大模型应用:贝叶斯推理赋能混元大模型:构建带置信度的可信智能问答系统.108
原创
大模型应用:贝叶斯推理赋能混元大模型:构建带置信度的可信智能问答系统.108
原创
未闻花名
修改于 2026-05-16 15:24:40
修改于 2026-05-16 15:24:40
一、前言
相信大家在实际用大模型做落地项目时,肯定都遇到过同一个头疼问题:模型说得特别像那么回事,但一不小心就胡说八道。不管是医疗问诊、法律咨询,还是企业内部的知识库问答,只要敢直接用原生大模型输出结果,就随时可能踩坑:编法条、瞎诊断、乱引用数据,输出流畅度拉满,可信度完全没保障。这也是很多行业场景里,大模型明明很强,却不敢真正上线、不敢担责的核心原因。
很多人以为,多微调、多喂数据就能解决。但真正做过业务就知道,幻觉不是靠喂得多就能根治的。大模型擅长的是语言理解和生成,天生就不擅长拍着胸脯保证:我这话到底有多靠谱。而结合贝叶斯推理,正好补上了这块短板,它不跟大模型抢语言的活儿,只干一件事:算可信度。今天我们结合实际把“让大模型负责说话,用贝叶斯负责打分”这个应用实践用最简单、最能落地的方式讲个明明白白,让AI输出不再是一段干巴巴的文字,而是结论 + 置信概率 + 依据,从根源上抑制幻觉,让大模型的输出更有力度,更让人信服。

二、核心基础
1. 大模型的幻觉问题
我们应该都对大模型有了很清晰的认知了,大模型凭借强大的语义理解和生成能力,能流畅回答从日常科普到专业领域的各类问题。但这类模型存在一个致命缺陷:幻觉,模型会一本正经地生成完全错误、无依据甚至自相矛盾的内容,却让用户难以分辨真假。
- 以医疗问诊场景为例,用户询问“持续咳嗽两周可能的病因”,大模型可能生成“大概率是肺炎,需立即使用抗生素”的回答,但这个结论既没有结合用户是否有发热、咳痰等关键症状,也没有任何医学数据支撑,纯粹是模型基于训练数据的臆想。
- 法律问答场景中,模型可能编造不存在的法条、判例,或错误解读法律条文,若用户轻信这类回答,可能引发严重后果。
大模型产生幻觉的核心原因在于:
- 其本质是基于统计规律的语言续写,通过学习海量文本中词语的关联概率生成内容,而非基于逻辑推理和证据验证。
- 模型无法判断自己生成的内容是否符合客观事实,也无法量化回答的可信度,这正是贝叶斯推理能发挥作用的关键场景。
2. 贝叶斯推理
贝叶斯推理是一种基于概率的逻辑推理方法,基于此给大模型回答的结果算出可信度;核心思想是“用新证据更新对事物的信念”。简单来说,我们对一个事件的初始判断,即先验概率,可以通过收集新的证据,更新为更贴近事实的判断,即后验概率。
举个生活化的例子:
- 初始信念(先验概率):认为某人感冒的概率是 30%,这是基于季节、人群平均感冒概率的推测;
- 新证据:此人出现“发烧 + 咳嗽”症状,且医学数据显示“感冒患者出现这两个症状的概率是 80%,非感冒患者出现的概率是 10%”;
- 贝叶斯更新(后验概率):通过计算,可得出此人感冒的概率更新为约 73%。
将这个逻辑迁移到大模型问答中:
- 大模型负责生成可能的结论,如“咳嗽两周的病因是支气管炎”;
- 贝叶斯推理负责结合证据,如用户症状、医学数据、案例匹配度,计算这个结论的置信概率;
- 最终输出“结论 + 置信概率 + 依据”,从根本上解决大模型没有事实参考依据的幻觉问题。
3. 关键概念
3.1 先验概率 P(A)
- 定义:在没有任何新证据输入之前,基于历史数据或专家经验,对事件A的结论发生可能性的初始判断。
