
当使用image_dataset_from_directory时,是否有可能将tensorflow数据集拆分为训练、验证和测试数据集?
我正在使用tf.keras.utils.image_dataset_from_directory加载一个由4575个图像组成的数据集。虽然此函数允许将数据拆分为两个子集(带有validation_split参数),但我希望将其拆分为训练、测试和验证子集。
我尝试使用dataset.skip()和dataset.take()进一步拆分一个结果子集,但是这些函数分别返回一个SkipDataset和一个TakeDataset (顺便说一句,与文献资料相反,这里声称这些函数返回一个Dataset)。这将导致模型拟合时的问题--在验证集(val_loss,val_accuracy)上计算的度量从模型历史中消失。
因此,我的问题是:是否有一种方法可以将Dataset划分为三个子集进行培训、验证和测试,从而使所有三个子集也都是Dataset对象?
用于加载数据的代码
def load_data_tf(data_path: str, img_shape=(256,256), batch_size: int=8):
train_ds = tf.keras.utils.image_dataset_from_directory(
data_path,
validation_split=0.2,
subset="training",
label_mode='categorical',
seed=123,
image_size=img_shape,
batch_size=batch_size)
val_ds = tf.keras.utils.image_dataset_from_directory(
data_path,
validation_split=0.3,
subset="validation",
label_mode='categorical',
seed=123,
image_size=img_shape,
batch_size=batch_size)
return train_ds, val_ds
train_dataset, test_val_ds = load_data_tf('data_folder', img_shape = (256,256), batch_size=8)
test_dataset = test_val_ds.take(686)
val_dataset = test_val_ds.skip(686)模型的编制与的拟合
model.compile(optimizer='sgd',
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])
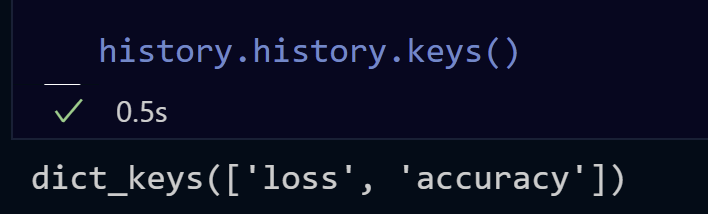
history = model.fit(train_dataset, epochs=50, validation_data=val_dataset, verbose=1)当使用普通的Dataset**,** val_accuracy 和 val_loss 时,在模型的历史记录中有:

但在使用SkipDataset**,时,它们不是:**

Stack Overflow用户
发布于 2022-02-16 06:54:52
问题是,在执行test_val_ds.take(686)和test_val_ds.skip(686)时,并不是获取和跳过样本,而是实际上是批处理。尝试运行print(val_dataset.cardinality()),您将看到实际保留了多少批用于验证。我猜val_dataset是空的,因为您没有686批进行验证。下面是一个有用的例子:
import tensorflow as tf
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)
batch_size = 32
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(180, 180),
batch_size=batch_size)
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(180, 180),
batch_size=batch_size)
test_dataset = val_ds.take(5)
val_ds = val_ds.skip(5)
print('Batches for testing -->', test_dataset.cardinality())
print('Batches for validating -->', val_ds.cardinality())
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255, input_shape=(180, 180, 3)),
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(5)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
epochs=1
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=1
)Found 3670 files belonging to 5 classes.
Using 2936 files for training.
Found 3670 files belonging to 5 classes.
Using 734 files for validation.
Batches for testing --> tf.Tensor(5, shape=(), dtype=int64)
Batches for validating --> tf.Tensor(18, shape=(), dtype=int64)
92/92 [==============================] - 96s 1s/step - loss: 1.3516 - accuracy: 0.4489 - val_loss: 1.1332 - val_accuracy: 0.5645在本例中,batch_size为32,您可以清楚地看到验证集保留了23批。之后,对测试集进行了5次批次的分配,并为验证集保留了18批。
https://stackoverflow.com/questions/71129505
复制相似问题
腾讯云开发者
