
如何将抛物线函数传授给神经网络
如何将抛物线函数传授给神经网络
提问于 2021-12-18 22:34:53
我的目标是建立一个具有两个神经元的序列神经网络,它可以再现一个二次函数。为此,我选择了第一个神经元为lambda x: x**2,第二个神经元为None的激活函数。
每个神经元输出A(ax+b),其中A是激活函数,a是给定神经元的权重,b是偏置项。第一个神经元的输出传递给第二个神经元,该神经元的输出就是结果。
我的网络输出的形式是:
训练模型意味着调整每个神经元的权重和偏倚。选择一组非常简单的参数,即:
将我们引向一个抛物线,这个抛物线应该可以通过上面所述的2神经元神经网络来学习:
[](https://chart.googleapis.com/chart?cht=tx&chl=f(x%29%20%3D%20x%5E2%20%2B%202x%20%2B%202)
为了实现神经网络,我做:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt定义要学习的功能:
f = lambda x: x**2 + 2*x + 2利用上述职能生成培训投入和产出:
np.random.seed(42)
questions = np.random.rand(999)
solutions = f(questions)定义神经网络体系结构:
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=1, input_shape=[1],activation=lambda x: x**2),
tf.keras.layers.Dense(units=1, input_shape=[1],activation=None)
])汇编网:
model.compile(loss='mean_squared_error',
optimizer=tf.keras.optimizers.Adam(0.1))培训模型:
history = model.fit(questions, solutions, epochs=999, batch_size = 1, verbose=1)使用新训练的模型生成f(x)的预测:
np.random.seed(43)
test_questions = np.random.rand(100)
test_solutions = f(test_questions)
test_answers = model.predict(test_questions)可视化结果:
plt.figure(figsize=(10,6))
plt.scatter(test_questions, test_solutions, c='r', label='solutions')
plt.scatter(test_questions, test_answers, c='b', label='answers')
plt.legend()
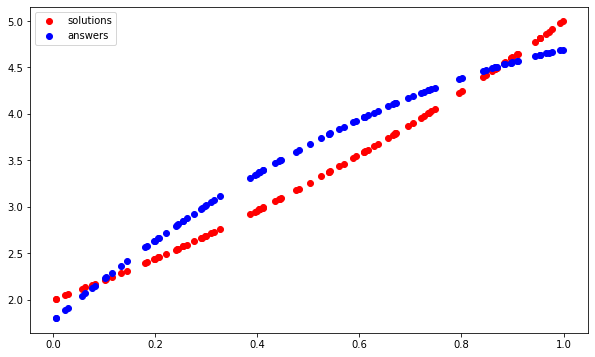
红色的点构成抛物线的曲线,我们的模型应该学习,蓝色的点形成它所学习的曲线。这种做法显然行不通。
上述方法有什么问题,以及如何使神经网络真正学习抛物线?
Stack Overflow用户
回答已采纳
发布于 2021-12-20 08:41:17
添加到@Zabob的回答中。您使用过对初始学习速度敏感的Adam优化器,虽然它被认为是相当健壮的,但我发现它对初始学习速率很敏感,并且可能导致意外的结果(就像您的情况下,它正在学习相反的曲线)。如果将优化器更改为SGD:
model.compile(loss='mean_squared_error',
optimizer=tf.keras.optimizers.SGD(0.01))然后,在不到100个时代,您可以得到一个优化的网络:
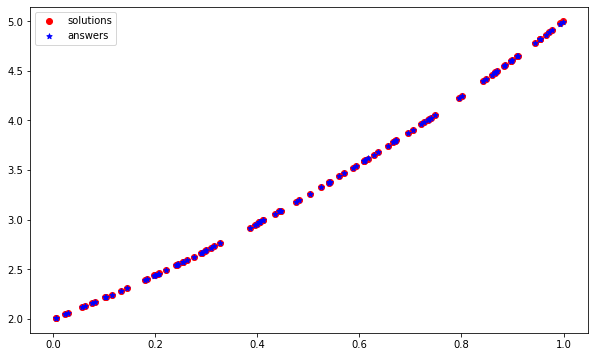
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70407674
复制相关文章
相似问题
腾讯云开发者
