
使用python搜索文本文件中的段落
使用python搜索文本文件中的段落
提问于 2022-01-27 02:39:51
我有一个文字文件,其中有将近700页的文本。我只想根据标题过滤特定的文本,然后从这700页中提取该特定标题下的全部内容。一旦实现了这一点,我希望将其存储在Excel表中。想要用Python来做这件事,但是R中的解决方案也是受欢迎的。
回答 1
Stack Overflow用户
发布于 2022-01-27 02:54:34
我搜索"R“和"docx”文件,officer经常出现。我检查了它的克拉恩页面,该页面指向它的主页,其中包括一个名为“data.frame中的导入Word文档”的部分。该部分链接到docx_summary,其中包含两行代码。我要详述这一点。
但首先,可重复的数据。
- 打开Word并将下列文本粘贴为未格式化文本: Lorem Ipsum Lorem ipsum dolor从现在到现在,我的工作一直都是这样的。我不是在谴责它,而是在无意义的地方逃亡。霍多尔·伊普苏姆·霍多尔。霍多尔霍多尔。霍多尔·霍多尔。霍多尔。霍多尔!霍多尔,霍多尔;霍多尔霍多尔。霍多尔。霍多尔;霍多尔-霍多尔,霍多尔,霍多尔。霍多尔霍多尔。霍多尔。霍多尔,霍多尔霍多尔;霍奇霍;霍奇霍霍多尔!霍多尔·霍多尔!霍多尔·霍多尔。霍多尔·霍多尔。嬉皮士Ipsum Lorem ipsum dolor同胡须+1,蓝色瓶背心tbh符号学技工合成stumptown,胃酒吧,玉米洞,腹腔。早午餐消息之机,后讽刺的舌吻,无聊,XOXO,mlkshk,godard,over,tumblr,humblebrag。蓝色的瓶子在上面放了一只鸟,这是布鲁克林区的棱镜生物柴油。蓝色瓶中的油腻多汁。
- 对于每一行"Ipsum“,突出显示它们,并指定它们为"Header 1”样式。
- 保存。我把它保存为
Lorem Ipsum.docx。
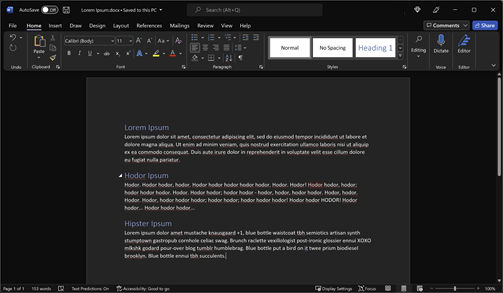
R中提取
我们去找"Hodor Ipsum“吧。
# library(officer) # optional, I'm doing the work without fully loading it
lorem <- officer::read_docx("Lorem Ipsum.docx")
summ <- officer::docx_summary(lorem)
summ
# doc_index content_type style_name text level num_id
# 1 1 paragraph heading 1 Lorem Ipsum NA NA
# 2 2 paragraph <NA> Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. NA NA
# 3 3 paragraph heading 1 Hodor Ipsum NA NA
# 4 4 paragraph <NA> Hodor. Hodor hodor, hodor. Hodor hodor hodor hodor hodor. Hodor. Hodor! Hodor hodor, hodor; hodor hodor hodor. Hodor. Hodor hodor; hodor hodor - hodor, hodor, hodor hodor. Hodor, hodor. Hodor. Hodor, hodor hodor hodor; hodor hodor; hodor hodor hodor! Hodor hodor HODOR! Hodor hodor... Hodor hodor hodor... NA NA
# 5 5 paragraph heading 1 Hipster Ipsum NA NA
# 6 6 paragraph <NA> Lorem ipsum dolor amet mustache knausgaard +1, blue bottle waistcoat tbh semiotics artisan synth stumptown gastropub cornhole celiac swag. Brunch raclette vexillologist post-ironic glossier ennui XOXO mlkshk godard pour-over blog tumblr humblebrag. Blue bottle put a bird on it twee prism biodiesel brooklyn. Blue bottle ennui tbh succulents. NA NA
str(summ)
# 'data.frame': 6 obs. of 6 variables:
# $ doc_index : int 1 2 3 4 5 6
# $ content_type: chr "paragraph" "paragraph" "paragraph" "paragraph" ...
# $ style_name : chr "heading 1" NA "heading 1" NA ...
# $ text : chr "Lorem Ipsum" "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore m"| __truncated__ "Hodor Ipsum" "Hodor. Hodor hodor, hodor. Hodor hodor hodor hodor hodor. Hodor. Hodor! Hodor hodor, hodor; hodor hodor hodor. "| __truncated__ ...
# $ level : num NA NA NA NA NA NA
# $ num_id : int NA NA NA NA NA NA
ind <- with(summ, which(grepl("heading", style_name) & text == "Hodor Ipsum"))
ind
# [1] 3这个示例文档实际上并没有太多的level或其他分组样式/机制,所以我将假设在适用的标题之后的data.frame行是我要寻找的段落。
if (ind < nrow(summ)) summ$text[ind+1]
# [1] "Hodor. Hodor hodor, hodor. Hodor hodor hodor hodor hodor. Hodor. Hodor! Hodor hodor, hodor; hodor hodor hodor. Hodor. Hodor hodor; hodor hodor - hodor, hodor, hodor hodor. Hodor, hodor. Hodor. Hodor, hodor hodor hodor; hodor hodor; hodor hodor hodor! Hodor hodor HODOR! Hodor hodor... Hodor hodor hodor..."页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70872674
复制相关文章
相似问题
腾讯云开发者
