书签真正难的不是收藏,而是找回来:我是怎么做这个 Chrome 插件的
原创
书签真正难的不是收藏,而是找回来:我是怎么做这个 Chrome 插件的
原创
一只牛博
发布于 2026-05-18 09:50:07
发布于 2026-05-18 09:50:07
书签真正难的不是收藏,而是找回来:我是怎么做这个 Chrome 插件的
浏览器书签这个功能,大家都不陌生,但真正用顺手的人并不多。原因不是不会收藏,而是收藏数量一上来以后,原生书签管理器越来越像仓库,不像检索工具。你明明记得自己收藏过一个东西,也记得大概和“短信”“支付”“AI”“监控”“后台”有关,但就是想不起来它到底被塞进了哪一层目录。最后最常见的结局不是找到,而是重新去搜索引擎再搜一遍。
这就是我做 Bookmark Finder 的原因。目标并不大,也不是想重做一个复杂的书签系统,我只想解决一个非常具体的问题:当书签数量越来越多以后,怎样让“我之前存过的那个链接”能尽快被找回来。
如果只讲“体验更好”“搜索更快”,这样的文章没有说服力。所以这篇文章不打算泛泛而谈,而是直接围绕几个实际问题展开:为什么我选 Chrome 扩展来做,为什么它能搜得出来,为什么入口必须做短,为什么最近记录要能删,以及为什么我在第一版里刻意控制性能和内存开销。
这篇文章只回答一个问题:undefined当书签越来越多时,怎样把“之前存过的链接”重新找回来。
先说痛点:原生书签的问题,不是不能存,而是检索思路不对
原生书签管理器更适合“我知道自己把东西放在哪”。但现实中,大多数人真正遇到的是另一种场景:我不记得目录了,只记得一个模糊线索。比如我记得那个网站和短信接码有关,或者和某个 AI 工具有关,或者以前放在“国外”这个目录附近,但我已经记不清完整标题,也记不清域名了。
这时候,传统的目录式管理就会失灵。因为收藏时你是按分类思路保存的,使用时你却是按需求思路找的。这两个上下文天然不是一回事。
所以这个插件从一开始就没有把重点放在“怎样继续优化分类”,而是直接把目标改成“怎样把书签变成可检索的内容”。换句话说,核心不是帮用户继续往收藏夹里塞东西,而是让之前积累过的东西真正能再次用起来。
核心痛点:
- 收藏时按“分类思路”保存
- 使用时按“需求思路”检索
- 两个上下文不一致,原生书签就会越来越难找
为什么一定是 Chrome 扩展,而不是油猴脚本
这个选择其实没有什么悬念。只要目标是做书签搜索,Chrome 扩展天然更合适,因为它有官方的 bookmarks API,可以直接拿到完整书签树,也能监听书签变更事件。油猴脚本更适合针对某个网页做增强,不适合做这种浏览器级工具。
从 manifest.json 就能看出这个插件的基本定位:
{
"manifest_version": 3,
"name": "Bookmark Finder",
"omnibox": {
"keyword": "bm"
},
"permissions": ["bookmarks", "storage", "tabs"],
"background": {
"service_worker": "background.js"
},
"action": {
"default_popup": "popup.html"
},
"commands": {
"_execute_action": {
"suggested_key": {
"default": "Ctrl+Shift+K",
"mac": "Command+Shift+K"
}
}
}
}这里有三个关键点。
第一,bookmarks 权限让插件能直接读取 Chrome 的书签树,而不是靠页面抓取。第二,omnibox 让地址栏本身变成搜索入口,用户可以直接在浏览器地址栏里输入 bm 再按 Tab 搜书签。第三,commands 把搜索框变成一个可以用快捷键随时呼出的高频动作。
这三个点放在一起,决定了这个插件不是一个“点开图标偶尔搜一下”的玩具,而是一个真正能嵌进浏览器日常工作流的工具。
这里真正重要的不是权限本身,而是入口能力:
bookmarks:决定它能直接读取书签树omnibox:决定地址栏可以直接搜commands:决定它能变成快捷键工具
它为什么能把书签搜出来:不是只搜标题,而是把标题、路径、URL 全部索引化
很多书签搜索不好用,问题根本不在搜索框本身,而在它只搜标题。现实里,人记住一个链接的方式往往是碎片化的。有人记住的是标题,有人记住的是域名片段,有人记住的是自己放进去的文件夹名字。所以如果只搜标题,召回率一定不够。
这个插件做索引时,会把每个书签文档拆成三部分:标题、路径和 URL。
const FIELD_WEIGHT = {
title: 4.0,
path: 2.0,
url: 1.5
};
function buildDoc(record) {
const titleNorm = normalize(clipText(record.title, MAX_FIELD_CHARS.title));
const pathNorm = normalize(clipText(record.path, MAX_FIELD_CHARS.path));
const urlNorm = normalize(clipText(record.url, MAX_FIELD_CHARS.url));
const searchText = `${titleNorm} ${pathNorm} ${urlNorm}`.trim();
const titleTokens = buildTokens(titleNorm);
const pathTokens = buildTokens(pathNorm);
const urlTokens = buildTokens(urlNorm);
...
