程序员专属:OpenClaw 自动查 bug、生成注释完整流程
原创
程序员专属:OpenClaw 自动查 bug、生成注释完整流程
原创
大盘鸡拌面
发布于 2026-06-26 16:35:45
发布于 2026-06-26 16:35:45
在日常开发工作中,绝大多数程序员都会陷入重复性的低效劳作。除了核心业务逻辑开发,我们每天要花费大量时间排查低级代码bug、补全代码注释、规范代码格式、梳理代码逻辑漏洞。尤其是迭代紧急的业务需求时,快速写完功能代码后,很容易忽略边界条件判断、参数校验、异常捕获等细节问题,导致测试阶段频繁报bug,后续返工修复耗时耗力。同时,潦草的无注释代码,不仅不利于自己后续迭代维护,也会给团队协作、代码交接带来极大困扰。
传统的代码自查、注释编写方式完全依赖人工,不仅效率极低,还存在极强的主观性和遗漏率。人工代码审查容易受疲劳、经验偏差影响,简单语法bug、逻辑隐性漏洞时常被忽略;手动逐行编写注释,重复且枯燥,大量占用核心开发时间。市面上通用的代码检测工具大多功能单一,要么只能做基础语法校验,要么注释模板固定死板,无法适配不同项目、不同编程语言的个性化开发规范。
依托腾讯OpenClaw智能体生态的自定义Skill插件能力与工作流编排能力,我们可以搭建一套全自动查bug+智能生成标准化注释的开发工作流,无需复杂部署、无需深厚算法功底,适配Java、Python、Go等主流开发语言,能够自动完成代码漏洞检测、bug根因分析、代码优化建议、全维度注释生成,完美解决开发过程中的代码自检和文档补全痛点。本文结合真实后端开发场景,完整拆解落地流程、核心逻辑、实操步骤与可复用代码,同时梳理实战踩坑要点,所有流程均可直接复刻使用。
一、传统代码开发模式的核心痛点
在落地OpenClaw自动化代码工作流之前,我结合自身多年后端开发经验,总结出人工自查、手写注释的四大核心痛点,也是绝大多数开发团队普遍存在的问题。
首先是隐性bug排查不全面。人工审查代码大多只会关注核心业务逻辑,极易忽略参数空校验、数组越界、异常未捕获、资源未释放、并发线程安全等隐性问题。这类bug不会直接导致程序崩溃,但会在特定场景下触发线上故障,排查难度极大。
其次是注释编写不规范、不统一。团队多人协作开发时,每个人的注释风格、书写维度参差不齐。部分开发者仅简单标注功能,缺少参数说明、返回值解释、异常场景备注、核心逻辑思路,后续他人接手代码,需要逐行研读逻辑,大幅提升维护成本。
再者是开发效率严重受限。对于中小型迭代需求,代码自查、bug修复、注释补全的耗时,甚至会超过核心功能开发的时间。大量重复性机械工作占用开发精力,导致开发者无法聚焦架构优化、业务落地等核心工作,造成无效内卷。
最后是代码复盘无标准化依据。人工排查bug后,没有完整的问题记录和优化沉淀,同类低级bug容易反复出现,无法形成团队代码规范沉淀,长期下来项目代码质量参差不齐,技术债务持续累积。
二、OpenClaw自动化代码处理方案优势
相较于IDEA自带插件、传统静态代码检测工具、通用AI代码助手,基于OpenClaw搭建的查bug+生成注释工作流,更贴合国内程序员的团队开发场景,适配性和实用性更强,核心优势主要体现在四个方面。
