数值模式|如何稳妥完成大量模式数据备份

数值模式|如何稳妥完成大量模式数据备份

用户11172986
发布于 2026-06-02 14:40:43
发布于 2026-06-02 14:40:43
超算实战|如何稳妥地完成大量模式数据备份
海量模式结果迁移,最怕的不是慢,而是拷到一半断掉还得从头再来。
1. 事情是怎么开始的
做气象数值模拟的人,对"大文件"这件事一般都不会陌生。
一个 WRF 个例,几十 GB 很正常;如果是长时段积分、集合预报、敏感性试验,目录体量很快就会上到几百 GB,甚至直接以 TB 为单位。平时这些数据躺在超算上问题不大,但一旦你要做归档、换机器、拷到移动硬盘、或者准备带回本地分析,麻烦就来了。
前段时间我就遇到一个很典型的场景:
- 当前工作目录总量接近 3TB;
- 其中有一个核心实验目录,大约 1.5TB;
- 其余脚本、后处理结果、图件、评估数据等零散内容,加起来也差不多 1.5TB;
- 手头有两个外挂硬盘,分别挂载到
/mnt/disk1和/mnt/disk2,每个盘都是 2TB。
目标很明确:
/mnt/disk1只放那个最核心的 1.5TB 大目录;/mnt/disk2放剩下的所有内容。
问题也很直接:
- 用
cp -r还是rsync? - 怎么避免拷到一半中断?
- 怎么后台运行?
- 怎么看进度?
- 怎么确认最终没漏文件?
这类问题,说白了不是"会不会命令",而是"怎么做更稳"。
2. 先别急着拷,先看目录到底有多大
我个人很不建议一上来就开拷。先把数据分布摸清楚,后面很多判断都会轻松不少。
最常用的命令就是:
du -h --max-depth=1
类似输出大概会长这样:
6.1G ./tools
3.6G ./model_output
1.2T ./ensemble_data
95G ./assimilation
1.5T ./core_experiment
... ...
3.0T .
这个结果一出来,事情就清楚了:
core_experiment是绝对的大头,单独放一个盘最合理;- 其余目录虽然零碎,但总量也不小;
- 两个 2TB 盘从容量上是够用的,但必须提前规划好分配方式。
很多时候,真正耽误时间的不是拷贝本身,而是你没先搞清楚目录结构,结果拷到一半发现盘满了,或者重复拷了一遍大目录。那个时候血压一般都不太稳定。
3. 这类任务,为什么我更推荐 rsync
很多朋友第一反应会是:
cp -r source target
这条命令当然没错,而且在"小目录、一次性、无所谓中断"的场景里,它也够用。
但如果场景换成:
- 文件总量几个 TB;
- 文件数量很多;
- 拷贝时间可能按小时算;
- SSH 连接可能中断;
- 移动硬盘可能偶发掉挂载;
- 任务可能需要重复执行;
那我基本都会优先选 rsync。
原因很简单,rsync 在这种场景里几乎是天然占优。
cp 和 rsync 的区别可以简单理解为:
场景 | cp | rsync |
|---|---|---|
首次全量拷贝 | 简单直接 | 稍有比对开销 |
中断后继续 | 往往只能重来 | 可以续传 |
后续增量同步 | 基本等于重拷 | 只同步变化部分 |
文件属性保留 | 需要额外参数 | -a 一步到位 |
查看进度 | 不方便 | 很方便 |
适合超算大目录迁移 | 一般 | 很合适 |
最关键的一点是:rsync 不怕你重复执行。
第一次没传完,第二次接着跑就行;已经传过去的部分,它会自动跳过或校验。对于几百 GB、几 TB 的任务来说,这种"可恢复性"非常重要。
说得直白一点:
cp更像一次性搬家,rsync更像一个可以随时续上的搬运系统。
4. 这次任务的执行思路
我的处理思路其实很朴素,就两步:
- 先把最大的核心目录单独拷到
/mnt/disk1; - 再把当前目录剩下的内容,排除掉这个核心目录后,同步到
/mnt/disk2。
逻辑上可以画成下面这个流程:
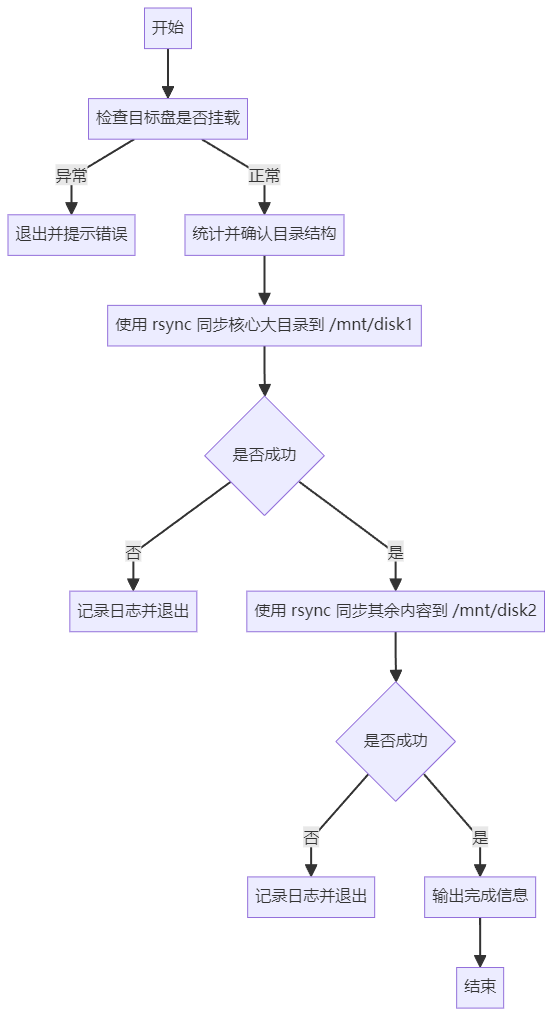
image
image
这里我特意没有做真正的"并行拷贝"。
原因也很现实:如果两个超大 rsync 同时打满同一套 IO,尤其是在登录节点或者共享存储上,很多时候不一定更快,反而更容易互相抢资源。所以这类任务我一般更倾向于顺序执行,稳一点。
5. rsync 里最值得理解的几个参数
很多人会抄一条 rsync 命令去用,但不太清楚参数含义。其实把几个核心参数搞懂之后,后面你自己就能灵活变形。
5.1 -a:归档模式
-a
这是最常见也最重要的参数之一。
它本质上相当于一组参数的组合,能帮你:
- 递归拷贝目录;
- 保留符号链接;
- 保留权限;
- 保留时间戳;
- 保留属主属组;
- 保留设备文件等元信息。
如果你拷的是模式输出、脚本、后处理文件,通常都希望尽量保留原始结构和属性,那 -a 基本是默认选项。
5.2 -v:详细输出
-v
这个参数不复杂,就是让 rsync 多说话。
在大任务场景里,我反而很喜欢它。因为你最怕的不是程序慢,而是终端半天没反应,你开始怀疑它是不是卡住了。-v 至少能让你知道它还在干活。
5.3 -P:进度条 + 断点续传
-P
这是个很实用的组合参数,等价于:
--partial --progress
它带来的两个好处非常关键:
- 显示实时进度;
- 保留未完成的部分,便于续传。
尤其是第二点,在超大文件迁移时非常重要。假设一个几百 GB 的文件已经传了 80%,中断后如果不能续传,那是真的难受。-P 能帮你把这个问题大大缓解掉。
5.4 --stats:任务完成后给你一个统计结果
--stats
这个参数会在同步结束后输出一些统计信息,比如:
- 总文件数;
- 总字节数;
- 实际传输量;
- 传输速率;
- 匹配文件数等。
它的好处是,你后面核对任务是否完整时,不必完全靠肉眼看日志,有一组整体统计数据做参考会更安心。
5.5 --exclude:排除某个目录
--exclude="core_experiment"
这个参数就是第二步任务的核心。
因为第一步已经把 core_experiment 单独传走了,所以第二步同步整个源目录时,一定要显式排除掉它。否则你会在第二块盘上再拷一遍,直接把空间打爆。
这个错误在实战里非常常见,不是不会写命令,而是忙起来时容易忘。
5.6 --append-verify:超大文件续传时可考虑
这个参数不是每次都必须用,但对于极大的单文件同步,它有时很好用:
--append-verify
它的思路是:
- 对已有部分采用追加方式写入;
- 同时做校验,避免文件损坏。
如果你拷的是超大二进制文件、单体很大的输出文件,可以按需考虑。但对一般目录迁移来说,-aP 往往已经够用了。
6. 一个可直接复用的脚本
下面这份脚本,就是我比较推荐的实战写法。
它做了几件事:
- 检查两个目标挂载点是否存在;
- 先同步核心大目录到第一个盘;
- 再同步剩余内容到第二个盘;
- 全程写日志;
- 某一步失败就直接退出,不继续往下跑。
#!/bin/bash
# ============================================================================
# 脚本名称: copy_data.sh
# 功能描述: 将核心大目录单独拷贝到第一个硬盘,其余内容拷贝到第二个硬盘
# 使用方法: nohup ./copy_data.sh &
# 日志文件: /tmp/copy_data.log
# ============================================================================
# ---------- 用户配置区域 ----------
SOURCE_DIR="." # 源目录(当前目录,可改为绝对路径)
BIG_DIR_NAME="core_experiment" # 需要单独拷贝的核心大目录名