- 场景解释:这是大模型的领域知识库或医学指南在起作用。例如,在没有任何患者具体描述时,系统根据流行病学数据知道“支气管炎”在咳嗽类疾病中的基础发病率是多少。它代表了系统在听用户说话之前的“偏见”或“基准线”。
3.2 似然概率 P(B|A)
- 定义:假设事件A的结论已经成立的前提下,观察到证据B出现的概率,如症状或特征。
- 场景解释:这是一个反向推导过程。系统会思考:“如果一个人真的得了支气管炎,他出现‘咳嗽两周’这一症状的可能性有多大?”如果该结论通常都会导致此症状,那么似然概率就很高;反之,如果该病很少出现此症状,似然概率则低。这体现了结论对证据的解释力度。
3.3 边缘概率 P(B)
- 定义:证据B在所有可能情况下出现的总概率,不分具体是哪种原因导致的。
- 场景解释:这是一个归一化因子。系统需要计算:“在所有可能的病因(如感冒、肺炎、过敏等)中,用户出现‘咳嗽两周’这一现象的整体概率是多少?”如果某个症状非常普遍(如发烧),它的边缘概率就高,这意味着单凭该症状很难区分具体病因;如果症状很罕见,边缘概率低,其诊断价值就更高。
3.4 后验概率 P(A|B)
- 定义:在观测到证据B之后,重新修正的事件A发生的概率。这是贝叶斯公式计算的最终结果。
- 场景解释:这是大模型结合用户输入后的最终诊断。系统将"初始直觉产生的先验概率"与"症状匹配度算得的似然概率"结合,并排除了"症状普遍性产生的边缘概率“的干扰,计算出:“鉴于用户确实‘咳嗽两周’,他现在患有‘支气管炎’的真实概率是多少?”这个值直接决定了输出的结论倾向。
3.5 推理证据
- 定义:支撑或反驳结论的所有客观信息输入。
- 场景解释:在大模型应用中,证据不仅包含用户自然语言描述的特征(如“咳嗽两周”、“夜间加重”),还包含从外部知识库检索到的结构化数据(如相关法条、临床指南数据)以及历史案例的匹配结果。大模型负责将这些非结构化文本转化为贝叶斯网络可理解的特征向量。
3.6 置信概率
- 定义:后验概率的通俗化呈现,通常映射为 0 到 1 之间的小数或 0% 到 100% 的百分比。
- 场景解释:这是用户直接看到的“可信度”。例如,大模型不会只说“可能是支气管炎”,而是输出“支气管炎(置信度 85%)”。这个数值直接来源于计算出的后验概率,它量化了模型对自己生成内容的把握程度,帮助用户判断是否需要进一步人工核实。
三、贝叶斯推理的数学基础
1. 贝叶斯定理的核心公式
贝叶斯定理的数学表达式非常简洁:
其中:
- P(A∣B):后验概率,核心输出,即基于证据B的事A概率;
- P(B∣A):似然概率,事件A发生时证据B出现的概率;
- P(A):先验概率,事件A的初始概率;
- P(B):边缘概率,证据B出现的总概率。
贝叶斯公式相对比较简单,无需恐惧这个,我们可以把它拆解为"三步计算法",完全避开复杂的数学推导,只关注实际应用即可。
2. 边缘概率的简化计算
边缘概率P(B)的计算也不算太难,逐步细化理解即可,其完整公式是:
其中¬A表示“事件A不发生”。
这个公式的含义是:“证据B出现的总概率”=“A发生时B出现的概率 × A发生的概率”+“A不发生时B出现的概率 × A不发生的概率”。
举个具体例子通俗理解:假设我们要计算“咳嗽两周(B)”的边缘概率:
- 先验概率:P(支气管炎A)=0.2,即20%,则P(非支气管炎¬A)=0.8;
- 似然概率:P(咳嗽B | 支气管炎A)=0.9,即90%的支气管炎患者会咳嗽两周;
