
利用Intel oneAPI MKL实现密集向量乘法稀疏矩阵
我正在开发一个程序,大量使用Armadillo库。我有10.8.2版本,链接到英特尔的oneAPI MKL 2022.0.2。在某个时候,我需要执行许多稀疏矩阵乘以密集向量乘法,这两者都是用Armadillo结构定义的。我发现这一点可能是一个瓶颈,我很好奇用MKL (中压)的稀疏CBLAS例程替换Armadillo乘法是否会加快速度。但是为了做到这一点,我需要从Armadillo的SpMat转换到MKL理解的东西。根据Armadillo文档,稀疏矩阵以CSC格式存储,因此我尝试了csc。我的尝试如下:
#include <iostream>
#include <armadillo>
#include "mkl.h"
int main()
{
arma::umat locations = {{0, 0, 1, 3, 2},{0, 1, 0, 2, 3}};
// arma::vec vals = {0.5, 2.5, 2.5, 4.5, 4.5};
arma::vec vals = {0.5, 2.5, 3.5, 4.5, 5.5};
arma::sp_mat X(locations, vals);
std::cout << "X = \n" << arma::mat(X) << std::endl;
arma::vec v = {1,1,1,1};
arma::vec v2;
v2.resize(4);
std::cout << "v = \n" << v << std::endl;
std::cout << "X * v = \n" << X * v << std::endl;
MKL_INT *cols_beg = static_cast<MKL_INT *>(mkl_malloc(X.n_cols * sizeof(MKL_INT), 64));
MKL_INT *cols_end = static_cast<MKL_INT *>(mkl_malloc(X.n_cols * sizeof(MKL_INT), 64));
MKL_INT *row_idx = static_cast<MKL_INT *>(mkl_malloc(X.n_nonzero * sizeof(MKL_INT), 64));
double *values = static_cast<double *>(mkl_malloc(X.n_nonzero * sizeof(double), 64));
for (MKL_INT i = 0; i < X.n_cols; i++)
{
cols_beg[i] = static_cast<MKL_INT>(X.col_ptrs[i]);
cols_end[i] = static_cast<MKL_INT>((--X.end_col(i)).pos());
std::cout << cols_beg[i] << " --- " << cols_end[i] << std::endl;
}
std::cout << std::endl;
for (MKL_INT i = 0; i < X.n_nonzero; i++)
{
row_idx[i] = static_cast<MKL_INT>(X.row_indices[i]);
values[i] = X.values[i];
std::cout << row_idx[i] << " --- " << values[i] << std::endl;
}
std::cout << std::endl;
sparse_matrix_t X_mkl = NULL;
sparse_status_t res = mkl_sparse_d_create_csc(&X_mkl, SPARSE_INDEX_BASE_ZERO,
X.n_rows, X.n_cols, cols_beg, cols_end, row_idx, values);
if(res == SPARSE_STATUS_SUCCESS) std::cout << "Constructed mkl representation of X" << std::endl;
matrix_descr dsc;
dsc.type = SPARSE_MATRIX_TYPE_GENERAL;
sparse_status_t stat = mkl_sparse_d_mv(SPARSE_OPERATION_NON_TRANSPOSE, 1.0, X_mkl, dsc, v.memptr(), 0.0, v2.memptr());
std::cout << "Multiplication status = " << stat << std::endl;
if(stat == SPARSE_STATUS_SUCCESS)
{
std::cout << "Calculated X*v via mkl" << std::endl;
std::cout << v2;
}
mkl_free(cols_beg);
mkl_free(cols_end);
mkl_free(row_idx);
mkl_free(values);
mkl_sparse_destroy(X_mkl);
return 0;
}我正在Pop!_OS 21.10上使用(在链接线顾问的帮助下)编译这段代码。它编译并运行,没有任何问题。产出如下:
X =
0.5000 2.5000 0 0
3.5000 0 0 0
0 0 0 5.5000
0 0 4.5000 0
v =
1.0000
1.0000
1.0000
1.0000
X * v =
3.0000
3.5000
5.5000
4.5000
0 --- 1
2 --- 2
3 --- 3
4 --- 4
0 --- 0.5
1 --- 3.5
0 --- 2.5
3 --- 4.5
2 --- 5.5
Constructed mkl representation of X
Multiplication status = 0
Calculated X*v via mkl
0.5000
0
0
0正如我们所看到的,Armadillo的乘法结果是正确的,而MKL的结果是错误的。我的问题是:我是不是在哪里犯了一个错误?或者MKL有什么问题吗?。当然,我怀疑前者,但在花费了相当长的时间之后,却找不到任何东西。任何帮助都将不胜感激!
