
MNIST超拟合
MNIST超拟合
提问于 2022-03-28 03:39:43
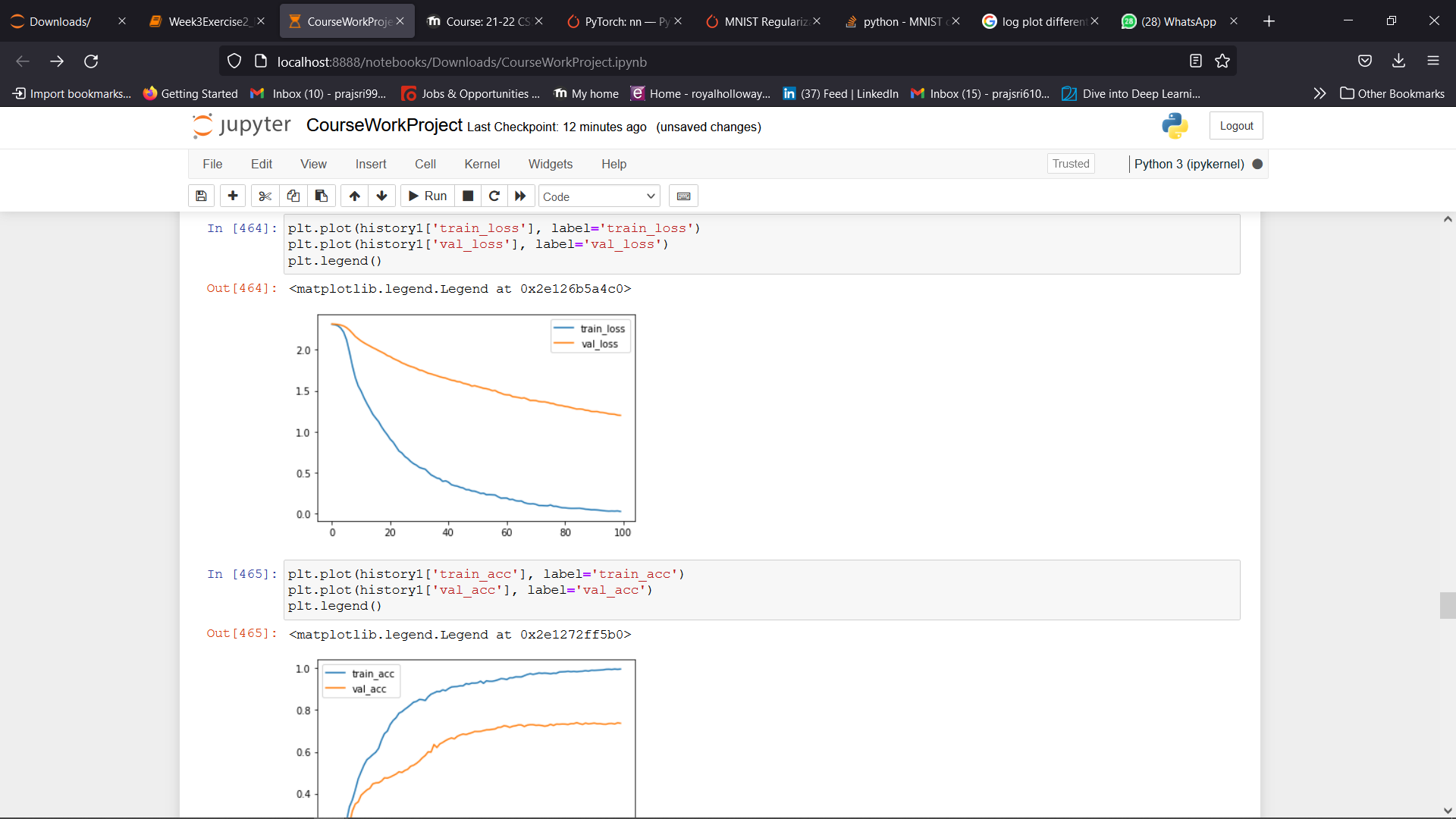
我目前正在处理MNIST数据集。我的模型已经对训练数据进行了拟合,我希望通过使用weight_decay来减少过度拟合。我目前使用0.1作为weight_decay的值,这给了我糟糕的结果,因为我的验证损失和训练损失并没有减少。但是,我想为weight_decay尝试不同的值。这样我就可以在x轴上绘制不同数量的weight_decay,并在y轴上显示验证集的性能。我该怎么做?将值存储在列表中,并使用for循环来迭代?下面是我尝试过的代码。
class NN(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(784,4096),
nn.ReLU(),
nn.Linear(4096,2048),
nn.ReLU(),
nn.Linear(2048,1024),
nn.ReLU(),
nn.Linear(1024,512),
nn.ReLU(),
nn.Linear(512,256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,64),
nn.ReLU(),
nn.Linear(64,32),
nn.ReLU(),
nn.Linear(32,16),
nn.ReLU(),
nn.Linear(16,10))
def forward(self,x):
return self.layers(x)
def accuracy_and_loss(model, loss_function, dataloader):
total_correct = 0
total_loss = 0
total_examples = 0
n_batches = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = model(images)
batch_loss = loss_function(outputs,labels)
n_batches += 1
total_loss += batch_loss.item()
_, predicted = torch.max(outputs, dim=1)
total_examples += labels.size(0)
total_correct += (predicted == labels).sum().item()
accuracy = total_correct / total_examples
mean_loss = total_loss / n_batches
return (accuracy, mean_loss)
def define_and_train(model,dataset_training, dataset_test):
trainloader = torch.utils.data.DataLoader( small_trainset, batch_size=500, shuffle=True)
testloader = torch.utils.data.DataLoader( dataset_test, batch_size=500, shuffle=True)
values = [1e-8,1e-7,1e-6,1e-5]
model = NN()
for params in values:
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay = params)
