
M == q:r比较(1)中的错误仅适用于原子类型和列表类型。
我需要转换for循环来申请优化的整个函数。
plans_achievements <- function(pa_m,pa_q){
if(nrow(pa_m)==0 & nrow(pa_q==0)){
df = data.frame(a = c(""), b = c("No Data Available"))
colnames(df)=""
}else{
pa_m= pa_m%>% select(inc,month_year,Plans,Achievements,quarter_year)
colnames(pa_mon)[2] = "Period"
pa_q= pa_q%>% select(inc,quarter_year,Plans,Achievements)
colnames(pa_qtr)[2] = "Period"
df = data.frame(inc=c(""),Period=c(""),Plans=c(""),Achievements=c(""))
for (q in unique(pa_q$Period)){
df1 = pa_q[pa_q$Period==q,]
df1$Period = paste0("<span style=\"color:#288D55\">",df1$Period,"</span>")
df1$Plans = paste0("<span style=\"color:#288D55\">",df1$Plans,"</span>")
df1$Achievements = paste0("<span style=\"color:#288D55\">",df1$Achievements,"</span>")
df = rbind(df,df1)
for (m in unique(pa_m$quarter_year)){
if(m==q){
df2 = pa_m[pa_m$quarter_year==q,][-5]
df = rbind(df,df2)
}
}
}
df = df[-1,]
}
return(df)
}我试过的申请
my_fun <- function(q){
df1 = pa_qtr[pa_qtr$Period==q,]
df1$Period = paste0("<span style=\"color:#288D55\">",df1$Period,"</span>")
df1$Plans = paste0("<span style=\"color:#288D55\">",df1$Plans,"</span>")
df1$Achievements = paste0("<span style=\"color:#288D55\">",df1$Achievements,"</span>")
df = rbind(df,df1)
}
df = do.call(rbind,lapply(unique(pa_qtr$Period), my_fun))
my_fun2 <- function(m,my_fun){
if (m == q) {
df2 = pa_mon[pa_mon$qtr_yr == q, ][-5]
df = rbind(df,df2)
}
}
df = do.call(cbind,lapply(unique(pa_mon$qtr_yr), my_fun2))DT::datatable(plans_achievements(pa_mpa_m$inc=="vate",,pa_qpa_q$inc=="vate",),行名= F,转义= FALSE,selection=list(mode=“单行”,target=“行”),选项=列表(pageLength= 50,scrollX = TRUE,dom = 'tp',ordering=F,columnDefs =list(列表(visible=FALSE,targets=c(0)),list(className =‘dt-左,目标=’_all‘)
回答 1
Stack Overflow用户
发布于 2021-12-21 09:10:33
为什么要得到错误comparison is possible only for atomic and list types
我会先回答你原来的问题:
您得到了错误,因为您没有将q定义为函数my_fun2中的一个变量。因为您还没有定义这个变量,R会在全局环境中查找它。在那里,R将找到函数 q() (用于退出R)。因此,您得到了错误消息comparison (1) is possible only for atomic and list types,因为R认为您试图将数字m与函数q进行比较。
