
用SIMD查找sgn值的int8_t数组中-1和+1之间的转换来解决循环数据依赖问题
我试图实现性能改善,并取得了一些良好的经验,SIMD。到目前为止,我正在使用OMP,并希望进一步提高我的技能使用本质。
在下面的场景中,由于元素last_value测试所需的n+1的数据依赖关系,我未能改进(甚至是矢量化)。
环境是x64有AVX2,所以想要找到一种方法来矢量化和SIMDfy这样的函数。
inline static size_t get_indices_branched(size_t* _vResultIndices, size_t _size, const int8_t* _data) {
size_t index = 0;
int8_t last_value = 0;
for (size_t i = 0; i < _size; ++i) {
if ((_data[i] != 0) && (_data[i] != last_value)) {
// add to _vResultIndices
_vResultIndices[index] = i;
last_value = _data[i];
++index;
}
}
return index;
}输入是一个有符号的1字节值数组.每个元素都是<0,1,-1>的元素之一。输出是一个索引数组,用于输入值(或指针),表示更改为1或-1。
示例中/输出
in: { 0,0,1,0,1,1,-1,1, 0,-1,-1,1,0,0,1,1, 1,0,-1,0,0,0,0,0, 0,1,1,1,-1,-1,0,0, ... }
out { 2,6,7,9,11,18,25,28, ... }我的第一次尝试是使用各种无分支版本,并通过比较程序集输出来查看自动矢量化或OMP是否能够将其转换为SIMDish代码。
示例尝试
int8_t* rgLast = (int8_t*)alloca((_size + 1) * sizeof(int8_t));
rgLast[0] = 0;
#pragma omp simd safelen(1)
for (size_t i = 0; i < _size; ++i) {
bool b = (_data[i] != 0) & (_data[i] != rgLast[i]);
_vResultIndices[index] = i;
rgLast[i + 1] = (b * _data[i]) + (!b * rgLast[i]);
index += b;
}由于没有任何实验导致SIMD输出,所以我开始对本质进行实验,目的是将条件部分转换为一个掩码。
对于!= 0部分,这是非常直接的:
__m256i* vData = (__m256i*)(_data);
__m256i vHasSignal = _mm256_cmpeq_epi8(vData[i], _mm256_set1_epi8(0)); // elmiminate 0's对“最后一次翻转”进行测试的条件方面,我还没有找到一种方法。
为了解决以下输出打包方面,我假设AVX2基于掩码的最有效的打包方法是什么?可以工作。
更新1
深入研究这个话题会发现,分离1/-1和去掉0是有益的。幸运的是,在我的例子中,我可以直接从预处理到<1,0,-1>使用_mm256_xor_si256,有两个输入向量分隔为gt0 (所有1's)和lt0 (all -1's),这也允许4倍更紧密的数据打包。
我可能想以这样一个过程结束
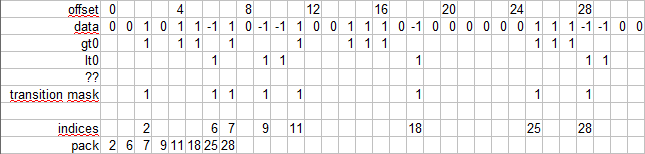
现在的挑战是如何创建基于gt0和lt0掩码的转换掩码。
更新2
一种将1和-1分割成2个流的方法(见答案),在访问交替扫描的元素时引入了依赖关系:如何有效地扫描每次迭代交替的2位掩码。
创建转换掩码( @aqrit )的方法是
transition mask = ((~lt + gt) & lt) | ((~gt + lt) & gt)是可能的。尽管这增加了相当多的指令,但对于消除数据依赖来说,这是一种有益的权衡。我假设增益越大,寄存器就越大(可能依赖于芯片)。
更新3
通过将transition mask = ((~lt + gt) & lt) | ((~gt + lt) & gt)矢量化,我可以编译这个输出
vmovdqu ymm5,ymmword ptr transition_mask[rax]
vmovdqu ymm4,ymm5
vpandn ymm0,ymm5,ymm6
vpaddb ymm1,ymm0,ymm5
vpand ymm3,ymm1,ymm5
vpandn ymm2,ymm5,ymm6
vpaddb ymm0,ymm2,ymm5
vpand ymm1,ymm0,ymm5
vpor ymm3,ymm1,ymm3
vmovdqu ymmword ptr transition_mask[rax],ymm3首先,与后处理的潜在条件相关的缺陷(垂直扫描+附加到输出)相比,它似乎是有效的,虽然它似乎是正确的和合乎逻辑的处理2流而不是1。
这缺乏每个周期生成初始状态的能力(从0过渡到1或-1)。不确定是否有一种方法可以增强transition_mask生成的“位旋转”,或者像Soons使用的那样使用auto initial _tzcnt_u32(mask0) > _tzcnt_u32(mask1):似乎包含一个分支的https://stackoverflow.com/a/70890642/18030502。
结论
使用改进的每个块负载的bit-twiddling解决方案来查找转换的方法@aqrit是运行时性能最好的方法。使用这样的tzcnt和blsr,热内环只有9个asm指令长(每2个找到的项,以便与其他方法进行比较)
tzcnt rax,rcx
mov qword ptr [rbx+rdx*8],rax
blsr rcx,rcx
tzcnt rax,rcx
mov qword ptr [rbx+rdx*8+8],rax
blsr rcx,rcx
add rdx,2
cmp rdx,r8
jl main+2580h (...) 回答 2
Stack Overflow用户
发布于 2022-01-29 00:55:08
在64位SIMD通道之间串行携带状态比在64位通用寄存器(gpr)之间串行携带状态要昂贵。
实际上,查找表(或SIMD左包装)仅限于一次处理8个元素。如果数据平均保持每64个元素中有6个元素,那么剩下的包装就浪费了大量的处理(特别是当我们收集偏移而不进行收集操作时)。如果位集是密集的,那么考虑移动到查找表。
正如@Snoots建议的那样,使用SIMD创建64位位集,并使用位扫描本质查找想要的集位的索引。
