
PyTorch到ONNX导出,不支持ATen运算符,ONNX运行时挂起
我想将基于roberta-base的语言模型导出为ONNX格式。该模型使用ROBERTA嵌入并执行文本分类任务。
from torch import nn
import torch.onnx
import onnx
import onnxruntime
import torch
import transformers来自原木:
17: pytorch: 1.10.2+cu113
18: CUDA: False
21: device: cpu
26: onnxruntime: 1.10.0
27: onnx: 1.11.0PyTorch出口
batch_size = 3
model_input = {
'input_ids': torch.empty(batch_size, 256, dtype=torch.int).random_(32000),
'attention_mask': torch.empty(batch_size, 256, dtype=torch.int).random_(2),
'seq_len': torch.empty(batch_size, 1, dtype=torch.int).random_(256)
}
model_file_path = os.path.join("checkpoints", 'model.onnx')
torch.onnx.export(da_inference.model, # model being run
model_input, # model input (or a tuple for multiple inputs)
model_file_path, # where to save the model (can be a file or file-like object)
export_params=True, # store the trained parameter weights inside the model file
opset_version=11, # the ONNX version to export the model to
operator_export_type=torch.onnx.OperatorExportTypes.ONNX_ATEN_FALLBACK,
do_constant_folding=True, # whether to execute constant folding for optimization
input_names = ['input_ids', 'attention_mask', 'seq_len'], # the model's input names
output_names = ['output'], # the model's output names
dynamic_axes={'input_ids': {0 : 'batch_size'},
'attention_mask': {0 : 'batch_size'},
'seq_len': {0 : 'batch_size'},
'output' : {0 : 'batch_size'}},
verbose=True)我知道从ATen (C++11的张量库)转换一些操作符可能有问题,如果包含在模型体系结构PyTorch模型导出到ONNX由于ATen失败中。
如果我设置参数operator_export_type=torch.onnx.OperatorExportTypes.ONNX_ATEN_FALLBACK,即‘如果在ONNX中不支持也是ATen操作符’,导出就会成功。
PyTorch导出函数给我以下警告:
Warning: Unsupported operator ATen. No schema registered for this operator.
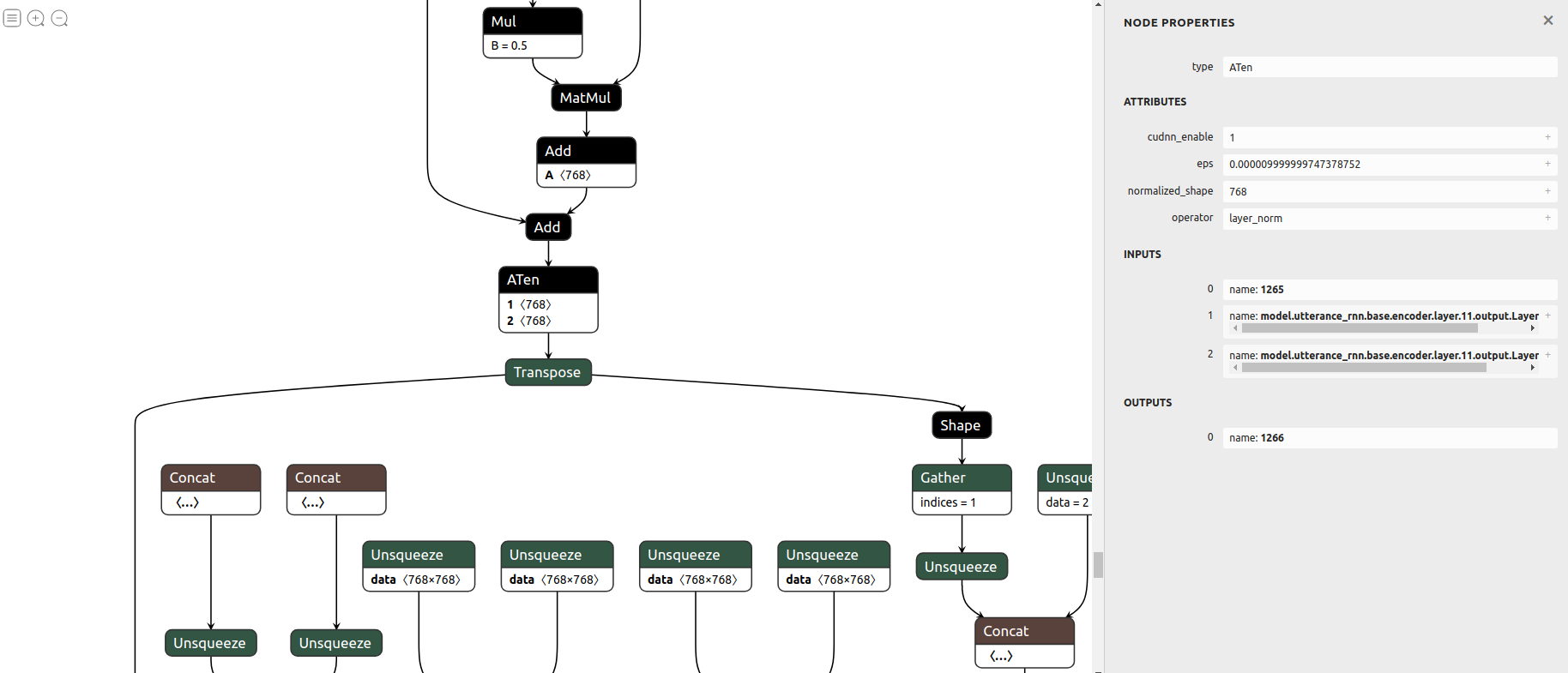