下面是一个很容易看到的小例子:
# Run this in a clean environment
m <- 1
m == b # Understandable error message - "b" is not found
m == q # Your error - because R thinks you are comparing m to a function通过确保在函数中定义了q,可以修复此错误。要么在函数中创建它,要么将其作为输入参数提供。
解决你的问题的可能方法
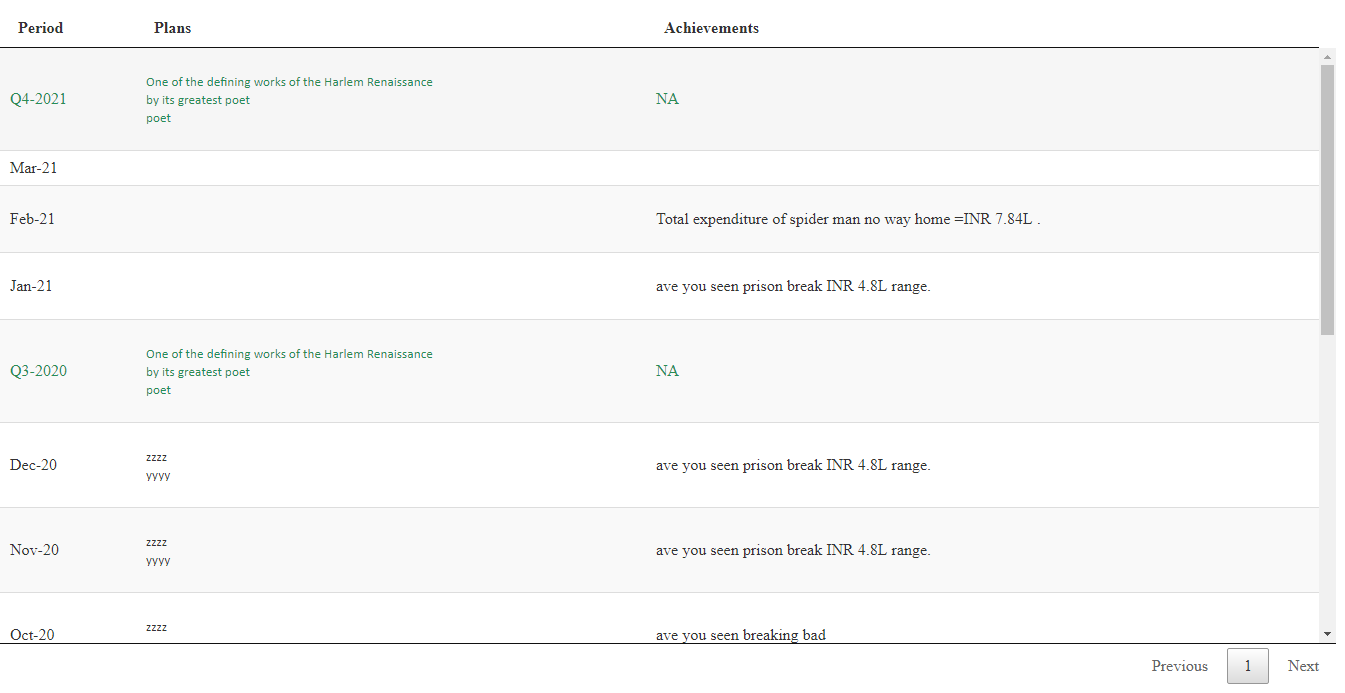
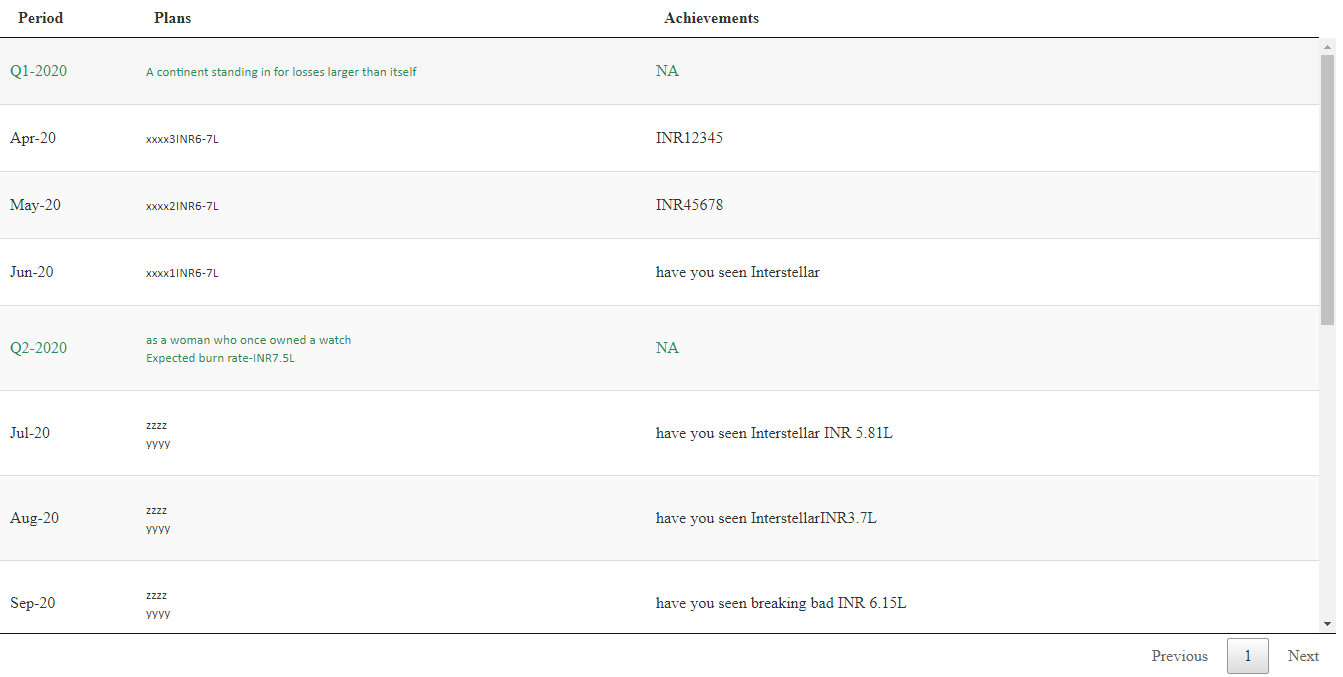
正如我理解您的代码一样,您希望格式化、合并和排序pa_q和pa_m中的值,以便在html表中显示它们。
下面是一个可能的解决方案,使用tidyverse和矢量化操作,而不是循环或应用函数。向量化函数通常是R中最快的选项,因为我知道您希望优化代码。
library(dplyr)
plans_achievements <- function(pa_m, pa_q) {
# I've modified the logic a bit: there is no need to wrap the full function in
# an else statement, since we can return early if the data has no rows
if (nrow(pa_m) == 0 && nrow(pa_q == 0)) {
df = data.frame(a = c(""), b = c("No Data Available"))
colnames(df) = ""
return(df)
}
pa_q <-
pa_q %>%
# Select and rename the columns vi need
select(inc, Period = quarter_year, Plans, Achievements, date) %>%
# Format the values
mutate(
Period = paste0("<span style=\"color:#288D55\">", Period,"</span>"),
Plans = paste0("<span style=\"color:#288D55\">", Plans,"</span>"),
Achievements = paste0("<span style=\"color:#288D55\">", Achievements,"</span>")
)
pa_m <-
pa_m %>%
# Select and rename the columns we need
select(inc, Period = month_year, Plans, Achievements, date) #%>%
# Combine the datasets
bind_rows(
pa_q,
pa_m
) %>%
# Make sure that R understand date as a date value
mutate(
date = lubridate::dmy(date)
) %>%
# Sort by date
arrange(desc(date)) %>%
# Remove columns we do not need
select(-date, -inc)
}
DT::datatable(
plans_achievements(
pa_m[pa_m$inc=="vate",],
pa_q[pa_q$inc=="vate",]
),
rownames = FALSE,
escape = FALSE,
selection = list(mode = "single", target = "row"),
options = list(
pageLength = 50,
scrollX = TRUE,
dom = 'tp',
ordering = FALSE,
columnDefs = list(
list(className = 'dt-left', targets = '_all')
)
)
)希望这能解决你的问题。
https://stackoverflow.com/questions/70431213
复制相似问题
腾讯云开发者