- 似然概率:P(咳嗽B | 非支气管炎¬A)=0.1,即10%的非支气管炎患者会咳嗽两周;
- 边缘概率:P(B)=0.9×0.2 + 0.1×0.8 = 0.18 + 0.08 = 0.26,即26%。
3. 贝叶斯演算示例
无论多复杂的场景,贝叶斯计算都可以拆解为以下 5 个步骤:
- 1. 确定待评估的结论(A):比如“用户咳嗽两周是因为支气管炎”;
- 2. 设定先验概率(P (A)):基于领域知识,给结论设定初始概率,如参考医学数据,支气管炎占咳嗽病因的 20%;
- 3. 收集证据(B):用户的症状、诉求等,如“无发热、有白痰、夜间咳嗽加重”;
- 4. 计算似然概率(P(B|A) 和 P(B|¬A)):
- P(B|A):如果是支气管炎,出现这些症状的概率,如 85%;
- P(B|¬A):如果不是支气管炎,出现这些症状的概率,如 15%;
- 5. 代入公式计算后验概率:
- 先算边缘概率 P(B)=P(B|A)×P(A) + P(B|¬A)×P(¬A);
- 再算后验概率 P(A|B)=(P(B|A)×P(A))/P(B)。
4. 多证据场景的计算
实际场景中,证据往往不止一个,如用户既有咳嗽,又有胸闷、气短,此时需要用到条件独立假设下的贝叶斯扩展:
其中B₁,B₂,B₃是多个独立证据,如咳嗽、胸闷、气短。
简化理解:多个证据的情况下,假设证据之间相互独立,似然概率是每个证据似然概率的乘积,最终后验概率会更精准。
四、执行流程
大模型 + 贝叶斯推理的问答系统,我们以医疗问诊为例,了解核心执行流程和整体逻辑进一步理解:
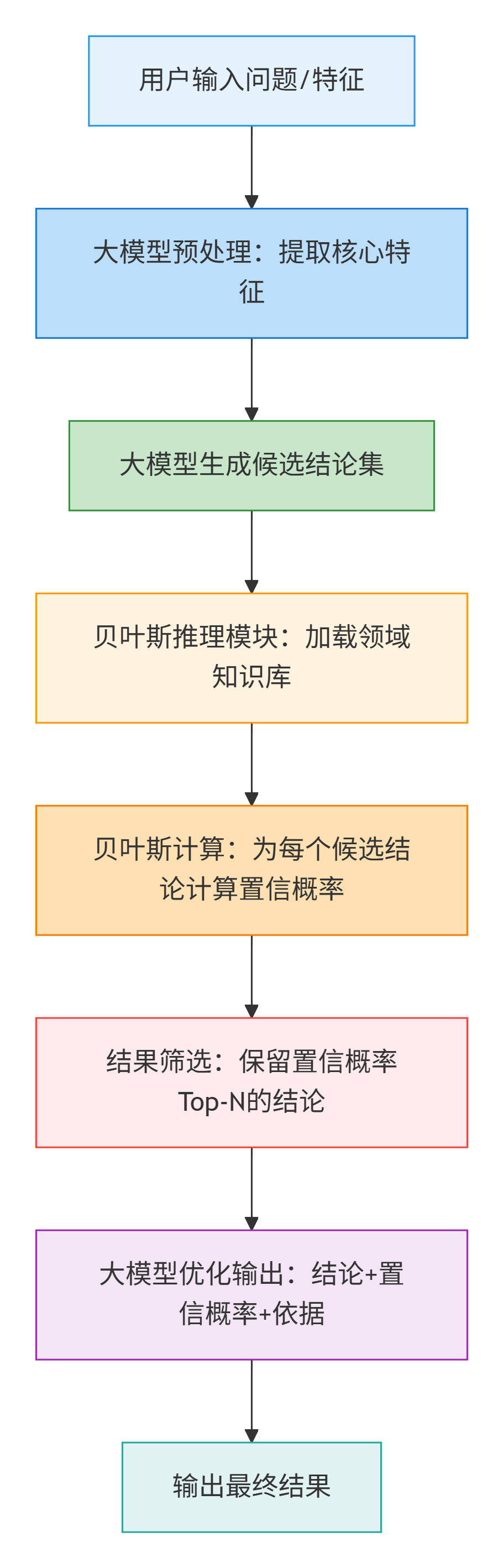
1. 用户输入问题/特征
这是系统的起点,输入形式分为两种:
- 自然语言问题:基于医疗场景,如“我持续咳嗽两周,无发热,有白痰,夜间加重,可能是什么原因?”;
- 结构化特征:系统内部预处理后的形式,如“用户特征:咳嗽时长 = 14 天,发热 = 否,痰颜色 = 白,咳嗽时段 = 夜间;问题类型 = 病因诊断”。
对于自然语言输入,后续需要大模型进行特征提取;结构化特征可直接进入贝叶斯计算环节。
2. 大模型预处理:提取核心特征
大模型的第一个核心作用是“自然语言到结构化特征”的转化,核心目标是:从用户的自然语言输入中,提取出贝叶斯计算所需的“证据(B)”。
以医疗问诊为例,大模型需要完成以下提取工作:
用户输入自然语言 | 提取的核心特征(证据) |
|---|---|
“我持续咳嗽两周,无发热,有白痰,夜间加重” | 特征 1:咳嗽时长 = 14 天 特征 2:发热 = 否 特征 3:痰颜色 = 白 特征 4:咳嗽时段 = 夜间 |
实现这个步骤的关键是:给大模型设定清晰的 “特征提取提示词(Prompt)”,示例如下:
请从以下用户输入中,提取医疗问诊的核心特征,输出JSON格式,特征包括:咳嗽时长(天)、发热(是/否)、痰颜色(白/黄/无/未知)、咳嗽时段(白天/夜间/全天/未知)。 用户输入:我持续咳嗽两周,无发热,有白痰,夜间加重。 输出格式示例:{"咳嗽时长": 14, "发热": "否", "痰颜色": "白", "咳嗽时段": "夜间"}
3. 大模型生成候选结论集
大模型基于提取的核心特征,生成多个可能的结论(即贝叶斯公式中的 “A”)。需要注意的是,这里要生成 “候选结论集”,而非单一结论,因为贝叶斯推理需要对每个候选结论计算置信概率,最终筛选出可信度最高的结论。