return {
...record,
titleNorm,
pathNorm,
urlNorm,
titleTf,
pathTf,
urlTf,
docNorm,
searchText
};
}这里最重要的不是代码写法,而是产品思路:标题权重最高,路径次之,URL 也参与。因为标题最能表达语义,路径是用户自己定义的分类信息,URL 则往往包含域名和路径线索。三者叠加,实际命中率会比单纯搜标题高很多。
这也是为什么输入“短信”这类词时,哪怕目标链接标题没有完整出现这个词,只要路径、URL 或者扩展词里有相关线索,也能被排出来。
重点:undefined不是“搜标题”,而是把一个书签当成
title + path + url的组合文档来搜。
为什么它不是死板的字面匹配:我做了扩词和模糊打分
只做精准匹配的搜索,很容易出现一个问题:你脑子里想到的词和书签里真实存在的词不完全一致时,结果会直接掉下去。为了解决这个问题,我在第一版里加了两个补充层,一个是扩词,一个是模糊相关性。
扩词词库写在后台脚本里,像 sms、otp、验证码 这类跨中英文、跨缩写的相关词会归并到一起:
const BASE_LEXICON = {
otp: ["2fa", "mfa", "sms", "verification", "one-time", "验证码", "动态码", "双因子"],
sms: ["otp", "message", "text", "verification", "短信", "验证码"],
payment: ["billing", "invoice", "checkout", "pay", "付款", "支付", "账单", "发票"],
docs: ["document", "guide", "manual", "readme", "文档", "教程", "指南"]
};这件事的意义不是“写死关键词”,而是把真实使用中的表达差异收敛掉。用户搜的是“短信”,目标书签里可能写的是 sms;用户搜的是“支付”,目标里写的是 billing 或 invoice。如果不做这层扩词,搜索结果会比用户预期弱很多。
然后是最终排序逻辑。这个插件不是简单 contains,而是把词法得分、短语命中、模糊相似度和点击行为一起算进分数:
function scoreSearch(query, limit, options = {}) {
...
