
AWS :调用NoSuchKey操作时出错( GetObject ):指定的键不存在
我想从S3 (.csv)数据中获取数据,并将其放入DynamoDB中。我的意图是通过AWS将数据直接放入DynamoDB,每当S3接收到任何文件时,它都应该调用Lambda并将数据放入DynamoDB。我创建了一个S3桶,并创建了一个调用Lambda的触发器,如下面的图片所示。
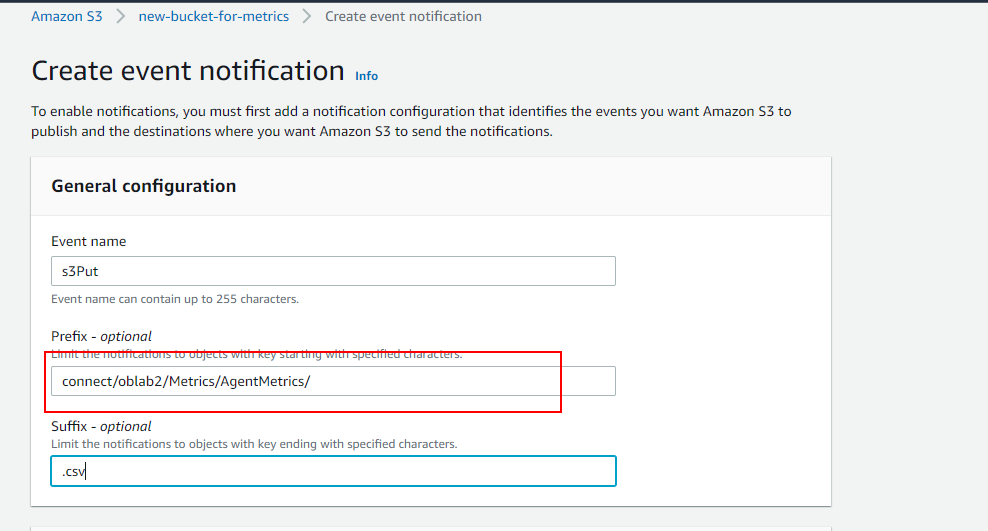
我还搞不懂在子目录前缀中写什么:"AgentMegrics/“或"connect/ oblab2 / Metrics / AgentMetrics /”,我所有的CSV文件都是在AgentMetrics中生成的,后者是metrics的子目录,它是oblab2的子目录,它是连接的子目录,它是存储桶的子目录(新的-桶- for -metrics)。
Lambda函数
import json
import boto3
s3_client = boto3.client("s3")
dynamodb = boto3.resource("dynamodb")
student_table = dynamodb.Table('AgentMetrics')
def lambda_handler(event, context):
source_bucket_name = event['Records'][0]['s3']['bucket']['name']
file_name = event['Records'][0]['s3']['object']['key']
file_object = s3_client.get_object(Bucket=source_bucket_name,Key=file_name)
print("file_object :",file_object)
file_content = file_object['Body'].read().decode("utf-8")
print("file_content :",file_content)
students = file_content.split("\n")
print("students :",students)
for student in students:
data = student.split(",")
try:
student_table.put_item(
Item = {
"Agent" : data[0],
"StartInterval" : data[1],
"EndInterval" : data[2],
"Agent idle time" : data[3],
"Agent on contact time" : data[4],
"Nonproductive time" : data[5],
"Online time" : data[6],
"Lunch Break time" : data[7],
"Service level 120 seconds" : data[8],
"After contact work time" : data[9],
"Contacts handled" : data[10],
"Contacts queued" : data[11]
} )
except Exception as e:
print("File Completed")我所犯的错误
{
"errorMessage": "An error occurred (NoSuchKey) when calling the GetObject operation: The specified key does not exist.",
"errorType": "NoSuchKey",
"requestId": "5047dd05-4d17-4e8a-8cb8-cc32002f8e9b",
"stackTrace": [
" File \"/var/task/lambda_function.py\", line 12, in lambda_handler\n file_object = s3_client.get_object(Bucket=source_bucket_name,Key=file_name)\n",
" File \"/var/runtime/botocore/client.py\", line 386, in _api_call\n return self._make_api_call(operation_name, kwargs)\n",
" File \"/var/runtime/botocore/client.py\", line 705, in _make_api_call\n raise error_class(parsed_response, operation_name)\n"
]
}Lambda测试事件
{
"Records": [
{
"eventVersion": "2.0",
"eventSource": "aws:s3",
"awsRegion": "us-east-1",
"eventTime": "1970-01-01T00:00:00.000Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "EXAMPLE"
},
"requestParameters": {
"sourceIPAddress": "127.0.0.1"
},
"responseElements": {
"x-amz-request-id": "EXAMPLE123456789",
"x-amz-id-2": "EXAMPLE123/5678abcdefghijklambdaisawesome/mnopqrstuvwxyzABCDEFGH"
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "testConfigRule",
"bucket": {
"name": "new-bucket-for-metrics",
"ownerIdentity": {
"principalId": "EXAMPLE"
},
"arn": "arn:aws:s3:::new-bucket-for-metrics"
},
"object": {
"key": "AgentMetrics-2022-02-23T13:30:00Z.csv",
"size": 1024,
"eTag": "0123456789abcdef0123456789abcdef",
"sequencer": "0A1B2C3D4E5F678901"
}
}
}
]
}我不知道我到底在哪里做错了,我感到沮丧,因为我已经张贴了这个问题三到四次。我没有得到任何仍然有帮助的回应。如果有人能帮我的话,我会很感激的。提前谢谢。
回答 1
Stack Overflow用户
发布于 2022-02-25 17:03:37
从根本上说,S3中的键应该引用对象的整个“文件夹”结构,而不仅仅是文件名。因此,假设您已经共享了全部信息,您的测试密钥应该是:
connect/oblab2/Metrics/AgentMetrics/AgentMetrics-2022-02-23T13:30:00Z.csv
当然,您需要将一个角色附加到具有"GetObject“权限的Lambda到这个特定位置。
注意:我将文件夹放入引号中,因为S3中实际上没有文件夹,这正是控制台中表示文件夹的方式。我认为对象的名称非常长,允许分组。基于此,您在S3通知中的前缀可以是"connect/oblab2/Metrics/AgentMetrics/“,前提是您只希望将文件放在该级别以下。
https://stackoverflow.com/questions/71252445
复制相似问题
腾讯云开发者
