
使用HUDI在TRINO上创建表的示例
使用HUDI在TRINO上创建表的示例
提问于 2021-12-23 10:19:27
我使用Spark Structured Streaming (3.1.1)从Kafka读取数据,并使用HUDI (0.8.0)作为S3上的存储系统,按日期对数据进行分区。(本节无问题)
我希望使用Trino (355)来查询这些数据。作为一个预言家,我已经把hudi-presto-bundle-0.8.0.jar放在/data/trino/hive/里了
我创建了一个具有以下模式的表
CREATE TABLE table_new (
columns, dt
) WITH (
partitioned_by = ARRAY['dt'],
external_location = 's3a://bucket/location/',
format = 'parquet'
);即使调用了下面的函数,trino也无法发现任何分区。
CALL system.sync_partition_metadata('schema', 'table_new', 'ALL')我的评估是,我无法使用hudi在trino下创建一个表,这主要是因为我无法在WITH选项下传递正确的值。我也找不到HUDI文档下的create示例。
如果有人能给我举个例子,或者为我指出正确的方向,万一我错过了什么,我会非常感激的。
真的很感激你的帮助
小更新:尝试添加
connector = 'hudi'但这会引发错误:
Catalog 'hive' does not support table property 'connector'回答 1
Stack Overflow用户
发布于 2021-12-23 11:56:45
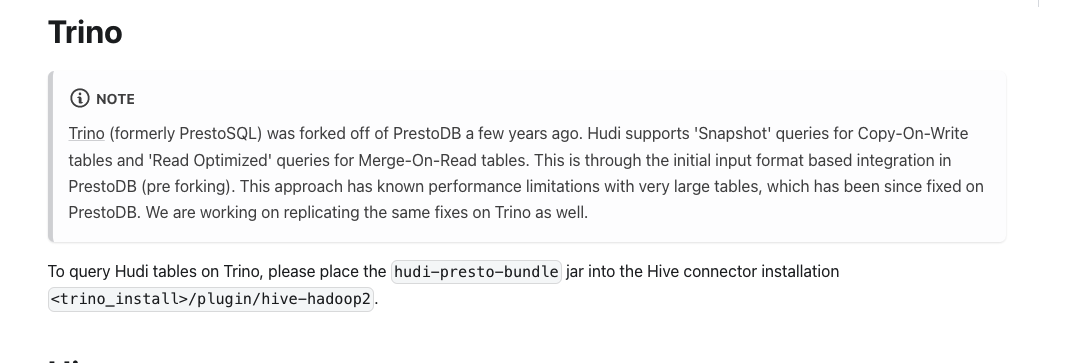
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70460695
复制相关文章
相似问题
腾讯云开发者