const preliminary = [...candidate.entries()]
.map(([docIndex, lexical]) => {
const doc = state.docs[docIndex];
const phrase = computePhraseBonus(queryNorm, doc);
return {
docIndex,
lexical: lexical + phrase
};
})
.sort((a, b) => b.lexical - a.lexical)
.slice(0, fuzzyCap);
const scored = preliminary
.map((entry) => {
const doc = state.docs[entry.docIndex];
const fuzzy = cosineSparse(queryGrams, ngrams(doc.searchText)) * 0.9;
const behavior = clickScore(doc.id);
const finalScore = entry.lexical * 0.78 + fuzzy + behavior;
return {
doc,
score: finalScore,
lexical: entry.lexical,
fuzzy,
behavior
};
})
.sort((a, b) => b.score - a.score)
.slice(0, limit);
}这段代码背后其实就是一句话:用户不是在“找一段文本”,而是在“找一个最像自己想找的链接”。所以排序不能只看是否命中,还得看命中强度、模糊相关性和历史使用行为。
这一层解决的不是“能不能搜”,而是“排得准不准”。
为什么我把地址栏搜索做进去:入口不短,工具就很难高频使用
很多效率工具的问题不是能力不够,而是入口太深。书签搜索尤其如此。你如果每次都要先去找扩展图标,再点开,再输入,久而久之就很容易放弃,直接用搜索引擎重新搜。看似只是多点几下,但这几下足够让一个高频动作变成低频动作。
所以我把地址栏搜索做成了第一入口。逻辑也很直接:
chrome.omnibox.onInputChanged.addListener((text, suggest) => {
const query = String(text || "").trim();
if (!query) {
