
如何提取大写第一字母,每个单元格多个单词,理想情况下,忽略第一句与谷歌表,REGEXEXTRACT公式?
我试图从文本中提取带有大写字母的所有单词,并在google中使用REGEXEXTRACT公式。
理想情况下,句子的第一个单词应该被忽略,只有所有后面带有大写字母的单词都应该被提取出来。
其他密切的问题和公式:
我找到了另外两个问题和答案:
=ARRAYFORMULA(TRIM(IFERROR(REGEXREPLACE(IFERROR(REGEXEXTRACT(IFERROR(SPLIT(A2:A, CHAR(10))), "(.*) .*@")), "Mr. |Mrs. ", ""))))
=REGEXEXTRACT(A2, REPT(".* ([A-Z]{2,})", COUNTA(SPLIT(REGEXREPLACE(A2,"([A-Z]{2,})","$"),"$"))-1))
它们很接近,但我无法将它们成功地应用到我的项目中。
我使用的Regex模式:
我还找到了这个regex [A-ZÖ][a-zö]+模式,它可以很好地获得所有大写首字母单词。
问题是它并没有忽视句子的第一个单词。
其他Python解决方案与Google公式:
我还找到了这个python教程和脚本来完成它:
# Importing the required libraries
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize, sent_tokenize
# Function to extract the proper nouns
def ProperNounExtractor(text):
print('PROPER NOUNS EXTRACTED :')
sentences = nltk.sent_tokenize(text)
for sentence in sentences:
words = nltk.word_tokenize(sentence)
words = [word for word in words if word not in set(stopwords.words('english'))]
tagged = nltk.pos_tag(words)
for (word, tag) in tagged:
if tag == 'NNP': # If the word is a proper noun
print(word)
text = """Down the Rabbit-Hole
Alice was beginning to get very tired of sitting by her sister on the bank, and of having nothing to do: once or twice she had peeped into the book her sister was reading, but it had no pictures or conversations in it, `and what is the use of a book,' thought Alice `without pictures or conversation?'
So she was considering in her own mind (as well as she could, for the hot day made her feel very sleepy and stupid), whether the pleasure of making a daisy-chain would be worth the trouble of getting up and picking the daisies, when suddenly a White Rabbit with pink eyes ran close by her.
There was nothing so very remarkable in that; nor did Alice think it so very much out of the way to hear the Rabbit say to itself, `Oh dear! Oh dear! I shall be late!' (when she thought it over afterwards, it occurred to her that she ought to have wondered at this, but at the time it all seemed quite natural); but when the Rabbit actually took a watch out of its waistcoat-pocket, and looked at it, and then hurried on, Alice started to her feet, for it flashed across her mind that she had never before seen a rabbit with either a waistcoat-pocket, or a watch to take out of it, and burning with curiosity, she ran across the field after it, and fortunately was just in time to see it pop down a large rabbit-hole under the hedge."""
# Calling the ProperNounExtractor function to extract all the proper nouns from the given text.
ProperNounExtractor(text)它工作得很好,但我在Google中这样做的想法是让大写首字母的单词以表格的格式与文本相邻,以便更方便地参考。
问题摘要:
在下面的样本表中,你如何调整我的公式?
=ARRAYFORMULA(IF(A1:A="","",REGEXEXTRACT(A1:A,"[A-ZÖ][a-zö]+")))
增加这些职能:
- 用文本从每个单元格中提取所有第一个大写字母单词
- 忽略句子的第一个词
- 返回所有第一个大写字母单词,将句子中的第一个单词保存到相邻的单元格中,每个单元格只返回一个单词(类似于下面的示例(来自上面的第二个封闭问题):
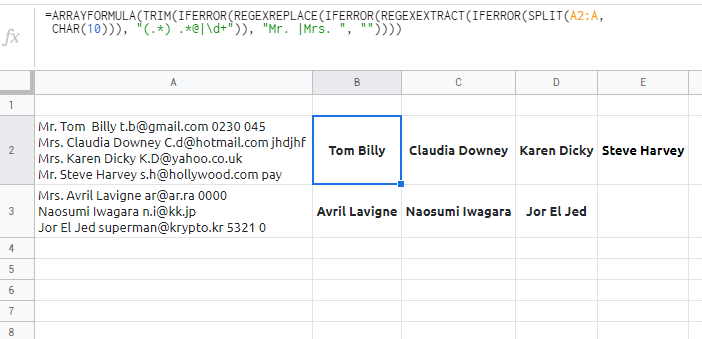
)
样本表:
这是我的测试样本表
非常感谢你的帮助!
