
MariaDB:对内部查询结果使用PK
我有三个表(MariaDB 10.6.5):person、private_person和corporate_person。在person是已存储的In中,在其他表中是存储的名称,它们都连接到每个FK中的person:
CREATE TABLE `person` (
`Id` INT(11) NOT NULL AUTO_INCREMENT,
`TypeOfPerson` ENUM('PRIVATE','CORPORATE') NOT NULL,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB;
CREATE TABLE `private_person` (
`PersonId` INT(11) NOT NULL,
`FirstName` VARCHAR(255) NULL DEFAULT NULL,
`LastName` VARCHAR(255) NULL DEFAULT NULL,
PRIMARY KEY (`PersonId`),
INDEX `IX_private_person_FirstName` (`FirstName`),
INDEX `IX_private_person_LastName` (`LastName`),
CONSTRAINT `FK_private_person_person_PersonId` FOREIGN KEY (`PersonId`) REFERENCES `person` (`Id`) ON UPDATE RESTRICT ON DELETE RESTRICT
) ENGINE=InnoDB;
CREATE TABLE `corporate_person` (
`PersonId` INT(11) NOT NULL,
`Name` VARCHAR(255) NULL DEFAULT NULL,
PRIMARY KEY (`PersonId`),
INDEX `IX_corporate_person_Name` (`Name`),
CONSTRAINT `FK_corporate_person_person_PersonId` FOREIGN KEY (`PersonId`) REFERENCES `person` (`Id`) ON UPDATE RESTRICT ON DELETE RESTRICT
) ENGINE=InnoDB;现在我必须在表private_person和corporate_person中搜索一个名称
SELECT `p`.Id
FROM `test`.`person` AS `p`
LEFT JOIN `test`.`private_person` AS `p0` ON `p`.`Id` = `p0`.`PersonId`
LEFT JOIN `test`.`corporate_person` AS `c0` ON `p`.`Id` = `c0`.`PersonId`
WHERE `p0`.`FirstName` = 'Test' OR p0.LastName = 'Test' OR `c0`.`Name` = 'Test';但是查询有点慢,因为这里有很多行:
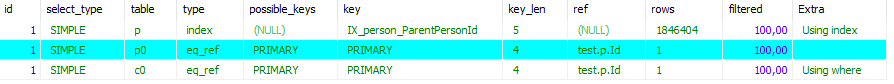
因此,我将查询更改为:
SELECT Id FROM `test`.`person` WHERE Id IN (
SELECT p.Id
FROM `test`.`person` AS `p`
INNER JOIN `test`.`private_person` AS `p0` ON `p`.`Id` = `p0`.`PersonId`
WHERE `p0`.`FirstName` = 'Test' OR `p0`.`LastName` = 'Test'
UNION SELECT p.Id
FROM `test`.`person` AS `p`
INNER JOIN `test`.`corporate_person` AS `c0` ON `p`.`Id` = `c0`.`PersonId`
WHERE `c0`.`Name` = 'Test' ORDER BY Id);内部查询(UNION)非常快,但是整个语句也很慢:

我不明白为什么。内部查询只提供一定数量的Ids,为什么优化器不对这些简单数量的Ids使用主索引?当我给出Ids而不是内部查询时
SELECT Id FROM `test`.`person` WHERE Id IN (25251, 47413, 99851 ...);当然,声明的速度也很快:

即使强制使用主索引(SELECT Id FROM test.person FORCE INDEX (PRIMARY) WHERE ...),它也不会更改任何内容;根据查询优化器,现在使用的是主索引,但语句的速度并不快:

如果优化器只从子查询中获得一定数量的in,那么为什么不以快速的方式使用主索引呢?
编辑:抱歉误会了。我不想让查询更快,实际上我已经为我的具体问题找到了解决方案(在比这里描述的更复杂的场景中,缓慢的查询),也许我错过了更明确地编写这个问题。但是在开发一个声明的过程中,我尝试使用我对mysql和优化器的了解,在这里,我非常惊讶,我不明白,mariadb的问题在哪里。同样,外部语句只获得一组in,并且不能以正确的方式使用PK。在SELECT Id FROM tabA WHERE Id IN (123, 456, 789)中使用PK,查询非常快,但是SELECT Id FROM tabA WHERE Id IN (SELECT Id FROM tabB WHERE ...) PK没有正确地使用,优化器在整个表tabA中爬行。为什么会这样呢?这就是我想问的问题。
回答 2
Stack Overflow用户
发布于 2022-01-20 14:00:49
是OR操作终结了您的查询。
WHERE `p0`.`FirstName` = 'Test' OR p0.LastName = 'Test' OR `c0`.`Name` = 'Test';这是查询优化的一个常见问题,因为MySQL每个表引用只使用一个索引(即使索引合并优化存在,它也没有您想象的那么频繁)。
问题是优化器不能使用单个B树索引来查找以下几个不同的列。
我经常用的比喻是一本电话簿。如果你想用姓氏来查找一个人,电话簿的顺序可以帮助你更有效地完成这个任务,因为它是以姓氏为首字母的。但是,如果你想用名字来查找一个人,这本书没有帮助,因为条目不是按名字排序的。如果你想查一个人的姓氏或名字,你仍然需要扫描整本书,以找到谁匹配的名字。
假设您有第二本电话簿,它是按名字排序的。这会有所帮助,但如果你受到一条规则的约束,迫使你只能使用一本或另一本书,而不是两者兼而有之,那么你就会陷入困境。不管你选哪本书,你都得扫描整本书才能找到另一个名字。
当优化器只允许每个表引用一个索引,并且查询中有OR条件时,就会发生这种情况。
许多人使用的解决方法是执行多个查询并对其结果进行UNION。
SELECT `p`.Id
FROM `test`.`person` AS `p`
INNER JOIN `test`.`private_person` AS `p0` ON `p`.`Id` = `p0`.`PersonId`
WHERE `p0`.`FirstName` = 'Test'
UNION
SELECT `p`.Id
FROM `test`.`person` AS `p`
INNER JOIN `test`.`private_person` AS `p0` ON `p`.`Id` = `p0`.`PersonId`
WHERE p0.LastName = 'Test'
UNION
SELECT `p`.Id
FROM `test`.`person` AS `p`
INNER JOIN `test`.`corporate_person` AS `c0` ON `p`.`Id` = `c0`.`PersonId`
WHERE `c0`.`Name` = 'Test';在这种情况下,每个表引用可以使用不同的索引,并更有效地搜索您想要的名称。一旦找到了一小部分匹配的行,它们就会通过该表的主键返回到person表(MySQL知道如何以不同于您在查询中列出的顺序访问表,所以不要担心哪个表在联接中先命名)。
关于你的评论:
有时,优化器会根据其成本估算模型,对如何排序表做出一些奇怪的决定,因为哪个表最好先访问。您可以这样覆盖它:
SELECT `p`.Id
FROM `private_person` AS `p0`
STRAIGHT_JOIN `person` AS `p` ON `p`.`Id` = `p0`.`PersonId`
WHERE `p0`.`FirstName` = 'Test'
UNION
SELECT `p`.Id
FROM `private_person` AS `p0`
STRAIGHT_JOIN `person` AS `p` ON `p`.`Id` = `p0`.`PersonId`
WHERE p0.LastName = 'Test'
UNION
SELECT `p`.Id
FROM `corporate_person` AS `c0`
STRAIGHT_JOIN `person` AS `p` ON `p`.`Id` = `c0`.`PersonId`
WHERE `c0`.`Name` = 'Test';STRAIGHT_JOIN意味着使用在SQL查询中出现的表顺序。
使用此方法,我测试了解释输出,得到了如下结果:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: p0
partitions: NULL
type: ref
possible_keys: PRIMARY,IX_private_person_FirstName
key: IX_private_person_FirstName
key_len: 1023
ref: const
rows: 1
filtered: 100.00
Extra: Using index
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: p
partitions: NULL
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: test2.p0.PersonId
rows: 1
filtered: 100.00
Extra: Using index
*************************** 3. row ***************************
id: 2
select_type: UNION
table: p0
partitions: NULL
type: ref
possible_keys: PRIMARY,IX_private_person_LastName
key: IX_private_person_LastName
key_len: 1023
ref: const
rows: 1
filtered: 100.00
Extra: Using index
*************************** 4. row ***************************
id: 2
select_type: UNION
table: p
partitions: NULL
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: test2.p0.PersonId
rows: 1
filtered: 100.00
Extra: Using index
*************************** 5. row ***************************
id: 3
select_type: UNION
table: c0
partitions: NULL
type: ref
possible_keys: PRIMARY,IX_corporate_person_Name
key: IX_corporate_person_Name
key_len: 1023
ref: const
rows: 1
filtered: 100.00
Extra: Using index
*************************** 6. row ***************************
id: 3
select_type: UNION
table: p
partitions: NULL
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: test2.c0.PersonId
rows: 1
filtered: 100.00
Extra: Using index
*************************** 7. row ***************************
id: NULL
select_type: UNION RESULT
table: <union1,2,3>
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
filtered: NULL
Extra: Using temporary这看起来会更好地使用索引,并以更好的顺序访问表。
请注意,我刚刚用空表进行了测试,这有时会使优化器对如何计算成本感到困惑。在你的环境中试一试。
Stack Overflow用户
发布于 2022-01-21 19:07:42
在您的联合案例中,SELECT Id FROM测试.person WHERE Id IN是不必要的。这可能是导致效率低下的原因。
如果您需要的不仅仅是来自结果的Id,请尝试如下:
SELECT ... -- (more than just Id)
FROM ( (SELECT ...)
UNION ALL
(SELECT ...)
) AS x;这在本质上迫使它在考虑外部选择之前先做联盟。
注意:UNION ALL可以导致dups (取决于细节),但比UNION (这意味着UNION DISTINCT)更快。也就是说,如果您知道没有dups,那么就在ALL上进行tack。
https://stackoverflow.com/questions/70784575
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号