
如何定义索引上带有condtions的序列?
如何定义索引上带有condtions的序列?
提问于 2022-03-24 19:12:06
我需要用i
我正试图像下面的屏幕截图一样操作,但它仍然保留了案例j
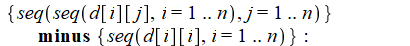
回答 2
Stack Overflow用户
发布于 2022-03-24 23:48:30
生成完整集(i=1..n和j=1..n)然后删除不需要的部分的方法是不必要的低效。
这里有两种更有效的方法(以及使用minus的方法,但是修正了使用double-seq)。
n:=4:
{seq( seq( d[i][j], j=i..n ), i=1..n )};
{d[1][1], d[1][2], d[1][3], d[1][4],
d[2][2], d[2][3], d[2][4],
d[3][3], d[3][4], d[4][4]}
{seq( seq( d[i][j], i=1..j ), j=1..n )};
{d[1][1], d[1][2], d[1][3], d[1][4],
d[2][2], d[2][3], d[2][4],
d[3][3], d[3][4], d[4][4]}
# The next is less efficient
{seq( seq( d[i][j], j=1..n ), i=1..n )}
minus {seq( seq( d[i][j], j=1..i-1 ), i=1..n )};
{d[1][1], d[1][2], d[1][3], d[1][4],
d[2][2], d[2][3], d[2][4],
d[3][3], d[3][4], d[4][4]}Stack Overflow用户
发布于 2022-06-04 08:49:10
对于这个问题,我将使用@acer的答案中的第一个方法。但是,如果索引上的条件有点复杂,以至于您不能很快想出一个简单的公式,可以在答案的第一个方法中创建您的索引,或者以两个索引集的集合减去等形式编写索引,那么您可以使用Maple中的select命令和作为布尔函数的原始条件。这是如何在你的情况下工作。
n := 4:
idxs := select( pair -> pair[1] < pair[2], [ seq( seq( [i, j], j = 1..n ), i = 1..n ) ] ); 您知道如何不受限制地生成所有[i, j],这是上面select命令的第二个参数。你的条件是,如果你拿起一对,它的第一个元素比它的第二个元素要小。因此,我们在上面编写了select的第一个参数,这是一个布尔函数,对于每一对,如果条件成立,则返回true,否则返回false。select命令在其第一个参数中提取它的第二个参数的元素,这些元素在函数下给出了true。现在您有了索引列表,您可以使用单个seq来使用它们。
{ seq( d[ pair[1] ][ pair[2] ], pair in idxs ) };这是输出的屏幕截图。

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71608188
复制相关文章
相似问题
腾讯云开发者