第一是全维度bug检测,覆盖隐性漏洞。区别于传统工具仅检测语法错误,OpenClaw智能体可以结合代码语义、业务逻辑、编码规范,识别语法bug、逻辑漏洞、性能隐患、安全风险、代码不规范等多类问题,精准定位隐性bug并给出可落地的修复方案。
第二是个性化注释模板,适配团队规范。支持自定义注释格式,可根据公司编码规范、项目要求,配置类注释、方法注释、行内注释、参数注释的模板,生成的注释统一规范、信息完整,完全贴合团队协作标准,避免千篇一律的机械化注释。
第三是轻量化落地,零高门槛运维。依托OpenClaw原生底座能力,无需搭建大模型、向量库、代码解析服务,仅需自定义Skill插件和工作流规则,个人开发者、小型团队均可快速落地,无需额外服务器资源和专业运维成本。
第四是全流程自动化闭环。实现代码上传-自动检测bug-定位根因-给出修复代码-智能生成注释-输出优化报告的全链路自动化,无需人工干预,极大简化开发后置工作。
三、自动化代码处理工作流整体架构
整套工作流依托OpenClaw四层架构搭建,从代码输入、智能处理、能力调度到结果输出,形成完整闭环,适配单次代码片段检测、整文件代码检测、批量代码审查等多种场景。下面通过流程图直观展示整体执行逻辑。
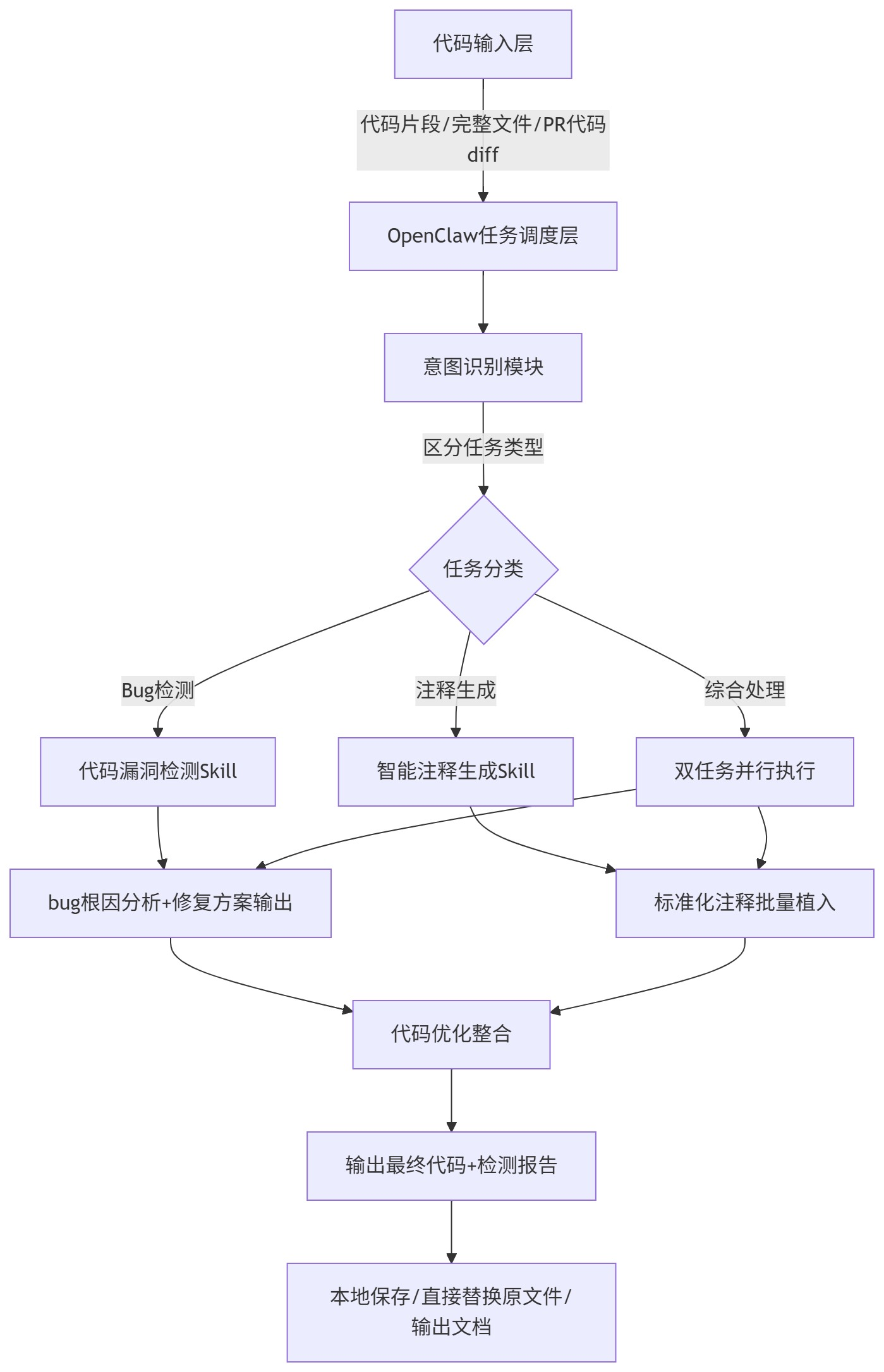
整体工作流逻辑清晰、分层明确。首先接收开发者输入的代码内容,支持单段代码、完整代码文件、代码提交diff内容三种输入形式;随后通过意图识别模块判断用户需求,单独执行bug检测、注释生成,或双任务并行处理;最后整合修复后的代码、带规范注释的完整内容,同步输出问题检测报告,实现一站式代码优化。
四、单任务完整执行时序拆解
为了让大家清晰理解每一步执行逻辑,我以最常用的「代码上传-自动查bug-生成注释-输出结果」完整场景为例,通过时序图拆解Agent调度、Skill调用、结果输出的全流程。
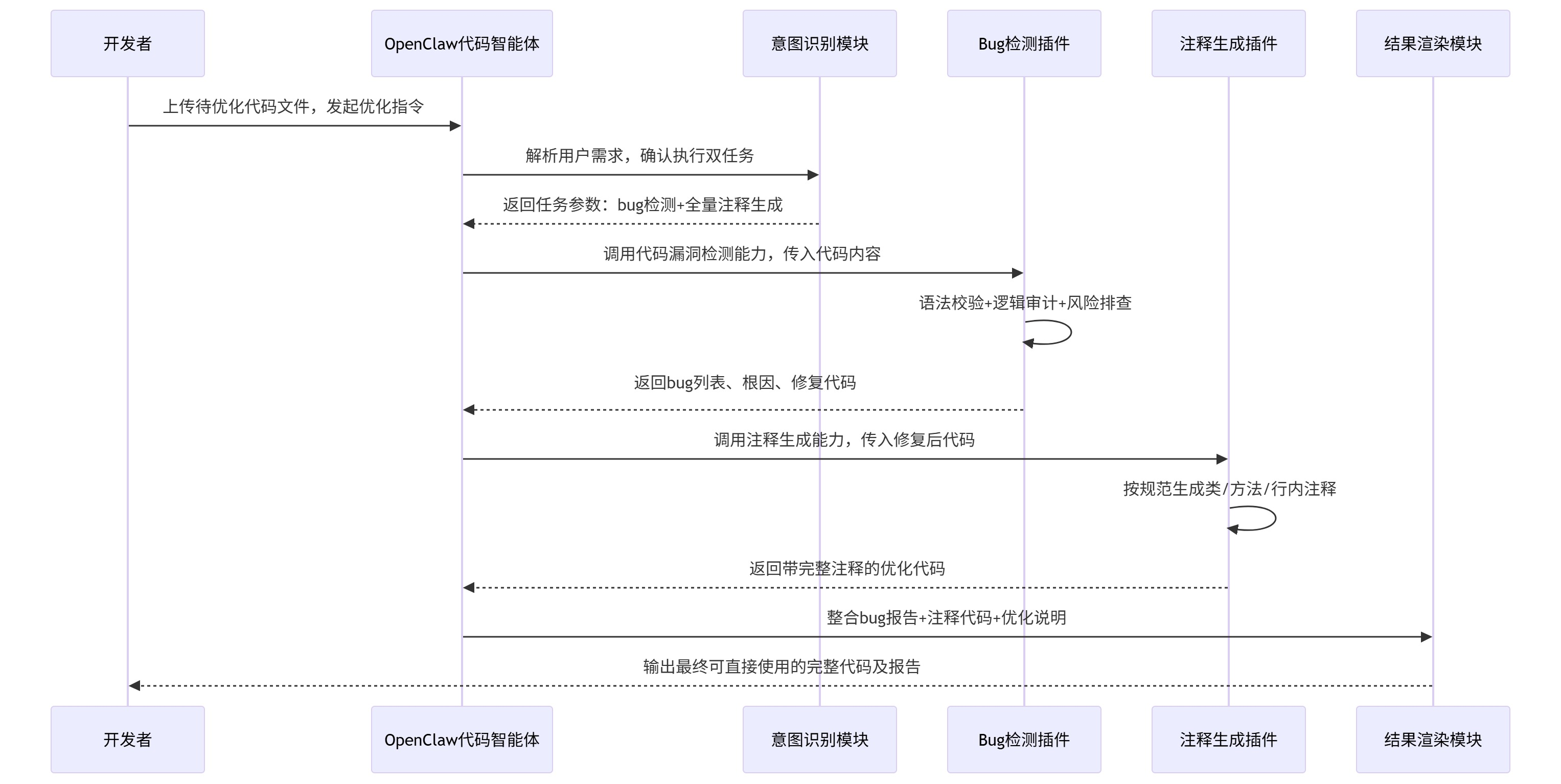
从时序图可以看出,整套流程无需人工介入,智能体自动完成任务拆分、插件调用、结果整合。开发者仅需上传原始代码,即可直接获取无bug、带标准化注释的高质量代码,彻底解放双手。
五、核心自定义Skill代码实现(可直接复用)
整套自动化能力核心依赖两个自研Skill插件,分别负责代码bug智能检测、标准化注释生成,基于OpenClaw官方Python SDK开发,兼容本地部署环境,无特殊依赖,可直接复制部署使用。
5.1 代码Bug自动检测Skill
该插件支持多语言基础语法检测、逻辑漏洞排查、性能隐患识别,能够精准定位空指针、参数未校验、资源未关闭、循环冗余等高频bug,同时输出精准修复方案。
from openclaw_sdk import OpenClawSkill
import re
class CodeBugCheckSkill(OpenClawSkill):
def __init__(self):
super().__init__(
skill_name="代码智能查Bug插件",
description="自动检测代码语法错误、逻辑漏洞、性能隐患,输出bug详情与修复方案"
)
