
如何使用Python将嵌套的Hive查询模式转换为Bigquery模式?
如何使用Python将嵌套的Hive查询模式转换为Bigquery模式?
提问于 2022-02-04 05:44:10
问题面前的快速注释:在从on实例迁移到BigQuery期间,我们需要将许多Hive转换为BigQuery模式。对于非嵌套模式转换,我问了类似的问题,@Anjela善意地回答了这个非常有用的问题。但是还有另一种将嵌套的结构类型模式转换为BigQuery模式的用例,如下所示
示例蜂巢模式:
样本=
"reports array<struct<orderlineid:string,ordernumber:string,price:struct<currencycode:string,value:double>,quantity:int,serialnumbers:array<string>,sku:string>>"必需的BigQuery模式:
bigquery.SchemaField("reports", "RECORD", mode="REPEATED",
fields=(
bigquery.SchemaField('orderline', 'STRING'),
bigquery.SchemaField('ordernumber', 'STRING'),
bigquery.SchemaField('price', 'RECORD'),
fields=(
bigquery.SchemaField('currencyCode', 'STRING'),
bigquery.SchemaField('value', 'FLOAT')
)
bigquery.SchemaField('quantity', 'INTEGER'),
bigquery.SchemaField('serialnumbers', 'STRING', mode=REPEATED),
bigquery.SchemaField('sku', 'STRING'),
)
)我们从前面的问题中得到了什么,这对于将非嵌套模式转换为bigquery非常有用:
import re
from google.cloud import bigquery
def is_even(number):
if (number % 2) == 0:
return True
else:
return False
def clean_string(str_value):
return re.sub(r'[\W_]+', '', str_value)
def convert_to_bqdict(api_string):
"""
This only works for a struct with multiple fields
This could give you an idea on constructing a schema dict for BigQuery
"""
num_even = True
main_dict = {}
struct_dict = {}
field_arr = []
schema_arr = []
# Hard coded this since not sure what the string will look like if there are more inputs
init_struct = sample.split(' ')
main_dict["name"] = init_struct[0]
main_dict["type"] = "RECORD"
main_dict["mode"] = "NULLABLE"
cont_struct = init_struct[1].split('<')
num_elem = len(cont_struct)
# parse fields inside of struct<
for i in range(0,num_elem):
num_even = is_even(i)
# fields are seen on even indices
if num_even and i != 0:
temp = list(filter(None,cont_struct[i].split(','))) # remove blank elements
for elem in temp:
fields = list(filter(None,elem.split(':')))
struct_dict["name"] = clean_string(fields[0])
# "type" works for STRING as of the moment refer to
# https://cloud.google.com/bigquery/docs/schemas#standard_sql_data_types
# for the accepted data types
struct_dict["type"] = clean_string(fields[1]).upper()
struct_dict["mode"] = "NULLABLE"
field_arr.append(struct_dict)
struct_dict = {}
main_dict["fields"] = field_arr # assign dict to array of fields
schema_arr.append(main_dict)
return schema_arr
sample = "reports array<struct<imageUrl:string,reportedBy:string,newfield:bool>>"
bq_dict = convert_to_bqdict(sample)
