
KeyError:使用python执行时的“image_path”
KeyError:使用python执行时的“image_path”
提问于 2022-02-11 09:07:11
我正在尝试使用从图像中提取文本数据。我最初的起点是这里,在启用Vision和创建服务帐户、生成json文件之后,我通过引用这个示例创建了一个脚本。
这是我的密码
from google.cloud import vision
from google.cloud.vision_v1 import types
import os
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'generated_after_creating_sec_key.json'
image_path = 'images\\image_1.png'
vision_client = vision.ImageAnnotatorClient()
print(vision_client)
image = types.Image()
image.source.image_path = image_path
response = vision_client.text_detection(image=image)
for text in response.text_annotations:
print(text.description)google页面中显示的示例与我的代码之间的唯一区别是,示例中上传的图像位于gcloud上,而我的图像恰好位于本地存储上。
这是完整的堆栈跟踪。
<google.cloud.vision_v1.ImageAnnotatorClient object at 0x000001DF861D7970>
Traceback (most recent call last):
File "text_detection.py", line 10, in <module>
image.source.image_path = image_path
File "C:\Users\user\ProjectFolder\ProjName\venv\lib\site-packages\proto\message.py", line 677, in __setattr__
pb_type = self._meta.fields[key].pb_type
KeyError: 'image_path'造成这一错误的根本原因是什么?请帮帮我!
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-02-11 09:16:13
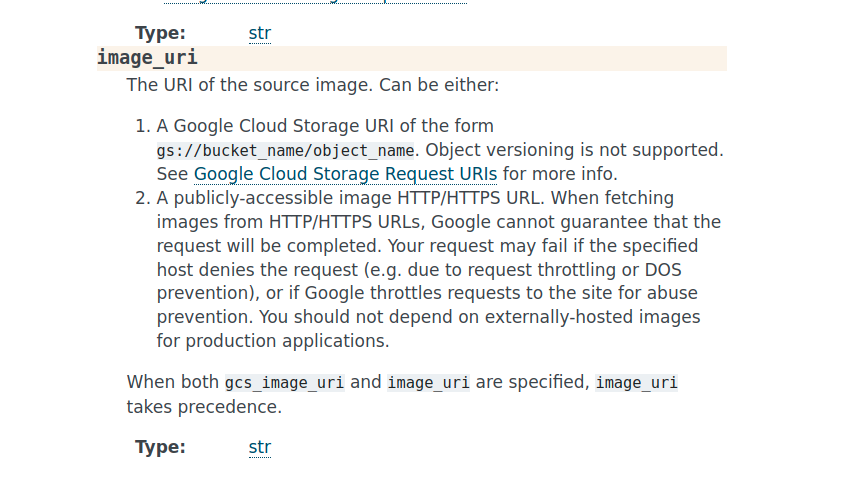
根据Google 文档,您需要的是image.source.image_uri。
Stack Overflow用户
发布于 2022-02-11 09:28:46
根据Google文档,您应该使用image.source.image_uri。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71077514
复制相关文章
相似问题
腾讯云开发者