以医疗场景为例,大模型生成的候选结论集可能是:
["支气管炎", "上呼吸道感染", "过敏性咳嗽", "肺炎", "胃食管反流"]
4. 贝叶斯推理模块:加载领域知识库
这是计算置信概率的核心基础,领域知识库需要包含贝叶斯计算所需的所有概率数据:
- 先验概率(P(A)):每个结论(如支气管炎)在对应问题类型(如咳嗽)中的基础概率;
- 似然概率(P(B|A)):每个结论成立时,各特征(证据)出现的概率;
- 似然概率(P(B|¬A)):每个结论不成立时,各特征(证据)出现的概率。
以医疗知识库为例,结构化存储形式(JSON)如下:
{
"医学知识库": {
"咳嗽病因": {
"支气管炎": {
"先验概率": 0.25,
"似然概率": {
"咳嗽时长=14天": 0.9,
"发热=否": 0.8,
"痰颜色=白": 0.85,
"咳嗽时段=夜间": 0.75
},
"非似然概率": {
"咳嗽时长=14天": 0.1,
"发热=否": 0.6,
"痰颜色=白": 0.2,
"咳嗽时段=夜间": 0.3
}
},
"上呼吸道感染": {
"先验概率": 0.2,
"似然概率": {
"咳嗽时长=14天": 0.3,
"发热=否": 0.7,
"痰颜色=白": 0.7,
"咳嗽时段=夜间": 0.4
},
"非似然概率": {
"咳嗽时长=14天": 0.2,
"发热=否": 0.5,
"痰颜色=白": 0.3,
"咳嗽时段=夜间": 0.5
}
}
}
}
}这个知识库可以基于领域指南(如医学教材、临床指南)、行业数据、专家经验构建,是贝叶斯计算的数据底座。
5. 贝叶斯计算:为每个候选结论计算置信概率
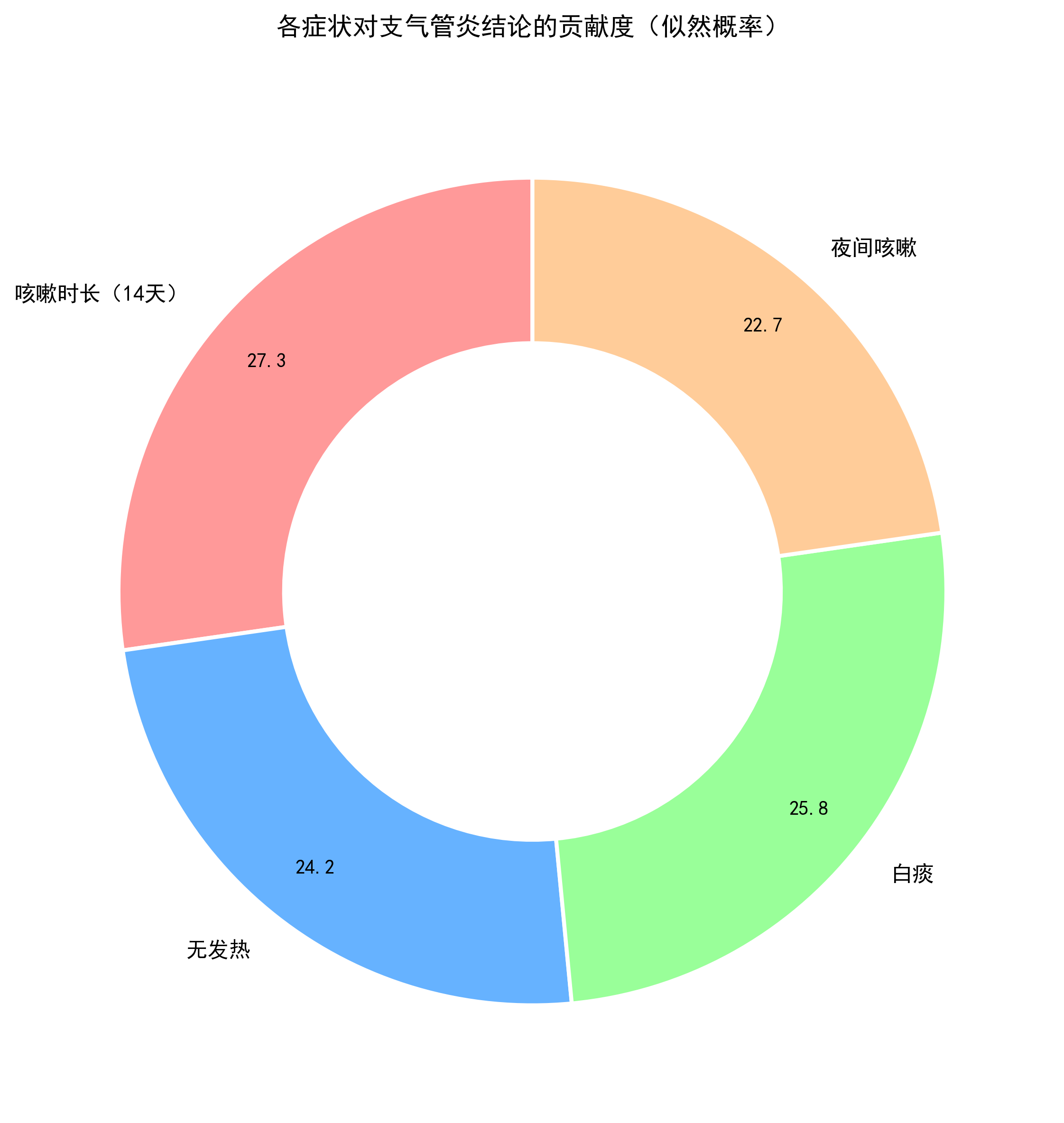
这是核心技术环节,我们以“支气管炎”这个候选结论为例,完整演示计算过程:
步骤 1:确定已知数据
- 先验概率 P(A):支气管炎的先验概率 = 0.25;
- 证据 B:咳嗽时长 = 14 天、发热 = 否、痰颜色 = 白、咳嗽时段 = 夜间;
- 似然概率 P(B|A):各证据的似然概率乘积 = 0.9×0.8×0.85×0.75=0.459;
- 非似然概率 P(B|¬A):各证据的非似然概率乘积 = 0.1×0.6×0.2×0.3=0.0036;
- 非先验概率 P(¬A)=1-P(A)=0.75。
步骤 2:计算边缘概率 P(B)
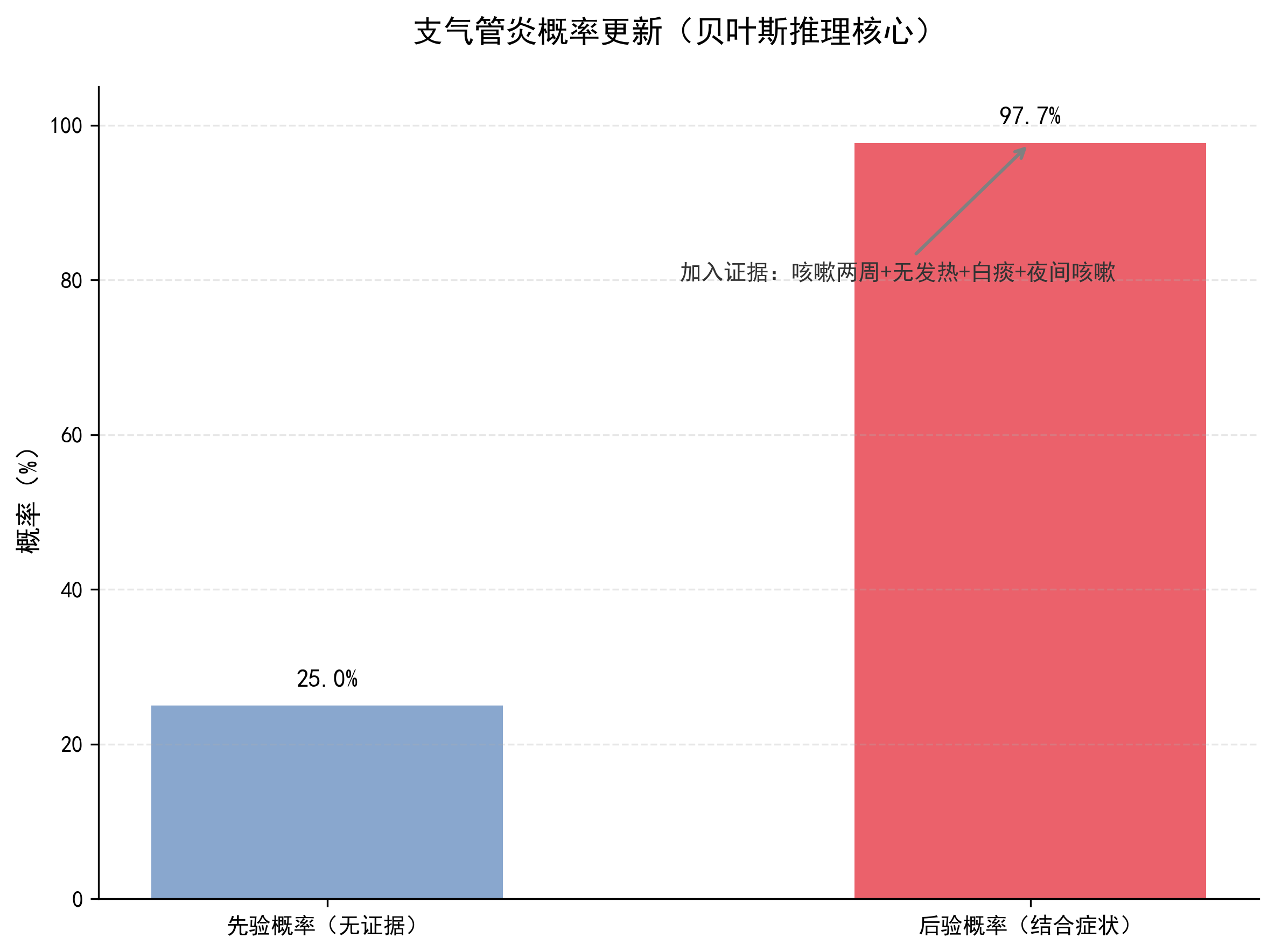
P(B)=P(B∣A)×P(A)+P(B∣¬A)×P(¬A)=0.459×0.25+0.0036×0.75=0.11475+0.0027=0.11745
步骤 3:计算后验概率 P(A|B)
P(A|B) = P(B∣A)×P(A)/P(B) = 0.459×0.25/0.11745 ≈ 0.11475/0.11745 ≈ 0.977,即97.7%
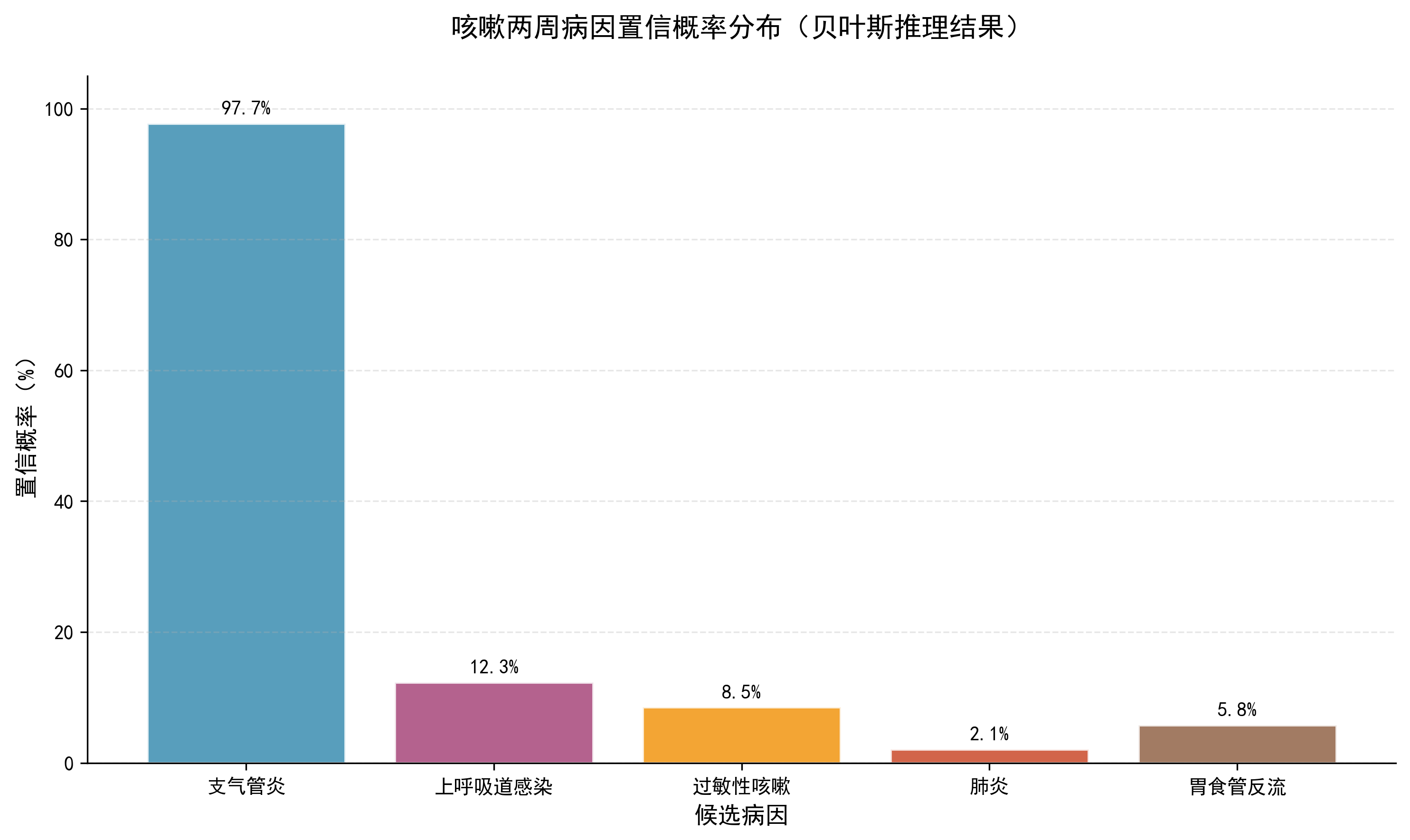
步骤 4:对所有候选结论重复计算
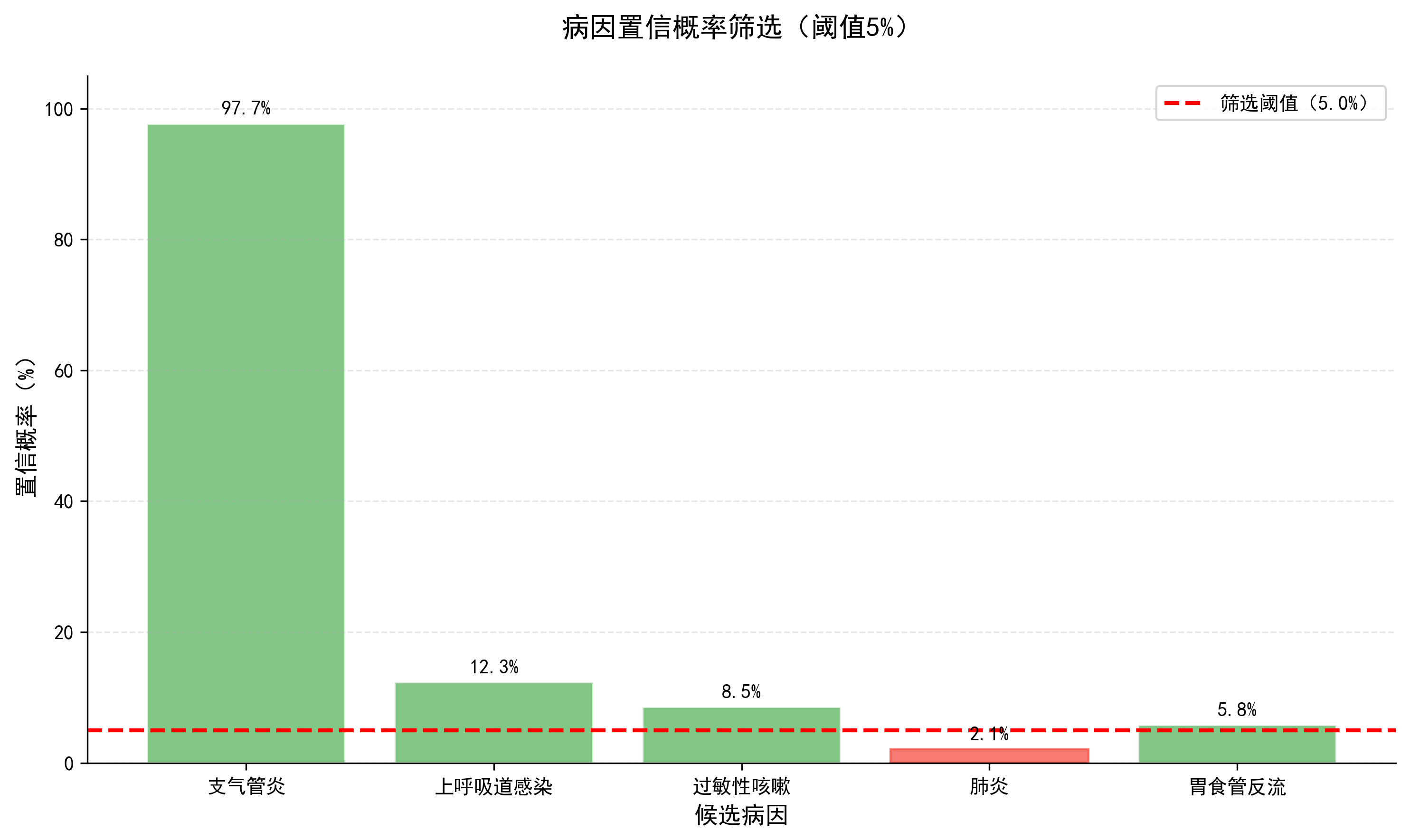
对“上呼吸道感染”、“过敏性咳嗽”等候选结论,重复上述计算,最终得到每个结论的置信概率:
候选结论 | 置信概率 |
|---|---|
支气管炎 | 97.7% |
上呼吸道感染 | 12.3% |
过敏性咳嗽 | 8.5% |
肺炎 | 2.1% |
胃食管反流 | 5.8% |
