前端开发者的 C++ 实战补漏:动态库边界上的内存释放
原创
前端开发者的 C++ 实战补漏:动态库边界上的内存释放
原创
骑猪耍太极
修改于 2026-06-30 14:51:08
修改于 2026-06-30 14:51:08
做 N-API 扩展时,
.node文件经常只是中间层。JS 调到 C++,C++ 再去调第三方业务 SDK,而 SDK 往往是另一个.dll或.so。函数调通只是第一步,更容易被忽略的是释放责任:SDK 返回的对象、字符串、句柄到底该由谁释放?这个责任一旦模糊,代码可能本地跑得很稳,上线后却崩在一个看不懂的free里。
1. 一次动态库边界上的崩溃
先看一个很容易写出来的接口。某个日志 SDK 提供 Logger,头文件里把类和工厂函数都暴露给调用方:
// logger_sdk.h,调用方也能看到 Logger 的定义
class Logger {
public:
void Log(const char* msg);
~Logger();
private:
std::vector<std::string> entries_;
};
Logger* CreateLogger();实现放在 logger.dll 里:
// logger.dll 内部
Logger* CreateLogger() {
return new Logger(); // 在 logger.dll 内部分配
}调用方拿到 Logger* 后,自然会把它当普通 C++ 对象用:
// app.exe
Logger* logger = CreateLogger();
logger->Log("hello");
delete logger; // 看起来合理,问题就在这里这段代码的问题不在 Log,而在最后一行。Logger 是在 logger.dll 内部分配的,却在 app.exe 里释放。它看起来只是一个普通指针,背后却跨过了动态库边界。
这种崩溃很容易误导排查方向。堆栈可能停在 free、delete 或堆检查函数里,表面上和业务对象没有关系;Debug 和 Release 的表现还可能不一样。真正的问题是分配和释放落到了不同的内存管理器上。
2. new 和 delete 背后的分配器
堆栈停在 free 里,看起来和 delete logger 对不上。中间缺的一环,是 new / delete 背后的分配器。
new Logger() 不是只做一件事。它会先调用底层申请函数(operator new)拿到一块内存,再在这块内存上执行构造函数。delete logger 也分两步:先执行析构函数,再通过底层释放函数(operator delete)把内存还回去。
这两个底层函数的默认实现通常不会自己管理整套堆结构,而是继续调用运行时库里的分配器。运行时库可以先理解成 C/C++ 程序运行时依赖的一组基础能力,内存分配也在里面。
Windows / MSVC 里,这层运行时常叫 CRT(C Runtime)。读者不需要记住缩写,只要记住一点:不同模块可能链接到不同的运行时副本,也就可能有不同的堆。Linux 上也有类似的基础运行时,只是常见场景下更容易共享同一套分配器。
问题出在动态库边界上。每个模块都可能有自己的运行时链接方式,也可能带自己的分配器。对象在哪个运行时或分配器里申请,通常就应该回到同一个运行时或分配器里释放。跨模块释放把这个配对关系打断了。
可以把不同模块想成两个 Worker。主线程可以让 Worker 创建对象,也可以拿到一个句柄,但不能直接伸手回收 Worker 内部的对象。更稳的方式是发消息让 Worker 自己清理。
3. 运行时副本怎么造成跨堆释放
在 Windows / MSVC 下,同一个项目可以选择不同的运行时链接方式。/MD 和 /MT 就是 MSVC 的运行时链接选项,它们会影响模块背后的堆。
