前端开发者的 C++ 实战补漏:异步操作的生命周期
原创

《Lambda 捕获与生命周期》里讲了,
[this]捕获不安全,要改weak_ptr。但真实业务里的异步操作不止一个坑。做 N-API 扩展时,经常遇到这类问题:发起一个资源加载,回调注册好了,但结果回来前用户离开了页面,发起操作的对象析构了;SDK 有 bug 导致同一个操作回调两次,Promise 被 resolve 了又 resolve;进程退出时还有一堆未完成的操作悬着,JS 侧的 await 永远卡住。这些不是 lambda 的问题,是异步操作本身的生命周期管理问题。这篇讲清楚。
1. 一次异步崩溃引出的问题
做 N-API 扩展时,JS 侧调用一个异步 API,C++ 这边起工作线程去调第三方业务 SDK(通常是另一个 .dll 或 .so),SDK 在自己的后台线程里干活,完成后通过回调把结果传回 JS。代码写起来很自然:
class PageController : public std::enable_shared_from_this<PageController> {
public:
void loadResource(const std::string& resId) {
sdk->loadAsync(resId, [weakSelf = weak_from_this()](Result result) {
auto self = weakSelf.lock();
if (!self) { return; }
self->onLoaded(result);
});
}
void onLoaded(Result result) { /* 更新 UI */ }
};用 weak_from_this 代替 this 捕获。this 悬垂的问题确实解决了。但操作不只涉及 this——SDK 内部还持有其他对象的引用,那些对象也可能在回调执行前析构。weak_ptr 能守住自己,守不住 SDK 引用的其他对象。
前端类比:组件卸载时可以清掉自己的定时器,但清不掉全局事件总线上注册的回调。weak_ptr 同理——管得了自己的析构,管不了 SDK 内部还握着什么。
单个对象的生命周期已经管住了,但一个异步操作涉及多个对象的协同,这部分还没有着落。异步操作的生命周期管理要回答两个问题:对象还活着吗,操作还在进行吗。
2. 对象还活着吗
异步操作有个时间差:发起操作的对象,可能在回调执行前析构。比如用户在资源加载完成前就离开了页面,PageController 析构了,但 SDK 的回调还在排队。回调执行时访问已析构的对象,就是 UAF。
前端类比:useEffect 里发了个请求,组件卸载了请求才回来。不处理就会操作已卸载的组件。JS 里有 GC 兜底,组件卸载后引用还在,不会立刻出事。C++ 里对象析构就是析构了,指针指向废内存。
weak_ptr + lock 就是这个问题的解法。用一个不持有所有权的弱引用观察对象,回调执行前先检查对象还在不在:
class PageController : public std::enable_shared_from_this<PageController> {
public:
void refreshUI() { /* ... */ }
void startDelayedTask(std::vector<std::function<void()>>& queue) {
std::weak_ptr<PageController> weakSelf = shared_from_this();
queue.push_back([weakSelf]() {
auto self = weakSelf.lock();
if (!self) { return; } // 对象已销毁,安全跳过
self->refreshUI(); // 对象还活着,安全调用
});
}
};创建对象、注册回调、对象析构后再执行回调。lock() 失败时回调安全退出,不会访问废内存。
但光守住对象还不够。对象还活着不代表操作只执行一次。
3. 操作只结算一次
SDK 有 bug 时可能对同一个操作回调两次。第一次回调 resolve 了 Promise,第二次又来 resolve,行为未定义。更隐蔽的是,如果回调里有 delete 操作,两次 delete 同一个指针就是 double-free。
根因是异步操作没有一个「已完结」的标记。回调来了就执行,不检查这个操作是不是已经结算过。
最直接的想法是给每个操作加一个 bool 标记。但真实业务里一个模块可能同时有几十个 pending 操作,分布在多个线程,散落的 bool 标记不好管。更可靠的做法是集中管理:把所有 pending 操作放进一张表,每个操作分配一个唯一 id,回调来了用 id 去表里认领。认领成功就从表里删除,第二次认领时找不到条目,直接失败。
class SimpleRegistry {
public:
uint64_t add(std::string name) {
uint64_t id = next_id_++;
std::lock_guard<std::mutex> lock(mu_);
entries_[id] = name;
return id;
}
bool claim(uint64_t id, std::string& outName) {
std::lock_guard<std::mutex> lock(mu_);
auto it = entries_.find(id);
if (it == entries_.end()) return false; // 已被认领
outName = it->second;
entries_.erase(it); // 认领后删除
return true;
}
// ...