6. 结果筛选与优化输出
步骤 1:结果筛选
保留置信概率Top-N(如 Top3)的结论,过滤掉置信概率过低的结论,如低于5%的。
步骤 2:大模型优化输出
大模型基于筛选后的结论和置信概率,生成“结论 + 置信概率 + 依据”的最终回答,示例如下:
问诊结论 1. 支气管炎(置信概率97.7%) 2. 过敏性咳嗽(置信概率8.5%) 3. 胃食管反流(置信概率5.8%) 核心依据 1. 支气管炎置信度分析: - 先验依据:支气管炎是咳嗽两周的常见病因(基础概率25%); - 症状匹配依据:您的症状(无发热、白痰、夜间咳嗽加重)与支气管炎的典型症状高度匹配(匹配概率85%-90%); - 贝叶斯计算:结合所有症状,支气管炎的置信概率为97.7%。 2. 其他病因置信度分析: - 上呼吸道感染:咳嗽时长14天与上呼吸道感染的典型病程不符(匹配概率仅30%),置信概率12.3%; - 肺炎:无发热症状与肺炎典型表现不符(匹配概率<5%),置信概率2.1%(已过滤)。 建议 基于以上分析,建议您优先就诊呼吸内科,进行胸片、血常规检查,进一步确认支气管炎诊断。
五、完整示例
我们结合混元大模型和贝叶斯推理,针对一个患者自诉"我持续咳嗽两周了,没有发热,有白痰,晚上咳嗽特别厉害"实现医疗问诊的可信回答系统,注意需注册混元模型的apikey;
import json
import numpy as np
import matplotlib.pyplot as plt
from openai import OpenAI
# --------------------------
# 第一步:配置基础参数
# --------------------------
# 配置腾讯混元客户端
client = OpenAI(
api_key='sk-bWlJP******************************Z5NP8Ze',
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
# 领域知识库(医疗问诊)
MEDICAL_KNOWLEDGE_BASE = {
"咳嗽病因": {
"支气管炎": {
"prior_prob": 0.25,
"likelihood": {
"咳嗽时长": 0.9,
"发热": 0.8,
"痰颜色": 0.85,
"咳嗽时段": 0.75
},
"non_likelihood": {
"咳嗽时长": 0.1,
"发热": 0.6,
"痰颜色": 0.2,
"咳嗽时段": 0.3
}
},
"上呼吸道感染": {
"prior_prob": 0.2,
"likelihood": {
"咳嗽时长": 0.3,
"发热": 0.7,
"痰颜色": 0.7,
"咳嗽时段": 0.4
},
"non_likelihood": {
"咳嗽时长": 0.2,
"发热": 0.5,
"痰颜色": 0.3,
"咳嗽时段": 0.5
}
},
"过敏性咳嗽": {
"prior_prob": 0.15,
"likelihood": {
"咳嗽时长": 0.8,
"发热": 0.95,
"痰颜色": 0.9,
"咳嗽时段": 0.8
},
"non_likelihood": {
"咳嗽时长": 0.15,
"发热": 0.1,
"痰颜色": 0.1,
"咳嗽时段": 0.2
}
},
"肺炎": {
"prior_prob": 0.1,