编辑
正如CJR和Vidyalatha_Intel所建议的,我已经将col_end更改为
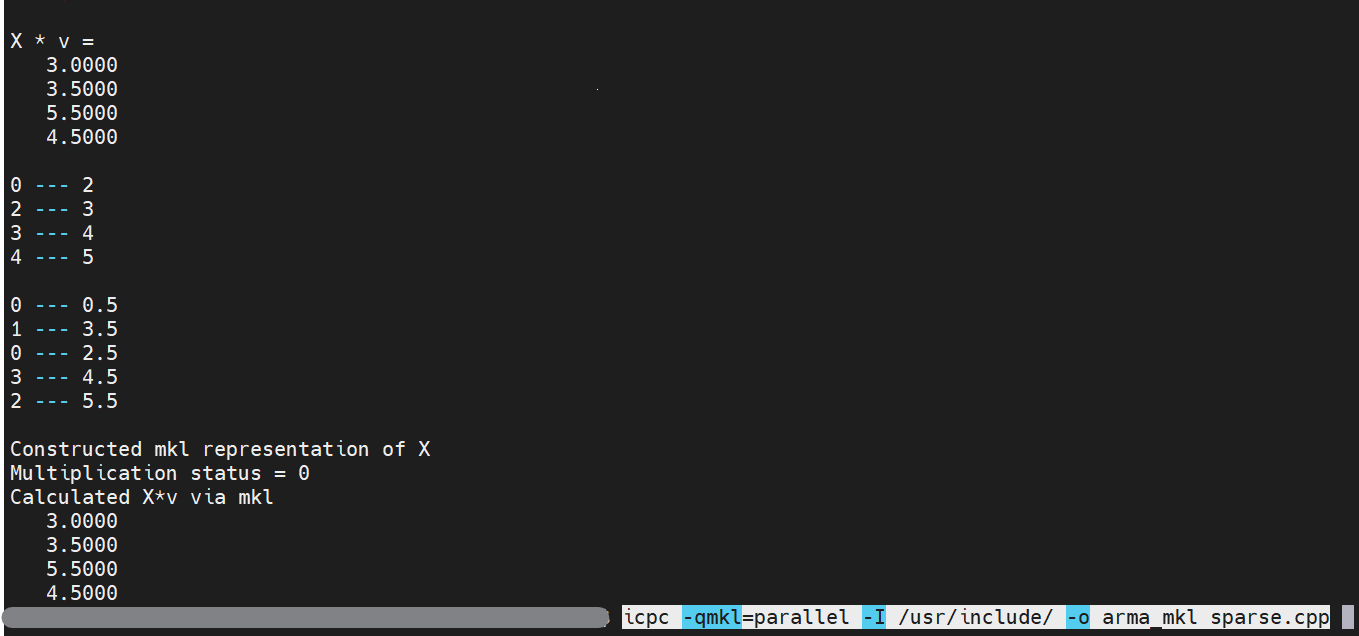
cols_end[i] = static_cast<MKL_INT>((X.end_col(i)).pos());结果是现在
X =
0.5000 2.5000 0 0
3.5000 0 0 0
0 0 0 5.5000
0 0 4.5000 0
v =
1.0000
1.0000
1.0000
1.0000
X * v =
3.0000
3.5000
5.5000
4.5000
0 --- 2
2 --- 3
3 --- 4
4 --- 5
0 --- 0.5
1 --- 3.5
0 --- 2.5
3 --- 4.5
2 --- 5.5
Constructed mkl representation of X
Multiplication status = 0
Calculated X*v via mkl
4.0000
2.5000
0
0col_end确实是建议的2,3,4,5,但结果仍然是错误的。
回答 1
Stack Overflow用户
发布于 2022-03-14 10:20:03
是的,正如CJR指出的那样,cols_end数组是不正确的。它们应该被索引为2,3,4,5。请参阅关于函数mkl_sparse_d_create_csc参数的文档。
cols_end:
该数组包含cols_endi索引,因此在数组值和row_indx中,col的最后一个索引是ind-1。ind采用0作为基于零的索引,1用于基于一个的索引.
更改这一行
cols_endi =static_cast(-X.end_col(I)).pos();
至
cols_endi =static_cast((X.end_col(I)).pos();
现在重新编译并运行代码。我已经测试过了,它显示了正确的结果。具有结果和编译命令的图像
https://stackoverflow.com/questions/71456912
复制相似问题
腾讯云开发者