train_acc = []
val_acc = []
train_loss = []
val_loss = []
for epoch in range(100):
total_loss = 0
total_correct = 0
total_examples = 0
n_mini_batches = 0
for i,mini_batch in enumerate(trainloader,0):
images,labels = mini_batch
optimizer.zero_grad()
outputs = model(images)
loss = loss_function(outputs,labels)
loss.backward()
optimizer.step()
n_mini_batches += 1
total_loss += loss.item()
_, predicted = torch.max(outputs, dim=1)
total_examples += labels.size(0)
total_correct += (predicted == labels).sum().item()
epoch_training_accuracy = total_correct / total_examples
epoch_training_loss = total_loss / n_mini_batches
epoch_val_accuracy, epoch_val_loss = accuracy_and_loss( model, loss_function, testloader )
print('Params %f Epoch %d loss: %.3f acc: %.3f val_loss: %.3f val_acc: %.3f'
%(params, epoch+1, epoch_training_loss, epoch_training_accuracy, epoch_val_loss, epoch_val_accuracy))
train_loss.append( epoch_training_loss )
train_acc.append( epoch_training_accuracy )
val_loss.append( epoch_val_loss )
val_acc.append( epoch_val_accuracy )
history = { 'train_loss': train_loss,
'train_acc': train_acc,
'val_loss': val_loss,
'val_acc': val_acc }
return ( history, model ) 这就是我要得到的情节。我哪里出问题了?
回答 1
Stack Overflow用户
发布于 2022-03-28 08:04:21
我不知道任何信息。(例如损失函数、数据集大小、数据集内容(培训和验证)、100或200个时代的结果、问题的范围)
然而,过度拟合的模型可以对验证数据集进行分类。因为MNIST数据集并不难深入学习(与其他图像分类相比)。将白噪声添加到验证数据集中如何?您可能会在验证方面遭受很大损失。
或者,如果要使用验证数据集,则至少要对该模型进行1000个历次的培训。但是,正如我前面所说的,过度拟合的模型可能会对验证数据集进行分类。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71642179
复制相关文章
相似问题
腾讯云开发者
