
如何在“OCR”之前验证图像中是否包含背景噪声
我有几种类型的图像,我需要从其中提取文本。根据背景噪声,我可以手动将图像分为3类:
- 没有噪音的图像。
- 背景中有一些光噪声的图像。
- 背景噪音很大。
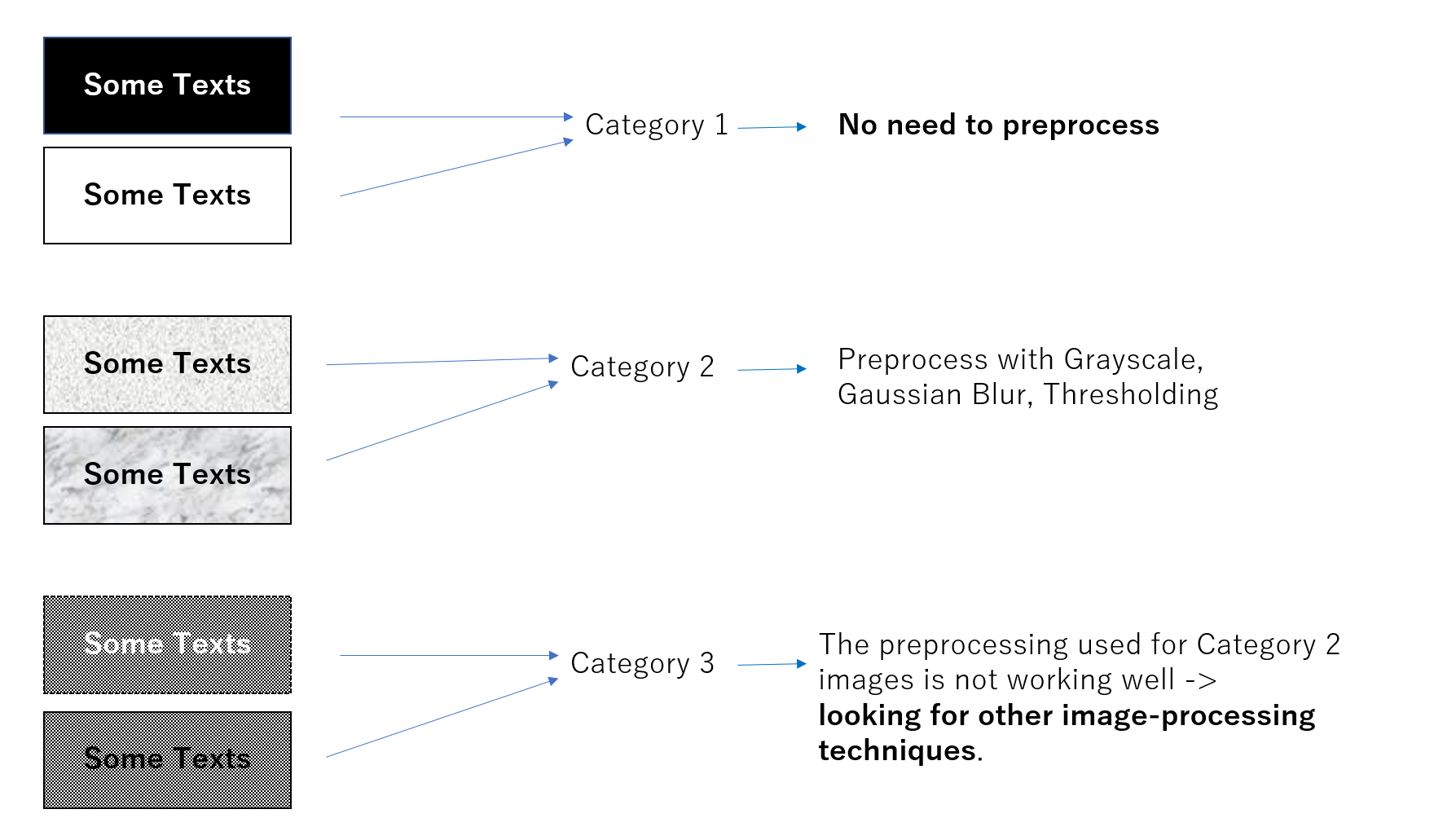
对于第一类图像,我可以在没有问题的情况下应用OCR‘’ing。→基本案例。
对于第2类图像和某些第3类图像,我可以通过应用以下方法来提取文本:
- 灰度,高斯模糊,Otsu阈值
- 打开变形消除噪声,倒置图像→,然后执行文本提取。
对于OCR‘’ing任务,一种消除噪声的方法显然不适用于所有图像。那么,有什么方法对图像的水平背景噪声进行分类吗?