分支错误预测:
将大于(gt)和小于(lt)的位集压缩为单个位集,使用transition_mask = ((~lt + gt) & lt) | ((~gt + lt) & gt)或@FalkHüffner transition_mask = (lt ^ (lt - gt)) & (gt ^ (gt – lt))的简化。
状态是一个算术运算的进位/执行状态。我会小心地使用_subborrow_u64,因为它是相当罕见的固有特性(并且在旧编译器上是有缺陷的)。
只剩下剩下的分支在位扫描操作上循环。所有设置的比特都必须被提取。但我们可以展开操作和超调,使分支更加可预测。超调量需要调整到预期的数据集。
还没测试过。Asm没有被检查。
#include <immintrin.h>
#include <stdint.h>
static inline
uint64_t get_mask (int8_t* src, unsigned char* state) {
__m256i src0 = _mm256_loadu_si256((__m256i*)(void*)src);
__m256i src1 = _mm256_loadu_si256((__m256i*)(void*)&src[32]);
uint64_t lt = (uint32_t)_mm256_movemask_epi8(src0) |
(((uint64_t)(uint32_t)_mm256_movemask_epi8(src1)) << 32);
src0 = _mm256_cmpgt_epi8(src0, _mm256_setzero_si256());
src1 = _mm256_cmpgt_epi8(src1, _mm256_setzero_si256());
uint64_t gt = (uint32_t)_mm256_movemask_epi8(src0) |
(((uint64_t)(uint32_t)_mm256_movemask_epi8(src1)) << 32);
// if borrow then greater-than span extends past the msb
uint64_t m;
unsigned char s = *state;
*state = _subborrow_u64(s, lt, gt, (unsigned long long*)&m); // sbb
return (m ^ lt) & ((gt - (lt + !s)) ^ gt);
}
static inline
size_t bitset_to_index (uint64_t* dst, uint64_t base, uint64_t mask) {
int64_t cnt = _mm_popcnt_u64(mask);
int64_t i = 0;
do { // unroll to taste...
dst[i + 0] = base + _tzcnt_u64(mask); mask = _blsr_u64(mask);
dst[i + 1] = base + _tzcnt_u64(mask); mask = _blsr_u64(mask);
dst[i + 2] = base + _tzcnt_u64(mask); mask = _blsr_u64(mask);
dst[i + 3] = base + _tzcnt_u64(mask); mask = _blsr_u64(mask);
i += 4;
} while (i < cnt);
return (size_t)cnt;
}
static
uint64_t* get_transition_indices (uint64_t* dst, int8_t* src, size_t len) {
unsigned char state = 0; // in less-than span
uint64_t base = 0; // offset into src array
size_t end = len / 64;
for (size_t i = 0; i < end; i++) {
uint64_t mask = get_mask(src, &state);
src += 64;
dst += bitset_to_index(dst, base, mask);
base += 64;
}
if (len % 64) {
; // todo: tail loop
}
return dst;
}Stack Overflow用户
发布于 2022-01-26 17:57:13
完全矢量化对于你的情况来说不是最优的。从技术上讲,这是可能的,但我认为生成该数组uint64_t值的开销(我假设您正在为64位CPU编译)将消耗所有的利润。
相反,您应该加载块32字节,并立即将它们转换为位掩码。以下是如何:
inline void loadBits( const int8_t* rsi, uint32_t& lt, uint32_t& gt )
{
const __m256i vec = _mm256_loadu_si256( ( const __m256i* )rsi );
lt = (uint32_t)_mm256_movemask_epi8( vec );
const __m256i cmp = _mm256_cmpgt_epi8( vec, _mm256_setzero_si256() );
gt = (uint32_t)_mm256_movemask_epi8( cmp );
}剩下的代码应该处理这些位图。要找到第一个非零元素(您只需要在数据开始时这样做),扫描(lt | gt)整数中的最小有效集位。若要查找-1编号,请扫描lt整数中最小有效集位,在gt整数中查找+1号扫描最小有效集位。一旦找到并处理,您可以清除低部分的两个整数与位和,或将它们都向右移动。
CPU有BSF指令,用于扫描整数中最低的集合位,并同时返回两件事:一个标志,指示整数是否为零,以及该集合位的索引。如果您使用的是VC++内部的_BitScanForward,否则使用内联ASM,则该指令仅在VC++中公开;GCC的__builtin_ctz不是完全相同的东西,它只返回一个值而不是两个。
然而,在AMD上,来自中科院集的BMI 1指令比老派 BSF要快一些(在英特尔上它们是相等的)。在AMD上,TZCNT可能会稍微快一些,尽管与0相比有额外的指令。
https://stackoverflow.com/questions/70853685
复制相似问题
腾讯云开发者