/MD:动态链接运行时库。多个模块通常共享同一份运行时,内存分配器更容易保持一致。/MT:静态链接运行时库。每个模块都带一份运行时副本,可能形成各自独立的堆。
如果 logger.dll 和 app.exe 都用 /MT 编译,两边可能各有自己的运行时副本和自己的堆。logger.dll 里的 new 在 heap A 上分配,app.exe 里的 delete 却拿着这个地址去 heap B 上释放。heap B 的分配器不认识这个地址,堆内部的管理数据就可能被破坏。
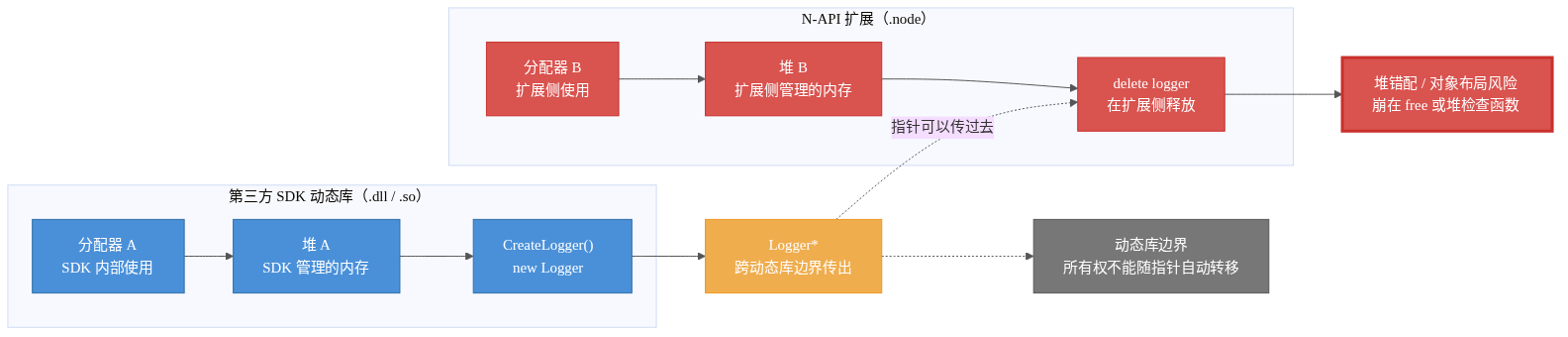
动态库边界上的堆错配
这类问题的表现很随机:有时立刻崩,有时过了很多次分配才崩,有时只在某个构建配置里复现。它破坏的是堆元数据,真正爆炸的位置经常离错误代码很远。
4. 二进制接口不一致也会出问题
/MD 能降低分配器不一致的风险,但它不是跨模块 delete 的通行证。动态库边界上还有另一类问题:两个模块都用 C++ 写,不代表它们编译后的对象布局完全一样。
比如字符串、动态数组这类标准库对象,内部字段可能受编译器版本、标准库版本、Debug/Release 配置影响。调用方看到的对象布局一旦和 SDK 内部不一样,访问成员、执行析构都可能出问题。std::string、std::vector 就属于这一类。
这类二进制层面的约定通常叫 ABI(Application Binary Interface,应用二进制接口)。它关注编译后的对象在内存里怎么摆、函数参数怎么传,而不是源码表面长什么样。这里不需要展开 ABI 的所有细节,只要记住:跨动态库传 C++ 对象时,两边必须按同一套规则理解这块内存。
工程上不应该把这类一致性当成接口契约。动态库边界更适合收窄成 C 风格接口:基本类型、指针、buffer、长度、句柄。复杂对象留在库内部,创建和销毁也留在库内部。
在 C++ 里导出这类 C 风格函数时,常会看到 extern "C"。它可以先理解成一个导出约定:让函数名按 C 的规则暴露出去,方便动态库查找。它只解决函数名怎么被找到,不解决内存该由谁释放。
5. 谁创建谁销毁
调用方拿到一个 Logger* 后,真正麻烦的是释放责任不清楚。这个指针背后的内存来自哪个模块、用的是 new 还是 malloc、析构函数依赖哪个标准库,调用方都不应该猜。
接口应该把释放责任写清楚:谁创建,谁销毁。每个 create 配一个 destroy,并且这两个函数都在同一个模块里实现。

分配释放流程对比
Logger* logger_create(void) {
return new Logger(); // 在库内部 new
}
void logger_destroy(Logger* p) {
delete p; // 在库内部 delete
}调用方只负责拿指针和归还指针:
Logger* logger = logger_create();
logger->Log("hello");
logger_destroy(logger); // 交给库自己释放这样 new 和 delete 永远在同一个模块内。调用方不需要知道内部对象是什么,也不需要知道它来自哪个堆。
字符串也遵守同一条规则。危险写法是让库返回一块新分配的内存:
// 危险:DLL 里 new 的 char[],调用方不知道怎么释放
extern "C" char* GetVersion() {
char* p = new char[16];
std::strcpy(p, "1.0.0");
return p;
}调用方拿到 char* 后会遇到同一个问题:该 delete[]、free,还是不释放?接口可以给出两种更稳的选择。
第一种是调用方传 buffer,库只负责填充:
void logger_last_entry(Logger* logger, char* buf, size_t size);