欢迎所有建议。提前谢谢。
回答 2
Stack Overflow用户
发布于 2022-01-21 14:24:12
在其他问题上跟进你的评论,下面是一些你可以尝试的东西。下面的一些想法组合应该会有所帮助。
图像嵌入与向量聚类
手册
使用预先培训过的网络,如resnet on imagenet (可能工作不好),或者使用经过MNIST/EMNIST培训的简单预培训网络。
Extract and concat中的一些层将网络末端的权重矢量压平。采用维数约简和最近邻/近似近邻算法来寻找最接近的匹配。将集群的数量设置为3,因为有3种类型的图像。
最近的邻居从KNN开始。在github中也有许多可以帮助的库,如费斯、烦扰等。
我们可以找到更多,
https://github.com/topics/nearest-neighbor-search
https://github.com/topics/approximate-nearest-neighbor-search
如果以上结果不够好,try finetuning仅在最后几层进行MNIST/EMNIST训练网络。
利用现有图书馆
为了分组/查找相似的图像,
https://github.com/jina-ai/jina
您应该能够使用github上的标记neural-search、image-search找到更多的相似聚类。
https://github.com/topics/neural-search
https://github.com/topics/image-search
OCR
- 尝试一下舒约克,因为它比上一次使用ocr时对我更有用。
- 首先在整个文档上运行它,看看是否满足了要求。
- 如果可能的话,在文本周围使用一些/大的填充物,如果可能的话,不要使用这么紧的裁剪,附近没有其他文本。另一种方法是尝试在所有方向填充紧凑的裁剪文本,看看它是否改善了ocr的结果。
- 有关tesserect,请查看提高质量文档中提到的工具是否有所帮助。
分类
- 如果您已经将数据分类到3个不同的目录中,并且只想对未来的图像进行分类,那么我建议使用一个神经网络。修改
pytorch或tensorflow的mnist或cifar示例,以训练和分类测试图像。 - 基于示例图像,它看起来像计算机字体,而不是手写文本。如果是这样的话,模板匹配 at 多尺度可能会有所帮助。你必须看看噪音是否影响匹配结果。
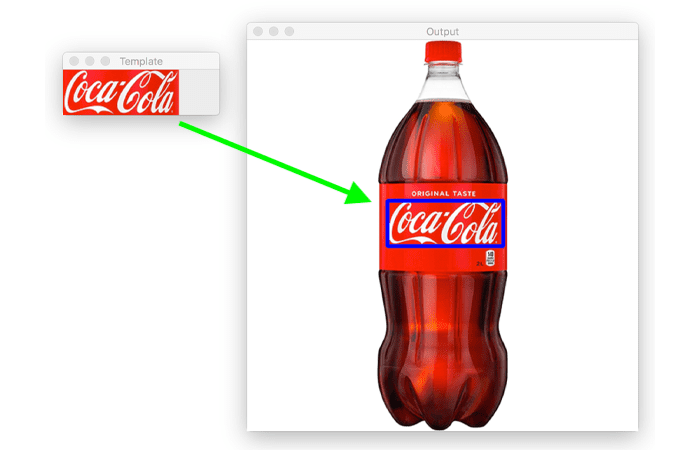
图片来自,https://www.pyimagesearch.com/2021/03/22/opencv-template-matching-cv2-matchtemplate/
噪声去除
- 这里你也可以用神经网络。通过添加模仿类别2和类别3图像的噪声,训练具有类别1图像的去噪自动编码器。这样,神经网络就可以在不需要人工创建数据集的情况下对3种图像类别进行分类,在后处理中,可以使用另一种神经网络或图像处理方法来去除基于类别类型的噪声。
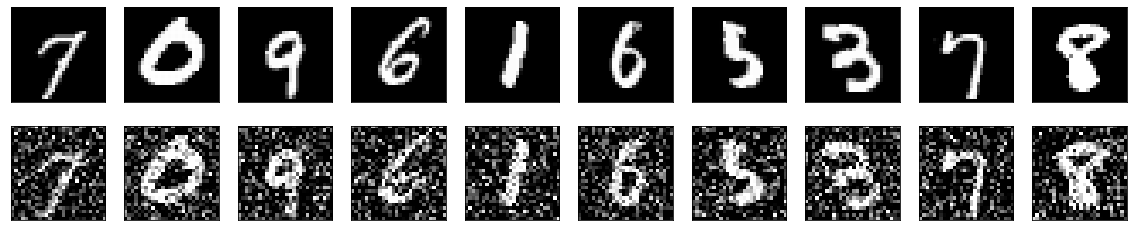
图片来自,https://keras.io/examples/vision/autoencoder/
- 在github上尝试现有的库或预先培训的网络,以消除整个文档/裁剪区域中的噪声。如果雷姆在文本文档上有效,请查看它。
Stack Overflow用户
发布于 2022-01-06 11:54:49
你的样品不太有说服力。所有图像都很容易被二值化(阈值25)。

https://stackoverflow.com/questions/70604177
复制相似问题
腾讯云开发者