DEST1="/mnt/disk1" # 第一个目标盘(存放核心大目录)
DEST2="/mnt/disk2" # 第二个目标盘(存放其余内容)
LOG_FILE="/tmp/copy_data.log" # 日志文件路径
# ---------------------------------
# 检查目标挂载点是否存在
if [ ! -d "$DEST1" ]; then
echo"错误:目标目录 $DEST1 不存在,请检查挂载。" | tee -a "$LOG_FILE"
exit 1
fi
if [ ! -d "$DEST2" ]; then
echo"错误:目标目录 $DEST2 不存在,请检查挂载。" | tee -a "$LOG_FILE"
exit 1
fi
# 记录开始信息
echo"========================================" | tee -a "$LOG_FILE"
echo"开始拷贝任务: $(date)" | tee -a "$LOG_FILE"
echo"源目录: $(realpath $SOURCE_DIR)" | tee -a "$LOG_FILE"
echo"目标1(存放 $BIG_DIR_NAME): $DEST1" | tee -a "$LOG_FILE"
echo"目标2(存放其余内容): $DEST2" | tee -a "$LOG_FILE"
echo"========================================" | tee -a "$LOG_FILE"
# 1. 拷贝核心大目录到 DEST1
echo"[1/2] 开始拷贝 $BIG_DIR_NAME 到 $DEST1/$BIG_DIR_NAME ..." | tee -a "$LOG_FILE"
rsync -avP --stats "$SOURCE_DIR/$BIG_DIR_NAME/""$DEST1/$BIG_DIR_NAME/" >> "$LOG_FILE" 2>&1
if [ $? -eq 0 ]; then
echo"[OK] $BIG_DIR_NAME 拷贝完成: $(date)" | tee -a "$LOG_FILE"
else
echo"[ERROR] $BIG_DIR_NAME 拷贝失败,请检查日志 $LOG_FILE" | tee -a "$LOG_FILE"
exit 1
fi
# 2. 拷贝其余内容到 DEST2
echo"[2/2] 开始拷贝剩余内容(排除 $BIG_DIR_NAME)到 $DEST2 ..." | tee -a "$LOG_FILE"
rsync -avP --stats --exclude="$BIG_DIR_NAME""$SOURCE_DIR/""$DEST2/" >> "$LOG_FILE" 2>&1
if [ $? -eq 0 ]; then
echo"[OK] 剩余内容拷贝完成: $(date)" | tee -a "$LOG_FILE"
else
echo"[ERROR] 剩余内容拷贝失败,请检查日志 $LOG_FILE" | tee -a "$LOG_FILE"
exit 1
fi
echo"========================================" | tee -a "$LOG_FILE"
echo"全部拷贝任务完成: $(date)" | tee -a "$LOG_FILE"
echo"========================================" | tee -a "$LOG_FILE"
7. 实际运行时怎么用
7.1 保存脚本并加执行权限
vi copy_data.sh
chmod +x copy_data.sh
把里面的 BIG_DIR_NAME 改成你自己的大目录名就行。
7.2 用 nohup 放后台跑
