化后的粗摘结果: 以下是文本的核心句子(粗摘): 1. 它涵盖了机器学习、深度学习、自然语言处理、计算机视觉等多个子领域。 2. 机器学习是人工智能的核心,它使计算机能够从数据中学习并改进性能,而无需显式编程。 3. 深度学习是机器学习的一个分支,基于神经网络,能够处理复杂的非线性关系。 以下是文本的核心关键词(粗提): 1. 人工智能 2. 机器学习 3. 人类 4. 深度学习 5. 计算机
4. 构造大模型提示词
提示词是大模型输出质量的核心,初学者需遵循 “清晰、具体、有场景” 的原则。以下是不同场景的提示词模板:
4.1 长文摘要场景
def build_summary_prompt(formatted_rough, style="学术", length="200字"):
"""
构造长文摘要提示词
:param formatted_rough: 格式化的粗摘结果
:param style: 输出风格(学术/口语化/分点)
:param length: 输出长度
"""
prompt = f"""
请基于以下文本的核心句子和关键词,生成一篇{length}左右的{style}风格摘要:
{formatted_rough}
要求:
1. 严格保留核心信息,不遗漏关键内容;
2. 语言流畅,逻辑连贯,符合{style}风格;
3. 避免冗余,不添加无关信息;
4. 若风格为分点,需分3-5点总结核心内容。
"""
return prompt.strip()
# 测试
prompt = build_summary_prompt(formatted_text, style="学术", length="200字")
print("大模型摘要提示词:")
print(prompt)输出结果:
大模型摘要提示词: 请基于以下文本的核心句子和关键词,生成一篇200字左右的学术风格摘要: 以下是文本的核心句子(粗摘): 1. 它涵盖了机器学习、深度学习、自然语言处理、计算机视觉等多个子领域。 2. 机器学习是人工智能的核心,它使计算机能够从数据中学习并改进性能,而无需显式编程。 3. 深度学习是机器学习的一个分支,基于神经网络,能够处理复杂的非线性关系。 以下是文本的核心关键词(粗提): 1. 人工智能 2. 机器学习 3. 人类 4. 深度学习 5. 计算机 要求: 1. 严格保留核心信息,不遗漏关键内容; 2. 语言流畅,逻辑连贯,符合学术风格; 3. 避免冗余,不添加无关信息; 4. 若风格为分点,需分3-5点总结核心内容。
4.2 关键词润色场景
def build_keyword_prompt(formatted_rough, need_explain=True):
"""
构造关键词润色提示词
:param formatted_rough: 格式化的粗摘结果
:param need_explain: 是否需要为关键词添加简短解释
"""
explain_text = "并为每个关键词添加1-2句话的简短解释(说明该关键词在文本中的含义)" if need_explain else ""
prompt = f"""
请基于以下文本的核心关键词,优化并整理关键词列表{explain_text}:
{formatted_rough}
要求:
1. 保留核心关键词,可合并语义相近的词汇;
2. 关键词列表控制在8-10个;
3. 解释需简洁、准确,贴合文本语境。
"""
return prompt.strip()
# 测试
keyword_prompt = build_keyword_prompt(formatted_text, need_explain=True)
print("大模型关键词提示词:")
print(keyword_prompt)输出结果:
大模型关键词提示词: 请基于以下文本的核心关键词,优化并整理关键词列表并为每个关键词添加1-2句话的简短解释(说明该关键词在文本中的含义): 以下是文本的核心句子(粗摘): 1. 它涵盖了机器学习、深度学习、自然语言处理、计算机视觉等多个子领域。 2. 机器学习是人工智能的核心,它使计算机能够从数据中学习并改进性能,而无需显式编程。 3. 深度学习是机器学习的一个分支,基于神经网络,能够处理复杂的非线性关系。 以下是文本的核心关键词(粗提): 1. 人工智能 2. 机器学习 3. 人类 4. 深度学习 5. 计算机 要求: 1. 保留核心关键词,可合并语义相近的词汇; 2. 关键词列表控制在8-10个; 3. 解释需简洁、准确,贴合文本语境。
5. 调用大模型 API
我们调用混元大模型的在线api,注意需注册自己的api_key,并替换到一下示例中;
from openai import OpenAI
# 配置API Key(替换为你的混元API Key)
api_key = 'sk-bWl**********************vZ5NP8Ze'
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
def call_llm(prompt, model="hunyuan-lite", temperature=0.3):
"""
调用混元大模型API
:param prompt: 提示词
:param model: 模型名称(hunyuan-lite/hunyuan-pro等)
:param temperature: 生成温度(越低越精准)
:return: 大模型输出结果