Stack Overflow用户
发布于 2022-01-05 11:55:31
我的两分钱:
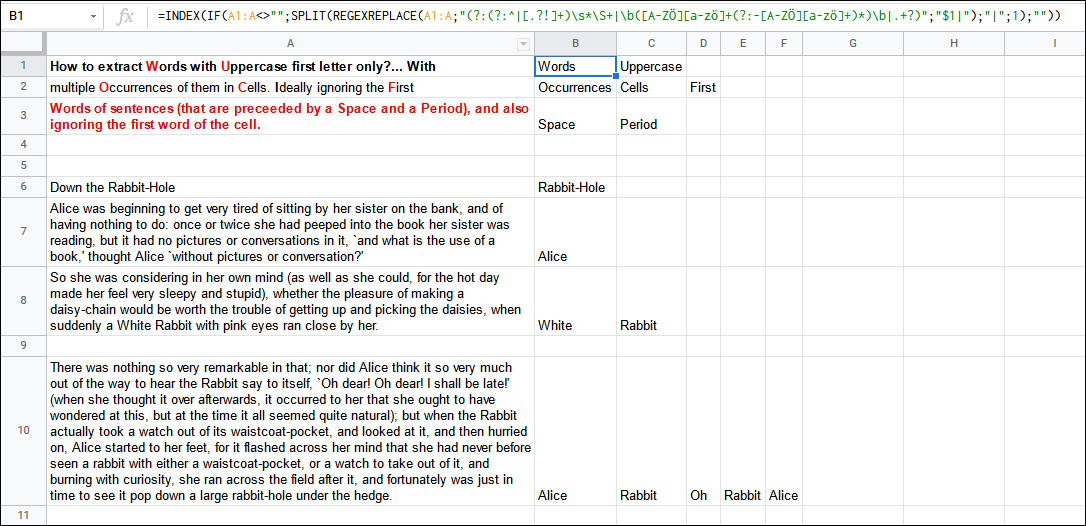
B1中的公式
=INDEX(IF(A1:A<>"",SPLIT(REGEXREPLACE(A1:A,"(?:(?:^|[.?!]+)\s*\S+|\b([A-ZÖ][a-zö]+(?:-[A-ZÖ][a-zö]+)*)\b|.+?)","$1|"),"|",1),""))模式:(?:(?:^|[.?!]+)\s*\S+|\b([A-ZÖ][a-zö]+(?:-[A-ZÖ][a-zö]+)*)\b|.+?)的意思是:
(?:-开放非捕获组以允许更改:(?:^|[.?!]+)\s*\S+-一个嵌套的非捕获组,用于允许起始行锚点或 1+文字点或问号/感叹号,然后是0+空格字符和1+非空格字符;|-或;\b([A-ZÖ][a-zö]+(?:-[A-ZÖ][a-zö]+)*)\b-第一次捕获-组捕捉骆驼-大小写字符串(可选连字符)之间的字-边界;|-或;.+?-任何1+字符(拉兹);)-关闭非捕获组。
这里的想法是使用REGEXREPLACE()替换任何匹配的第一个捕获组和管道符号(或任何不在您输入中的符号)的反向引用,并使用SPLIT()将所有单词分开。注意,使用函数的第三个参数忽略空字符串是很重要的。
INDEX()将触发数组功能并泄漏结果。我使用嵌套的IF()语句检查是否跳过空单元格。
https://stackoverflow.com/questions/70591241
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号