IM分布式架构系列(16) 移动端一直connecting | TCP网络故障排查
原创
IM分布式架构系列(16) 移动端一直connecting | TCP网络故障排查
原创
拉丁解牛说技术
发布于 2026-06-26 00:57:00
发布于 2026-06-26 00:57:00
IM系统经常要面对的移动端 TCP 连不上,九成根因落在 DNS 解析、运营商链路、云入口三处,几乎不在接入层进程本身。
一、网络异常排查:从一条"重连中"说起
二、这条 TCP 怎么一跳一跳连到服务端TCP端口
三、业界怎么做移动接入
四、连不上时怎么逐跳定位排查
一、网络异常排查:从一条"重连中"说起
测试同学发来一张截图:App 顶部挂着"连接中…"转了十几秒,然后变成"网络不可用",过一会儿自己又好了。这种问题几乎每个做 IM 的团队都遇到过——它不报错码、不崩溃、不在服务端日志里留下任何痕迹,因为那条 TCP 压根没连上来,服务端根本不知道有人来过。
但这个问题细扣起来:移动端那条长连接,到底是怎么连到服务端的?又断在了哪一跳? 简单的说,服务端对外的 TCP 地址写在配置里,长这样:xx.xx.com:8200,一个域名加一个端口。客户端拿到它,要先把域名解析成 IP,再发起握手;这中间要穿过家里的 WiFi 或楼下的蜂窝基站、运营商核心网、公网骨干、云服务商最外层的入网设施,最后才落到接入层进程监听的 8200端口。每一跳都可能是"连不上"的真凶,归因方式还各不一样。
今天我们专讲传输层及以下:DNS 怎么解析、TCP 怎么握手、字节怎么一跳一跳穿过运营商和云入口,以及连不上时怎么逐跳定位。这个聊起来很有意思!
1.1 这条 TCP 在 IM 链路里的位置
对于移动端操作系统 or 我们服务端系统都一样,当需要建立一条长连接,需要两个系统级的调用动作,首先: getaddrinfo(域名换 IP),再 connect(对着 IP:Port 发起握手)。IM 客户端所有花活——加密、协议、心跳、鉴权——全建在这两步成功之后。任一步卡住,用户看到的都是同一个"连接中"。
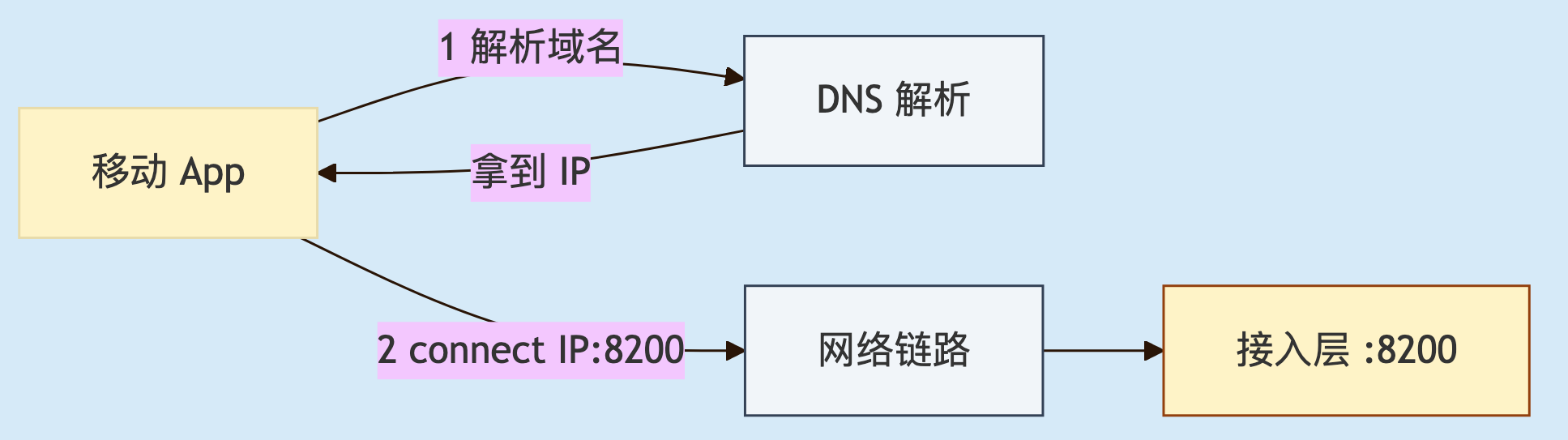
一条长连接的两个动作:域名解析、握手连接。
我们一般人,脑子里有这张图足够:客户端直连服务端。但是,真正的真相是中间那个"网络链路"框里藏着至少五六跳,每一跳都做了一次转换和转发——接下来一个个看。
1.2 排查时绕不开的三类归因
现实过程排查网络问题,我们复盘下来,"移动端连不上 / 反复重连"的根因绝大多数落在三个区域:
- 客户端的本地网络:典型是某个办公网络丢包严重,握手 SYN 发出去收不到回应,超时报失败。换个网就好——恰恰说明问题不在服务端(这个最近监控非常频繁预警,尤其国外基础设施不好的地区)。
