
Heroku BeautifulSoup + cloudscraper不要绕过服务器端的cloudflare
Heroku BeautifulSoup + cloudscraper不要绕过服务器端的cloudflare
提问于 2022-02-10 13:02:52
我正在使用BeautifulSoup + 云刮器来废弃一个站点。问题是在本地,它是工作的,但在heroku服务器上,它不工作。
看起来,当我通过heroku服务器启动脚本时,JS或cookie是不启用的。这就是为什么在当地的云刮板可以绕过云层而不是赫洛库。
我的代码:
import requests
import cloudscraper
from bs4 import BeautifulSoup
session = requests.session()
scraper = cloudscraper.create_scraper(browser='chrome', sess=session)
contract_page = scraper.get("https://bscscan.com/token/0x30e650783b4046c64dcf3b7b78854f3d4a87b058",
headers = {
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36",
'Cache-Control': "no-cache",
})
soupa = BeautifulSoup(contract_page.content, 'html.parser')
print(soupa)
tokenholders = soupa.find(id='ContentPlaceHolder1_tr_tokenHolders').get_text()soupa的打印给了我这个HTML页面:
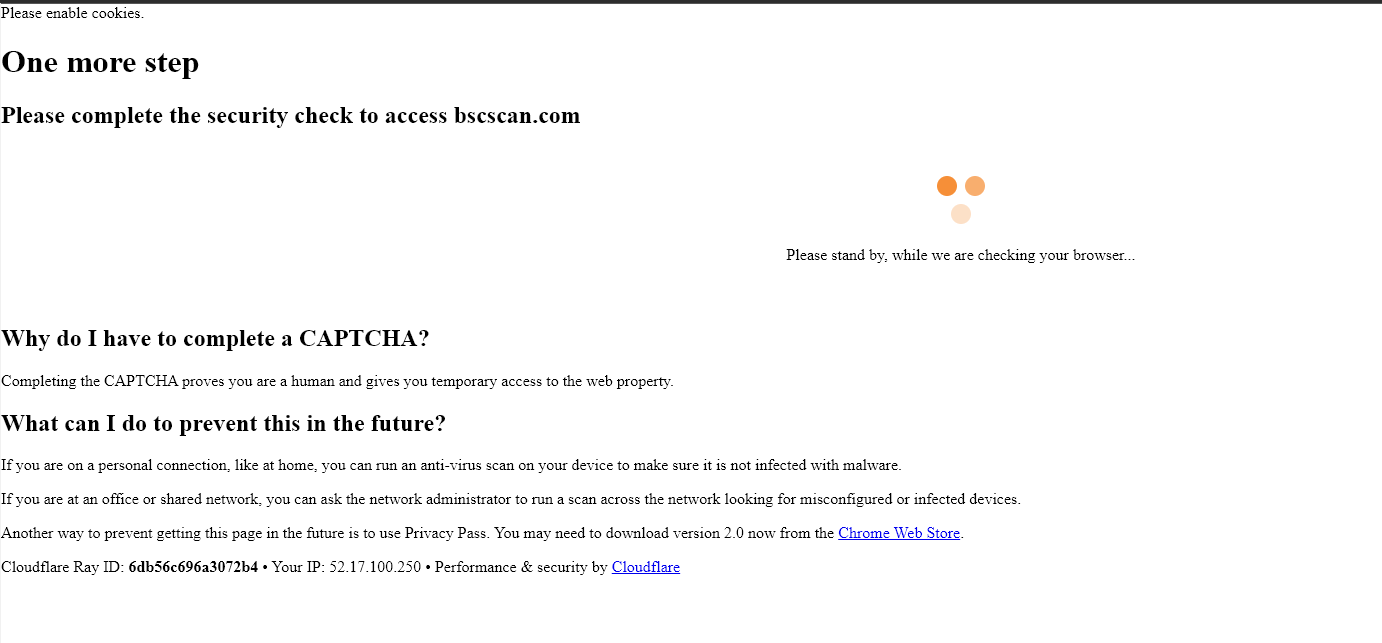
有人知道如何从运行脚本的heroku服务器上启用JS或cookie吗?
回答 1
Stack Overflow用户
发布于 2022-02-11 20:49:16
经过多次尝试,我找到了一个解决方案,为了绕过它,我们必须使用代理来更改heroku服务器的IP。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71065608
复制相关文章
相似问题
腾讯云开发者