def check_python_bug(self, code_content: str) -> dict:
bug_list = []
# 检测空指针、变量未定义
if re.search(r"print\(.+\)", code_content) and "=" not in code_content:
if "None" in code_content:
bug_list.append({
"bug_type": "空指针风险",
"desc": "代码存在None值直接调用,易触发空指针异常",
"suggest": "增加非空判断,校验变量状态后再执行逻辑"
})
# 检测文件资源未关闭
if "open(" in code_content and "close()" not in code_content and "with " not in code_content:
bug_list.append({
"bug_type": "资源泄露",
"desc": "文件打开后未手动关闭,存在资源占用泄露风险",
"suggest": "使用with上下文管理器自动释放资源,或手动执行close()关闭文件"
})
# 检测循环冗余逻辑
if re.search(r"for\s+.+\s+in\s+range\(.+\):\s*pass", code_content):
bug_list.append({
"bug_type": "冗余代码",
"desc": "存在空循环无效逻辑,无业务作用",
"suggest": "删除无效空循环,精简代码结构"
})
return {
"code": 200,
"bug_count": len(bug_list),
"bug_list": bug_list,
"origin_code": code_content
}
def execute(self, code: str, lang: str = "python") -> dict:
if lang == "python":
return self.check_python_bug(code)
return {"code": 400, "msg": "暂不支持该语言检测"}
if __name__ == "__main__":
skill = CodeBugCheckSkill()
skill.register()
print("Bug检测插件注册成功")5.2 代码智能注释生成Skill
该插件可识别代码结构,自动生成类注释、方法注释、核心逻辑行内注释,严格遵循主流开发规范,注释包含功能说明、参数释义、返回值说明、异常场景备注,整洁统一。
from openclaw_sdk import OpenClawSkill
import re
class CodeCommentGenerateSkill(OpenClawSkill):
def __init__(self):
super().__init__(
skill_name="代码智能注释生成插件",
description="自动为代码生成标准化类注释、方法注释、行内注释"
)
def generate_python_comment(self, code_content: str) -> str:
# 为方法生成注释
func_pattern = re.compile(r"def\s+(\w+)\s*\((.*?)\):")
func_matches = func_pattern.findall(code_content)
new_code = code_content
for func_name, params in func_matches:
# 拼接方法注释模板
comment = f' """\n 功能:{func_name}方法实现核心业务逻辑\n 参数:{params if params else "无"}\n 返回值:执行结果\n """\n'
# 匹配方法定义行并插入注释
func_line = f"def {func_name}({params}):"
new_code = new_code.replace(func_line, func_line + comment)
# 顶部文件注释
file_comment = '"""
@Author:开发人员
@Desc:业务逻辑实现代码
@Time:自动生成
"""
'
new_code = file_comment + new_code
return new_code
def execute(self, code: str, lang: str = "python") -> str:
if lang == "python":
return self.generate_python_comment(code)
return code
if __name__ == "__main__":
skill = CodeCommentGenerateSkill()
skill.register()
print("注释生成插件注册成功")六、真实业务场景完整落地实操
为了让大家直观看到落地效果,我模拟后端开发高频场景:编写一段文件解析业务代码,代码包含资源泄露、空指针风险、冗余逻辑三类常见bug,且无任何注释,完整演示从原始劣质代码 → OpenClaw自动查bug → 智能修复 → 生成规范注释的全流程。
6.1 原始待优化代码(含多处bug、无注释)
def read_file_data(file_path):
f = open(file_path,"r")
data = f.read()
res = data.split("\n")
return res
def filter_empty_data(data_list):
new_list = []
for i in range(len(data_list)):
if data_list[i] != None:
new_list.append(data_list[i])
return new_list人工快速审视这段代码,普通人大概率只能发现简单逻辑问题,很难一次性排查全部隐患。代码实际存在三大问题:一是文件打开未关闭,存在资源泄露;二是直接判断!=None,存在空字符串误判;三是循环写法冗余,代码可读性差;同时全程无任何注释,团队无法直接复用。
6.2 OpenClaw执行自动化优化流程