- 云最外层入网:公网 IP、负载均衡、安全组、入口网关,任一处异常都会让握手到不了接入层进程。这类最隐蔽,因为进程本身是健康的。
- 中间运营商网络:移动到云之间隔着运营商核心网和公网骨干,某条链路抖动或跨网绕路,表现为时通时断、特定地区特定运营商连不上。
这三类的共同特征是:问题都不在接入层进程本身,但第一反应都会怀疑服务端。要快速定位真凶,得先理解这条 TCP 究竟经过了哪些环节。
二、这条 TCP 怎么一跳一跳连到 :8200
这一节,我们把每一跳讲透——只有理解了链路,后面第四部分排查故障就不需要背命令,而是知道每条命令在验证哪一跳。
2.1 第一步:把 xx.xx.com 解析成 IP
connect 只认 IP 不认域名,所以客户端第一件事是把 xx.xx.com 换成一个像 203.0.113.10 的地址。这个过程叫 DNS 解析:客户端只向 LocalDNS(运营商或路由器提供)问一句,LocalDNS 替它一级级向上追问根域名、.com 顶级域、xx.xx.com 权威服务器,拿到 IP 再回答客户端。
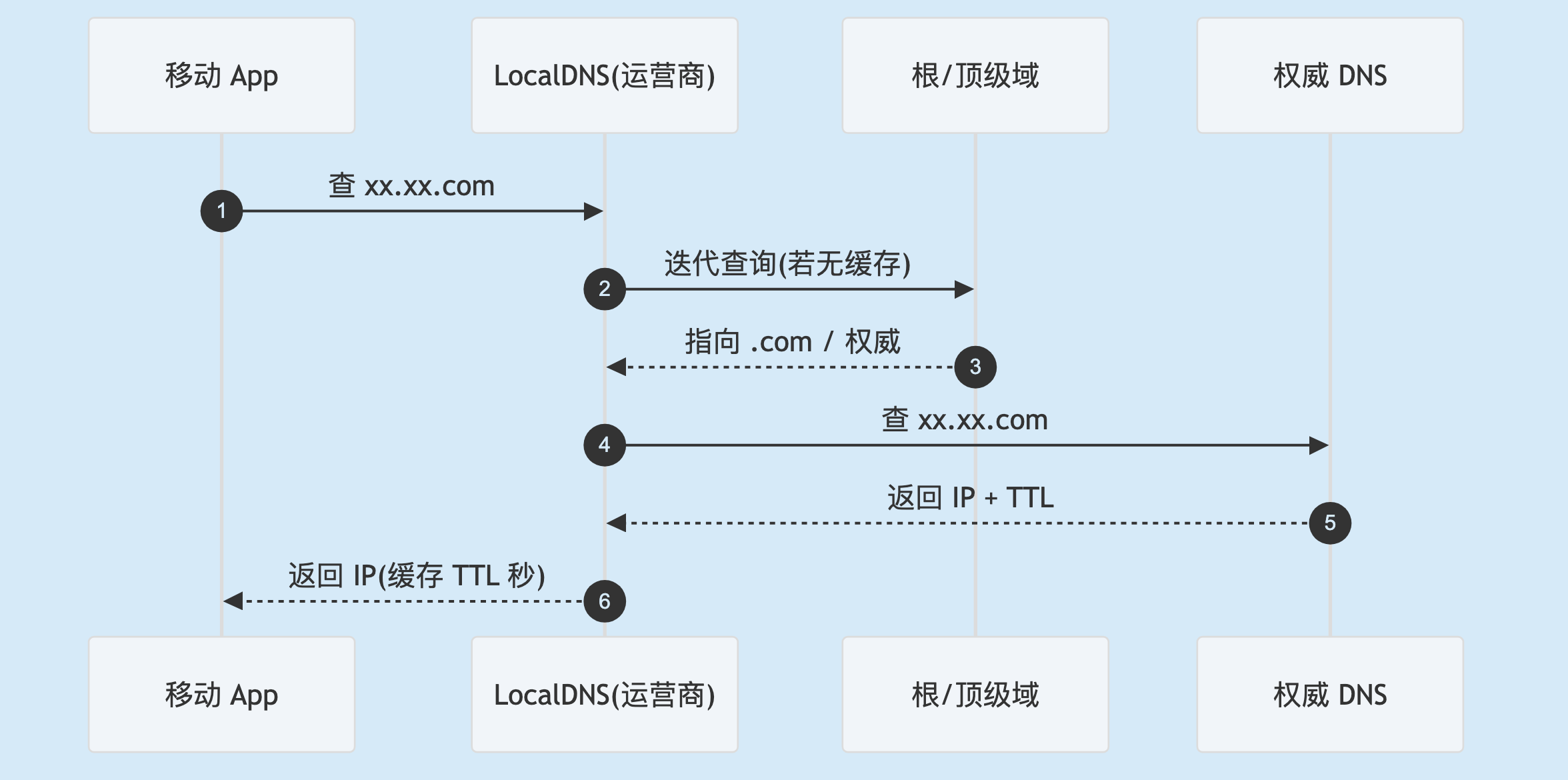
DNS 递归解析的一来一回。LocalDNS 命中缓存时直接返回,跳过中间几步。
这里有个关键变量叫 TTL(Time To Live):权威 DNS 返回 IP 时附带"这条记录可缓存多少秒",TTL 内各级缓存直接复用。TTL 是把双刃剑——设长了解析快,但想切 IP 时旧 IP 会在各级缓存里滞留很久;设短了切换灵敏,但解析频繁。IM 接入域名通常把 TTL 设得偏短(几十秒到几分钟),换取故障时快速切流。
2.2 移动端 DNS 的几个坑
桌面环境里 DNS 一般很乖,移动端就不一样了。几类常见坑:
- 解析慢:弱网下一次 UDP 解析可能几百毫秒甚至超时重试,用户的"连接中"有时纯粹卡在解析这一步,TCP 连接都还没开始,就GG了。
- 调度不准:LocalDNS 按它自己的位置而非用户真实位置做地理调度,可能解析到物理上很远的接入点,延迟陡增。
- 劫持 / 污染:少数网络里 LocalDNS 会把域名解析到不属于你的 IP(缓存投毒、中间设备改写应答),表现为连到莫名其妙的地址或直接连不上。
- 缓存脏数据:权威侧已切了 IP,用户侧 LocalDNS 还在 TTL 内返回旧 IP,一部分用户始终连向已下线的入口。
这些坑,主要是 HTTPDNS 要解决的。这里,我们可以了解到:移动端连不上,相当一部分根因在解析阶段而非握手阶段,所以我们的网络故障排查,不能跳过 DNS,更不应该直接怀疑TCP连接。
2.3 TCP 三次握手到底在握什么
域名换成 IP后,connect 才真正开始。TCP 建连要握三次手,本质是双方各自确认"我能发能收,你也能发能收":
