
使用火花计数2级跟随器
使用火花计数2级跟随器
提问于 2021-12-10 13:08:07
我有一个问题,以计数2级追随者使用火花。程序是计算所有跟随者和跟随者。以下是数据的示例:
format : USER \t FOLLOWER \n
P1 P2
P1 P3
P2 P4
P2 P3
P3 P4编制:
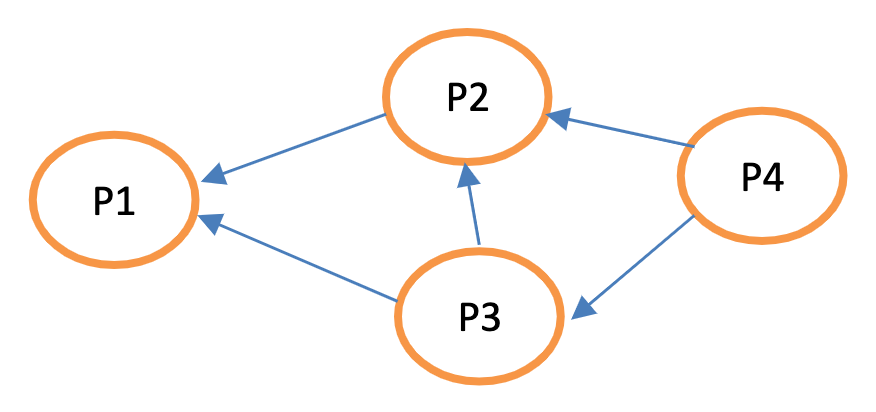
从图片上看,P1有三个二级跟随者( P2,P3,P4),P2有2 (P4和P3),P3有1 ( P4 ),P4有0。
因此,程序的输出将是:
P1 -> 3
P2 -> 2
P3 -> 1
P4 -> 0我试着在pyspark中使用RDD,但不知道解决方案的其余部分。
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appName("word count").getOrCreate()
sc = spark.sparkContext
twt_txt = sc.textFile("follow.txt")
twt_txt = twt_txt.map(lambda x : kv(x))
twt_groupby = twt_txt.groupByKey().map(lambda x : (x[0], list(x[1])))
twt_groupby.collect()
# result : [('1', ['2', '3']), ('2', ['4', '3']), ('3', ['4'])] this is one level follower
# but the problem is 2 level follower注意事项:实际数据集为5GB。
Stack Overflow用户
发布于 2021-12-11 02:48:53
自我加入,得到第二个跟随者,并将其与第一个跟随者合并,爆炸数组,使末端跟随者达到2级并计数。
df = spark.read.csv('test.csv', header=True, sep=' ')
df.show()
+----+--------+
|USER|FOLLOWER|
+----+--------+
| P1| P2|
| P1| P3|
| P2| P4|
| P2| P3|
| P3| P4|
+----+--------+
df.withColumnRenamed('FOLLOWER', 'TEMP') \
.join(df.withColumnRenamed('USER', 'TEMP'), ['TEMP'], 'left') \
.withColumn('FOLLOWERS', f.array('FOLLOWER', 'TEMP')) \
.select(f.col('USER'), f.explode('FOLLOWERS').alias('FOLLOWER')) \
.filter('FOLLOWER is not NULL') \
.groupBy('USER').agg(f.array_distinct(f.collect_list('FOLLOWER')).alias('FOLLOWERS')) \
.withColumn('SIZE', f.size('FOLLOWERS')) \
.show(truncate=False)
+----+------------+----+
|USER|FOLLOWERS |SIZE|
+----+------------+----+
|P2 |[P4, P3] |2 |
|P3 |[P4] |1 |
|P1 |[P3, P2, P4]|3 |
+----+------------+----+页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70304997
复制相关文章
相似问题
腾讯云开发者