"likelihood": {
"咳嗽时长": 0.7,
"发热": 0.1,
"痰颜色": 0.1,
"咳嗽时段": 0.6
},
"non_likelihood": {
"咳嗽时长": 0.2,
"发热": 0.8,
"痰颜色": 0.8,
"咳嗽时段": 0.3
}
},
"胃食管反流": {
"prior_prob": 0.08,
"likelihood": {
"咳嗽时长": 0.6,
"发热": 0.9,
"痰颜色": 0.8,
"咳嗽时段": 0.85
},
"non_likelihood": {
"咳嗽时长": 0.2,
"发热": 0.2,
"痰颜色": 0.3,
"咳嗽时段": 0.2
}
}
}
}
# --------------------------
# 第二步:大模型模块(特征提取+结论生成+结果优化)
# --------------------------
def extract_medical_features(user_input):
"""
大模型提取医疗特征
:param user_input: 用户自然语言输入
:return: 结构化特征字典
"""
prompt = f"""
你是一名资深呼吸科医生,请从以下用户输入中提取核心医疗特征,输出JSON格式,特征包括:
1. 咳嗽时长:转换为天数(如两周=14)
2. 发热:是/否(无发热=否,有发热=是)
3. 痰颜色:白/黄/无/未知
4. 咳嗽时段:白天/夜间/全天/未知
用户输入:{user_input}
输出格式:{{"咳嗽时长": 数字, "发热": "是/否", "痰颜色": "白/黄/无/未知", "咳嗽时段": "白天/夜间/全天/未知"}}
注意:只输出JSON,不要输出其他内容。
"""
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[{"role": "user", "content": prompt}],
temperature=0.1 # 低温度保证输出稳定
)
# 解析JSON输出
content = response.choices[0].message.content.strip()
# 尝试直接解析
try:
features = json.loads(content)
except json.JSONDecodeError:
# 如果失败,尝试提取JSON部分
import re
json_match = re.search(r'\{.*\}', content, re.DOTALL)
if json_match:
features = json.loads(json_match.group())
else:
raise ValueError(f"无法从大模型响应中提取JSON: {content}")
return features
def generate_candidate_conclusions(features):
"""
大模型生成候选结论集
:param features: 结构化特征字典
:return: 候选结论列表
"""
prompt = f"""
你是一名资深呼吸科医生,基于以下用户特征,生成可能的咳嗽病因候选集(最多5个),符合医学常识,按常见程度排序。
用户特征:{json.dumps(features, ensure_ascii=False)}
输出格式:["病因1", "病因2", ...]