客户端 ──SYN(seq=x)─────────────▶ 服务端 // 我想连,我的起始序号是 x
客户端 ◀──SYN-ACK(seq=y,ack=x+1)─ 服务端 // 收到;我也想连,我的序号是 y
客户端 ──ACK(ack=y+1)───────────▶ 服务端 // 收到,握手完成,连接 ESTABLISHED每一步在干一件具体的事:
- 第一次 SYN:客户端发出建连请求带初始序号,进入
SYN_SENT等回应。 - 第二次 SYN-ACK:服务端确认客户端能发,同时回上自己的 SYN,把这条半成品连接放进半连接队列(SYN backlog)。
- 第三次 ACK:客户端确认收到服务端的 SYN,连接建立,从半连接队列挪进全连接队列(accept queue),等应用层
accept取走。
理解这三步,排障时就能读懂现象:发了 SYN 收不到 SYN-ACK,要么 SYN 在路上被丢(链路丢包、被防火墙/安全组拦截),要么服务端收到没回(监听没起、半连接队列满),客户端按指数退避重传,全部超时后报"连接失败"——这就是"连接中"转很久;偶尔成功偶尔失败是典型链路丢包,SYN 丢了重传命中就成功;能连上但很慢则是每次 SYN 都要重传一两次才通,按秒级退避把连接耗时拉长。
一个经常被忽略的点:客户端"连接超时"和服务端"拒绝连接"是两回事。收到 RST 是拒绝(端口没监听、被安全组 reject),明确且快速;收不到任何回应才是超时(丢包、被 drop),要等满重传周期。这两个现象指向完全不同的根因,排障时第一步就要分清。
2.4 逐跳:手机到云入口走过谁
现在把"网络链路"黑盒拆开。一条发往 xx.xx.com:8200 的 TCP 实际要穿过这几跳:
- 手机 → 接入网:经家里/公司的 WiFi AP,或楼下蜂窝基站接入,手机此时拿到的往往是私有地址。
- 接入网 → 运营商核心网:流量汇聚到核心网,这里有一道关键设施 NAT(网络地址转换),把手机私有地址映射成公网地址端口,对端看到的源地址就是它。
- 核心网 → 公网骨干:经运营商间互联骨干网,跨网时可能绕路(跨运营商访问慢的常见原因)。
- 公网骨干 → 云最外层:到达云入口,依次是公网 IP(绑在 LB 上)→ 安全组/网络 ACL(决定源 IP、端口放不放行)→ 负载均衡 / 入口网关(转发到后端某个接入层实例)。
- 云入口 → 接入层进程:LB 选定一台后端,把 TCP 转发到
:8200,三次握手在这里真正完成。
容易搞混的是:手机以为"我直连了 xx.xx.com:8200",实际上链路上有多个设备替它做接力和转换——运营商 NAT 改写源地址端口,云负载均衡又把连接转发给后端实例。手机视角只有一条连接,链路视角它被拆成了好几段。