chrome.omnibox.setDefaultSuggestion({
description: "输入关键词搜索书签,例如:支付 回调 或 sms"
});
suggest([]);
return;
}
ensureIndex()
.then(() => {
const results = scoreSearch(query, 6, { fuzzyCap: 120 });
suggest(
results.map((item) => ({
content: `bookmark://${item.doc.id}`,
description: formatOmniboxDescription(item)
}))
);
});
});这里其实做的不是“再加一个入口”,而是把入口往用户最自然的输入位置前移。地址栏本来就是浏览器里最顺手的输入区,让书签搜索直接发生在那里,使用成本会立刻下降一个层级。
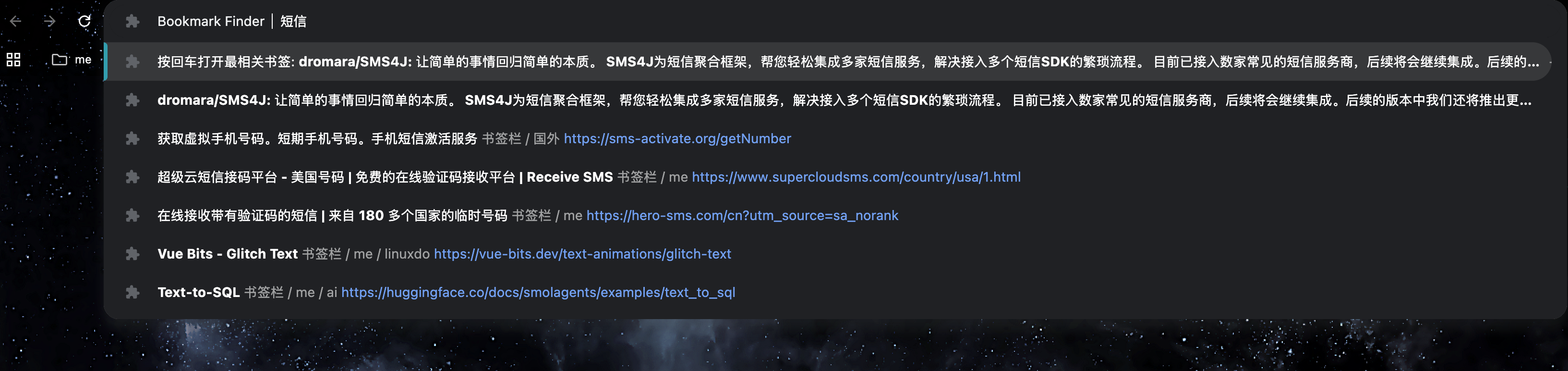
地址栏搜索
从截图也能看出来,搜索建议会直接出现在地址栏下方,这种体验和日常搜索非常接近,几乎不需要重新学习。
产品上的关键判断:
- 搜索能力只是下限
- 入口是否足够近,决定用户会不会真的高频使用
为什么我还要加快捷键:真正高频的工具,必须能靠肌肉记忆打开
地址栏搜索已经很顺了,但我还是加了快捷键呼出。原因很简单:当用户已经知道“我要搜书签”,这时最快的路径不是移动鼠标,也不是切到地址栏,而是直接按一个键。
manifest.json 里的这段配置就是为这个场景准备的:
"commands": {
"_execute_action": {
"suggested_key": {
"default": "Ctrl+Shift+K",
"mac": "Command+Shift+K"
},
"description": "Open Bookmark Finder"
}
}这个设计不花哨,但很关键。因为一旦形成肌肉记忆,搜索行为会从“我得先去找入口”变成“我直接开始找链接”。对于开发者、运营、产品这类频繁切后台和文档的人来说,这种改动比多几个设置项更有价值。
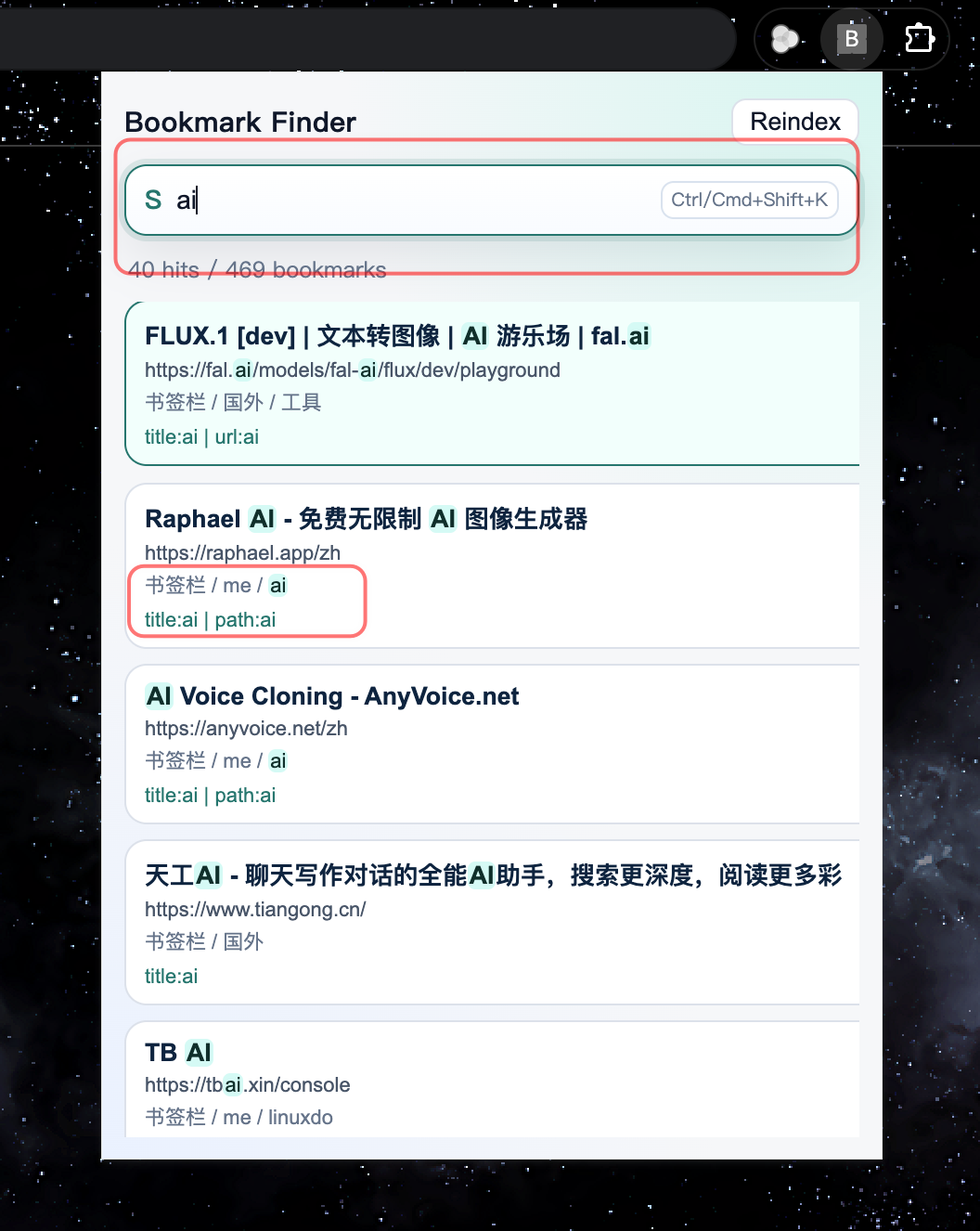
快捷键呼出搜索框
从截图能看到,搜索框本身也是围绕这个高频场景设计的:打开即聚焦、输入即检索、上下键选择、回车打开。工具链条越短,才越容易长期留下来。