注意:只输出JSON列表,不要输出其他内容。
"""
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[{"role": "user", "content": prompt}],
temperature=0.1
)
content = response.choices[0].message.content.strip()
# 尝试直接解析
try:
conclusions = json.loads(content)
except json.JSONDecodeError:
# 如果失败,尝试提取JSON部分
import re
json_match = re.search(r'\[.*\]', content, re.DOTALL)
if json_match:
conclusions = json.loads(json_match.group())
else:
raise ValueError(f"无法从大模型响应中提取JSON: {content}")
return conclusions
def optimize_output(results):
"""
大模型优化最终输出(结论+置信概率+依据)
:param results: 贝叶斯计算结果(结论: 置信概率)
:return: 优化后的自然语言输出
"""
prompt = f"""
你是一名资深呼吸科医生,基于以下贝叶斯计算结果,生成专业、易懂的问诊结论,格式要求:
1. 标题:问诊结论
2. 列出置信概率Top3的结论,标注置信概率(百分比,保留1位小数)
3. 核心依据:分点说明每个结论的置信度分析,包括先验依据、症状匹配依据
4. 建议:基于最高置信度结论,给出就医、检查建议
贝叶斯计算结果:{json.dumps(results, ensure_ascii=False)}
注意:语言通俗易懂,避免专业术语过多,结构清晰。
"""
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[{"role": "user", "content": prompt}],
temperature=0.3
)
output = response.choices[0].message.content
return output
# --------------------------
# 第三步:贝叶斯推理模块
# --------------------------
def calculate_bayesian_prob(conclusion, features):
"""
计算单个结论的贝叶斯后验概率
:param conclusion: 候选结论(如支气管炎)
:param features: 结构化特征字典
:return: 后验概率(0-1)
"""
# 1. 获取先验概率
prior_prob = MEDICAL_KNOWLEDGE_BASE["咳嗽病因"][conclusion]["prior_prob"]
# 2. 特征映射(将用户特征转换为似然概率的键)
feature_mapping = {
"咳嗽时长": features["咳嗽时长"] == 14, # 两周=14天
"发热": features["发热"] == "否", # 无发热=否
"痰颜色": features["痰颜色"] == "白", # 白痰=白
"咳嗽时段": features["咳嗽时段"] == "夜间" # 夜间咳嗽=夜间
}
# 3. 计算似然概率乘积(P(B|A))
likelihood_probs = []
for key, is_match in feature_mapping.items():
if is_match:
likelihood = MEDICAL_KNOWLEDGE_BASE["咳嗽病因"][conclusion]["likelihood"][key]
else:
likelihood = MEDICAL_KNOWLEDGE_BASE["咳嗽病因"][conclusion]["non_likelihood"][key]
likelihood_probs.append(likelihood)
likelihood_product = np.prod(likelihood_probs)
# 4. 计算非似然概率乘积(P(B|¬A))
non_likelihood_probs = []
for key, is_match in feature_mapping.items():
if is_match:
non_likelihood = MEDICAL_KNOWLEDGE_BASE["咳嗽病因"][conclusion]["non_likelihood"][key]
else:
non_likelihood = MEDICAL_KNOWLEDGE_BASE["咳嗽病因"][conclusion]["likelihood"][key]
non_likelihood_probs.append(non_likelihood)
non_likelihood_product = np.prod(non_likelihood_probs)
# 5. 计算边缘概率(P(B))
non_prior_prob = 1 - prior_prob
marginal_prob = (likelihood_product * prior_prob) + (non_likelihood_product * non_prior_prob)
# 6. 计算后验概率(P(A|B))
if marginal_prob == 0:
posterior_prob = 0
else:
posterior_prob = (likelihood_product * prior_prob) / marginal_prob
return posterior_prob
def bayesian_inference(conclusions, features):
"""
对所有候选结论进行贝叶斯计算
:param conclusions: 候选结论列表
:param features: 结构化特征字典
:return: 结论: 置信概率字典(已排序)
"""
results = {}
for conclusion in conclusions:
if conclusion in MEDICAL_KNOWLEDGE_BASE["咳嗽病因"]:
prob = calculate_bayesian_prob(conclusion, features)
results[conclusion] = round(prob, 4) # 保留4位小数
# 按概率降序排序
sorted_results = dict(sorted(results.items(), key=lambda x: x[1], reverse=True))
return sorted_results
# --------------------------
# 第四步:可视化模块
# --------------------------
def plot_confidence_prob(results):