2.5 运营商核心网的 NAT 连接映射
NAT 是"连接为什么莫名其妙断"的常见嫌疑。移动网络里设备几乎都没有独立公网 IP,多台设备共享少量公网地址出网。NAT 设备(家用路由器、运营商 NAT 网关)维护一张连接映射表,每条出向连接记一行 内网地址:端口 ↔ 公网地址:端口:手机发出的包源地址被改写成公网侧,对端回包按表反向改写回内网地址送回手机。

对 IM 长连接来说,NAT 有两个直接影响:
- 映射有老化时间:一条连接一段时间没数据来往,NAT 会回收表项腾空间。这条映射一旦被回收,对端再发数据就找不到路,连接在用户那头"假死"——心跳维持连接活性的根本依据正在这里。
- 多设备共享一个公网 IP:服务端看到的源 IP 可能是整栋办公楼共享的出口 IP,不能简单按源 IP 限流或封禁,否则误伤一片真实用户。
理解了 NAT 就能解释一类现象:客户端这边连接好好的、状态 ESTABLISHED,但服务端早就收不到数据——中间某个 NAT 把映射悄悄回收了。
2.6 全链路拓扑与时序
把前面几跳串成一张完整时序图:
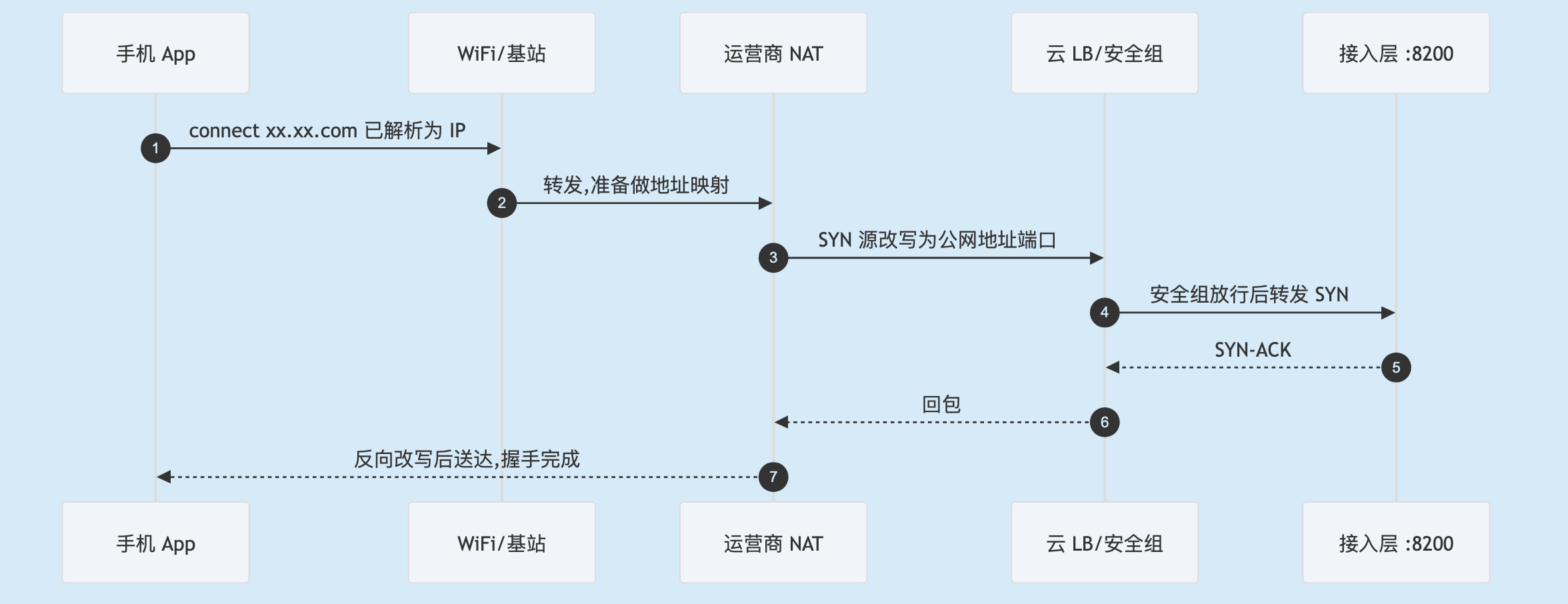
一条 TCP连接 从手机到 :8200 的全链路时序。任意一跳卡住,用户都看到"连接中"。
这张图的价值在于:有人说"移动端连不上"时,脑子里要有图这条多跳链路。排障的本质就是沿这条链路逐跳确认包走到哪一跳就断了——脑子里有这条链路,定位才不靠猜。
三、业界怎么做移动接入
移动接入的传输层优化,公开资料里讲得最透的是某信的 mars(其移动端网络层跨平台组件,开源)。它把"在烂网络下尽快连上、连上后稳定"打磨得很细。
3.1 某信 mars 的复合连接与 IP 排序
mars 的信令网络层(STN)要解决的核心问题是:移动网络下怎么用最短时间、最低服务端负载连上一个可用入口。它的做法叫复合连接。
按公开分享描述,纯并发连接(同时对所有候选 IP 发 connect)最快,但给服务端带来连接竞争压力;纯串行(连不上才试下一个)服务端友好,但弱网下一个个超时太慢。复合连接折中:先对第一个 IP:Port 发 connect,到第 4 秒还没返回再并发对第二个发 connect,以此类推,最多并行 5 路(4 路常规候选 + 1 路保底),第一个连上的胜出、其余取消——既不会一上来压垮服务端,又能在首选 IP 不通时快速切换。
候选 IP 怎么排序也有讲究。mars 的 IP&Port 排序经历三代演进:随机组合(随机配对快速探活,但容易把可用资源都试坏)→ 以史为鉴(记录每个 IP 成败历史,优先用成功率高的)→ 遗忘历史(给历史加 24 小时刷新和恢复探测,避免某 IP 短暂故障后被永久打入冷宫)。