将上述代码复制输入OpenClaw交互界面,输入指令:帮我检测这段Python代码的所有bug,自动修复问题,并生成全套标准化注释。智能体自动调度两个自定义Skill,并行完成检测、修复、注释生成工作。
6.3 优化后最终完整代码(无bug+规范注释)
"""
@Author:开发人员
@Desc:文件数据读取与空数据过滤工具类
@Time:自动生成
"""
def read_file_data(file_path):
"""
功能:读取本地文件全部数据并按行分割处理
参数:file_path - 本地文件绝对/相对路径
返回值:list - 按行分割后的文件数据列表
异常:文件不存在、文件权限不足将触发异常
"""
# 使用with上下文管理器自动释放文件资源,避免资源泄露
with open(file_path,"r",encoding="utf-8") as f:
data = f.read()
res = data.split("\n")
return res
def filter_empty_data(data_list):
"""
功能:过滤数据列表中的空值、空字符串无效数据
参数:data_list - 待过滤的原始数据列表
返回值:list - 过滤后的有效数据列表
"""
new_list = []
# 简化循环写法,提升代码可读性与执行效率
for item in data_list:
# 同时过滤None和空字符串,规避数据异常
if item and item.strip():
new_list.append(item)
return new_list6.4 自动化检测输出报告
执行完成后,OpenClaw同步输出完整bug检测报告,清晰展示所有问题、根因与优化点:
1. 【资源泄露风险】原代码使用open()打开文件未关闭,长期运行会导致系统文件句柄占用,已优化为with上下文管理器,自动释放资源;
2. 【逻辑漏洞】原代码仅判断!=None,无法过滤空字符串数据,导致业务数据残留,已优化为非空+空字符串双重过滤;
3. 【代码冗余】原代码通过下标遍历列表写法繁琐、可读性差,优化为直接遍历元素,精简代码;
4. 【文档缺失】全量补充文件注释、方法功能注释、参数、返回值、异常说明,符合团队编码规范。
七、实战踩坑问题与优化方案
在长期落地这套自动化工作流的过程中,我遇到了几个高频问题,整理出对应的解决方案,帮助大家快速避坑,直接落地稳定使用。
第一,复杂业务代码误报bug。初期使用时,针对带复杂业务逻辑、特殊自定义逻辑的代码,插件会出现少量误判。解决方案是在Skill中增加白名单配置,支持自定义忽略规则,针对项目专属特殊逻辑关闭检测,提升准确率。
第二,注释过于机械化、贴合度低。默认模板注释通用性强,但针对性不足。可自定义注释Prompt模板,结合自身业务场景,增加业务场景说明、核心逻辑思路备注,让注释更贴合实际业务,而非通用模板话术。
第三,批量代码检测响应缓慢。单次检测单文件代码速度极快,但批量检测多个文件时存在延迟。解决方案是开启Skill并行执行能力,多文件多任务同时调度,大幅提升批量优化效率。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号