
熊猫:用群比计算特定值的比率
熊猫:用群比计算特定值的比率
提问于 2022-03-05 15:57:25
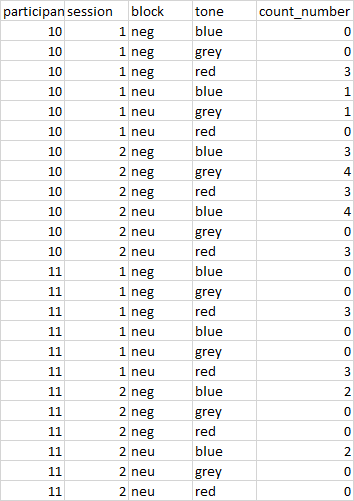
嗨,我有一张数据,看起来是这样的:
我想要计算列“count_number”中的比率,根据这个公式计算列‘色调’中的值:‘蓝色’+‘灰色’/‘红色’每个‘参与者_id’,‘会话’,‘块’的联合组合-
这里是作为文本的数据集的一部分,左列“比率”是我的预期输出:
participant_id会话音count_number比10 1 neg蓝0 0 10 1 neg count_number 0 0 10 1 neg红3 0 10 1 neu蓝1#DIV/0 10 1 neu灰色1 #DIV/0!10 1 neu红0 #DIV/0!10 2 neg蓝3 2.333333333 10 2 neg灰色4 2.333333333 10 2 neg红3 2.333333333 10 2 neu蓝41.333333333 10 2 neu灰色0 1.333333333 10 2 neu红3 1.333333333 11 1 neg蓝0 0 11 1 neg灰色0 0 11 1 neg红3 0
我尝试了这个(错误)方向
def group(df):
grouped = df.groupby(["participant_id", "session", "block"])['count_number']
return grouped
neutral = df.loc[df.tone=='grey']
pleasant = df.loc[df.tone=='blue']
unpleasant = df.loc[df.tone=='red']
df['ratio'] = (group(neutral)+group(pleasant)) / group(unpleasant)回答 1
Stack Overflow用户
回答已采纳
发布于 2022-03-05 17:22:49
这里有一个方法:
我们可以为除法的分子和分母创建单独的Series对象;然后groupby + transform sum + div将获取所需的比率:
num = df['tone'].isin(['blue','grey']) * df['count_number']
denom = df['tone'].eq('red') * df['count_number']
cols = [df[c] for c in ['participant_id', 'session', 'block']]
df['RATIO'] = (num.groupby(cols).transform('sum')
.div(denom.groupby(cols).transform('sum'))
.replace(float('inf'), '#DIV/0!'))另一种方法可以是使用groupby +应用lambda来计算每个组所需的比率;然后将这些比率映射回原始的DataFrame:
cols = ['participant_id', 'session', 'block']
mapping = (df.groupby(cols)
.apply(lambda x: (x.loc[x['tone'].isin(['blue','grey']), 'count_number'].sum() /
x.loc[x['tone'].eq('red'), 'count_number']))
.droplevel(-1))
df['RATIO'] = df.set_index(cols).index.map(mapping)
df['RATIO'] = df['RATIO'].replace(float('inf'), '#DIV/0!')输出:
group participant_id session block tone count_number RATIO
0 1 10 1 neg blue 0 0.0
1 1 10 1 neg grey 0 0.0
2 1 10 1 neg red 3 0.0
3 1 10 1 neu blue 1 #DIV/0!
4 1 10 1 neu grey 1 #DIV/0!
5 1 10 1 neu red 0 #DIV/0!
6 1 10 2 neg blue 3 2.333333
7 1 10 2 neg grey 4 2.333333
8 1 10 2 neg red 3 2.333333
9 1 10 2 neu blue 4 1.333333
10 1 10 2 neu grey 0 1.333333
11 1 10 2 neu red 3 1.333333
12 1 11 1 neg blue 0 0.0
13 1 11 1 neg grey 0 0.0
14 1 11 1 neg red 3 0.0页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71363686
复制相关文章
相似问题
腾讯云开发者