};add 发起操作时调,往表里插一条,拿到唯一 id。claim 回调进来时调,用 id 查表,找到就取出并删除,返回 true;找不到(已被认领过)返回 false。所有操作都加了锁,多线程安全。
实际使用流程是这样的:发起异步操作时调 add 拿到 op_id,存进回调上下文。SDK 回调进来时用 op_id 调 claim,第一次成功走 resolve 逻辑,SDK bug 导致的第二次回调 claim 返回 false,直接跳过。
对照一下就很清楚:
// 首次回调
registry.claim(op, name); // → 成功,走 resolve
// SDK bug 导致第二次回调
registry.claim(op, name); // → 失败,安全跳过这就是 once 语义。
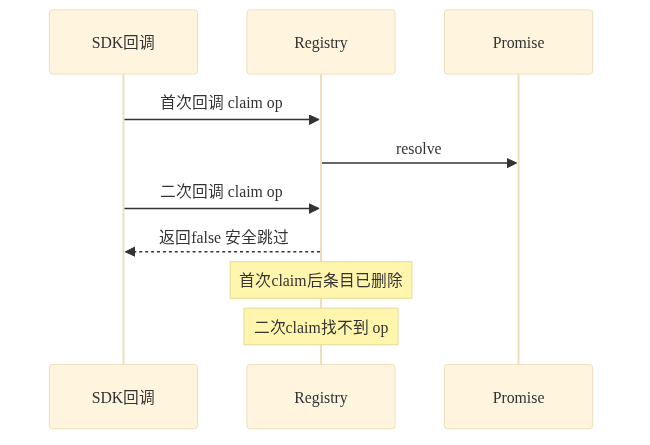
Registry 双重回调防御
前端类比:一个 Promise 只能 resolve 一次。你可以在 resolve 前放一个标志位,第二次调直接忽略。Registry 的 claim 就是把这件事做到了操作级别。
weak_ptr::lock 管的是对象生命周期,Registry 的 claim 管的是操作生命周期。两层配合,异步回调才不会因重复触发或悬空引用而出事。
4. 退出时批量回收
进程退出时,可能还有一堆异步操作没完成。这些操作的 Promise 还在 pending,JS 侧的 await 会永远卡住。更麻烦的是,SDK 的后台线程可能还在跑,回调进来时 napi_env 已经销毁了,再访问就崩。退出时不能直接走,得先把所有 pending 操作统一结算掉。
Registry 已经有 claim,再补一个 claimAll 就能批量回收:
void claimAll(std::vector<std::pair<uint64_t, std::string>>& out) {
std::lock_guard<std::mutex> lock(mu_);
for (auto& [id, name] : entries_) {
out.emplace_back(id, name);
}
entries_.clear();
}退出时批量取出所有 pending 操作,逐个 reject,告诉 JS 侧环境正在关闭。这和 React 的 useEffect cleanup 是一个思路:组件(或进程)卸载时,把所有未完成的异步操作统一清理,不能留悬空回调。
这里有个顺序问题。如果通道已经被 abort,投递了但还没执行的 lambda 不会跑了,lambda 里 new 的对象会泄漏。所以 abort 之前要先 claimAll 把 pending 操作回收掉,让对应的清理逻辑跑完,再关闭通道。顺序不能反。
5. 总结
回到开头那次崩溃。异步操作的生命周期管理,不是靠一个 weak_ptr 能全部解决的。
它需要三道防线:
weak_ptr + lock检查对象还在不在,守住对象生命周期。- Registry 的
claim保证同一个操作只结算一次,防双重回调。 claimAll在退出时批量回收 pending 操作,不留悬空回调。
三道防线的分工:第一道管对象存活,第二道管操作结算,第三道管退出清理。缺了任何一道,异步回调都可能出事。
后面讨论 N-API 桥接时,会把这些防线放进 JS 和 C++ 的桥接场景,看真实的 TSFN 通道和 Promise 怎么把异步结果安全回传给 JS。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号