client = bigquery.Client()
project = client.project
dataset_ref = bigquery.DatasetReference(project, '20211228')
table_ref = dataset_ref.table("20220203")
table = bigquery.Table(table_ref, schema=bq_dict)
table = client.create_table(table) @Anjela中的脚本正在将未嵌套的查询从单元模式转换为bigquery,如下所示:
"name":"reports"
"col_type":"array<struct<imageUrl:string,reportedBy:string>>"
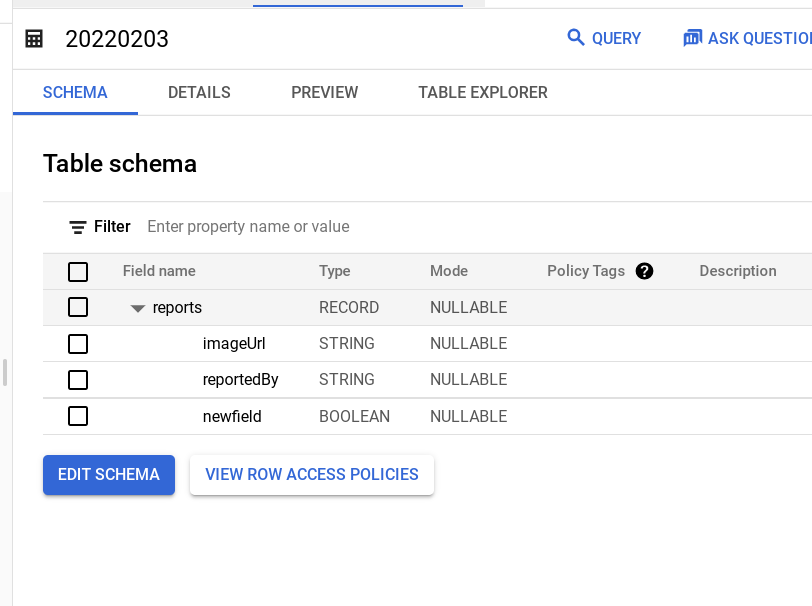
如有任何帮助/建议,将不胜感激。
Stack Overflow用户
回答已采纳
发布于 2022-02-05 13:24:37
以下是解决办法:
def getSchema2(self):
try:
getJsonUrl = requests.get(self.urlAddress)
except requests.exceptions.Timeout:
time.sleep(300)
try:
getJsonUrl = requests.get(self.urlAddress)
except requests.exceptions.Timeout as e:
logger.error("Communication error: {}".format(e))
raise SystemExit(e)
except requests.exceptions.TooManyRedirects:
logger.info("URL is not correct check your variables")
except requests.exceptions.RequestException as e:
logger.info("Communication error: {}".format(e))
raise SystemExit(e)
print(getJsonUrl.json()["tableData"]["columns"])
main_dict = {}
struct_dict = {}
subfield_struct_dict = {}
field_arr = []
subfield_arr = []
schema_arr = []
partition = None
for i in range(len(getJsonUrl.json()["tableData"]["columns"])):
if len(getJsonUrl.json()["tableData"]["columns"][i]["badges"]) > 0:
partition = True
col_name = getJsonUrl.json()["tableData"]["columns"][i]["name"]
col_type = 'partition'
main_dict["name"] = col_name
main_dict["mode"] = "NULLABLE"
main_dict["type"] = col_type
else:
col_name = getJsonUrl.json()["tableData"]["columns"][i]["name"]
col_type = getJsonUrl.json()["tableData"]["columns"][i]["col_type"]
if 'map' in col_type:
col_type = 'string'
main_dict["name"] = col_name
main_dict["type"] = col_type
elif 'bigint' == col_type:
col_type = 'integer'
main_dict["name"] = col_name
main_dict["type"] = col_type
elif 'int' == col_type:
col_type = 'integer'
main_dict["name"] = col_name
main_dict["type"] = col_type
elif 'double' == col_type:
col_type = 'float'
main_dict["name"] = col_name
main_dict["type"] = col_type
elif 'array<string>' == col_type:
col_type = 'string'
main_dict["name"] = col_name
main_dict["type"] = col_type
main_dict["mode"] = 'REPEATED'
elif ('array<struct' in col_type or 'struct<' in col_type):
main_dict["name"] = col_name
main_dict["type"] = 'RECORD'
if 'array<struct' in col_type:
main_dict["mode"] = 'REPEATED'
else:
main_dict["mode"] = 'NULLABLE'
raw_value = extractField(col_type)
for i in raw_value:
if 'struct' not in i:
field_col_name = i.split(":")[0]
