
Windows Tesseract OCR得到分散的HOCR输出,而不是干净的标准格式
Windows Tesseract OCR得到分散的HOCR输出,而不是干净的标准格式
提问于 2022-02-09 08:40:34
快速的帮助是非常感谢的。我正在通过tesseract-OCR从tiff图像中提取文本。我正在寻找is.HOCR (HTML)的输出。在内容方面,我得到了完美的输出,但是格式看起来非常混乱。但同样,当我打开记事本++时,它给出了一种清晰的格式。
下面给出了windows命令行
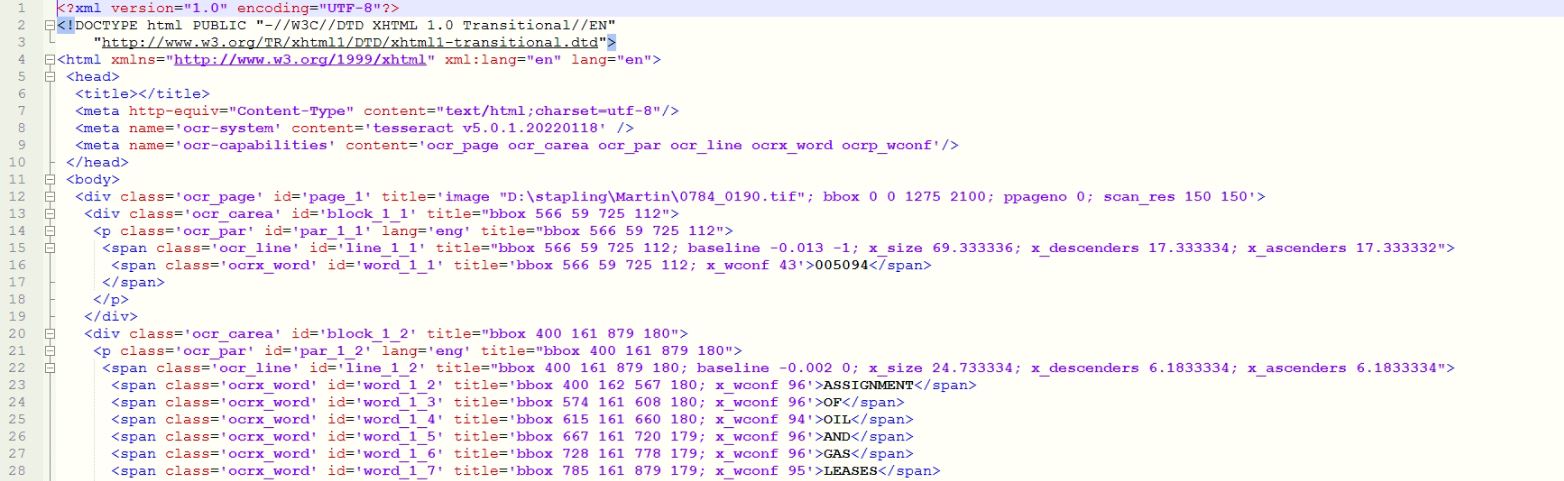
Tesseract "Path\image.tiff" "Path\output" HOCR需要您的帮助,以获得有组织的hocr格式的记事本作为附件。
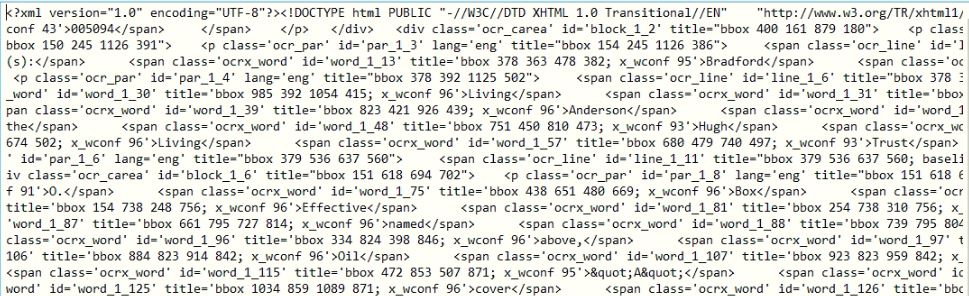
我是如何组织起来的?
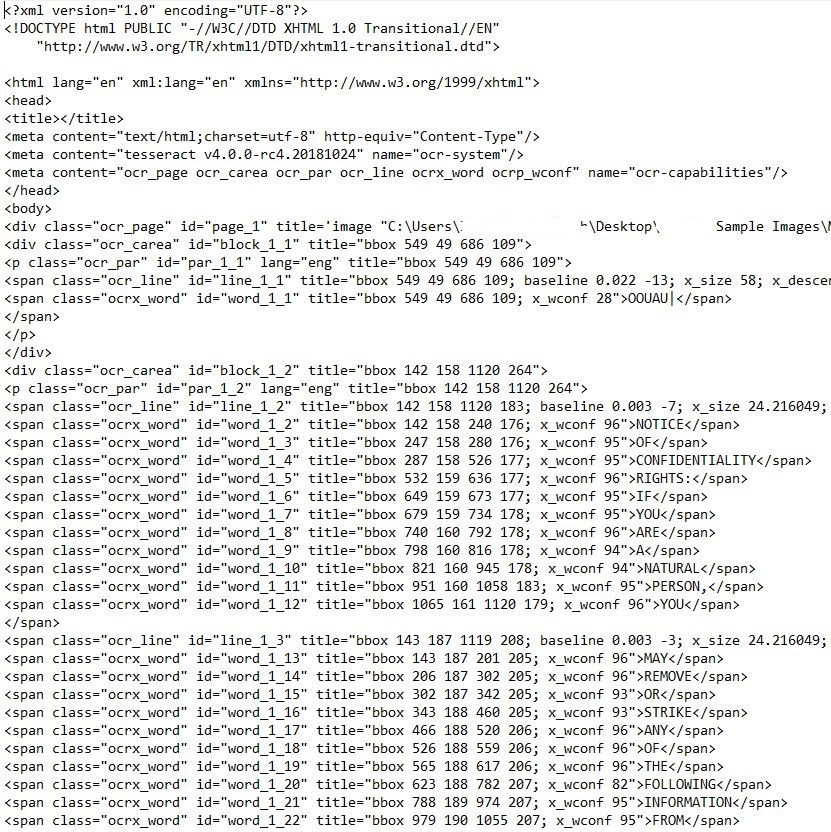
当我用记事本打开数据时?
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71046353
复制相关文章
相似问题
腾讯云开发者