nohup ./copy_data.sh &
这是我在超算上非常常用的方式。
因为一旦你是 SSH 登录环境,就要默认接受一个现实:终端会断,网络会抖,人会下班。把任务丢到后台,是对自己情绪最友好的处理方式。
7.3 实时看日志
tail -f /tmp/copy_data.log
如果 rsync 正在正常工作,你一般能看到类似这样的输出:
6,540,123,456 15% 112.34MB/s 0:35:20
这个时候你就知道,程序没死,还在老老实实搬数据。
7.4 看任务还在不在
ps aux | grep copy_data.sh
如果你想进一步确认 rsync 本身,也可以直接查:
ps aux | grep rsync
8. 实战里几个很容易踩的坑
8.1 目标盘"目录存在"不等于"挂载正常"
这个问题特别常见。
有时候 /mnt/disk1 这个目录还在,但真正的移动硬盘已经掉挂载了。你如果不检查,就可能把数据误拷到系统盘目录下,等发现时已经晚了。
所以更稳一点的做法,其实是配合 df -h 一起看:
df -h /mnt/disk1
df -h /mnt/disk2
确认它们确实对应你想要的设备。
8.2 日志别放在源目录里
这点看起来细枝末节,但我建议一直养成习惯。
如果日志文件写在源目录下,而你又在同步整个源目录,日志本身也可能被同步走,轻则干扰结果,重则造成一些重复写入和混乱。放到 /tmp/ 或者其他独立路径更省心。
8.3 不建议一开始就双任务并发
理论上你可以同时开两个 rsync:
- 一个往
/mnt/disk1传; - 一个往
/mnt/disk2传。
但实战里不一定值。
如果源数据都在同一套存储上,双任务很可能一起抢读 IO;如果目标又是 USB 外挂盘,还可能一起抢写带宽。最后结果常常不是"两倍快",而是"大家都不快"。
所以我的建议是:
如果你没有做过带宽和 IO 评估,先顺序执行,稳妥优先。
8.4 任务中断后不要删目标,直接重跑
这是 rsync 最大的优势之一。
如果中间断了,不要手忙脚乱去清空目标目录,直接重新执行同样的命令或脚本即可。它会自动识别哪些已经同步完成,继续处理剩余部分。
这也是为什么我在大文件迁移场景里,很少愿意回到 cp。
9. 拷贝完成后,怎么做一个最基本的验证
最简单的检查方法,就是先对比体量。
du -sh core_experiment
du -sh /mnt/disk1/core_experiment
再看剩余内容:
du -sh --exclude=core_experiment .
du -sh /mnt/disk2
如果你想更严谨一点,也可以再用 rsync 的 dry-run 做一次"空跑校验":
rsync -avn --exclude="core_experiment" ./ /mnt/disk2/
如果输出里几乎没有需要同步的内容,说明目标和源已经基本一致。
这一招我个人很喜欢,因为它比单纯看 du 更细。
10. 小结:这类任务,核心不是命令多高级,而是流程要稳
回头看,这次 3TB 数据迁移真正有用的,不是什么"神秘黑科技",而是下面这几件很朴素的事:
- 先用
du看清目录结构; - 提前规划两个目标盘各放什么;
- 用
rsync而不是cp; - 用日志记录过程;
- 用
nohup放后台,接受任务会很久这件事; - 出现中断时直接重跑,不要慌。
很多超算实战问题,本质上都不是"不会",而是"第一次做的时候不够稳"。而一旦你把流程走顺了,后面无论是模式归档、实验搬迁,还是长期结果备份,都会轻松很多。
如果你现在也正好要迁移 WRF、MPAS、后处理图件或者观测资料,我个人觉得这套思路是值得直接拿去用的。至少它能帮你避开一个非常典型、也非常消耗耐心的坑:
拷了一晚上,早上起来发现中断了,而且还得从头开始。
这个事,谁遇到谁知道。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号