
比较dataframe列的后续行(具有字符串数据),如果有任何字符串匹配,则记录时间戳和持续时间。
比较dataframe列的后续行(具有字符串数据),如果有任何字符串匹配,则记录时间戳和持续时间。
提问于 2022-01-03 13:32:12
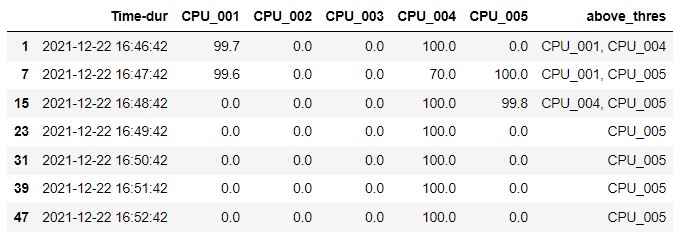
例1:就像上面的字符串"CPU_001“在第0行和第1行中匹配的那样,我们需要记录用户在2分钟内的高持续时间(因为每行的持续时间为1分钟),而Idle则是高的1分钟的持续时间。
例2:" CPU_005“在第2行和第3行很常见,然后CPU_005高2分钟,CPU_005高7分钟(接下来6行)。
下面是数据的详细信息。如果需要进一步的信息,请告诉我。
above_thres列仅包含值大于99.5的列的名称。
from pandas import Timestamp
dataFrame =
{'Time-dur': {1: Timestamp('2021-12-22 16:46:42'),
7: Timestamp('2021-12-22 16:47:42'),
15: Timestamp('2021-12-22 16:48:42'),
23: Timestamp('2021-12-22 16:49:42'),
31: Timestamp('2021-12-22 16:50:42'),
39: Timestamp('2021-12-22 16:51:42'),
47: Timestamp('2021-12-22 16:52:42'),
55: Timestamp('2021-12-22 16:53:42'),
63: Timestamp('2021-12-22 16:54:42'),
71: Timestamp('2021-12-22 16:55:42')},
'CPU_001': {1: 99.7,
7: 99.6,
15: 0.0,
23: 0.0,
31: 99.9,
39: 0.0,
47: 0.0,
55: 0.0,
63: 0.0,
71: 0.0},
'CPU_002': {1: 0.0,
7: 0.0,
15: 0.0,
23: 0.0,
31: 0.0,
39: 0.0,
47: 0.0,
55: 0.0,
63: 0.0,
71: 0.0},
'CPU_003': {1: 0.0,
7: 0.0,
15: 0.0,
23: 0.0,
31: 0.0,
39: 0.0,
47: 0.0,
55: 0.0,
63: 0.0,
71: 0.0},
'CPU_004': {1: 100.0,
7: 70.0,
15: 100.0,
23: 100.0,
31: 100.0,
39: 100.0,
47: 100.0,
55: 100.0,
63: 100.0,
71: 100.0},
'CPU_005': {1: 0.0,
7: 100.0,
15: 99.8,
23: 0.0,
31: 0.0,
39: 0.0,
47: 0.0,
55: 0.0,
63: 0.0,
71: 0.0},
'above_thres': {1: 'CPU_001, CPU_004',
7: 'CPU_001, CPU_005',
15: 'CPU_004, CPU_005',
23: 'CPU_005',
31: 'CPU_001, CPU_005',
39: 'CPU_005',
47: 'CPU_005',
55: 'CPU_005',
63: 'CPU_005',
71: 'CPU_005'}}
df = pd.DataFrame(dataFrame )
df.head()我正在寻找一个输出,该输出指示CPU的使用率高于99.5值,以及持续时间长短。即在上述情况下,CPU_001的使用超过阈值2分钟(2021-12-22 16:46:42到2021-12-22 16:47:42),时间1 min : 2021-12-22 16:50:42,另一种情况下,CPU_005超过阈值9分钟(2021-12-22 16:47:42到2021-12-22 16:55:42)输出可以以任何方便和可读的格式存储。
预期产出可类似于:
output_dict = {"CPU_001" : {
"count" : 3,
"interval" : [['2021-12-22 16:46:42', '2021-12-22 16:47:42'], ['2021-12-22 16:50:42','2021-12-22 16:50:42']],
"duration" : [2, 1]},
"CPU_002" : {
"count" : 0,
"interval" : [],
"duration" : []},
"CPU_003" : {
"count" : 0,
"interval" : [],
"duration" : []},
"CPU_004" : {
"count" : 2,
"interval" : [['2021-12-22 16:46:42', '2021-12-22 16:46:42'], ['2021-12-22 16:48:42','2021-12-22 16:48:42']],
"duration" : [1, 1]}
}回答 1
Stack Overflow用户
回答已采纳
发布于 2022-01-03 15:00:03
不久前也有类似的问题,我相信您可以重用我的代码:
dataFrame2= dataFrame.set_index('Time-dur').drop(columns=['above_thres'])
binary = pd.DataFrame(0, index=dataFrame2.index, columns=dataFrame2.columns)
binary[dataFrame2> 99.5] = 1
durations = pd.DataFrame(0, index=binary.index, columns=binary.columns)
for column in binary.columns:
sr = binary[column]
cnt: pd.Series = sr.groupby(sr.ne(sr.shift()).cumsum()).value_counts().reset_index(level=0, drop=True) # This is also from SO, but cannot remember where, sorry...
if len(cnt) == 0:
continue
cnt.name = 'count'
cnt = cnt.reset_index()
idx_dur = cnt['count'].cumsum().shift(1)
idx_dur[0] = 0
idx_dur += sr.index.get_loc(sr.first_valid_index())
cnt.index = sr.iloc[idx_dur].index
cnt = cnt.loc[cnt[column] == 1, 'count']
durations.loc[cnt.index, column] = cntdf durations包含值大于99.5%的后续行数。假设您的行间距相等,如果有必要,只需将此值乘以相应的TimeDelta (在本例中为1分钟)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70566540
复制相关文章
相似问题
腾讯云开发者