field_col_type = i.split(":")[1]
field_mode = 'NULLABLE'
struct_dict["name"] = field_col_name
struct_dict["type"] = field_col_type
struct_dict["mode"] = field_mode
field_arr.append(struct_dict)
struct_dict = {}
else:
subfield_col_name = i.split(":")[0]
subfield_col_tpye = "RECORD"
subfield_col_mode = 'NULLABLE'
struct_dict["name"] = subfield_col_name
struct_dict["type"] = subfield_col_tpye
struct_dict["mode"] = subfield_col_mode
raw_subfield_types = i.split("struct")[1].split(",")
for i in raw_subfield_types:
raw_subfield_name = cleanString(i.split(":")[0])
raw_subfield_type = cleanString(i.split(":")[1])
raw_subfield_mode = "NULLABLE"
subfield_struct_dict["name"] = raw_subfield_name
subfield_struct_dict["type"] = raw_subfield_type
subfield_struct_dict["mode"] = raw_subfield_mode
subfield_arr.append(subfield_struct_dict)
struct_dict["fields"] = subfield_arr
field_arr.append(struct_dict)
struct_dict = {}
main_dict["fields"] = field_arr
schema_arr.append(main_dict)
main_dict = {}
else:
main_dict["name"] = col_name
main_dict["type"] = col_type
main_dict["mode"] = "NULLABLE"
schema_arr.append(main_dict)
main_dict = {}
if len(main_dict) != 0:
schema_arr.append(main_dict)
logger.info("Schema definition succesfully extracted from Amundsen")
return schema_arr, partition代码解释:
第一部分( First part,Request.get):该部分仅用于提取问题中给出的示例字符串。
第二部分:第二部分,灵感来自@Anjela .,他解决了这个问题的未嵌套类型。我只是为嵌套字段多添加了一个字典和数组结构,每次我们检查字段是否包含嵌套结构。
第三部分:看到我们使用extractField函数来解析嵌套结构,然后我们可以使用简单的拆分函数来获得子字段的col_names、col_types。
from itertools import accumulate
import re
def extractField(S):
levels = accumulate((c == "<") - (n == ">") for c, n in zip(' ' + S, S + ' '))
delim = "".join([c, "\n"][c == "," and lv == 2] for c, lv in zip(S, levels) if lv >= 2)
fields = delim.split("\n")
return fields
def cleanString(str_value):
return re.sub(r'[\W_]+','', str_value)最后,这里还有生成bigquery的功能:
def generate2(self):
client = bigquery.Client()
dataset = bigquery.Dataset(self.database)
dataset.location = "EU"
dataset = client.create_dataset(dataset, timeout=30, exists_ok=True)
query = bigquery.Table(self.database + "." + self.table, schema=self.schema)
query = client.create_table(query, exists_ok=True)
logger.info("Schema created under google cloud project id as: {}".format(self.database))
logger.info("Bigquery schema generated succesfully.")结果:
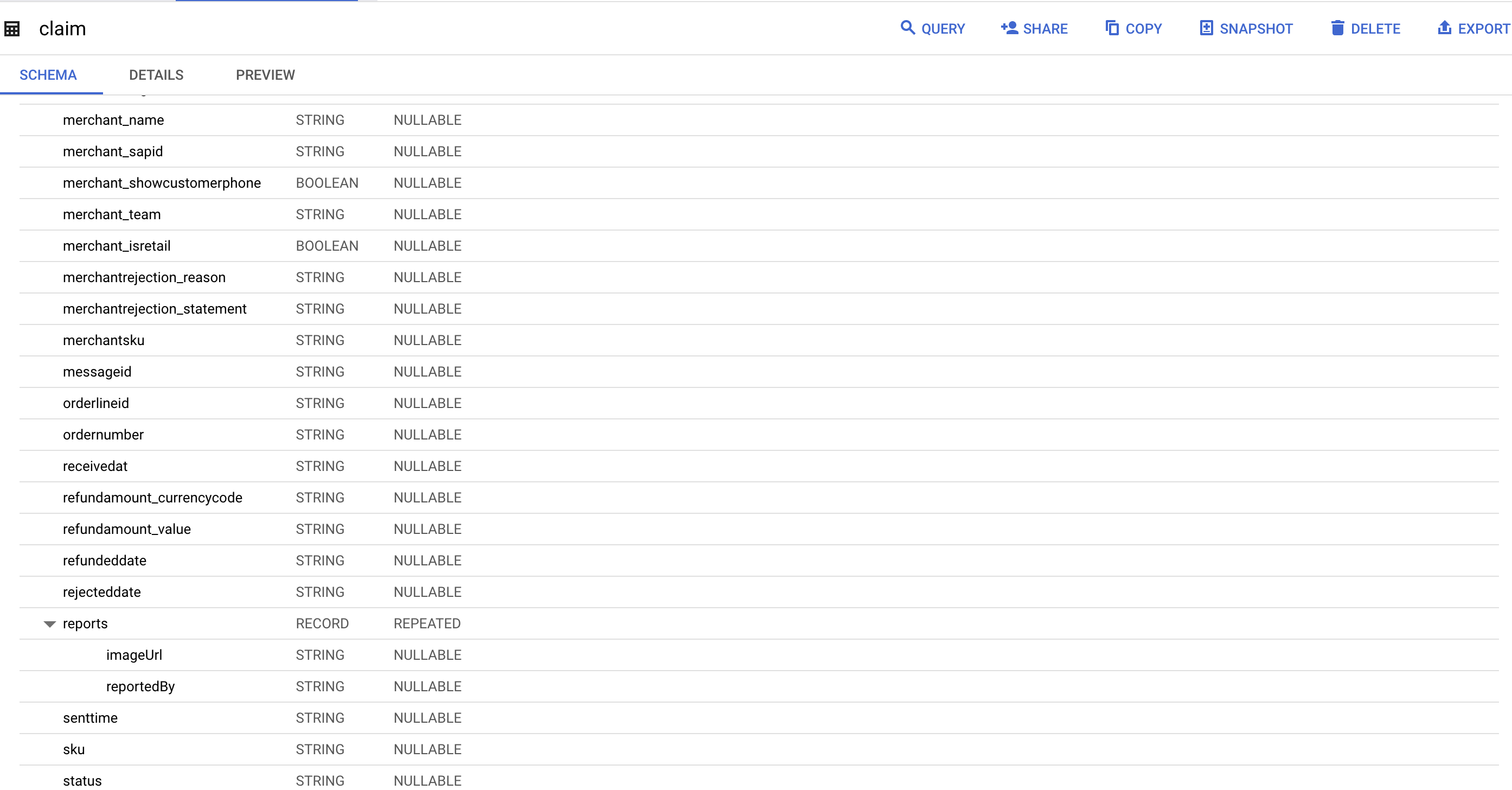
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70981937
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号