值得注意的是它的 IP 来源分级,对应 §2.2 的 DNS 坑:WXDNS IP(自家 HTTPDNS 下发)、DNS IP(常规 LocalDNS 解析)、Auth IP(登录时服务端下发的保底列表)、Hardcode IP(写死在客户端的最终兜底)。前两类是常规来源,后两类是"DNS 全挂了也能连上"的兜底。
维度 | 详情 |
|---|---|
优势 | 弱网下连接成功率与速度兼顾; 服务端不被并发握手打满; DNS 不可用时有多级保底 IP 兜底; 历史排序减少无效尝试 |
代价 | 实现复杂度高,一套连接状态机要管多路并发与取消; 保底 IP 列表需要持续维护,写死的 Hardcode IP 一旦机房下线就是死地址; 多路并发探测本身会放大短时握手量 |
mars 这套打磨是为 toC 海量弱网用户场景服务的——连接成功率每提升一个百分点,背后都是巨大的活跃用户基数。mars 这套打磨,在面对海量 toC场景,这个投入量级是值得的。
3.2 mars 的 HTTPDNS 与 IP 直连
mars 那套 IP 来源分级里排第一的 WXDNS,本质就是 HTTPDNS:某信不再用 DNS 协议向运营商 LocalDNS 查询,而是用 HTTP 直接向自家解析服务请求 IP,一举绕开 §2.2 列的几乎所有 LocalDNS 坑——不被劫持,不受调度不准影响(自家服务能拿到客户端真实出口 IP 做就近调度),TTL 自己掌控。
拿到 IP 后 mars 走 IP 直连:直接对 HTTPDNS 返回的 IP 发 connect,省掉一次解析往返;拿不到时才退回 §3.1 那条来源链。前面的复合连接,正是在这批候选 IP 之上做的多路竞速。连接失败后的重连也不是死循环,而是用指数退避加随机抖动拉长间隔,避免一片用户在网络恢复瞬间同时重连把入口打垮。
这套"HTTPDNS 解析 + 多源 IP + 复合连接 + 退避重连"组合拳,对某信级别的海量弱网用户是标准配置。
四、连不上时怎么逐跳定位
4.1 一条从客户端到服务端的归因路径
把链路分成四层,每层用对应工具确认,哪层断了就停在哪层深挖:
层 | 验证什么 | 常用工具 | 断在这层的现象 |
|---|---|---|---|
DNS 层 | 域名解析对不对、快不快 | dig / nslookup / HTTPDNS 接口自测 | 解析慢、解析到错误 IP、解析超时 |
连通性层 | 包能不能到、哪一跳开始丢 | ping / traceroute / mtr | 某一跳起丢包率飙升、延迟陡增 |
握手层 | 端口通不通、SYN 有没有回 | telnet / nc / tcpdump | SYN 发出无 SYN-ACK,或收到 RST |
服务端层 | 进程在不在听、队列满没满、入口放没放行 | ss / netstat / LB 健康检查 / 安全组 | 端口没监听、accept 队列满、安全组拦截 |
