
Selenium获得429的响应代码,但firefox私有模式没有
在python3中使用Selenium打开页面。它不是在selenium下打开,而是在firefox私有页面下打开的。
有什么区别,如何解决呢?
from selenium import webdriver
from time import sleep
driver = webdriver.Firefox()
driver.get('https://google.com') # creating a google cookie
driver.get_cookies() # check google gets cookies
sleep(3.0)
url='https://www.realestate.com.au/buy/in-sydney+cbd%2c+nsw/list-1'
driver.get(url)创建google cookie是不必要的。它也不在firefox的私有页面下,但是没有它它就能工作。然而,在硒环境下,这种行为是不同的。
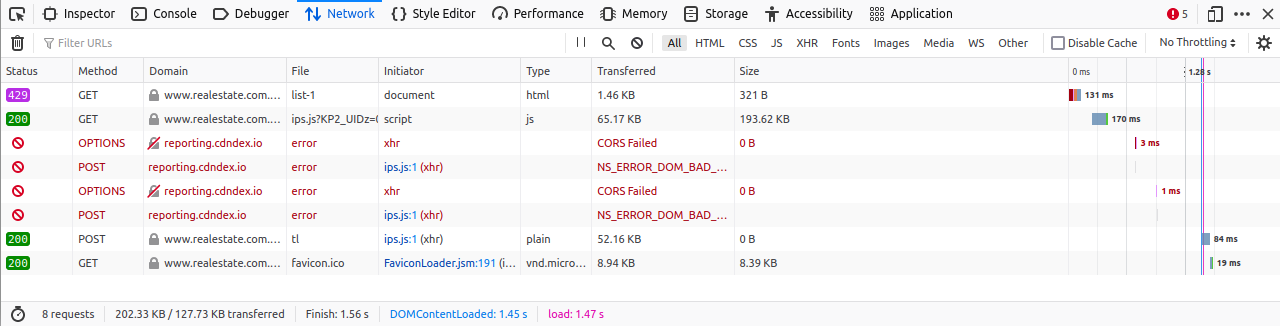
我还看到网站返回[HTTP/2 429 Too Many Requests 173ms]状态,页面是空白的白色。这种情况不会发生在firefox私有模式下。
更新:
我打开了持久的原木。私有模式下的Firefox也将收到429的响应,但似乎javascript将从另一个url恢复。这只是第一次发生。
然而,在selenium上,该请求无法在429响应中存活。它确实向cdndex网站报告了一些事情。我已经封锁了那个网站,所以你不能看到请求通过那里。这仍然是firefox和selenium之间的不同行为。
使用持久日志的Selenium:
具有持久日志的Firefox:

回答 2
Stack Overflow用户
发布于 2021-12-30 18:25:46
这只是我使用selenium和webdriver一段时间后的huch;我怀疑这是由于selenium的默认用户代理在默认情况下被设置为一些蹩脚的东西,服务器端认识到这一点,并因此为您提供了一个愚蠢的HTTP代码和一个空白页。
尝试将用户代理设置为合理的内容,并/或禁用selenium对默认值的干扰。
另一个技巧是使用wireshark或类似的方法查看请求,以确切地查看通过有线发送的内容。
Stack Overflow用户
发布于 2022-01-02 23:37:17
429太多的请求
代码表示用户在短时间内发送了太多请求。429状态码用于限制速率的方案.
根本原因
当您的服务器检测到用户代理在很短的时间内试图访问特定页面时,它会触发一个限制速率的特性。最常见的例子是当用户(或攻击者)反复尝试登录到web应用程序时。
服务器还可以使用cookies来标识bot,而不是通过它们的登录凭据。请求也可以计算在每个请求的基础上,跨服务器或跨多个服务器。因此,有很多种情况可能会导致您看到这样的错误:
- 429太多请求
- 429错误
- HTTP 429
- 错误429 (请求太多)
这个酶
这个usecase似乎是硒驱动的GeckoDriver启动的火狐浏览上下文获取探测到是机器人的经典案例,原因是:
Selenium自定义为
参考文献
您可以在以下网站找到几个相关的详细讨论:
https://stackoverflow.com/questions/70479603
复制相似问题
腾讯云开发者