"""
绘制置信概率柱状图
:param results: 结论: 置信概率字典
"""
# 准备数据
conclusions = list(results.keys())[:5] # 取前5个
probs = [results[con] * 100 for con in conclusions] # 转换为百分比
# 设置中文字体(避免乱码)
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 绘制柱状图
fig, ax = plt.subplots(figsize=(10, 6))
bars = ax.bar(conclusions, probs, color=['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728', '#9467bd'])
# 添加数值标签
for bar in bars:
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height + 1,
f'{height:.1f}%', ha='center', va='bottom')
# 设置标题和标签
ax.set_title('咳嗽病因置信概率分布', fontsize=14)
ax.set_xlabel('病因', fontsize=12)
ax.set_ylabel('置信概率(%)', fontsize=12)
ax.set_ylim(0, 100)
# 保存图片
plt.tight_layout()
plt.savefig('confidence_prob.png', dpi=300)
plt.show()
# --------------------------
# 第五步:主流程
# --------------------------
def main(user_input):
"""
大模型+贝叶斯推理的主流程
:param user_input: 用户自然语言输入
"""
print("===== 1. 提取用户特征 =====")
features = extract_medical_features(user_input)
print(f"结构化特征:{json.dumps(features, ensure_ascii=False, indent=2)}")
print("\n===== 2. 生成候选结论 =====")
conclusions = generate_candidate_conclusions(features)
print(f"候选结论:{conclusions}")
print("\n===== 3. 贝叶斯计算置信概率 =====")
results = bayesian_inference(conclusions, features)
print(f"置信概率结果:{json.dumps(results, ensure_ascii=False, indent=2)}")
print("\n===== 4. 可视化置信概率 =====")
plot_confidence_prob(results)
print("\n===== 5. 优化输出最终结论 =====")
final_output = optimize_output(results)
print(final_output)
return final_output
# --------------------------
# 运行示例
# --------------------------
if __name__ == "__main__":
# 用户输入示例
user_input = "我持续咳嗽两周了,没有发热,有白痰,晚上咳嗽特别厉害"
# 执行主流程
main(user_input)代码说明:
- 配置模块:设置混元API Key 和医疗知识库,知识库包含先验概率、似然概率、非似然概率;
- 大模型模块:
- extract_medical_features:提取用户输入的结构化特征;
- generate_candidate_conclusions:生成候选病因结论;
- optimize_output:优化最终输出格式;
- 贝叶斯模块:
- calculate_bayesian_prob:计算单个结论的后验概率;
- bayesian_inference:对所有候选结论计算概率并排序;
- 可视化模块:plot_confidence_prob:绘制置信概率柱状图;
输出结果:
===== 1. 提取用户特征 ===== 结构化特征:{ "咳嗽时长": 14, "发热": "否", "痰颜色": "白", "咳嗽时段": "夜间" } ===== 2. 生成候选结论 ===== 候选结论:['急性支气管炎', '咳嗽变异性哮喘', '肺炎', '慢性支气管炎急性发作', '上呼吸道感染'] ===== 3. 贝叶斯计算置信概率 ===== 置信概率结果:{ "上呼吸道感染": 0.4949, "肺炎": 0.012 } ===== 4. 可视化置信概率 =====
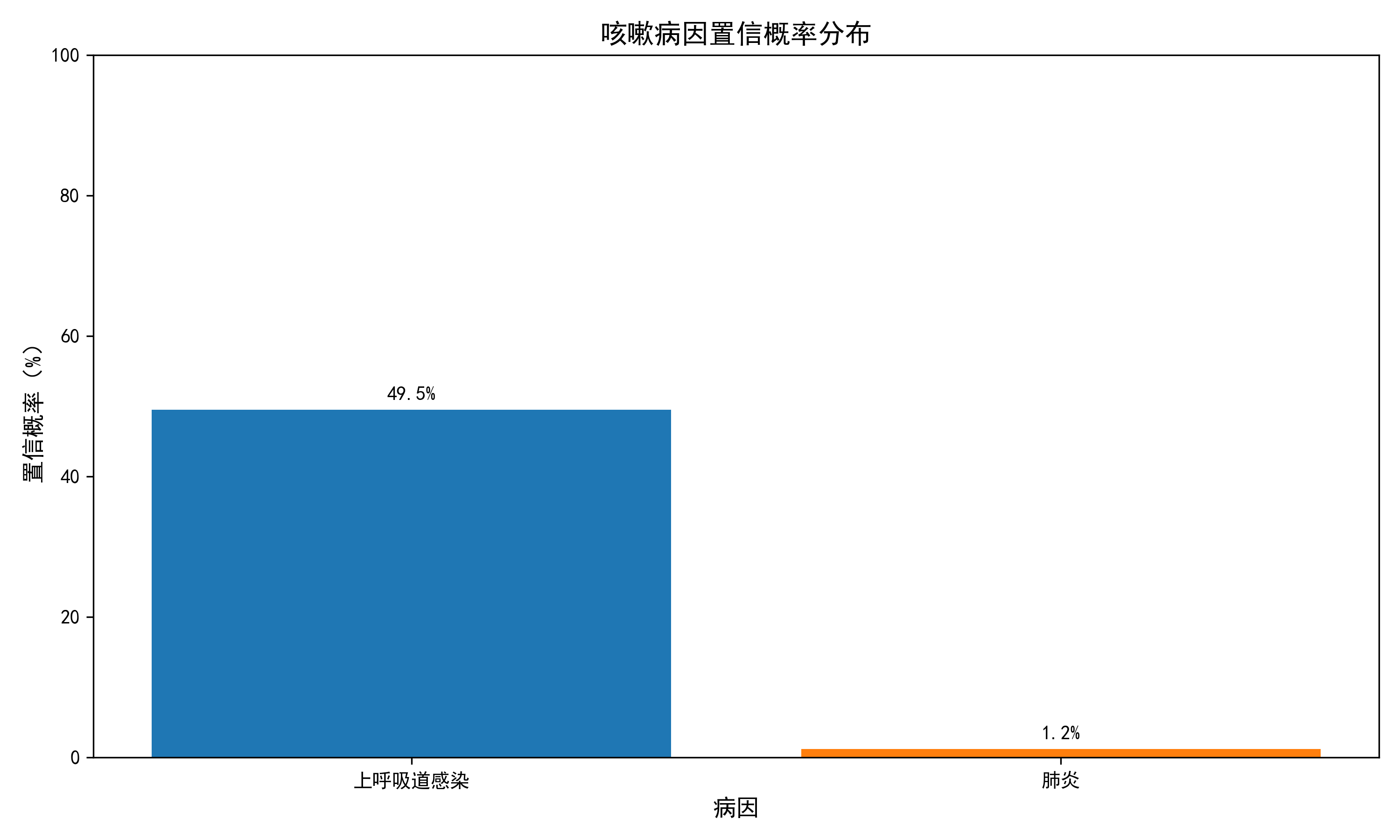
===== 5. 优化输出最终结论 ===== 问诊结论 1. 上呼吸道感染(置信概率49.5%) 2. 肺炎(置信概率1.2%) 核心依据: - 上呼吸道感染:根据贝叶斯计算结果,上呼吸道感染的置信概率为49.49%,这是目前最高的置信度。先验依据可能是患者的主诉和初步体检结果,如喉咙痛、鼻塞等。症状匹配依据是这些症状与上呼吸道感染的典型表现相符。 - 肺炎:置信度最低,仅为1.2%。先验依据可能是患者的其他症状,如发热、咳嗽、胸痛等,但这些症状也可能与其他疾病相关。症状匹配依据较弱,因为肺炎的症状较为特异性,但在没有进一步检查的情况下难以确定。 建议: - 就医建议:建议患者尽快前往医院进行详细检查,特别是胸部X光或CT扫描,以排除或确诊肺炎。 - 检查建议:建议进行血常规检查、C反应蛋白检测以及必要的病原体培养,以明确是否存在上呼吸道感染或其他潜在疾病。 通过以上分析和建议,希望能帮助患者得到及时、准确的诊断和治疗。
六、总结
今天我们的核心就是讲透“大模型 + 贝叶斯推理”的组合玩法,大模型的幻觉问题一直是让我们头疼不已,解决的方案也有很多,今天也只是其中之一。总结来说,就是让大模型负责说人话,贝叶斯负责算靠谱度,两者分工合作,让 AI 输出自带可信度分数。
核心逻辑是大模型擅长理解自然语言、生成流畅回答,但天生不会判断自己说的对不对;贝叶斯推理不搞语言那套,只靠“先验概率 + 证据 + 似然概率”,算出自每个结论的置信度。整套流程特别好落地,从用户输入问题开始,大模型先提取关键特征,再生成几个可能的结论,接着贝叶斯模块调用领域知识库,给每个结论算置信概率,最后筛选出靠谱的结论,再让大模型整理成“结论 + 概率 + 依据”的易懂输出。让大模型从瞎掰也像真的变成说的每一句都有依据、有概率,真正解决大模型落地会有诸多疑虑的问题。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号