排查顺序就从上往下走。下面用三个脱敏案例把它串起来,每个给"现象 → 怎么验证 → 根因 → 结论"。
4.2 案例一:公司网络丢包导致握手超时
现象:测试同学在公司办公网里 App 长时间"连接中"后报失败;同一台手机切到 4G 立刻就好。
怎么验证:
- 排除 DNS:公司网络里
dig xx.xx.com解析正常、IP 和 4G 下一致——DNS 不是问题。 - 测连通性:
mtr xx.xx.com连续探测,从公司出口往外某一跳开始丢包率 30%+,后面每跳都跟着丢。 - 看握手:
tcpdump抓到客户端反复发 SYN、零星收到 SYN-ACK,大部分 SYN 石沉大海;telnet xx.xx.com 8200不稳定,时通时不通。
根因:公司出口链路丢包严重,SYN 大概率丢失。TCP 按指数退避重传,撑到总超时仍未握手,报"连接失败"。问题在本地网络,与服务端无关。
结论:这是之前讲的"发了 SYN 收不到 SYN-ACK"的典型。判据三件套——换网即好 + mtr 显示本地出口段丢包 + 抓包看 SYN 无回应。处理方向是本地网络治理。
4.3 案例二:云最外层入网异常
现象:所有地区、所有运营商的用户都连不上或大面积重连,但接入层进程监控一切正常、CPU 内存都很闲,服务端日志里没有新连接进来。
怎么验证:
- DNS 正常,解析出的公网 IP 也对。
telnet 公网IP 8200直连 IP,超时或收到 RST——绕过域名直连入口都不通。- 登到接入层机器
ss -lntp看:8200,进程在正常监听,本机telnet 127.0.0.1 8200通——进程是好的,是外面进不来。 - 怀疑点上移到云入口:查 LB 后端健康检查、安全组/网络 ACL、公网 IP 绑定。常见真凶是安全组被误改、LB 把后端全判为不健康而摘除、公网带宽被打满。
根因:接入层进程健康,但云最外层入网环节(LB / 安全组 / 公网 IP)出了问题,握手包到不了进程。
结论:这类最隐蔽,"进程正常"会让人误判没问题。判据是本机直连进程通、外部直连公网 IP 不通、且全网用户同时受影响。排查重点是云入口配置而非应用进程。
4.4 案例三:运营商网络问题
现象:只有特定地区 + 特定运营商的用户连不上或延迟极高,其他地区运营商正常;问题来去无常,可能几小时后自愈。
怎么验证:
- DNS 正常。
- 用受影响地区/运营商的网络(或让当地同事配合)跑
mtr xx.xx.com,对比正常路径:受影响链路在进入某个骨干互联节点后丢包或绕远(本该就近的流量被绕到外省)。 - 换一个出口 IP / 换接入点(若有多地域多入口)测试,连另一个地域入口就正常——不是服务端,是到原入口的运营商链路出了问题。