"""
try:
completion = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "你是一个专业的文本处理助手"},
{"role": "user", "content": prompt}
],
temperature=temperature,
max_tokens=1000
)
# 提取输出内容
result = completion.choices[0].message.content.strip()
return result
except Exception as e:
print(f"调用混元大模型失败:{e}")
return None
# 测试
if __name__ == "__main__":
# 构造提示词
prompt = build_summary_prompt(formatted_text, style="学术", length="200字")
# 调用大模型
summary_result = call_llm(prompt)
if summary_result:
print("大模型生成的精摘:")
print(summary_result)输出结果:
大模型生成的精摘: 本文探讨了人工智能的多个子领域,特别是机器学习和深度学习。机器学习作为人工智能的核心,利用算法使计算机从数据中学习并提升性能,无需显式编程 。深度学习则是机器学习的一个分支,基于神经网络,擅长处理复杂的非线性关系。文章还强调了计算机在这些技术中的应用,以及它们如何共同推动人工智 能的发展。通过深入研究这些核心技术,我们可以更好地理解人工智能的工作原理,并为其未来的应用提供理论支持。
6. 结果后处理与输出
大模型输出结果可能存在格式问题,比如多余的换行、符号,可进行简单后处理:
def post_process_result(result):
"""
结果后处理:去除多余空格、换行,格式化输出
"""
# 去除多余空格和换行
result = re.sub(r'\s+', ' ', result).strip()
# 按句子拆分,换行显示(提升可读性)
sentences = split_sentences(result)
final_result = chr(10).join(sentences)
return final_result
# 测试
if summary_result:
final_summary = post_process_result(summary_result)
print("最终精摘结果:")
print(final_summary)输出结果:
最终精摘结果: 本文探讨了人工智能的多个子领域,特别是机器学习和深度学习。 机器学习作为人工智能的核心,利用算法使计算机从数据中学习并提升性能,无需显式编程。 深度学习则是机器学习的一个分支,基于神经网络,擅长处理复杂的非线性关系。 文章还强调了计算机在这些技术中的应用,以及它们如何共同推动人工智能的发展。 通过深入研究这些核心技术,我们可以更好地理解人工智能的工作原理,并为其未来的应用提供理论支持。
六、大模型在融合方案中的价值
TextRank 的粗摘结果存在“碎片化、语义孤立、无场景适配”的问题,大模型可针对性解决:
1. 语义整合:从句子拼接到逻辑连贯
- TextRank提取的核心句子是原文的直接截取,句子间无逻辑关联,比如先讲 人工智能应用”,再讲“机器学习定义”,最后讲“人工智能定义”。
- 大模型可以重新组织句子顺序,使其符合“总 - 分 - 总”、“因果”、“递进”等逻辑;补充过渡词或句子,让摘要流畅自然;
2. 语义补全:从孤立词汇到语境化解释
- TextRank 提取的关键词是孤立的词汇,比如“深度学习”,初次接触可能无法理解其在文本中的具体含义。
- 大模型可以为关键词添加简短解释,贴合文本语境;合并语义相近的关键词;
- 比如“机器学习”和“深度学习”可标注为“人工智能核心分支:机器学习(含深度学习)”;
3. 场景适配:从通用结果到场景化输出
- TextRank 的结果是通用的,无法适配不同场景需求。
- 大模型可根据提示词调整输出风格:
- 学术场景:语言严谨、术语规范,符合论文摘要格式;
- 办公场景:分点总结、重点突出,适合会议记录;
- 科普场景:语言通俗、举例生动,适合大众阅读;
4. 冗余过滤与纠错:提升结果精准度
- TextRank 可能因文本重复内容导致核心句子、关键词权重过高,比如文本中多次提到“算力提升”,可能提取多个类似句子。
- 大模型可合并重复内容,保留核心信息;纠正粗摘中的错误,比如TextRank误提的无关关键词;
- 示例:若TextRank粗摘包含两个“算力提升推动人工智能应用”的句子,大模型会合并为一句,避免冗余。
七、总结
通过今天我们可以领悟到一个高效做事的思路,不用追求单一种工具做到完美,而是让不同工具各司其职。TextRank 虽然简单,但胜在快速、轻量,能帮我们快速过滤冗余,抓住文本核心;大模型虽然强大,但不用盲目直接用它处理长文本,既费钱又容易跑偏。我们不用一开始就死磕复杂代码或大模型调参,先把TextRank的基础用法练熟,能独立提取核心句子和关键词就够了。然后慢慢学习构造提示词,让大模型把粗摘结果变精致,循序渐进比一口吃成胖子更靠谱。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号