地址栏搜索解决“顺手搜”,快捷键解决“立刻搜”。
为什么最近记录必须能删除:历史加速不等于历史堆积
很多工具做到“最近使用”这一步就停了,但我觉得这还不够。最近记录的确能提速,尤其是一些阶段性高频链接,比如某个后台、某个短信平台、某个调试页面,你今天点过,明天大概率还会再点一次。但如果最近记录只能一直累积,它很快也会变成新的噪音来源。
所以这个插件对最近查询和最近打开记录不仅支持展示,也支持单条删除和一键清空。
后台行为数据的结构很轻:
const MAX_RECENT_BOOKMARKS = 12;
const MAX_RECENT_QUERIES = 20;
const MAX_OPEN_HISTORY = 80;
function updateOpenHistory(bookmarkId) {
const id = String(bookmarkId);
const now = Date.now();
state.openHistory = [
{ id, ts: now },
...state.openHistory.filter((entry) => entry.id !== id)
].slice(0, MAX_OPEN_HISTORY);
}
function clearRecents() {
state.recentQueries = [];
state.openHistory = [];
}前端交互也没有做复杂,核心就是最近查询、最近打开、单条删除和清空:
clearRecentsBtn.addEventListener("click", async () => {
await sendRuntimeMessage({ type: "CLEAR_RECENTS" });
await showRecents();
});这种设计看起来很简单,但它决定了最近记录到底是“加速层”,还是“又一个越积越乱的列表”。我更希望它始终保持前者。
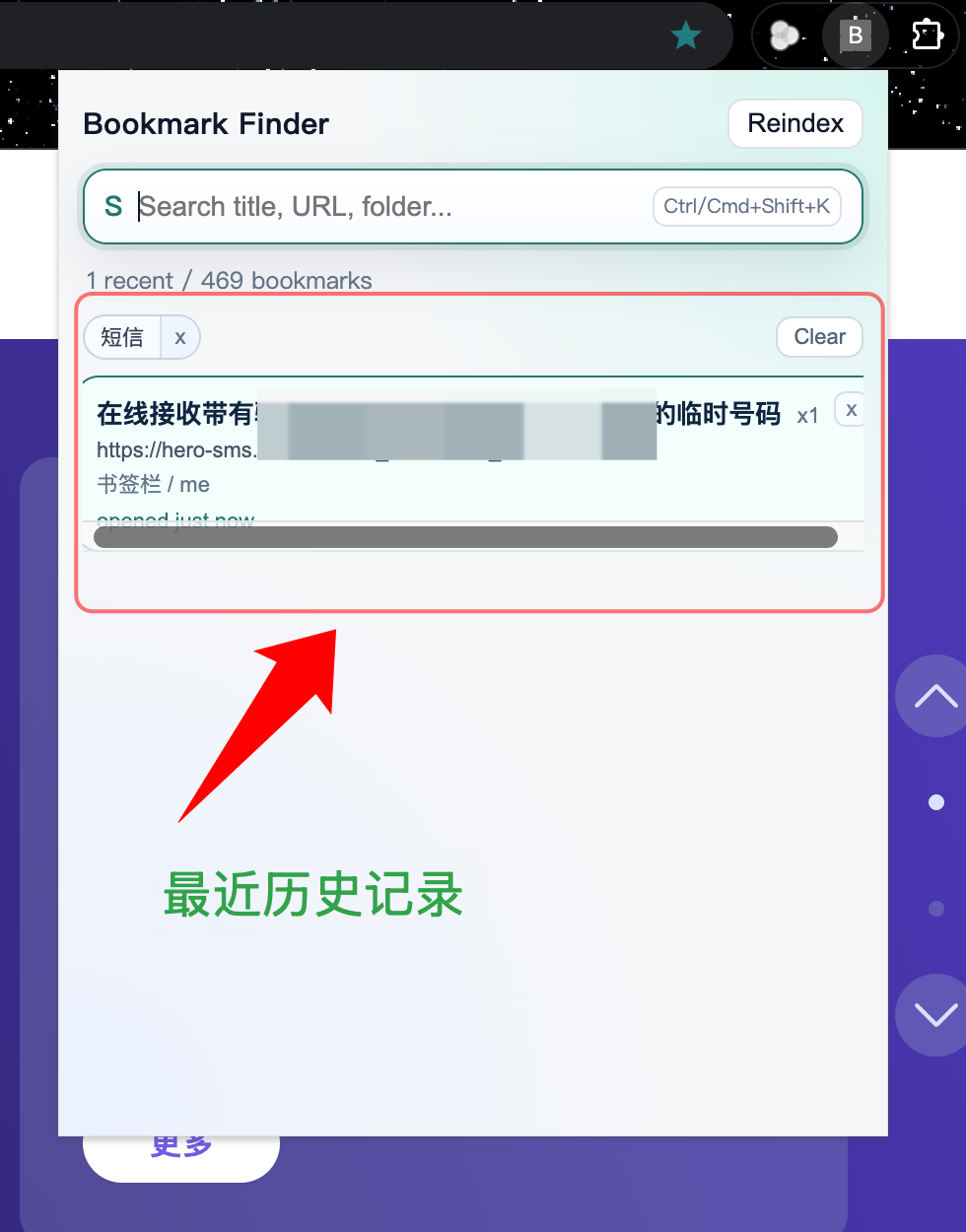
最近记录与删除管理
这里的重点不是“有最近记录”,而是“最近记录不会反噬体验”。
为什么第一版要克制性能和内存:书签搜索是高频动作,不能做重
我在这版实现里刻意压了一些高开销设计。因为这个插件是要高频开的,而不是偶尔运行一次就放着。如果一个工具每次打开都很重,哪怕它功能再多,最后也不会真正融入日常工作流。
