
在抓取网站时,如何在到达最后一页后停止selenium?
在抓取网站时,如何在到达最后一页后停止selenium?
提问于 2022-03-15 10:20:21
网站上的数据量(页数)一直在变化,我需要在分页过程中刮掉所有的页面。网址:https://monentreprise.bj/page/annonces
我试过的代码:
xpath= "//*[@id='yw3']/li[12]/a"
while True:
next_page = driver.find_elements(By.XPATH,xpath)
if len(next_page) < 1:
print("No more pages")
break
else:
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, xpath))).click()
print('ok')ok是连续打印的
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-03-15 10:46:58
这里有几个问题:
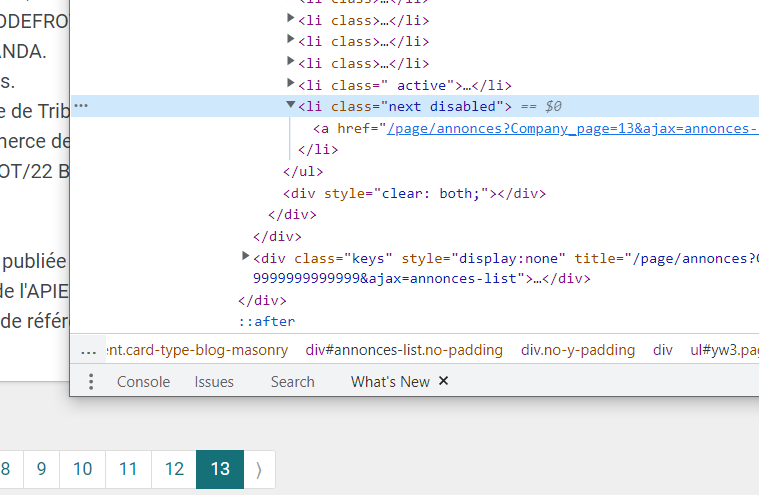
//*[@id='yw3']/li[12]/a不是next分页按钮的正确定位器。- 这里到达的最后一个页面的更好的指示是验证这个基于css_locator的元素
.pagination .next是否包含disabled类。 - 在单击“下一页”按钮之前,必须将页面向下滚动。
- 单击分页按钮后,必须添加延迟。否则这是行不通的。 这段代码适用于我:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
driver = webdriver.Chrome()
my_url = "https://monentreprise.bj/page/annonces"
driver.get(my_url)
next_page_parent = '.pagination .next'
next_page_parent_arrow = '.pagination .next a'
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(0.5)
parent = driver.find_element(By.CSS_SELECTOR,next_page_parent)
class_name = parent.get_attribute("class")
if "disabled" in class_name:
print("No more pages")
break
else:
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, next_page_parent_arrow))).click()
time.sleep(1.5)
print('ok')产出如下:
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
ok
No more pagesStack Overflow用户
发布于 2022-03-15 10:29:58
因为条件if len(next_page)<1总是假的。
例如,我尝试了url page=99999999999999999999999,它给出了第13页,这是最后一页。
您可以尝试的是检查“下一页”按钮是否已禁用。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71480545
复制相关文章
相似问题
腾讯云开发者
