
从有效范围列表中标识匹配范围
从有效范围列表中标识匹配范围
提问于 2022-02-11 10:08:19
我有一个csv文件,其中包含列中的一系列数字。我也有有效范围的列表。我需要识别csv中匹配号码的可能范围。
valid_range = "0-1“、"1-2”、"0-5“、"5-10”、"10-15“、"15-20”、">20“、”混合“
csv数据:
我拥有的:
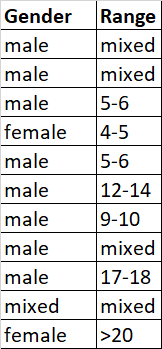
我需要什么:
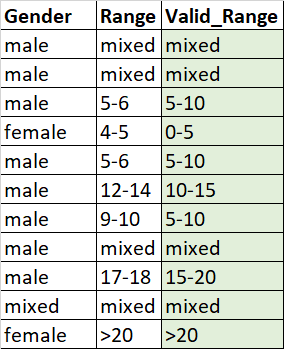
任何大于20的都会有">20“,而混合则会有相同的。
df = {'Gender': {0: 'male',
1: 'male',
2: 'male',
3: 'female',
4: 'male',
5: 'male',
6: 'male',
7: 'male',
8: 'male',
9: 'mixed',
10: 'female'},
'Range': {0: 'mixed',
1: 'mixed',
2: '5-6',
3: '4-5',
4: '5-6',
5: '12-14',
6: '9-10',
7: 'mixed',
8: '17-18',
9: 'mixed',
10: '>20'}}回答 1
Stack Overflow用户
回答已采纳
发布于 2022-02-11 10:24:38
如果你没有重叠,你可以依靠上界。
然后使用bit或regex魔术和pandas.cut
# non overlapping ranges
valid_range = ["0-5", "5-10", "10-15", "15-20", ">20", "mixed"]
# define bins (could also be coded as list directly!)
bins = (pd.Series(valid_range[:-2]).str.extract('(\d+)$', expand=False)
.astype(int).to_list()
)
bins = [0]+bins+[float('inf')]
# [0, 5, 10, 15, 20, inf]
df['Valid_Range'] = ( # replace ">x" with upper bound + 1
pd.cut(df['Range'].str.replace('>.*', f'{bins[-1]+1}', regex=True)
# extract trailing digits
.str.extract('(\d+)$', expand=False).astype(float),
bins=bins, labels=valid_range[:-1])
.values.add_categories(valid_range[-1]) # cut output is Categorical
.fillna(valid_range[-1]) # fill nans that correspond to initial "mixed"
)产出:
Gender Range Valid_Range
0 male mixed mixed
1 male mixed mixed
2 male 5-6 5-10
3 female 4-5 0-5
4 male 5-6 5-10
5 male 12-14 10-15
6 male 9-10 5-10
7 male mixed mixed
8 male 17-18 15-20
9 mixed mixed mixed
10 female >20 >20页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71078299
复制相关文章
相似问题
腾讯云开发者