char buf[64];
logger_last_entry(logger, buf, sizeof(buf));第二种是库提供配套释放函数:
extern "C" char* GetVersion();
extern "C" void FreeString(char* p); // 在 DLL 内 delete[],配对能传 buffer 就优先传 buffer。它从根上避免了跨边界传递所有权,调用方也不用猜该怎么释放。
6. 只暴露一个看不见内部的句柄
create / destroy 配对解决了责任归属,但它仍然依赖调用方自觉。如果头文件暴露了完整的 C++ 类定义,调用方还是可能顺手写出 delete logger。
更稳的做法是只给调用方一个指针,但不让它看到这个指针背后的结构体长什么样。这种写法通常叫不透明句柄。公开头文件里只前向声明结构体,也就是只告诉编译器“有这么个类型”,不暴露它的字段和大小:
typedef struct LoggerHandle LoggerHandle;
LoggerHandle* logger_create(void);
void logger_log(LoggerHandle* h, const char* msg);
void logger_last_entry(LoggerHandle* h, char* buf, size_t size);
void logger_destroy(LoggerHandle* h);真实头文件里通常还会用 extern "C" 包起来,保证这些函数按 C 风格导出;这里先省掉外层宏,只看句柄设计本身。
真实定义只放在库内部:
struct LoggerHandle {
std::vector<std::string> entries;
};调用方只能看到 LoggerHandle*,看不到内部字段,也不知道这个类型的大小。这样至少有三层好处:调用方不能访问内部状态,不能把它当普通 C++ 对象复制,也不会自然地写出依赖内部布局的代码。
如果调用方强行 delete h,很多编译器会给出不完整类型相关的警告;在严格编译选项或静态检查里,这类写法可以被拦住。更重要的是,公开 API 已经明确告诉调用方:这个指针只能交回 logger_destroy,不能自己处理。
这和前端里的私有字段有点像。你从 npm 包里拿到一个对象,但内部字段不暴露,只能调它提供的方法。C++ 的不透明句柄把这个边界放到了编译期接口上。
7. Linux 下为什么也要小心
标题里写的是动态库,问题并不只出现在 Windows。Linux 下只是触发条件不同。
在常见 Linux 发行版上,进程里的多个 .so 往往走同一套 glibc 分配器,所以单纯 malloc/free 跨 .so 释放不一定立刻出问题。这也是很多 Linux 示例跑不出崩溃的原因。
但不崩不代表接口安全。只要某个库带了自己的分配器,或者两边 C++ 标准库、编译配置不一致,同样可能遇到释放路径和对象布局的问题。这里不需要记住具体库名,记住一点就够了:Linux 上不崩,不等于跨模块释放就是合理的。
所以即便在 Linux,动态库边界也尽量只暴露 C 风格接口,内存仍然遵守谁创建谁销毁。
8. 总结
跨模块释放的问题,表面上是 delete 写错了地方,背后是分配器、运行时链接方式和二进制接口的边界没有处理好。
落地时记三条规则:
- 谁创建谁销毁:每个
create配一个destroy,都在同一个模块内new/delete。 - 跨边界少传所有权:字符串能传 buffer 就传 buffer,不轻易返回需要调用方释放的内存。
- 用不透明句柄收住接口:公开头文件只暴露
Handle*和操作函数,不暴露 C++ 类内部布局。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号