所以这里做了几个明确的约束。
第一,限制超长字段参与索引,避免某些很长的 URL 或标题把 token 数量拉爆:
const MAX_FIELD_CHARS = {
title: 180,
path: 240,
url: 420
};第二,模糊相似度不是对所有文档都算,而是只对词法召回后的高分候选去算:
const MAX_FUZZY_EVAL = 300;
...
.slice(0, fuzzyCap);第三,文档级 ngram 是按需算的,不是把所有模糊特征都常驻内存。这个策略的核心是:先用更轻的词法索引筛一遍,再把更贵的模糊相似度放在候选集里做精排。
这样做的结果非常明确:第一版不用为了“看上去更智能”去承担过大的内存成本,也不用一上来就做全文抓取和远程同步。先把标题、路径、URL 三类元数据的搜索做好,已经足够解决大部分真实问题。
性能策略就一句话:
先用轻量索引做召回,再把更贵的计算放进小范围候选集里做精排。
这个插件真正解决的,不只是搜索问题,而是收藏价值流失的问题
如果一个人积累了几百上千条书签,但回头找的时候越来越依赖重新搜索网页,那这些书签的实际价值其实是在持续流失的。它们没有消失,但因为调取成本太高,变成了沉睡的存量。很多人说自己书签很多,其实真正的问题不是“多”,而是“多了以后找不回来了”。
Bookmark Finder 想解决的,就是这件事。
它不是让用户多一个复杂工具,而是把书签这件事从“静态收藏”重新拉回“动态可用”。你不用再过度依赖当时怎么分类,也不用因为只记得一个模糊词就重新上网搜一遍。只要你当时存过,它就更有机会在你今天需要的时候重新回来。
从产品角度看,这个插件最重要的不是它有多少功能点,而是每个功能点都在围绕同一件事收敛:让入口更短,让召回更强,让结果更可解释,让重复使用更顺,让高频动作不至于变重。方向对了,工具才会留下来。
所以如果要我用一句话概括这个插件,我不会说它是“一个书签管理器增强版”,我更愿意叫它“一个把旧链接重新找回来的工具”。因为对重度用户来说,收藏本身从来不是难题,真正有价值的,是当你再次需要它的时候,它还能足够快地回到你面前。
最后一句总结:
Bookmark Finder 解决的不是“怎么继续收藏”,而是“怎么把以前收藏过的东西重新调出来”。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号