Warning: Shape inference does not support models with experimental operators: ATen看起来,模型中唯一没有转换为ONNX的ATen操作符位于LayerNorm.weight和LayerNorm.bias层内(我有几个这样的层):
%1266 : Float(3, 256, 768, strides=[196608, 768, 1], requires_grad=0, device=cpu) =
onnx::ATen[cudnn_enable=1, eps=1.0000000000000001e-05, normalized_shape=[768], operator="layer_norm"]
(%1265, %model.utterance_rnn.base.encoder.layer.11.output.LayerNorm.weight,
%model.utterance_rnn.base.encoder.layer.11.output.LayerNorm.bias)
# /opt/conda/lib/python3.9/site-packages/torch/nn/functional.py:2347:0超过模型检查通过确定:
model = onnx.load(model_file_path)
# Check that the model is well formed
onnx.checker.check_model(model)
# Print a human readable representation of the graph
print(onnx.helper.printable_graph(model.graph))我还可以使用内特恩可视化计算图。
但是,当我试图使用导出的ONNX模型执行推断时,它会在没有日志或stdout的情况下停止。因此,这段代码将挂起系统:
model_file_path = os.path.join("checkpoints", "model.onnx")
sess_options = onnxruntime.SessionOptions()
sess_options.log_severity_level = 0
ort_providers: List[str] = ["CUDAExecutionProvider"] if use_gpu else ['CPUExecutionProvider']
session = InferenceSession(model_file_path, providers=ort_providers, sess_options=sess_options)有什么解决这个问题的建议吗?从官方文档中我看到,以这种方式导出的torch.onnx模型可能只能由Caffe2运行。
这层不是在基础冻结罗伯塔模型内,所以这是我自己添加的额外层。是否有可能用相似的层来替代冒犯层,并对模型进行再培训?
或者Caffe2是这里最好的选择,Or运行时不会进行推断?
更新:我在基于BERT案例嵌入的基础上重新培训了模型,但问题依然存在。在ONNX中没有转换相同的ATen运算符。看起来LayerNorm.weight和LayerNorm.bias层只是在BERT上面的模型中。那么,您有什么建议来更改这个层并启用ONNX导出呢?
回答 2
Stack Overflow用户
发布于 2022-03-01 20:25:59
Stack Overflow用户
发布于 2022-03-03 14:05:56
最好的方法是重写模型中使用这些操作符的位置,并将其转换为这以供参考。例如,如果问题是层规范,那么您可以自己编写。另一件有时有帮助的事情是没有将轴设置为动态的,因为有些op还不支持它。
https://stackoverflow.com/questions/71220867
复制相似问题
腾讯云开发者
