自动绘制100多个使用熊猫、.txt问题的NaN文件
下午好
我试图导入一个100多个单独的.txt文件,其中包含我想要绘制的数据。我想自动化这个过程,因为对每个单独的文件执行相同的迭代是最繁琐的。
我已经阅读了如何读取多个.txt文件,并找到了一个很好的解释。但是,按照这个示例,我的所有数据都作为NaNs导入。我阅读了更多内容,找到了一种更可靠的导入.txt文件的方法,即使用pd.read_fwf() (如这里 )。
虽然我现在至少可以看到我的数据,但我不知道如何绘制它,因为数据在一个列中,由\t分隔。
扩展(mm)\tLoad (kN)\tMachine扩展(mm)\tPreload扩展
1 0.000000吨
2 0.152645\t0.000059312.
..。等。
我尝试在pd.read_csv()和pd.read_fwf()中使用不同的分隔符,包括“”、“\t”和“-s+”,但现在起作用了。
当然,这会引起问题,因为现在我无法绘制我的数据。说到这里,我也不知道如何在dataframe中绘制数据。我希望在相同的散点图上分别绘制每个.txt文件的数据。
我是非常新的堆栈溢出,所以请原谅格式的问题,如果它不符合正常标准。我在下面附上我的代码,但不幸的是我不能附加我的.txt文件。每个.txt文件包含大约一千行数据。我附上所有文件的一般格式的图片。.txt文件的一般格式。
{kind=link}
import numpy as np
import pandas as pd
from matplotlib import pyplot as pp
import os
import glob
# change the working directory
os.chdir(r"C:\Users\Philip de Bruin\Desktop\Universiteit van Pretoria\Nagraads\sterktetoetse_basislyn\trektoetse\speel")
# get the file names
leggername = [i for i in glob.glob("*.txt")]
# put everything in a dataframe
df = [pd.read_fwf(legger) for legger in leggername]
df 编辑:我现在获得的DataFrame输出是:
[ Time (s)\tLoad (kN)\tMachine Extension (mm)\tExtension“
0
1 0.000000吨
2
3 0.152645\t0.000059312\t-.
4.
...
997 76.0173\t0.037706\t0.005
998
999 76.1699\t0.037709\t
1000
1001
from Preload (mm) 0 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
3 NaN NaN NaN
4 NaN NaN NaN
.
997 NaN NaN NaN
998 NaN NaN NaN
九九九NaN NaN NaN
1000 NaN NaN NaN
1001 NaN NaN NaN
1002行x4列,时间(s)\tLoad (kN)\tMachine扩展(mm)\tExtension
0
1 0.000000吨
2
3 0.128151\t0.000043125吨
4.
...
997 63.8191\t0.034977\t0.00.
998
999 63.9473\t0.034974\t
1000
1001
from Preload (mm) 0 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
3 NaN NaN NaN
4 NaN NaN NaN
.
997 NaN NaN NaN
998 NaN NaN NaN
九九九NaN NaN NaN
1000 NaN NaN NaN
1001 NaN NaN NaN
1002行x4列,时间(s)\tLoad (kN)\tMachine扩展(mm)\tExtension
0
1 0.000000吨
2
3 0.174403\t0.000061553\t0.
4.
...
997 86.8529\t0.036093\t-0.00.
998
999 87.0273\t-0.0059160\t.
1000
1001
from Preload (mm) 0 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
3 NaN NaN NaN
4 NaN NaN NaN
.
997 NaN NaN NaN
998 NaN NaN NaN
九九九NaN NaN NaN
1000 NaN NaN NaN
1001 NaN NaN NaN
..。等
回答 1
Stack Overflow用户
发布于 2022-01-20 11:24:09
基本要点是跳过第一个数据行(其中包含一个值),然后使用选项卡作为分隔符,用pd.read_csv读取各个文件,并将它们堆叠在一起。
然而,还有一个更有问题的问题:数据文件最终被UTF-16编码(二进制数据在偶数位置显示一个NUL字符),但是没有字节顺序标记(BOM)来表示这一点。因此,您不能在read_csv中指定编码,而是必须将每个文件手动读取为二进制文件,然后用UTF-16将其解码为字符串,然后将该字符串提供给read_csv。因为后者需要文件名或IO流,所以需要首先将文本数据放入StringIO对象(或者先将校正后的数据保存到磁盘,然后读取更正的文件;可能不是个好主意)。
import pandas as pd
import os
import glob
import io
# change the working directory
os.chdir(r"C:\Users\Philip de Bruin\Desktop\Universiteit van Pretoria\Nagraads\sterktetoetse_basislyn\trektoetse\speel")
dfs = []
for filename in glob.glob("*.txt"):
with open(filename, 'rb') as fp:
data = fp.read() # a single file should fit in memory just fine
# Decode the UTF-16 data that is missing a BOM
string = data.decode('UTF-16')
# And put it into a stream, for ease-of-use with `read_csv`
stream = io.StringIO(string)
# Read the data from the, now properly decoded, stream
# Skip the single-value row, and use tabs as separators
df = pd.read_csv(stream, sep='\t', skiprows=[1])
# To keep track of the individual files, add an "origin" column
# with its value set to the corresponding filename
df['origin'] = filename
dfs.append(df)
# Concate all dataframes (default is to stack the rows)
df = pd.concat(dfs)
# For a quick and dirty plot, you can enjoy the power of Seaborn
import seaborn as sns
# Use appropriate (full) column names, and use the 'origin'
# column for the hue and symbol
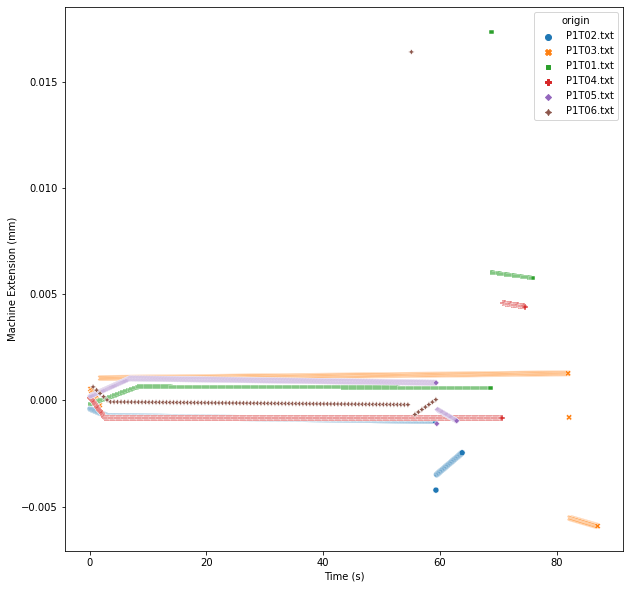
sns.scatterplot(data=df, x='Time (s)', y='Machine Extension (mm)', hue='origin', style='origin')
https://stackoverflow.com/questions/70784971
复制相似问题
腾讯云开发者