根因:运营商核心网或跨网互联骨干的链路抖动 / 绕路,问题在中间运营商网络,两头都没错。
结论:判据是地域/运营商相关 + mtr 显示中间骨干段异常 + 切换入口可规避。自己改不了运营商,但架构上可缓解——多地域多入口 + HTTPDNS 把受影响用户调度到健康入口。
4.5 从这些故障反推的设计取舍
三个案例的根因分别落在本地链路、云入口、运营商。反过来看,接入层在传输层能做的"防患",就是把这三类故障的影响面提前压小。下面几点是从故障倒推的取舍,不是照搬 mars——中小 toB IM 的判断标准和某信不一样。
HTTPDNS + 域名兜底,什么时候值得做。 运营商案例里能救场的只有"把受影响用户调度到另一个健康入口",而 LocalDNS 既看不到用户真实位置、又可能被缓存脏数据卡住——这正是 HTTPDNS 的价值。但它不免费:多一个解析服务要维护、要处理它自身不可用时的回退。但这个很简单:只要出现过"某地区/某运营商集中连不上、换网就好"的工单,就值得上;纯内网或固定园区的 toB 场景可以缓。落地最简形态是 IP 直连加域名回退两层。
心跳间隔不能脱离 NAT 老化时间拍脑袋定。 的 NAT 映射老化是"假死连接"的物理根源。心跳间隔的本质是要短于链路上最激进的那个 NAT 老化时间,否则映射先被回收、连接假死,心跳成了马后炮;但间隔越短越费电费流量。工程上的折中是按网络类型分档——蜂窝 NAT 老化通常比 WiFi 激进,蜂窝下用更短心跳、WiFi 下放宽,而不是全局一个固定值。具体阈值得靠线上实测各运营商的连接存活曲线标定,没有放之四海的数字。
把三类归因沉淀成分层可观测。 逐跳排障不能每次靠人肉抓包。把案例里的"判据"变成指标:客户端侧把连接耗时拆成 DNS 解析耗时、TCP 握手耗时两段分别上报,再带上失败类型(解析失败 / 握手超时 / 收到 RST)和网络环境(运营商、大致地域、WiFi/蜂窝),就能直接区分 "全网炸" 还是"某运营商炸";服务端侧守住半连接和全连接队列水位——队列满会丢 SYN、握手失败,但进程看起来一切正常,极易误判成"客户端问题"。客户端 metric 定位"断在哪一层",服务端 metric 排除"是不是我的锅",两边对齐了就可以形成闭环。
弱网退避和多 IP 竞速,中小 IM 应该抄到哪一步。 复合连接那套多路竞速对海量弱网用户收益明显,但对连接基数小、弱网占比低的 toB 场景,多路并发探测带来的额外握手量未必划算。我感觉是:退避重连(指数退避 + 随机抖动)必做,成本极低、还能防住网络恢复瞬间的惊群;多 IP 竞速等确实拿到了多个候选入口(比如上了多地域部署)再做。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号